作者:曾成訓(CH.Tseng)
如果想虛擬出人類的五官,用大頭照是最適合的,這邊使用的訓練樣本是來自 Flickr 的資料庫—Flickr Faces HQ Dataset(FFHQ)。
- 圖片數目:70,000 張
- 圖片種類:PNG 圖檔
- 圖片尺寸:共三種(裁切臉部的高品質 HQ、低解像 Thumbnail、in-the-wild 相片原圖各 70,000 張)
- HQ:1024×1024 Thumbnail:128×128
- 圖片特性:每一張圖片皆使用 Dlib 自動裁切臉部及校正對齊
這次所使用的程式,參考自周凡剛老師所開的課程並作了些許修改(如果您對 GAN 有興趣,相當推薦周老師的這個課程唷!)
Generator模型
主要修改基本的 MNIST DCGAN 架構,讓 Generator 能產生 56×56 的彩色 RGB 圖片。由於每次採樣會增加二倍尺寸,因此一開始的 7×7 需要三次的 up sampling 才會達到所需的 56×56(7x7x128 🡪 14x14x128 🡪 28x28x128 🡪 56×56×128 🡪 56x56x3),因此使用迴圈的方式會比較簡潔;另外,這邊使用的 128 是參考 VGG 的作法,這個數值可以更改。
def generator_model(dim, base_gen, rand_dim):
gen = Sequential()
gen.add(Dense(dim*dim*base_gen, input_dim=rand_dim, activation='relu'))
gen.add(Reshape((dim, dim, base_gen))) # 轉換成三維
for i in range(0, int(base_gen/28 + 1)):
# 上採樣, 長寬會變兩倍
gen.add(UpSampling2D(size=(2, 2)))
# (4, 4)卷積窗的卷積, DCGAN模型的標準用法。
gen.add(Conv2D(base_gen, kernel_size=(4, 4), activation='relu', padding='same'))
# 卷積層間使用BN來normalize,也是DCGAM的標準用法。
gen.add(BatchNormalization())
#因為是RGB圖片, 因此讓filter為3, 輸出channel為3的圖片
#一樣使用tanh作為激活
gen.add(Conv2D(3, kernel_size=(4, 4), activation='tanh', padding='same'))
return gen
Discriminator模型
基本上 Discriminator 方面,只要將輸入的部份修改成與 Generator 輸出的尺寸相同(56x56x3)即可。
def discriminator_model(in_shape, base_gen):
discriminator = Sequential()
#步長2卷積,這是 DCGAN的標準用法。
discriminator.add(Conv2D(int(base_gen/8), kernel_size=4,
strides=2,
input_shape=in_shape,
padding="same",
activation='relu'))
#DCGAN都會在兩層卷積中加入BN
discriminator.add(BatchNormalization())
discriminator.add(Conv2D(int(base_gen/4), kernel_size=4,
strides=2,
padding="same",
activation='relu'))
discriminator.add(BatchNormalization())
discriminator.add(Conv2D(int(base_gen/2), kernel_size=4,
