作者:許哲豪 Jack
現代化工業機器手臂早已成為自動化工廠中不可或缺的最佳幫手,面對大量重複性及需要精密定位的工作,沒了它幾乎寸步難行。傳統的機器手臂需要有專業的工程師預先將工作(運動)路徑輸入(教導)到系統中,手臂才能依序執行指定的動作,但是這樣的作法只適用固定形狀及擺放位置的物件進行取放或加工。
近年來隨著電腦視覺及3D(深度)感測技術的進步及高性能平價的計算平台陸續上市,幫機器手臂加上一雙明亮動人的眼睛,使其可以像人一般看到物件的形狀、擺放方式及位置,自動計算完手臂移動路徑及每個軸關節(馬達)運動距離、角度及速度後,便可伸手去拿取及放置到指定位置,已不再是遙不可及的夢想了。
雖然具有視覺能力的智能工業級的機器手臂已從數百萬降至數十萬元,算是相當便宜了,但這仍不是一般人玩的起的,那創客們是不是有機會自己土炮一台呢?這當然是有可能的,現在隨便花個數千元就能輕鬆在購物網站上買到相當不錯的迷你型多軸機器手臂(類手臂型、XYZ直交型、Delta三角錐型等),還想更省錢的創客們還可買一些小型步進馬達或大扭矩數位舵機、多軸運動控制板加上3D印表機或雷射切割機製作機構就有機會自己做一台機器手臂。
那智能視覺部份怎麼辦呢?傳統的雙眼立體視覺(深度)計算及校正原理那麼難懂,沒有讀一堆數學和算法可是搞不定的,那該怎麼辦呢?不用擔心,現在的3D(深度)感測器(如Intel RealSense)已相當平價,約3000~6000元就能取得,不用學那些數學,就像使用網路攝影機一樣簡單,透過USB就能獲得彩色加深度(RGB-D)影像。
