作者:CAVEDU 教育團隊
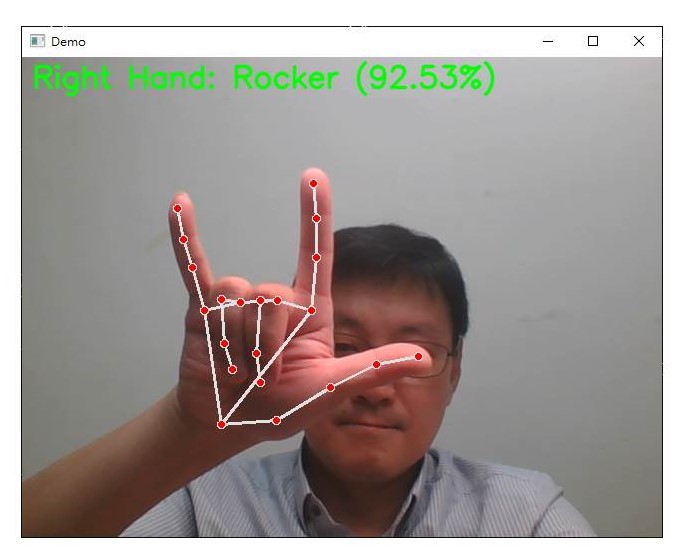
當我們想進行多手勢的辨識時,選擇僅用距離條件式的判斷相對於使用 SVM模型來說,存在一些明顯的限制和問題。以下是這兩種方法的比較:
- 複雜性與可維護性:距離條件式判斷:當手勢增多或變得複雜,你可能需要設定更多的條件和閾值。這不僅使得程式碼複雜、難以維護,而且很難確保每個條件都是正確的。SVM模型:透過機器學習,模型會從數據中學習如何正確區分手勢,而不是依賴手工設定的條件。
- 泛化能力:距離條件式判斷:可能只適用於特定的用戶和情境。例如,不同人的手大小、形狀不同,所以使用固定的距離閾值可能不適用於所有人。SVM模型:經過適當的訓練,模型可以學習到更普遍的、不依賴於特定人或情境的手勢特徵。
- 容錯能力:距離條件式判斷:僅基於距離的判斷可能非常敏感,一點點的誤差或變動都可能導致錯誤的分類。SVM模型:這些模型通常對於輸入的小變化有一定的容忍度,因此提供了更好的容錯能力。
- 擴展性:距離條件式判斷:若想新增手勢,你可能需要重新寫或調整大量的條件式,這是非常耗時和容易出錯的。SVM模型:只需增加新的訓練數據,然後重新訓練模型。
- 動態和變異性:距離條件式判斷:固定的條件很難捕捉手勢間的微妙差異或動態變化。SVM模型:可以捕捉和學習多種特徵的組合,並更好地處理手勢的動態和變異性。儘管使用距離條件式判斷在某些簡單的情境下可能是可行的,但對於多手勢或複雜的手勢識別,使用 SVM模型是一種更為強大、靈活和可靠的方法。
SVM
SVM 是一個強大的機器學習模型,特別適合於分類問題。它的設計理念和數學基礎使其在許多情境下都能提供出色的性能,特別是當數據具有複雜的邊界或當需要進行多類別的分類時,針對「支援向量模型」SVM (Support Vector Machines) 模型的特點進行的概述:
1. 泛化能力:
SVM 被設計來找到最大的邊界,使其在多類別的數據集上具有很好的泛化能力。這意味著一旦模型經過適當的訓練,它可以有效地對新的、未見過的數據進行預測。
2.容錯性:
SVM 透過找到最佳的超平面來分隔資料,這使得它具有一定的容錯性。也就是說,即使有一些數據點不完美地位於邊界的正確一側,SVM 仍然可以找到一個合適的超平面。
3.處理高維數據:
SVM 可以有效地處理高維數據。在手勢識別的情境下,每一個手部標誌點可以提供多維的資料,而 SVM 能夠很好地處理這種情況。
4.核技巧:
SVM 的一個重要特性是它可以使用所謂的核函數來處理非線性數據。即使數據在原始空間中不是線性可分的,SVM 仍然可以找到一個合適的邊界來分隔它。
5.模型簡潔:
與某些其他的機器學習模型相比,SVM 傾向於產生比較簡潔的模型。這是因為 SVM 只依賴於支持向量(即那些位於邊界附近的數據點)來定義分隔邊界。
6.可擴展性:
儘管 SVM 在非常大的數據集上可能比其他模型更加計算密集,但它仍然是可擴展的。當訓練集變得非常大時,還有一些優化的 SVM 變種可以使用。
MediaPipe 結合 SVM
使用 MediaPipe 來捕捉手部標誌點,再結合 SVM 進行手勢識別,具有以下優勢:
1.即時性:
MediaPipe 是一個專為高效能而設計的框架,能夠即時捕捉和分析影像串流中的手部標誌點。
2.實用性:
SVM 是一個相對輕量級的模型,當訓練完畢後,對於新數據的預測是非常快速的。結合兩者,我們可以獲得實時且流暢的手勢識別。
3.簡易性:
使用 MediaPipe 進行手部跟踪意味著不需要從頭開始訓練一個深度學習模型來識別手部或其標誌點,節省了大量時間和資源。
