當人工智慧(AI)成為新時代的「電力」與「算力即國力」的代名詞時,台灣正站在歷史的十字路口。過去,我們以半導體硬體供應全世界的運算需求;現在,面對生成式 AI 帶來的文化與資安風險,台灣正式宣告進入「主權 AI」元年。透過 TAIDE 模型、算力擴張與法制建立,我們試圖在美中兩大強權的演算法夾縫中,打造出屬於自己的數位大腦。
定義主權 AI — 為什麼台灣不能只有硬體?
在 2023 年 ChatGPT 橫掃全球後,各國政府驚覺,若核心的 AI 技術與數據完全依賴外國企業,將面臨嚴重的「數位殖民」風險。例如當我們向國外主流 AI 詢問台灣的法律義務、地理環境或歷史定位時,往往會得到「簡轉繁」的語法或是帶有外部偏見的回答。因此,對於台灣而言,主權 AI(Sovereign AI)不只是一個科技術語,更是國家安全的防線。
為此,政府正式將主權 AI 列為國家級戰略。主權 AI 的核心在於:國家的數據應該留在境內、由本土人才訓練、運行在自主的算力設施上,並最終服務於本國的公共利益。台灣擁有全球最完整的半導體供應鏈,具備發展 AI 硬體的絕對優勢,但在軟體與模型層次,則需要更具主導性的佈局。
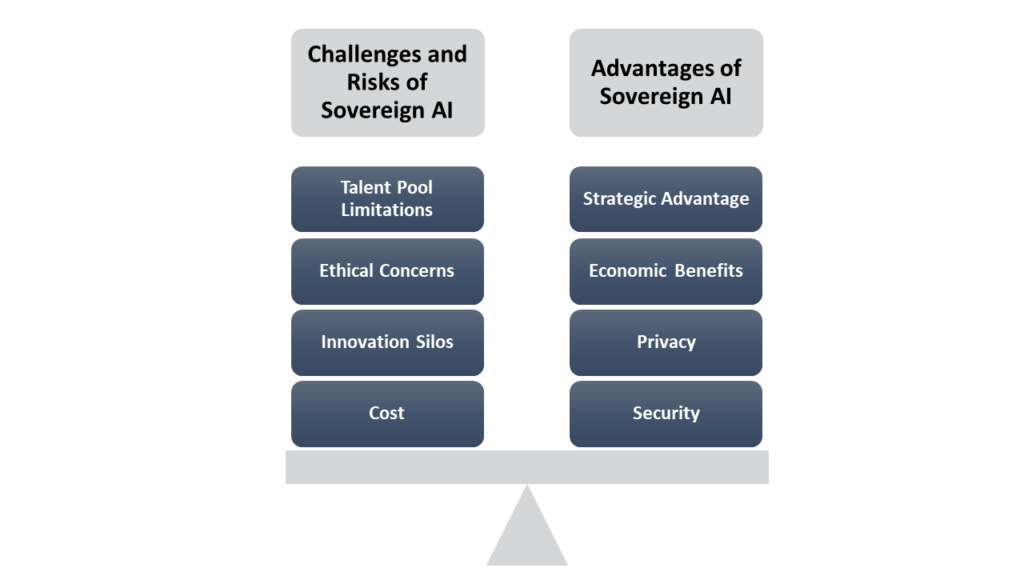
主權AI的挑戰與優勢(source)
》延伸閱讀:The Rise of Sovereign AI: A Technological Race with National Stakes
自己的大腦 — TAIDE 模型的開發與定位
台灣推動主權 AI 的第一步,就是由國科會主導的「TAIDE」(可信任人工智慧對話引擎)計畫。這項計畫結合了學界與產業界的力量,目標是開發出一個「懂台灣話」的大型語言模型。