strides=2,
padding="same",
activation='relu'))
discriminator.add(BatchNormalization())
discriminator.add(Conv2D(base_gen, kernel_size=4,
strides=2,
padding="same",
activation='relu'))
discriminator.add(BatchNormalization())
#全連接層(MLP)
discriminator.add(Flatten())
discriminator.add(Dense(base_gen*2, activation='relu'))
discriminator.add(Dropout(0.25))
discriminator.add(Dense(1, activation='sigmoid'))
return discriminator
DCGAN的訓練
在進行 GAN 訓練時,雖然 Discriminator 與 Generator 都包含在 GAN 模型中,但是由於 Discriminator 的 trainable 設定為 False,這表示在訓練 GAN 時,只有 Generator 被訓練到,此時 GAN 輸出的 loss 視為 Generator 的 loss;而 Discriminator 自己單獨進行訓練,它的 loss 是由兩種 loss 加總:判斷 Generator 產生的虛擬圖片、判斷 Dataset 中真實的圖片。
loss_file = os.path.join(output_folder, "loss_" + str(epoch_count) + "epochs.csv")
f = open(loss_file, 'w')
f.write("epoch,d_loss,g_loss \n")
f.close()
for epoch in range(0, epoch_count):
for batch_count in range(0, 100):
idx = np.random.randint(0, x_train.shape[0], batch_size)
imgs = x_train_shaped[idx]
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
#Generator製造出虛擬圖片,這些圖片由Discriminator來判斷是否為False
noise = np.random.normal(0, 1, (batch_size, random_dim))
gen_imgs = generator.predict(noise)
discriminator.trainable = True
#由Discriminator判斷由Dataset來的圖片是否為True。
d_loss_real = discriminator.train_on_batch(imgs, valid)
#由Discriminator判斷由Generator產生的虛擬圖片。
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
#兩者加總即為Discriminator的Loss
d_loss = (d_loss_real + d_loss_fake) / 2
discriminator.trainable = False
noise = np.random.normal(0, 1, (batch_size, random_dim))
#由於GAN模型中,Discriminator設為不可訓練,因此訓練GAN模型,可視為僅訓練Generator。
g_loss = gan.train_on_batch(noise, valid)
