作者:曾成訓(CH.TSENG)
Colab 最長的執行時間為 12 小時,但訓練 YOLO 通常都要來長達數天以上,因此在下方的步驟中,我們建立一個專用的 Colab disk 空間,讓每次重新執行 Colab 時,不會遺失訓練結果,更可以很快設定好訓練環境並從上次中斷的地方繼續訓練。
如果使用 transfer learning,例如使用已訓練好的麵包 weights 來訓練新的麵包種類,那麼訓練時間可大幅縮短,僅需數個小時到半天的時間,因此很適合使用 Colab。
由於需要將 dataset 上傳到 Google Drive,且訓練過程中會持續的產生 weights 檔(可以設定多少次 epochs 產生一個 weights),因此免費的 Google Drive 空間很快就會耗盡,您可能需要購買額外的空間,例如每月 NT $90 可擴增到 200 GB。
用Colab的免費GPU訓練YOLO
- 建立 Colab 專用的 disk 空間
在您的 Google Drive 建立一個 folder 專門給 Colab 使用。下方的例子中,我在最上層建了一個space_Colab。
(圖片來源:曾成訓提供)
接著,把你打算要訓練的 dataset(PASCAL-VOC format)上傳到此目錄下。
- 將 Colab 加入 javascript whitelist
Chrome:設定🡪網站設定🡪Javascript,將下列三個網域加入 white list,讓 Colab 頁面可長時間持續得執行而不會產生 javascript error。

(圖片來源:曾成訓提供)
Colab的限制
如果你在 Colab 輸入下方的指令,會看到目前提供的 GPU 型號是 Tesla P100,而且還是 16 GB 的版本!
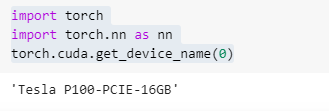
(圖片來源:曾成訓提供)
Tesla P100 發表於 2016 年,有 3584 個 CUDA Core,首發價格為 5,699 USD,其與 Nvidia 各系列 GPU 的性能表現比較,可參考這篇文章。
雖然 Tesla P100 在高精度 FP64 上的表現仍獨佔鼇頭,但在較低精度的表現已比不上較新的 GPU 如 2080 Ti,但是其實它用在深度學習的訓練上仍相當合適,尤其是 16 GB 這麼大的記憶體可讓我們在訓練時設定更大的 training batch,加快訓練的速度,然而想要使用這免費又超強的 GPU,利用它在 Colab 上訓練大型的 dataset,首要解決的是兩個問題:
- 12小時的使用時間限制
- Google Drive 的讀取限制
針對第一點的時間限制,我們可以先在 Google Drive 建立一個資料夾,將所有要訓練的 dataset 上傳到此空間,然後將該 folder mapping 到 Colab 來使用。當然除了 dataset,訓練過程中會用到與可能產生的檔案也必須放置於資料夾,當訓練時間超過了 12 小時的時間限制,我們只要重新啟動該 Colab 頁面,便可讀取上次的 weights 檔繼續訓練。
至於第二點 Google Drive 的檔案讀取限制,是指 Colab 持續讀取 Google Drive 檔案數目(約在 7000~8000左右),如果太多會 Time out 並出現 Input/Output error 的訊息,像是我打算建一個有 15,000 的資料夾,就出現了 error 訊息。

解決方式是將這些檔案放散到子目錄下,讓單一目錄的檔案數目不要過大,這樣讀取時就不會產生 Time out error。
Colab與本地端的路徑保持一致
如果我們把本地端的環境配置得和雲端的 Colab 一樣,就可以在本地端先產生需要的 dataset 和設定檔後,上傳 Google Drive 直接在 Colab 上訓練,這樣自由切換在 Colab 或本地端訓練或執行,可以增加兩者併用的方便性。
所謂環境的一致指的是 Colab 和本地端的檔案路徑。當 Colab map 到 Google Drive 的資料夾後,我們可以用 soft link 的方式,將它指向另一個 path,來讓這個 path 與本地端的 path 格式一樣;舉例來說,本地端的 dataset path 為 /WORK1/dataset,Colab 存取 Google Drive dataset 的 path 也是 /WORK1/dataset。