4.直觀性:
SVM 是一個經典的機器學習模型,相對於深度學習模型,其原理和實現都更為簡單和直觀。
5.靈活性:
MediaPipe 提供的手部標誌點數據可以轉化為多種特徵,例如指尖之間的距離、手部各部位的角度等。這些特徵可以容易地餵入 SVM 或其他模型進行學習。
6.低資源需求:
SVM 不需要像深度學習模型那樣的大量運算資源,對於邊緣設備或資源有限的情境,例如行動裝置,這是非常有益的。
7.可解釋性:
SVM,尤其是使用線性核的版本,提供了較好的解釋性。這意味著可以較容易地了解哪些特徵是對模型最有影響的,這對於了解和優化手勢識別過程是有價值的。
8.可擴充性:
如果在初步的研究或原型階段使用 MediaPipe 和 SVM 證明了手勢識別的有效性,那麼未來可以容易地升級到更複雜的深度學習模型,以提高精度或識別更多的手勢。
認識SVM模型
透過下圖來進行SVM模型特性的說明,我們假設紅色和藍色的數據點代表不同的手勢關節彎曲幅度的資料。
由於手勢在攝影鏡頭前面的距離或位置不一定都是穩定的,因此會產生手勢關節座標的辨識誤差,但由於特定的手勢其關節彎曲幅度是有一定的趨勢規則,因此會產生測量數據的「群聚趨勢」,透過SVM模型建立的超平面區隔演算法,可以將紅色或藍色兩個不同手勢的群聚趨勢加以區隔。
透過這樣的區隔演算法,在實際的影像辨識推論階段便可以透過區隔區域的差異或是群聚中心的距離,得知手勢的差異(群聚區域的不同),以及手勢辨識精確度(與群聚中心的距離),這樣的做法可以讓使用者不需要精確計算各手勢關節的座標相對關係,透過SVM模型便可以讓使用者更加彈性的操作,也因為這樣的操作便利性,讓使用者可以豐富多樣化想要辨識的手勢種類。
測試流程說明
接著來逐步說明如何完成本範例所需的各個功能吧,完成程式碼如本文最後。
一、 蒐集訓練資料
輸入手勢類別標籤名稱。
按下空白鍵後開始蒐集手勢資料。
蒐集手勢資料10秒,畫面會出現倒數計時秒數。
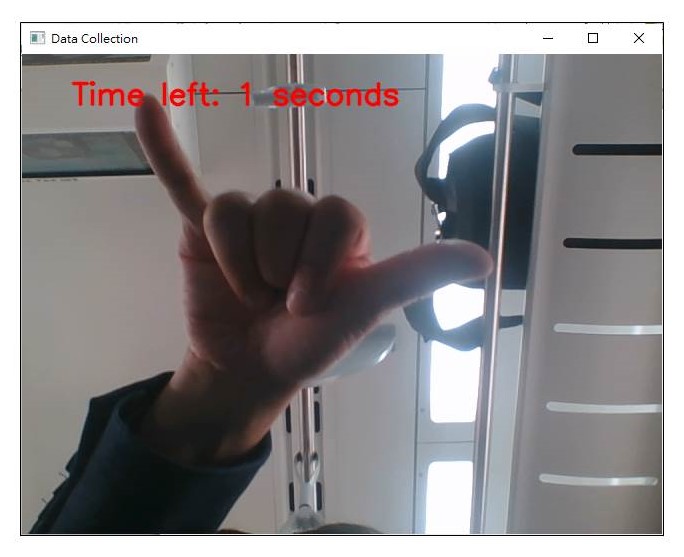
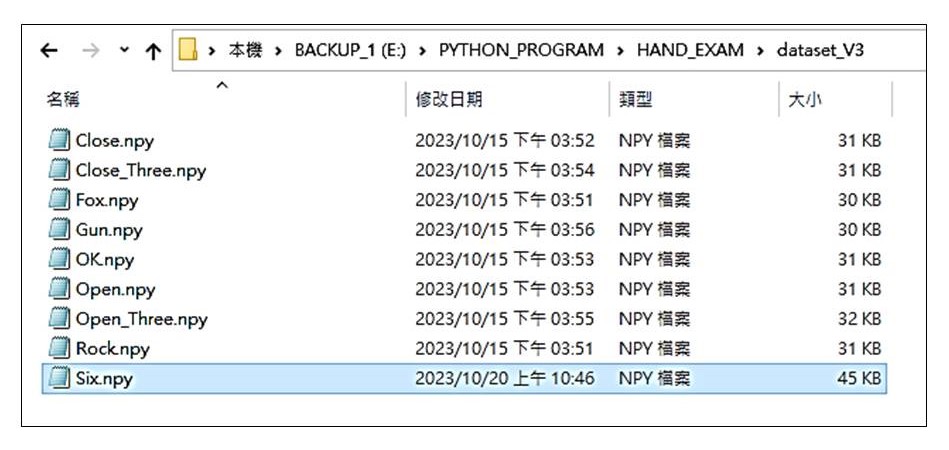
針對各種手勢資料進行紀錄,檔案名稱就是手勢類別標籤名稱。
二、 SVM模型訓練
透過SVM線性分類模型開始進行模型訓練。
 訓練完成後會產生SVM模型檔、比例記錄檔、類別名稱標籤檔,如下圖紅框。
訓練完成後會產生SVM模型檔、比例記錄檔、類別名稱標籤檔,如下圖紅框。

三、 影像實際測試
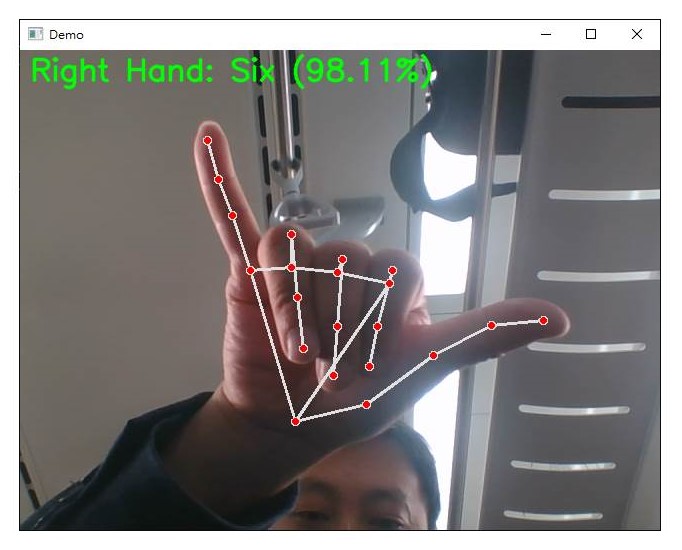
識別出手勢:Six
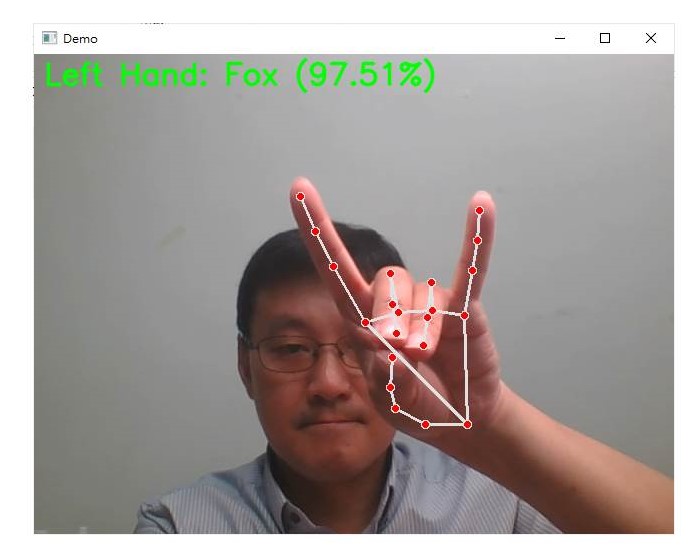
識別出手勢:Fox
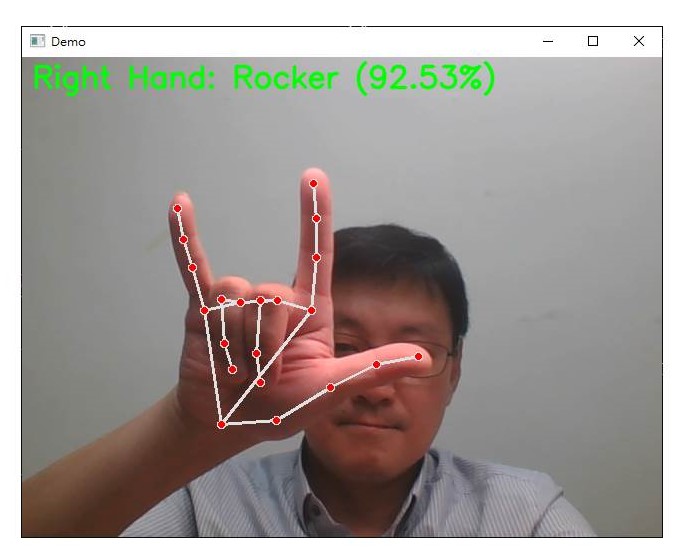
識別出手勢:Rocker
程式碼:
安裝好相關套件之後,請於終端機中執行以下程式即可,分成三個步驟
Data_Collect_V3.py 收集資料
Train_Model_V3.py 訓練模型
Demo_V3_Multi.py 即時手勢辨識
Data_Collect_V3.py (收集資料)
import cv2
import mediapipe as mp
import numpy as np
import time
import os
# Initialize mediapipe Hands
mp_hands = mp.solutions.hands
hands = mp_hands.Hands()
def compute_distances(landmarks):