訓練時的資訊輸出
因為想要看看 Generator 在迭代訓練時,每批次訓練出來的臉孔圖片有否進步,同時也希望將模型的 loss值輸出以利統計,因此加入了下方的程式,這可以讓其在指定間隔的 epoch 次數達到時,輸出 Generator 的預測圖片、loss 值以及匯出模型的權重。
out_path = output_folder +'/' + str(epoch+1) + '/'
if (epoch + 1) % epoch_interval_output_log == 0:
f = open(loss_file, 'a')
msg_line = "{} epoch Discriminator loss:{} Generator loss:{}".format(epoch + 1, d_loss, g_loss)
print(msg_line)
f.write( "{},{},{}\n".format(epoch+1,d_loss,g_loss))
f.close()
if (epoch + 1) % epoch_interval_output_model == 0:
if( not os.path.isdir(out_path)):
os.mkdir(out_path)
print("Output models.")
output_model(out_path, output_images_num, random_dim, epoch+1, generator, discriminator, gan)
if (epoch + 1) % epoch_interval_output_img == 0:
if( not os.path.isdir(out_path)):
os.mkdir(out_path)
print("Output images.")
output_img(out_path, output_images_num, random_dim, epoch+1, generator, discriminator, gan)
訓練結果
將 Generator 和 Discriminator 的 loss 輸出後,會看到它的訓練曲線圖如下,看起來並沒有明顯的下降趨勢,這是由於其 loss 是雙方相互拉距拔河的結果,Generator 強時 Discriminator 弱,反之亦同,因此就沒有一般深度學習模型訓練 loss 愈來愈低的情況。
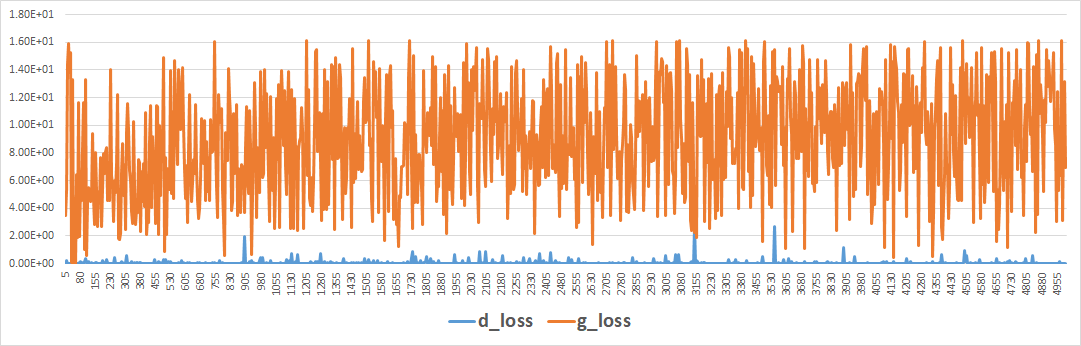
(圖片來源:曾成訓提供)
另外值得一提的是,起初在訓練時,Generator 處於很吃虧的情況,因為要由無生有地產生以假亂真的圖片,一定不知道要如何產生,因此它產生的圖片很容易就會被 Discriminator 判定為假,造成 Generator 不知道要如何產生真的圖片而被迫提早放棄。
幸好本範例使用 56×56 的圖片還能訓練出來,但如果擴大一倍到 112×112,對 Generator 來說可能就很難訓練了。
下面是 Generator 各訓練階段的虛擬能力:
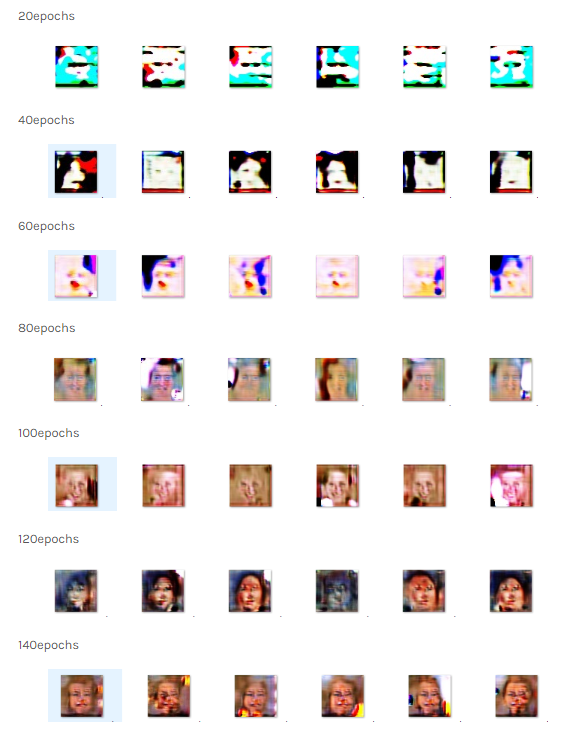
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
(圖片來源:曾成訓提供)
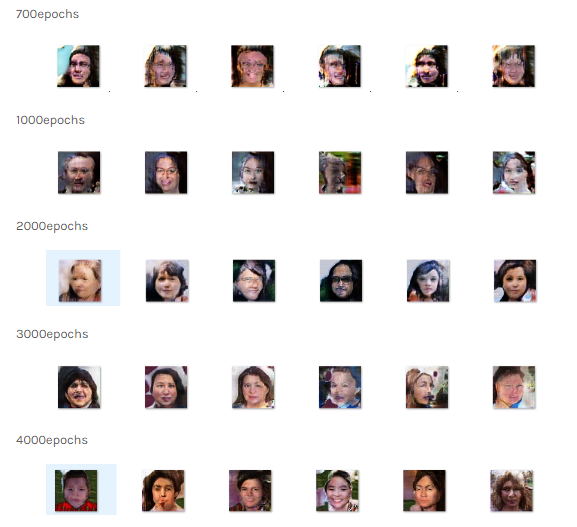
從上方的迭代訓練結果可以看出,一開始 Generator 是從大體結構開始學習,60 epochs 有了五官,100 epochs 開始有了臉部輪廓,200 epochs 後逐漸著重在細節的部份,訓練到最後的 5000 epochs,Generator 產生的人像已經相當接近實際的了。
這是最後第 5000 epochs 的訓練結果。你想像得出來這些臉孔都是虛擬出來的嗎?是不是有一些人讓你有似曾相似的熟悉感?