有了硬體後最後加上開源深度學習(如Intel OpenVINO)、電腦視覺(如OpenCV)及一些加速運算工具(如Intel 神經運算棒)幫忙辨識物件及計算平面(XY)位置後,加上3D感測器提供的深度(Z)資訊,如此便可驅動機器手臂移動到指定空間(XYZ)座標抓取指定物件了。
接下來就開始帶著大家了解如何建構「土炮智能機器手臂之視覺系統」。
視覺型智能機器手臂
一般常見的智能機器手臂視覺系統有很多做法,舉例來說可將深度攝影機裝在夾爪上方(如圖1a所示),會隨著機器手臂移動,使用時手臂會先移動到某個位置讓深度攝影機計算待抓取的物件位置,再令手臂移動及抓取物件,這樣的好處是可以取得較理想的視角及較大的物件成像且不易有視線遮擋問題,但缺點是手眼校正系統較為複雜,取放精度會略差。
另外一種作法則是反過來,外加一固定架安置深度攝影機(如圖1b所示),機器手臂取物前要先移開讓深度攝影機可正確計算物件位置,接著再移動取物,若搭配高級結構光投影設備及高解析度攝影機來計算深度則其解析度可達公釐(mm)甚到更小等級。
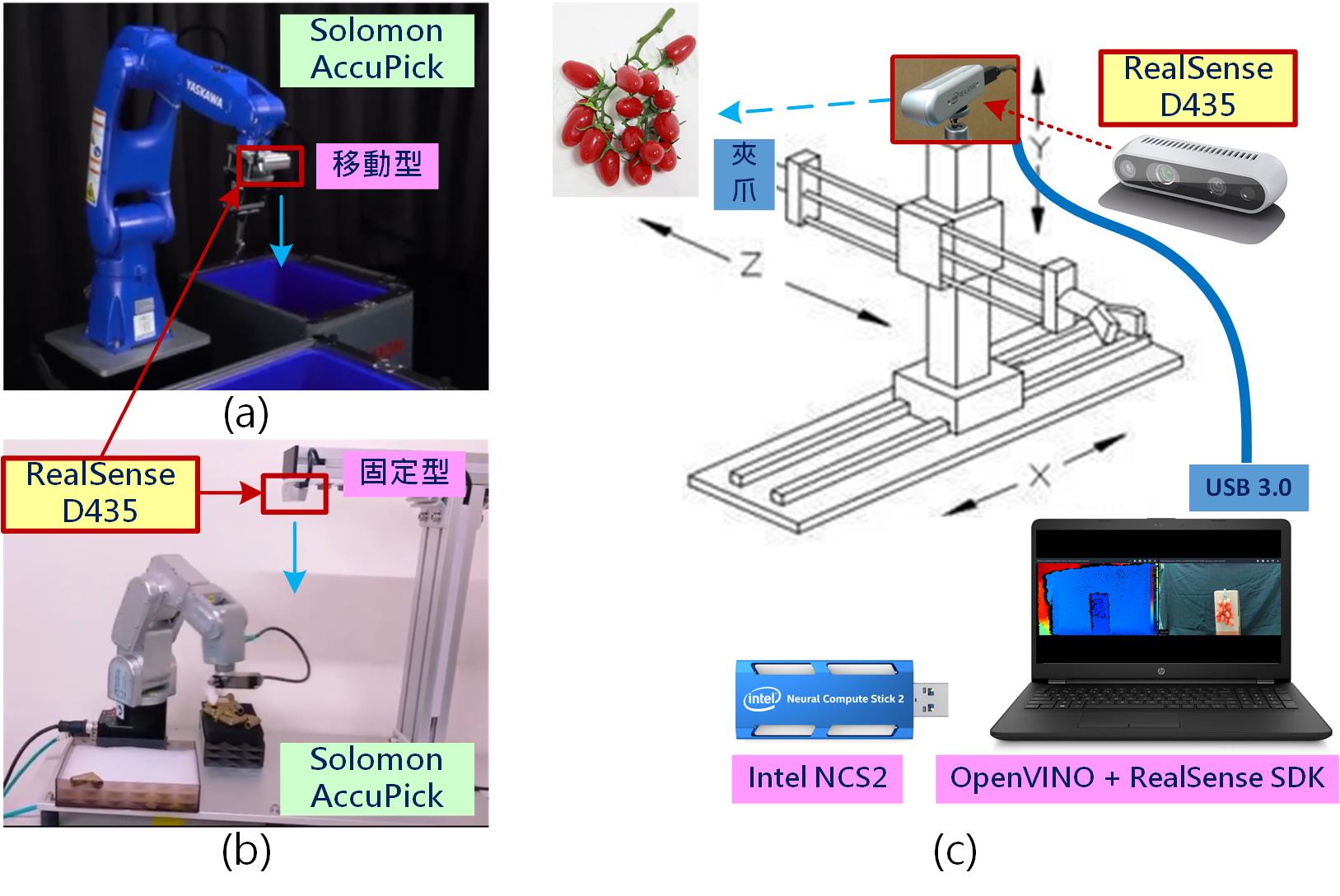
圖1 機器手臂之視覺系統示意圖,(a)專業型機器手配移動式深度攝影機,(b)專業型機器手臂配上置型固定式深度攝影機,(c)土炮型XYZ直交型機器手臂配後置固定式深度攝影機系統概念圖。 (OmniXRI整理製作)