預設 Google Drive mount 到 Colab 的 path 為 /content/gdrive/My Drive,但我們使用下面第三行的 ln -s 將 /WORK1 指向 /content/gdrive/My Drive,Colab 便能與本地端使用相同的 /WORK1/dataset 路徑,存取 /content/gdrive/My Drive/dataset。
在 Colab 端執行:
from google.colab import drive
drive.mount(‘/content/gdrive’, force_remount=True)
!ln -s ‘/content/gdrive/My Drive/space_Colab’ /WORK1
實際案例操作
在 Colab 使用官方版 YOLO 訓練 CrowdHuman Dataset
1. CrowdHuman Dataset下載及轉檔
請從官網下載 dataset,這個不需申請,下載解壓後其檔案架構如下。該 dataset 使用的並非我們熟悉的PASCAL VOC 格式,您可請將其轉為 VOC 檔格式,也可以不轉換另外撰寫程式直接讀取其標記檔。
原 dataset 架構:
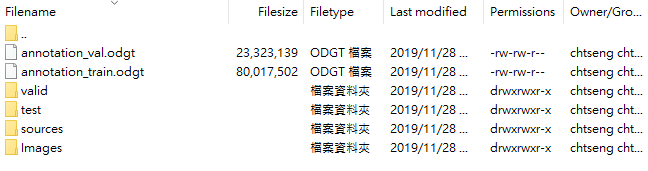
(圖片來源:曾成訓提供)
轉檔後的 dataset 架構:

(圖片來源:曾成訓提供)
2. 產生訓練用的 YOLO dataset 並減少單一資料夾檔案的數目
將 PASCAL dataset 轉為 YOLO dataset 格式,作法可以請參考如何快速完成 yolo-v3 訓練與預測這篇文章。最後產生給 YOLO 訓練用的圖片及標記會放在於同一資料夾中,總數共有 30,000 筆(15,000張 jpg 圖片和 15,000 個標記 txt 檔),但由於數目太大會讓 Colab 在讀取時產生 Time out 的錯誤,因此必須將這些檔案分散到子資料夾中。
請執行下方的程式,就可將這 30,000 筆的資料分散到 15 個資料夾中(每個資料夾設定為 2,000 筆)。
import glob, os
import os.path
import shutil
#YOLO folder must has: *.jpg and *.txt
img_count_total = 40000 #more than real number is ok
source_image_type = ".jpg"
source_yololabel_type = ".txt"
file_count_in_folder = 1000
source_dataset = "/DATA1/Datasets_mine/labeled/crowd_human_dataset/yolo2/yolo"
target_dataset = "/WORK1/dataset/CrowdHuman_YOLO_10_folders"
if not os.path.exists(target_dataset):
os.makedirs(target_dataset)
for loop_folder in range(int(img_count_total/file_count_in_folder)+1):
print("Loop count #{}".format(loop_folder))
for i, file in enumerate(glob.iglob(os.path.join(source_dataset, "*"+source_image_type))):
if(i>=file_count_in_folder):
break
filename = os.path.basename(file)
file_mainname, file_extension = os.path.splitext(filename)
source_img_file = os.path.join(source_dataset, filename )
source_txt_file = os.path.join(source_dataset, file_mainname + source_yololabel_type )