(圖片來源:曾成訓提供)
DCGAN 模型的利用
DCGAN 是一種非監督式學習,因為它不需要事先標記好的圖片便能訓練,那麼這個能夠產生無限多陌生臉孔的 GAN 模型能做什麼呢?目前我想到的是:
- 用於社交網站上,讓使用者產生代表自己的虛擬頭像
- 用在需要人臉臉孔的廣告或宣傳用途(擔心侵犯人身權但又不想花錢找真正的模特兒)
- 用於訓練標記點模型或臉孔偵測模型(使用 GAN 虛擬出大量的人臉圖案,再使用自動工具來標記人臉五官,達到完全不需搜集人臉相片便可獨立的訓練人臉模型)
DCGAN架構總結
這篇論文提出標準的 DCGAN 架構,能夠穩定訓練出品質相當好的虛擬圖片。
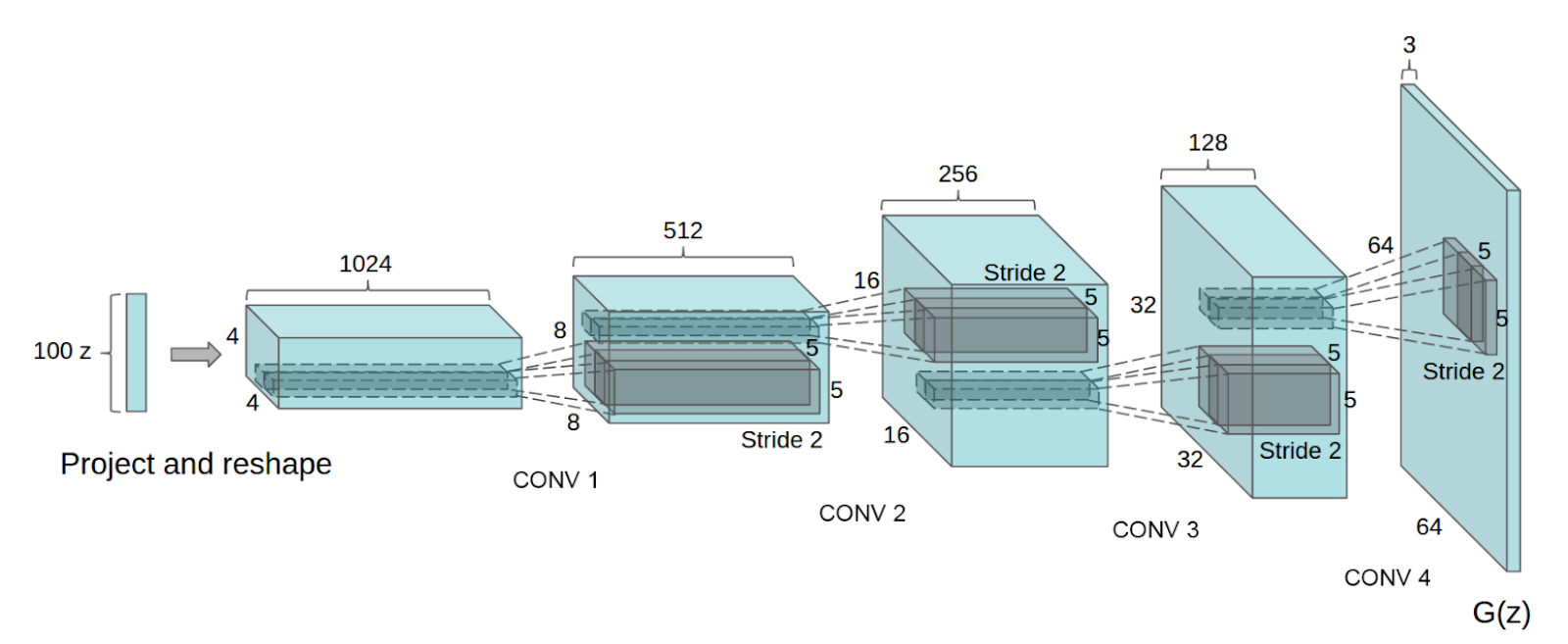
DCGAN 架構(圖片來源:曾成訓提供)
論文中所展示的 Generator 架構,開頭輸入的是 100 dim 常態分配的亂數,輸出為 64×64 的 RGB 圖片,若搭配程式仔細看看 Generator 和 Discriminator 的模型架構,會發現:
- Discriminator 不使用池化層(pooling),而使用步長(strides)為 2 來取代 pooling
- Generator 主要使用 upsampling(稱上採樣或反捲積)來擴大圖片
- 每層之間皆使用 batch normalization
- 取消隱藏層(全連結層)
- Kernel(稱捲積核)皆使用 4×4
- Generator 的 activation 除了輸出層使用 Tanh,其餘皆使用 ReLU
- Discriminator 的 activation 使用 LeakyReLU 或 ReLU
(本文經作者同意轉載自 CH.TSENG 部落格、原文連結;責任編輯:賴佩萱)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