distances = []
# Define pairs for distance calculation
pairs = [(0, 1), (0, 2), (0, 3), (0, 4),
(0, 5), (0, 6), (0, 7), (0, 8),
(0, 9), (0, 10), (0, 11), (0, 12),
(0, 13), (0, 14), (0, 15), (0, 16),
(0, 17), (0, 18), (0, 19), (0, 20),
(4, 8), (8, 12), (12, 16), (16, 20)]
reference_pair = (0, 9)
p_ref1 = np.array([landmarks.landmark[reference_pair[0]].x, landmarks.landmark[reference_pair[0]].y])
p_ref2 = np.array([landmarks.landmark[reference_pair[1]].x, landmarks.landmark[reference_pair[1]].y])
reference_distance = np.linalg.norm(p_ref1 - p_ref2)
for pair in pairs:
p1 = np.array([landmarks.landmark[pair[0]].x, landmarks.landmark[pair[0]].y])
p2 = np.array([landmarks.landmark[pair[1]].x, landmarks.landmark[pair[1]].y])
distance = np.linalg.norm(p1 - p2) / reference_distance
distances.append(distance)
return distances
# Ask user for filename
filename = input("Please enter the filename for data: ")
save_path = "dataset_V3/" + filename
# Check if the 'dataset' directory exists, if not, create it
if not os.path.exists("dataset_V3"):
os.makedirs("dataset_V3")
cap = cv2.VideoCapture(0)
data_collection = []
collecting = False
start_time = None
while True:
ret, frame = cap.read()
if not ret:
continue
if not collecting:
cv2.putText(frame, "Press SPACE to start data collection", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2, cv2.LINE_AA)
else:
elapsed_time = int(time.time() - start_time)
remaining_time = 10 - elapsed_time
cv2.putText(frame, f"Time left: {remaining_time} seconds", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA)