這裡為了讓大家把重點放在如何取得待抓取物的空間座標,所以暫時忽略機器手臂如何製作及控制的說明,僅以示意圖(如圖1c所示)說明機構設計方式。整體概念上採XYZ直交型三軸機器手臂最為簡單易懂且容易實現。Z軸最前方裝上夾爪,而深度攝影機固定於Y軸上方不動。左右移動為X軸,上下移動為Y軸,方便滿足攝影機取像座標系統。而前後移動為Z軸,以符合深度攝影機深度影像輸出結果,越靠近攝影機Z值越小,反之越遠Z值越大。
採果機器人專案
話說去(2018)年8月一群創客高手受到歐盟甜椒採收機器人計畫影片[1]激勵後,在FarmBot Taiwan User Group (FBTUG) 總召哈爸的號召下,一起參與了台版的「開源採收機器人(HarvestBot)」專案。小弟雖沒有直接參與實作部份,但也協助整理了相關技術並寫了幾篇文章(視覺篇[2]、夾爪篇[3]、機器手臂篇[4])方便大家了解各種可能做法。
雖然經過大家的努力各獨立項初步有了一些成果,包含簡易直交型(Mini FarmBot XYZ型改裝)機器臂、簡易剪切夾爪、深度學習物件定位(YOLO)算法(不含水果距離計算)及帶視覺模擬小車,如圖2 a ~ d所示,但中間的整合仍沒有明顯進度。
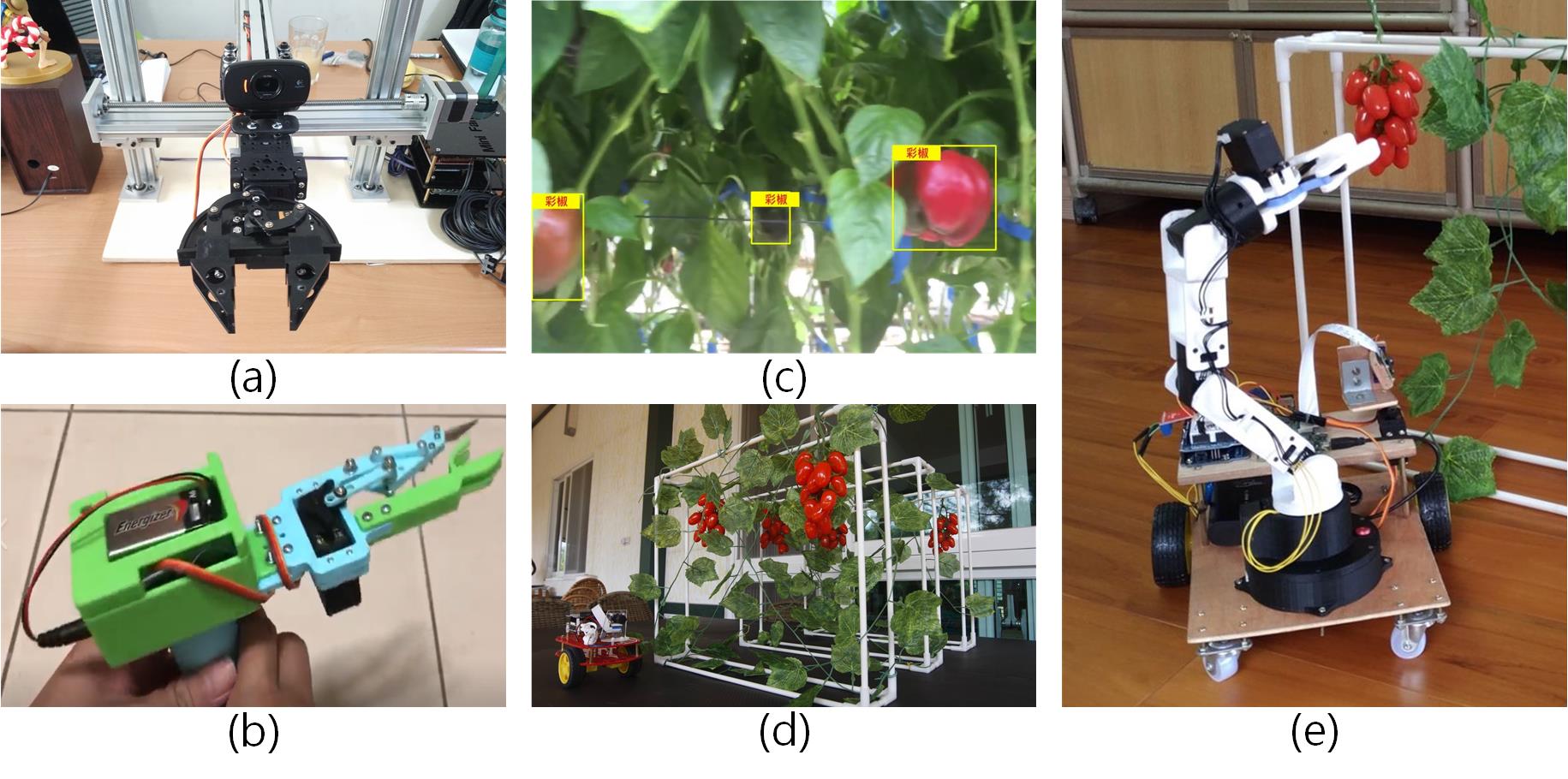
