作者:Felix Lin

有在涉略AI邊緣運算的各位們對於OpenVINO應該都有基礎的了解:不同框架(如TensorFlow、PyTorch等)訓練完成的模型檔在經由OpenVINO轉換後可以在不同邊緣運算裝置執行推論加速。
若筆者告訴各位,現在不用經過模型轉換可以直接在TensorFlow中推論時完成OpenVINO加速呢?
是的你沒看錯!Intel在2021下半年推出的OpenVINO™ integration with TensorFlow(以下簡稱OVTF)能夠實現在TensorFlow中介接OpenVINO執行推論加速。本篇將帶大家實際操作看看在不用改code就能夠把TensorFlow推論進行加速的方法!
OpenVINO x TensorFlow 幸福來得太突然
對於TensorFlow開發者來說,只要在程式碼裡增加兩行就可以增加推論速度!什麼程式碼這麼神奇!?眼見為憑,這兩行指令如下:
openvino_tensorflow.set_backend('')
上面第一行嚴格來說不算指令,只是匯入了OpenVINO整合TensorFlow套件。而第二行呼叫了openvino_tensorflow設定後端運算硬體的指令,其中帶入的參數可以設定為CPU(Intel 處理器)、GPU(Intel處理器中的整合式顯示卡)、MYRIAD(AI加速晶片VPU)等。如此一來就已完成TensorFlow推論加速了。
而其特別之處從架構圖看來可以得知在原始TenorFlow與OpenVINO toolkit之間多增加了Operator Capability Manager (OCM)、Graph Partitioner、TensorFlow Importer與
Backend Manager,讓前述二者可以渾然天成的結合在一起。簡單來說在執行推論時會對神經網路各個運算進行判讀,是否能夠透過OpenVINO進行加速,並讓其對應到OpenVINO 的相應的運算子,最後分配到指定的後端硬體進行運算,反之若是不行加速的運算則讓其返回在TensorFlow中處理。
各別功能作用細節可從github repo與說明文件進行深入探究。若不了解這些技術細節也不要緊,參考模型支援文件可以得知各個TensorFlow模型(包含TF-Slim Classification、Object Detecion、TF-Hub等眾多來源)的支援程度,或是跟著我們接下來的步驟進行體驗一番!
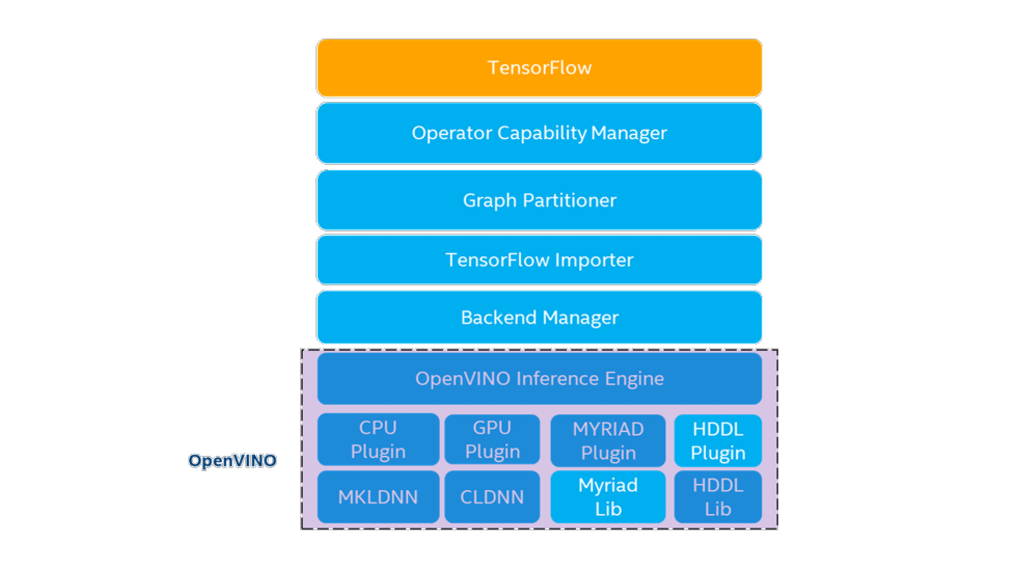
OpenVINO™ integration with TensorFlow架構圖
安裝OpenVINO™ integration with TensorFlow
此篇文章撰稿時OVTF的最新版本為V1.10,釋出時間是為2021年12月8日,OpeVINO核心版本是2021.4.2長期支援版本,搭配的TensorFlow版本為2.7.0。在TensorFlow2版本猶如飆車般的成長今年,還確實有跟上主要版本,算是相當有誠意。
筆者的開發環境是Ubnutu 20.04(搭配硬體為Intel Core i7-1185GRE),在終端機中執行以下指令,過程約花費兩分鐘內即可完成。
pip3 install -U pip
pip3 install tensorflow==2.7.0
pip3 install -U openvino-tensorflow
若讀者的開發環境是在Windows或MAC OS,也可以參照互動式安裝指令表來取得執行安裝所需執行的指令。完成安裝後可透過以下指令確認安裝正確:
python3 -c "import tensorflow as tf; print('TensorFlow version: ',tf.__version__);\