if elapsed_time >= 10:
break
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
if results.multi_hand_landmarks and collecting:
for landmarks in results.multi_hand_landmarks:
distances = compute_distances(landmarks)
data_collection.append(distances)
cv2.imshow("Data Collection", frame)
key = cv2.waitKey(1)
if key == 32 and not collecting:
collecting = True
start_time = time.time()
elif key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# Convert the data_collection list to numpy array and save
np.save(save_path, np.array(data_collection))
print(f"Data saved to {save_path}")
Demo_V3_Multi.py (手勢辨識)
import cv2
import mediapipe as mp
import numpy as np
import joblib
# Initialize mediapipe Hands Detection
mp_hands = mp.solutions.hands
hands = mp_hands.Hands()
# Load the SVM model and scaler
model_filename = "svm_model_V3.pkl"
clf = joblib.load(model_filename)
scaler_filename = "scaler_V3.pkl"
scaler = joblib.load(scaler_filename)
# Load labels
label_file = "labels_V3.txt"
with open(label_file, 'r') as f:
labels = f.readlines()
labels = [label.strip() for label in labels]
def compute_distances(landmarks):
# Define pairs for distance calculation
pairs = [(0, 1), (0, 2), (0, 3), (0, 4),
(0, 5), (0, 6), (0, 7), (0, 8),
(0, 9), (0, 10), (0, 11), (0, 12),
(0, 13), (0, 14), (0, 15), (0, 16),
(0, 17), (0, 18), (0, 19), (0, 20),
(4, 8), (8, 12), (12, 16), (16, 20)]
distances = []
reference_distance = np.linalg.norm(
np.array([landmarks.landmark[0].x, landmarks.landmark[0].y]) -
np.array([landmarks.landmark[9].x, landmarks.landmark[9].y])