圖2 FBTUG採果機器人專案,(a)Mini FarmBot改裝之XYZ直交型機器手臂,(b)甜椒切蒂夾爪,(c)甜椒YOLO物件定位算法結果,(d)小鴨城迷你視覺自走車,(e)土炮一號遙控型採果機器人。(source)
今(2019)年8月在熱心創客高手維嘉的協助下完成了一台迷你版的「土炮一號」(圖2e),它整合了控制電路及作業系統(ROS)、自走車、六軸機器手臂並在夾爪上方安裝了一台攝影機,雖然目前只能透過遠端視訊及遙控操作,仍無法自動走到定位以電腦視覺自動分析水果位置及距離(深度)並伸出手臂去摘取水果及取回放置,但機電控制系統已具有相當雛形了。
有鑑於此,本文就以此為主要目標,用來解決自動計算小蕃茄(水果)空間位置(XYZ),於是利用手上已有的深度感測器Intel RealSense D435(以下簡稱D435)及神經運算棒二代Intel Neural Compute Stick 2(以下簡稱NCS2)加上開源視覺推論及神經網路優化工具包Intel OpenVINO (自帶簡化版OpenCV 3.4.1)來土炮一下「智能機器手臂的視覺系統」。
本文主要是利用D435擷取到的彩色影像結合深度學習的物件定位算法YOLOv3找到水果位置(X,Y),當CPU算力不足時還可使用Intel GPU或VPU(NCS2)加速計算,最後再加上D435擷取到的深度影像所對應位置的深度(Z)資訊,未來就可以讓機器手臂正確地伸到正確空間位置(XYZ)夾取及摘取(剪切)水果了。
立體視覺原理