import openvino_tensorflow; print(openvino_tensorflow.__version__)"
會看到輸出結果如下則表示已安裝完成:
TensorFlow version: 2.7.0
OpenVINO integration with TensorFlow version: b'1.1.0'
OpenVINO version used for this build: b'2021.4.2'
TensorFlow version used for this build: v2.7.0
CXX11_ABI flag used for this build: 0
可以看到TensorFlow版本2.7.0,OpenVINO版本2021.4.2等資訊,往後有版本更新也可以此作為追蹤。若是輸出訊息中有出現:
Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
等錯誤訊息也毋須理會,這只是在檢測系統有無GPU硬體的過程,當偵測不到GPU則會出現此訊息。
OVTF範例試玩
在OVTF github專案中有附上立即可用的範例程式碼方便我們直接體驗與測試,在終端機下執行下面指令取得專案並且完成設置:
git clone https://github.com/openvinotoolkit/openvino_tensorflow.git
cd openvino_tensorflow
git submodule init
git submodule update --recursive
cd examples
pip3 install -r requirements.txt
完成之後指令後即可在openvino_tensorflow/examples目錄下執行影像分類Classification或是物件偵測Object Detection範例。首先我們先執行影像分類範例:
$ python3 classification_sample.py --no_show --backend CPU
...(中間省略)...
OVTF Summary -> 149 out of 910 nodes in the graph (16%) are now running with OpenVINO™ backend
Inference time in ms: 18.61
military uniform 0.6277221
bow tie 0.34492084
bearskin 0.006691128
theater curtain 0.0056200475
flagpole 0.0028387788
上方命令執行範例程式classification_sample.py將會抓取Grace Hopper照片,並使用Inception V3(ImageNet)模型進行推論,該模型也是取自於TF-Hub,使用推論引擎透過
參數指定為CPU,–no_show代表不顯示推論結果。可以看到輸出訊息中此模型有16%的節點可透過OpenVINO進行加速,推論時間花費18.61ms,推論結果62.7%為軍服。
我們也可以在參數中加上
來停用OpenVINO加速,也可以修改
參數為
或
來換成Intel GPU加速推論,藉此來比較加速前後差異(完整參數資訊可以透過
查詢)。
筆者使用固定Inception V3模型與相同輸入照片,切換不同後端推論硬體,其差異如下表。在沒有啟用OVTF需要費時26ms進行推論,若採用GPU並以FP16精度進行推論則可以節省一半以上時間縮短至12.54ms,若單純以CPU加速也能有縮短30%以上的時間!