)
for pair in pairs:
p1 = np.array([landmarks.landmark[pair[0]].x, landmarks.landmark[pair[0]].y])
p2 = np.array([landmarks.landmark[pair[1]].x, landmarks.landmark[pair[1]].y])
distance = np.linalg.norm(p1 - p2)
distances.append(distance/reference_distance) # Normalize the distance using the reference distance
return distances
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = hands.process(rgb_frame)
if results.multi_hand_landmarks:
for index, landmarks in enumerate(results.multi_hand_landmarks):
# Distinguish between left and right hand
hand_label = "Right" if results.multi_handedness[index].classification[0].label == "Left" else "Left"
distances = compute_distances(landmarks)
distances = scaler.transform([distances])
prediction = clf.predict(distances)
confidence = np.max(clf.predict_proba(distances))
label = labels[prediction[0]]
display_text = f"{hand_label} Hand: {label} ({confidence*100:.2f}%)"
cv2.putText(frame, display_text, (10, 30 + (index * 40)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2, cv2.LINE_AA)
# To visualize the landmarks of the hand
mp.solutions.drawing_utils.draw_landmarks(frame, landmarks, mp_hands.HAND_CONNECTIONS)
cv2.imshow('Demo', frame)
if cv2.waitKey(1) & 0xFF == 27: # ESC key
break
cap.release()
cv2.destroyAllWindows()
參考資料
[累累累] Google Mediapipe 深蹲偵測,結合 Arduino 首次接觸就上手
[手勢辨識應用] Google Mediapipe 手勢控制LED呼吸燈
Raspberry Pi 安裝 Google Mediapipe,3分鐘完成!

- 【CAVEDU講堂】micro:bit V2使用TCS34725顏色感測器模組方法 - 2025/06/27
- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