new_folder = os.path.join(target_dataset, str(loop_folder))
if not os.path.exists( new_folder ):
os.makedirs(new_folder)
target_img_file = os.path.join(new_folder, filename )
target_txt_file = os.path.join(new_folder, file_mainname + source_yololabel_type )
try:
print("#{}/{} move {},{}...".format(loop_folder, i, filename, file_mainname + source_yololabel_type))
shutil.move(source_img_file, target_img_file)
shutil.move(source_txt_file, target_txt_file)
except:
print("#{}/{} move filed".format(loop_folder, i))
continue

(圖片來源:曾成訓提供)
3. 產生訓練用的 YOLO dataset 及設定檔
此步驟要產生 YOLO 訓練時需要的 train.txt、test.txt、obj.data、obj.names、YOLO.cfg,作法同樣請參考如何快速完成 yolo-v3 訓練與預測這篇文章。
4. 將 YOLO dataset 及設定檔上傳 Google Drive
前一步驟會產生兩個資料夾,一個是 YOLO dataset,一個是設定檔,都要上傳到 Google Drive。
首先在 Google Drive 建立一個資料夾(命名可自取,這邊取為 space_Colab),之後將 YOLO dataset 資料夾上傳到 space_Colab,最後再將設定檔資料夾上傳到 space_Colab。
5. 下載官方版 Darknet 到 Google Drive
先新增一 Colab 頁面,指定為使用 GPU(Runtime 🡪 Change runtime type)
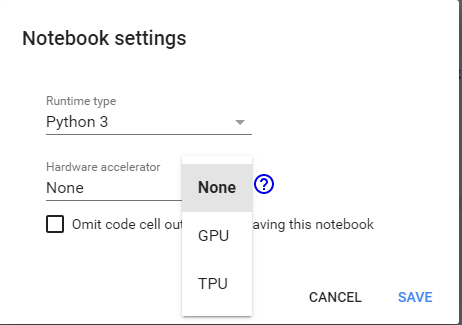
(圖片來源:曾成訓提供)
執行下方的指令,將 Darknet 程式下載到 Google Drive。
import os from google.colab import drive drive.mount(‘/content/gdrive’, force_remount=True) %cd “/content/gdrive/My Drive/space_Colab" git clone https://github.com/pjreddie/darknet
下載完成後,修改 darknet 的 Makefile,將參數修改為如下:
GPU=1 CUDNN=1 OPENCV=1 OPENMP=0 DEBUG=0
存檔後,進入 darknet 目錄下執行 make。
%cd darknet !make
6. 在 Colab 測試 YOLO
開一新的 Colab 頁面,執行下列的程式:
#連接Google Drive from google.colab import drive drive.mount(‘/content/gdrive’, force_remount=True) #指向/WORK1 !ln -s ‘/content/gdrive/My Drive/space_Colab’ /WORK1 #將darknet加入可執行權限 !ls -la /WORK1/darknet.official/darknet !chmod 755 /WORK1/darknet.official/darknet !ls -la /WORK1/darknet.official/darknet #下載YOLO COCO預訓練weights import requests, os weights_filename = “/WORK1/cfg_YOLO/Pretrained/yolov3.weights" weights_url = “https://pjreddie.com/media/files/yolov3.weights" #顯示圖片用 def imShow(path): import cv2 import matplotlib.pyplot as plt %matplotlib inline image = cv2.imread(path) height, width = image.shape[:2] resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC) fig = plt.gcf() fig.set_size_inches(18, 10) plt.axis(“off") #plt.rcParams[‘figure.figsize’] = [10, 5] plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)) plt.show() if( not os.path.exists(weights_filename)): #download to google drive r = requests.get(weights_url, stream = True) with open(weights_filename, “wb") as file: for block in r.iter_content(chunk_size = 1024): if block: file.write(block) #執行預測 !./darknet detect cfg/yolov3.cfg /WORK1/cfg_YOLO/Pretrained/yolov3.weights data/dog.jpg
由於 Darknet 在做偵測時會嘗試顯示圖片並等待使用者動作,所以會等待一段時間才會出現訊息,您可以修改 examples/detector.c,comment 下方 612~615 的內容。
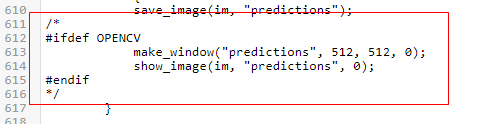
(圖片來源:曾成訓提供)
執行結果如下,確認 Darknet 可正常的執行。
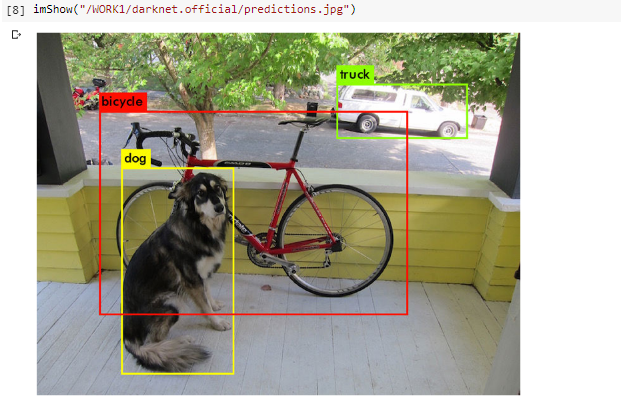
(圖片來源:曾成訓提供)
7. 開始訓練 YOLO
新增一 Colab 頁面,可命名為 train.ipynb,執行的程式如下:
from google.colab import drive drive.mount(‘/content/gdrive’, force_remount=True) !ln -s ‘/content/gdrive/My Drive/space_Colab’ /WORK1 !ls -la /WORK1/darknet.official/darknet !chmod 755 /WORK1/darknet.official/darknet %cd /WORK1/darknet.official !./darknet detector train /WORK1/cfg_YOLO/cfg.crowdHuman_colab/obj.data /WORK1/cfg_YOLO/cfg.crowdHuman_colab/crowd_human_yolov3_colab.cfg /WORK1/cfg_YOLO/Pretrained/darknet53.conv.74
會看到 Colab 載入 model 後開始進行訓練了。
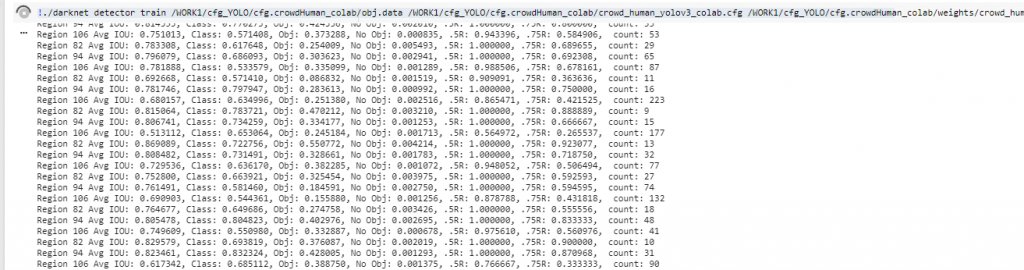
(圖片來源:曾成訓提供)
可能過了一段時間訓練 log 畫面都沒有更新,但左上角的圓形有在轉,表示有在運作,可以不用擔心,另外您也可以將其同步在 Google Drive 上,就能看到訓練的 weights 有持續在增加及更新(下圖紅框部份)。
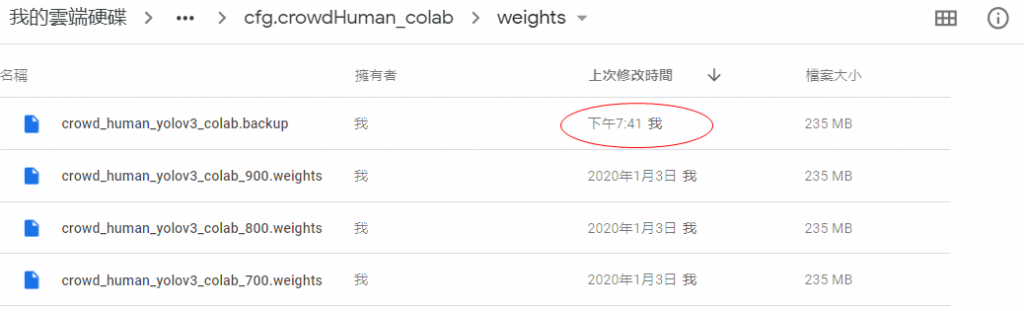
(圖片來源:曾成訓提供)
超過了 12 小時 Colab 就會出現 Runtime disconnected (如下圖),此時可重新載入 train.ipynb 的頁面,將最後一行訓練中所帶入的 pretrained weights 改為 xxxx.backup,重新執行一次,便可以接續最近一次訓練的結果繼續訓練下去。