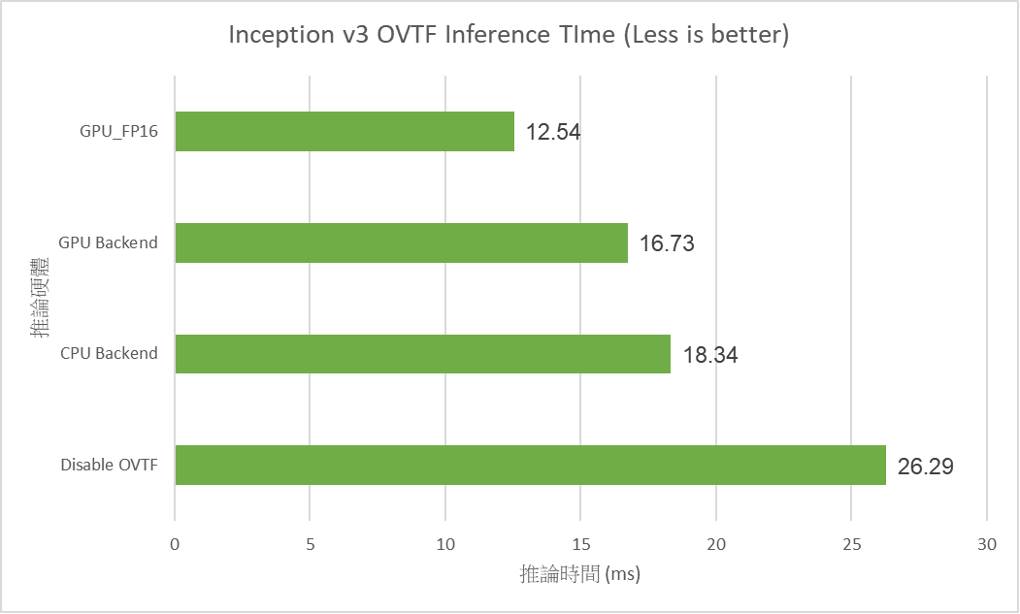
此外筆者將模型置換為Inception、Mobilenet、Resnet V2 152等四種不同模型,並比較停用OVTF與CPU加速之間的差異,確實發現在OVTF啟用後能提升30%~40%不等的堆論速度,其中Mobilenet V3 Large有29%的節點可以透過OVTF加速,因此效果最為顯著。

Object Detection with OVTF
接著我們也試玩一下物件偵測範例,在此範例中使用的模型為Yolo V4,可以偵測MS COCO資料集中80種物件。在執行之前我們需要把Yolo V4由Darknet轉換成TensorFlow的格式。
$ chmod +x convert_yolov4.sh
$ ./convert_yolov4.sh
筆者接上一個標準UVC介面的WEBCAM,加上
參數讓範例程式抓取Webcam即時影像,並選擇停用OVTF與GPU後端來比較兩者差異。
#disable OVTF
python3 object_detection_sample.py --input=0 --disable_ovtf
#backend=GPU
python3 object_detection_sample.py --input=0 --backend GPU
實際運行可以看到在沒啟用OVTF時每個frame花費超過400ms,而在啟用後可以縮短到94ms,差異超過四倍!
