- 單元
- 教學文

【創業小聚】新創先進感知要讓台灣擺脫「行人地獄」之名,先從路口紅綠燈聯網開始
本文將介紹先進感知團隊透過物聯網技術和手機App以及自行規劃的三階段交通改善計畫,從視障者社會福利作為起點,逐漸擴展至為社會全體大眾福祉努力。

視覺化 Raspberry Pi 數據:輕鬆用 Arduino Cloud 掌握物聯網裝置
如何將出色的感測器數據,轉化為易於在手機或筆記型電腦上查看和互動的數據?本篇文章會教導各位如何將 Raspberry Pi 數據視覺化!

【實作實驗室】看似掉漆其實是卡水垢?熱水瓶保養經驗談
熱水瓶用久了,內桶會出現淺淺的區塊,是塗層剝落嗎?本篇文章提供熱水瓶廠商的說明,並實際拆解熱水瓶了解其架構。

不只有MCU/MPU 瑞薩為Edge AI創新提供全方位支援
聚焦在語音(Voice)、即時分析(Real Time Analytics)與視覺(Vision)三大類技術,瑞薩在涵蓋工業、農業、交通、醫療保健、智慧家庭、消費性電子等廣泛領域的各種Edge AI應用都能游刃有餘;除了自有軟硬體技術,生態系夥伴的支援也扮演重要角色。
從流程圖到 Thunkable app:AI 影像識別
本文將接續系列前文,設計出能連結相機進行AI 影像識別的app。

【Maker電子學】Flash 記憶體的原理與應用—PART2(EEPROM)
本篇文章介紹可利用電子方法抹除再寫入的 EEPROM,包含其詳細運作原理與其並列式控制介面,說明它與現今的同步式介面有哪些不同。

輕鬆使用OpenVINO在本地裝置離線運作Llama3
利用OpenVINO部署Llama3到本地運算資源,例如AI PC,不僅意味著更快的回應速度和更低的運作成本,還能有效地保護資料安全,防止敏感資訊外洩。這對於需要處理高度敏感性資料的應用場景尤其重要,如醫療、金融和個人助理等領域。本文將介紹如何使用OpenVINO對Llama3模型進行最佳化和推論加速,並將其部署在本地裝置上,進行更快、更智慧的AI推論。
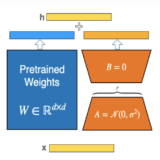
LoRA微調三步驟:以大語言模型MT5為例
本篇文章,將以MT5-small預訓練大模型為例,並以Python源碼(Source Code)來說明如何進行LoRA微調三步驟。

【Maker電子學】Flash 記憶體的原理與應用—PART1(NVM)
本篇文章為該系列的第一篇,主要先介紹非揮發性記憶體(Non-Volatile Memory)的發展過程。

具TinyML功效的開放硬體智慧錶專案:FryPi
開放硬體專案OV-Watch推出進階版的FryPi專案,它是以OV-Watch為基礎進行改進提升,這次希望一般初學者跟專業人士都能輕鬆運用,而且加入TinyML能力。本篇文章會簡單對此專案進行介紹。
【Maker電子學】Flash 記憶體的原理與應用—PART2(EEPROM)
本篇文章介紹可利用電子方法抹除再寫入的 EEPROM,包含其詳細運作原理與其並列式控制介面,說明它與現今的同步式介面有哪些不同。
輕鬆使用OpenVINO在本地裝置離線運作Llama3
利用OpenVINO部署Llama3到本地運算資源,例如AI PC,不僅意味著更快的回應速度和更低的運作成本,還能有效地保護資料安全,防止敏感資訊外洩。這對於需要處理高度敏感性資料的應用場景尤其重要,如醫療、金融和個人助理等領域。本文將介紹如何使用OpenVINO對Llama3模型進行最佳化和推論加速,並將其部署在本地裝置上,進行更快、更智慧的AI推論。
LoRA微調三步驟:以大語言模型MT5為例
本篇文章,將以MT5-small預訓練大模型為例,並以Python源碼(Source Code)來說明如何進行LoRA微調三步驟。

【Arm的AI世界】以ExecuTorch與TOSA讓PyTorch在Arm平台順利運作
Arm與Meta密切合作在ExecuTorch導入對Arm裝置的初步支援,以Tensor運算子集架構(TOSA)為基礎擷取類神經網路,並利用Ethos NPU在行動及嵌入式平台加速關鍵的ML工作負載…快來了解如何使用PyTorch及ExecuTorch以TOSA將圖形匯出至Arm平台!

用OpenVINO C# API部署YOLOv9目標檢測和實例分割模型
YOLOv9模型是YOLO系列即時目標檢測演算法中的最新版本,代表著該系列在準確性、速度和效率方面的又一次重大飛躍。在本文中,我們將結合OpenVINO C# API使用最新發佈的OpenVINO 2024.0部署YOLOv9目標檢測和實例分割模型。

【CAVEDU講堂】《Arduino首次接觸就上手》新手村教學:LED燈閃爍
本文將利用非常適合初學者的《Arduino首次接觸就上手》套件,帶領讀者快速掌握 Arduino 的基礎操作,完成一個 LED 燈閃爍專案。
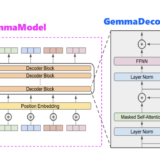
為什麼Gemma採取Decoder-Only Transformer架構呢?
本篇文章會說明Gemma為何會採取Decoder-Only Transformer架構,並針對Decoder-Only Transformer架構進行介紹。

如何從0訓練企業自用Gemma模型
Gemma模型是Text到Text的大型語言模型,非常適合各種文本生成任務。其有多種使用途徑,包括使用新資料來微調Gemma模型、拿Gemma開源程式碼,而從頭開始訓練它,本文將介紹如何從0訓練企業自用Gemma模型。

【Maker電子學】步進馬達的原理與驅動—PART10
步進馬達系列最終回,介紹步進馬達的控制的技巧:電流回授控制及閉環路控制。

Nvidia GTC 2024 提出的 FP8/FP4 如何加速AI訓練及推論
新一代 GPU Blackwell B200 在硬體端提供了 FP4 計算能力,單片就可達 20 petaFLOPS,二片 B200 組成的 GB200 在訓練性能是前一代 H100 的 4 倍,推論性能更高達 7 倍。若再將 36個 CPU 加上 72 個 GPU 組成「GB200 NVL72」超大型伺服器,則 FP8 訓練能力可高達 720 petaFLOPS, FP4 推論能力更高達1.44 exaFLOPS。而究竟什麼是 FP8 / FP4 呢?本篇文章會簡單幫大家科普一下。
線上學習