TAIDE 與 ChatGPT 最大的不同在於其「純度」。它使用台灣特有的在地資料作為訓練語料,包括政府公開公報、本土新聞媒體、學術研究論文以及在地文學作品。這確保了模型在處理繁體中文時,不會出現「屏幕」、「視頻」等中國大陸用語,更能精準處理台灣特有的法律術語與行政流程。目前 TAIDE 已從最初的 7B 模型進化至更強大的版本,並正式對外釋出,提供給政府機關與企業作為開發基礎。
算力的軍備競賽 — 國家級運算中心的擴張
若說模型是大腦,算力就是維持大腦運轉的能源。台灣過去雖有超級電腦「台灣杉」系列,但在生成式 AI 所需的高密度 GPU 運算上,仍有升級空間。為了支援主權 AI 的發展,國網中心(NCHC)正進行大規模的基礎設施升級。
以下是目前台灣在 AI 基礎設施與策略佈局的具體比較:
| 發展維度 | 具體策略與行動內容 | 預期目標 |
|---|---|---|
| 基礎模型 (TAIDE) | 採用 Llama 系列架構,導入台灣在地高品質語料(新聞、法律、文學)進行微調。 | 建立具台灣文化主體性的 AI,解決語法與事實偏誤。 |
| 算力資源 (Compute) | 擴大國網中心 AI 主機建置,採購 NVIDIA H100/B200 晶片,建構「晶創主機」。 | 提供產學研界充足算力,確保關鍵運算不需移至境外雲端。 |
| 法制規範 (Law) | 於 2026 年正式實施《人工智慧基本法》,確立倫理、資安與風險分級。 | 提供產業發展的法律穩定性,保障國民隱私與數位人權。 |
| 數據治理 (Data) | 建立「台灣主權 AI 訓練語料庫」,推動政府與民間語料授權機制。 | 解決 AI 訓練的著作權爭議,確保模型學習資料的合法來源。 |
| 人才與應用 (App) | 推動「百工百業 AI 化」,補助中小企業導入邊緣 AI 與私有雲。 | 提升國家整體生產力,將 AI 優勢轉化為經濟產值。 |
法律的疆界 — 《人工智慧基本法》的里程碑
在技術狂飆的同時,台灣政府深知若無法律框架,AI 的發展可能引發社會疑慮。2026 年初正式施行的《人工智慧基本法》,是台灣主權 AI 戰略中最重要的軟實力藍圖。這部法律不只是規範,更是引導。
新法中規定,政府推動人工智慧研發與應用,應在兼顧社會公益、數位平權、促進創新研發與強化國家競爭力之前提,並遵循永續發展與福祉、人類自主、隱私保護與資料治理、資安與安全、透明與可解釋、公平與不歧視、問責等7大原則。
為了避免人工智慧應用造成侵害,基本法條文中規定,政府應避免人工智慧的應用,有侵害人民生命、身體、自由或財產,破壞社會秩序、國家安全或生態環境,或偏差、歧視、廣告不實、資訊誤導或造假等違反相關法規之情事。
特別的是,該法要求政府成立「國家人工智慧戰略特別委員會」,這是一個跨部會的決策中心,負責協調數位發展部、國科會與經濟部之間的資源分配。此外,法律中明確定義了「風險分類框架」,對於涉及國安、醫療或金融的高風險應用,採取更嚴格的審查標準,這不僅是為了保護民眾,更是為了讓台灣的 AI 環境能與歐盟的《AI Act》接軌,爭取國際信任。

具體行動與落實 — 從中央到地方的全面動員
為了達成主權 AI 的目標,台灣政府採取了以下具體行動:
1. 建立「國家語料庫」:
數位發展部推動語料授權機制,解決過去 AI 模型訓練常面臨的版權灰色地帶。透過與主流媒體、學術機構簽署授權協議,確保 TAIDE 及其衍生的模型能夠使用合法、高品質的繁體中文語料,這對於保護台灣的文化多樣性至關重要。
2.推動「邊緣運算(Edge AI)」應用:
考慮到許多企業擔心數據上傳到雲端的隱私風險,政府大力補助發展邊緣運算技術。讓 AI 不必在遠端的大型伺服器運行,而是在工廠、醫院或辦公室內的微型主機上直接運算。這不僅符合「主權 AI」數據留境內的精神,也發揮了台灣在硬體終端設備上的強項。
除了中央的政策,地方政府也積極響應。例如南部科學園區與高雄亞灣區,正轉型為「AI 實證場域」。這些地區結合了 5G 專網與主權 AI 模型,應用於智慧港口監控、精準農業噴灑以及自動化災害防護系統。這種從模型研發到場域落實的完整鏈條,正是台灣主權 AI 能否成功的關鍵。
結語
「台灣不僅能為世界製造 AI,更能用 AI 定義台灣。」這是主權 AI 戰略的核心願景。
主權 AI 的發展不是為了閉關自守,而是為了在開放的國際合作中,握有對等的談判籌碼。當台灣擁有自主的模型與算力,我們便能確保國家的運作不會因為地緣政治的變動而停擺。
(責任編輯:歐敏銓)

- 機器人開發環境邁入「標準化、開源化、端對端」新時代 - 2026/07/21
- 人形機器人站上手術檯動刀的最後一哩路 - 2026/07/13
- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