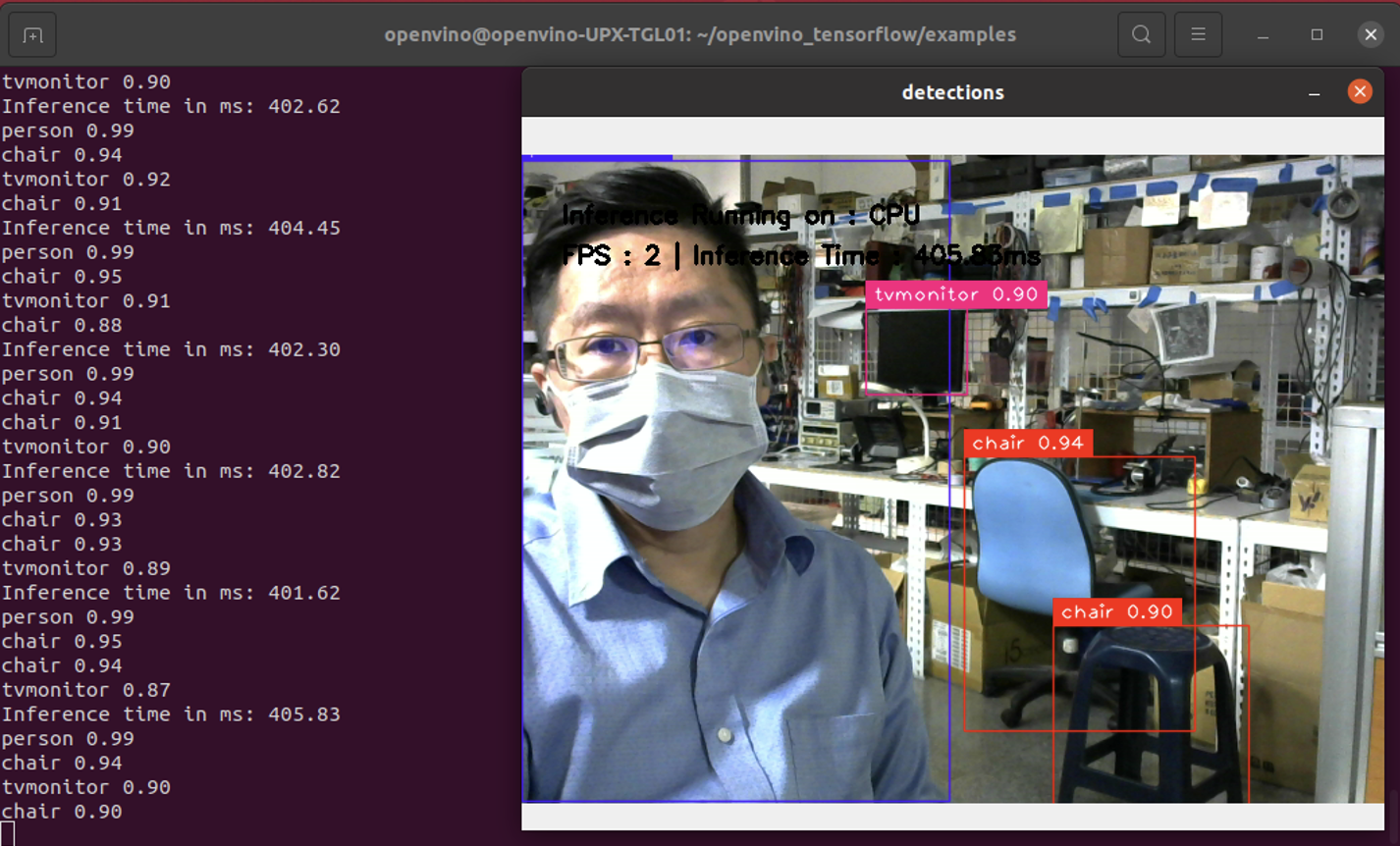
Webcam Object Detection /w TF Inference @FPS:2
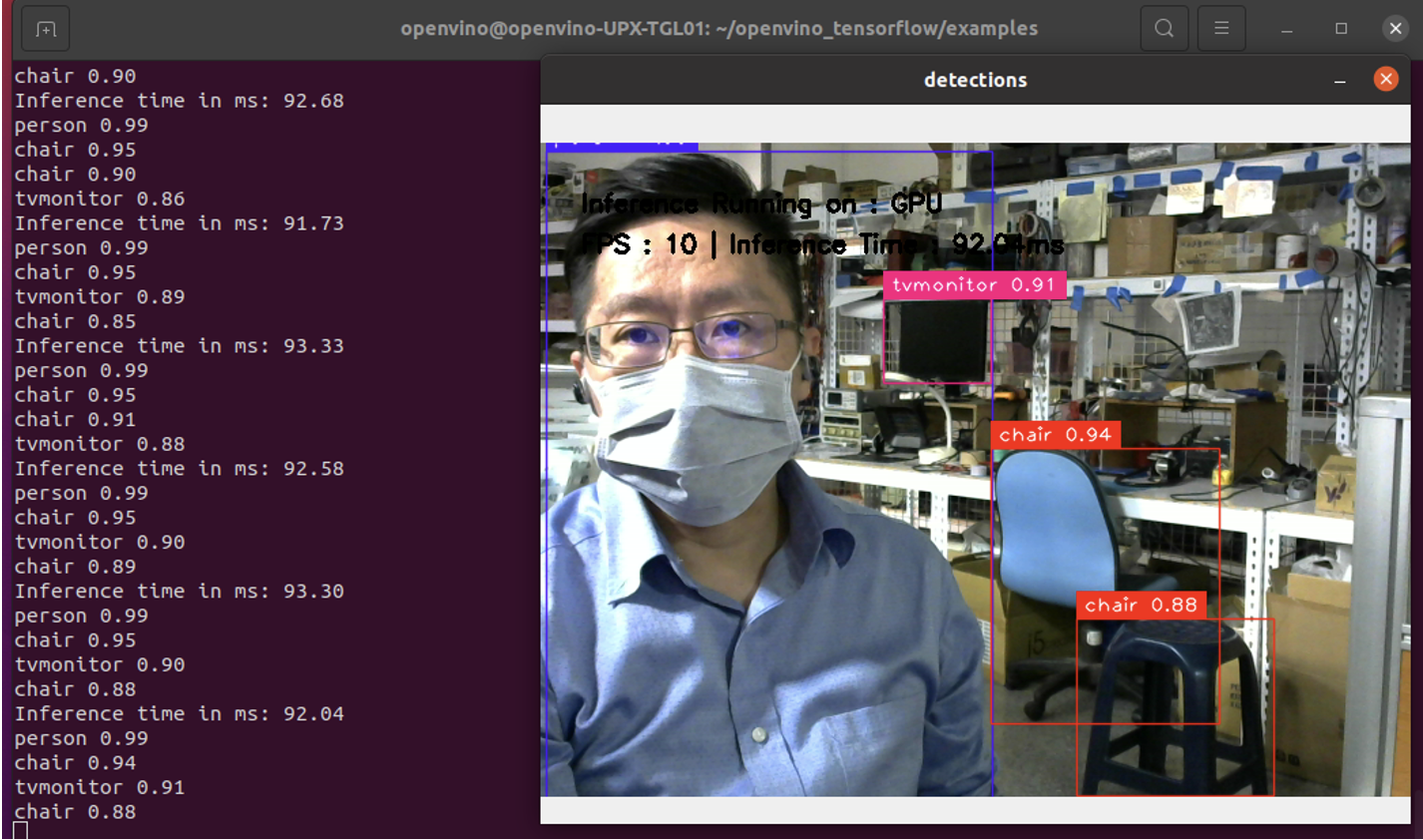
Webcam Object Detection /w OVTF GPU Inference @FPS:10
Running Example on Colab
若是手邊沒有合適的開發環境可以來測試也沒關係,OVTF專案中也提供了兩個notebook檔案可以直接在Colab上運行測試,分別為影像分類與物件偵測範例。我們直接執行物件偵測範例中所有程式碼區段來檢視成果,可以看到在於有啟用OVTF(後端硬體為CPU)的推論時間為946ms,相較於無啟用OVTF花費了1258ms減少了25%的推論時間!

Colab物件偵測範例啟用OVTF與關閉OVTF之間差異
小結
這次Intel所推出的OpenVINO™ integration with TensorFlow專案雖然說不上是個殺手級工具,但也紮紮實實搔到了AI開發者的癢處!過往訓練完成AI模型後要進行推論驗證,仍需要花費不少心力去轉換與測試,而OVTF則大幅削去了開發階段與佈署階段所隔著的鴻溝,直接在開發者熟悉的環境中就能估算實際佈署的效能概況。
筆者也是相當期待後續OVTF是否還能衍生出什麼方便好用的功能,又或者是針對其他深度學習框架也能有類似的整合,就讓我們繼續看下去!
(責任編輯:謝涵如)

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