!./darknet detector train /WORK1/cfg_YOLO/cfg.crowdHuman_colab/obj.data /WORK1/cfg_YOLO/cfg.crowdHuman_colab/crowd_human_yolov3_colab.cfg /WORK1/cfg_YOLO/cfg.crowdHuman_colab/weights/crowd_human_yolov3_colab.backup
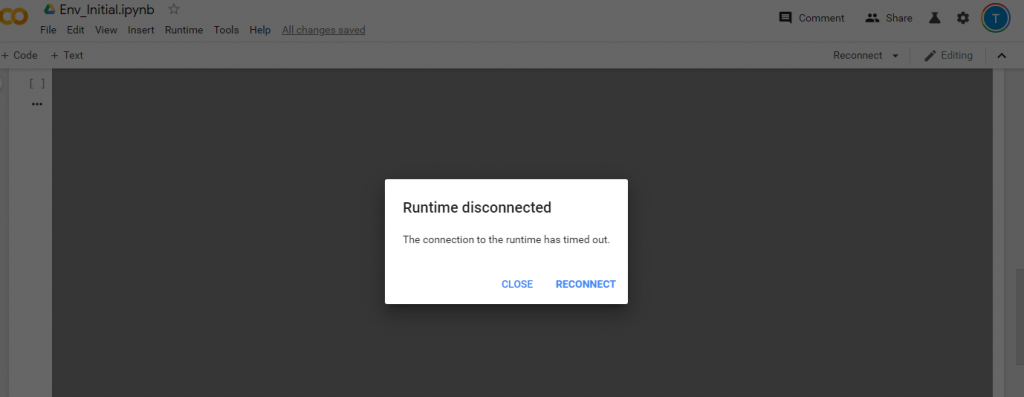
(圖片來源:曾成訓提供)
訓練結果
在經過數天斷斷續續的訓練後,使用 Crowd Human dataset 的15,000張圖片,透過 Colab 所訓練的結果如下,但其實還不算是最佳。

(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
小結
你可能會問「能用 Colab 取代實體 GPU 嗎?」
Colab 的優點:
- 免費且在雲端,隨時隨地可取用
- 超大的 GPU memory(16GB),遠勝 2080 Ti,訓練 YOLO V3 時,batch 可以設得更大來加快訓練速度
- 預設已安裝好一些常用的 AI frameworks,進入 Colab 即可直接使用
- 連接 Google Drive 相當方便,只要空間夠大,便可先預存大量的 dataset 備用
Colab 的缺點:
- 使用上的時間限制(12 hrs)
- 必須一直開啟著瀏覽器來避免 Colab 視窗關閉
- 在執行時很容易出現 Javascript 的警告或錯誤訊息,造成執行中斷
- 將 Dataset 上傳到 Google Drive 的時間及空間上成本
- Colab 與 Google Drive 之間的讀取速度緩慢,拖累了 GPU 的執行速度
回到現實,看完上方的介紹,您是否期待著用這個免費的 Colab GPU 來取代實體 GPU呢?很遺憾,沒有辦法,至少現階段還不行,最主要原因是 Google Colab 使用辦法中的這條限制:
The best available hardware is prioritized for users who use Colaboratory interactively rather than for long-running computations. Users who use Colaboratory for long-running computations may be temporarily restricted in the type of hardware made available to them, and/or the duration that the hardware can be used for. We encourage users with high computational needs to use Colaboratory’s UI with a local runtime.
Please note that using Colaboratory for cryptocurrency mining is disallowed entirely, and may result in being banned from using Colab altogether.
當您突破 12 小時的限制,持續重新執行 Colab 來跑你的 YOLO training,不消幾天您的 Colab 頁面就會出現下方訊息:
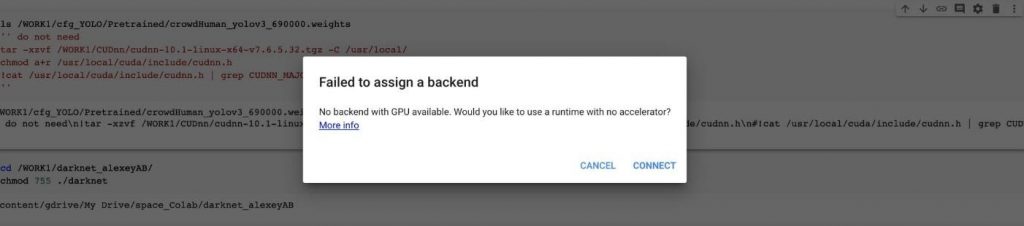
(圖片來源:曾成訓提供)
您會在短時間內被封鎖,無法再使用 Colab 的 GPU,因為只要一執行就會出現這個訊息,只有切換為一般的 CPU 才能正常運作,因為您已經被 Google 逮到將 Colab 用在長時間運算而非測試與學習的任務,必須等待短則半天多則數天才能再次使用。
至於這封鎖時間為期多久呢?坦白說我也不曉得,因為我也正在封鎖期!等解封後就能告訴你答案了!
(本文經作者同意轉載自 CH.TSENG 部落格、原文連結;責任編輯:賴佩萱)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2020/10/27
很棒!感谢!!