常見3D立體視覺或稱深度感測器技術主要分為被動式和主動式。被動式中最常見的就是「雙目立體視覺(Stereo Vision)」,利用兩組攝影機模擬人的雙眼,進而計算出場景中物件的視差(或稱深度或距離)。而主動式須要額外輔助裝置來協助計算物件深度,常見作法有「結構光(Structured Light)」及「飛行時間(Time of Flight)」,更多技術原理、優缺比較可參考小弟之前分享的「3D感測可行技術與開發工具剖析」[5]。
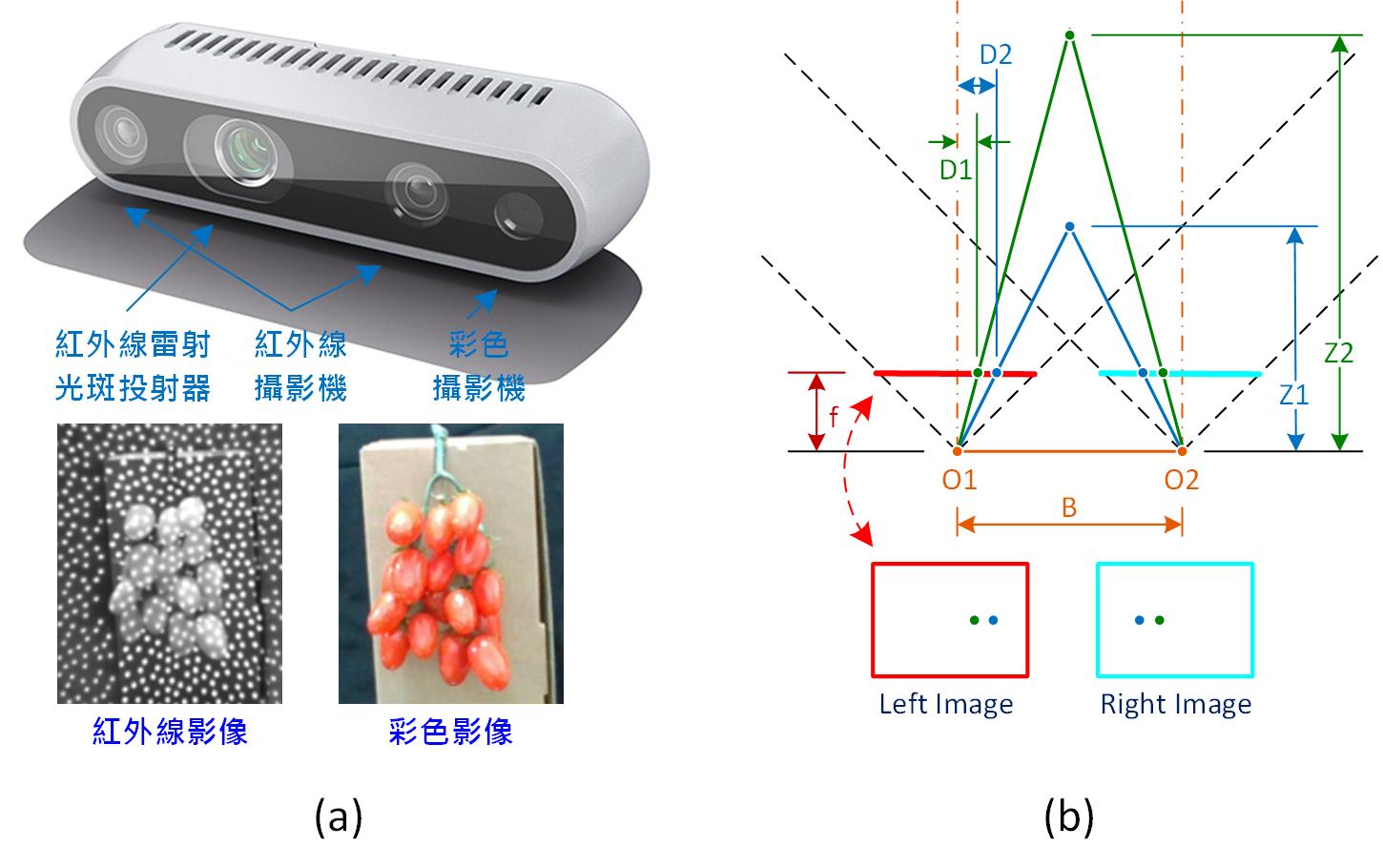
圖3 Intel RealSense D435主動式立體視覺系統,(a)D435結構及取像結果,(b)雙目立體視覺視差(深度)計算原理。(OmniXRI整理製作)
本文主要使用的深度感測器為Intel RealSense D435,它由一組普通的彩色(RGB)攝影機,二組紅外線攝影機及一組紅外線雷射光斑投射器構成(如圖3a所示),而其深度感測技術稱為「主動式雙目立體視覺」,顧名思義是結合雙目立體視覺及主動式結構光而得,更完整的產品技術資料可參考下表 [6]。
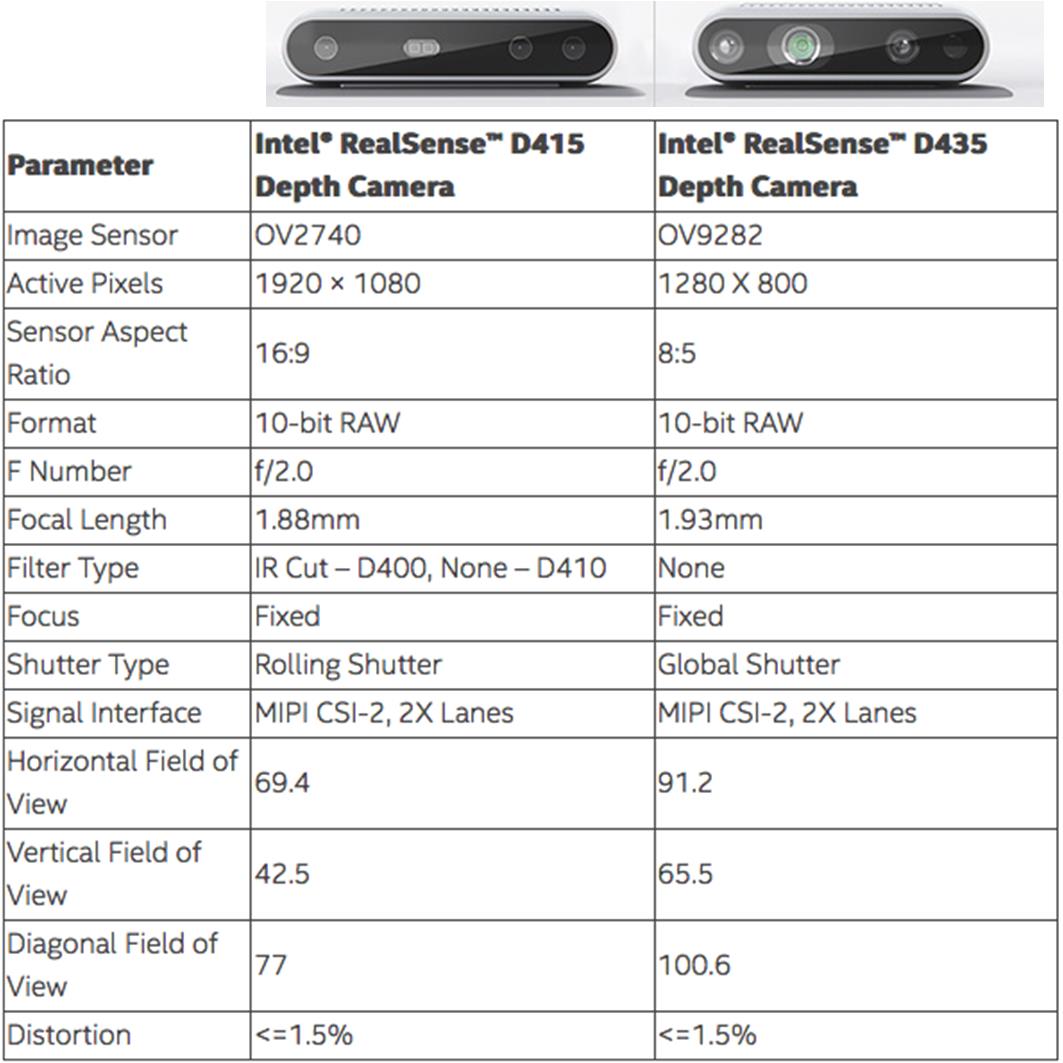
深度感測器技術規格 (source)
從[5]一文中可得知雙目立體視覺最怕遇到素色(無紋理)或深色的材質,因為無特徵可供比對導致難以計算視差(深度)。而D435透過紅外線雷射發射器打出的均勻尺寸(直徑)、間距的光斑(如圖3b),就使得素色及深色材質有了特徵可進行比對和計算視差。
另外為避免雷射光斑在物體太近時會過強(亮),或者過遠時過弱(暗),其SDK也提供調整雷射強度的功能。當D435在室外使用或物體的距離較遠時,雷射光斑是無法產生輔助效果的,只能靠原始的雙目立體視覺原理計算(如Fig. 3b所示)。不過為了補足很多情況下部份位置(如素色區、紋理重複區)深度無法計算問題,SDK另有提供「Default」、「High Accuracy」、「High Density」、「Medium Density」、「Customer」等模式可供切換。
RealSense SDK安裝流程
本次主要使用Intel RealSense D435深度感測器,操作步驟如下:
- 使用前須先安裝SDK並更新韌體,完整的安裝步驟可參考Intel RealSense™ SDK無痛安裝指引[7]。
- 安裝完成後所有SDK內容預設會存放在”C:\Program Files (x86)\Intel RealSense SDK 2.0″下。
- 自帶的OpenCV 3.4.1版(預編譯精簡版)存放在\third-party\opencv-3.4下;相關範例程式在其\samples路徑下。
- 接著使用Microsoft Visual Studio 2015以上版本以「系統管理員身份」開啟rs-examples.sln,重新建置(build),相關執行檔(*.exe)及OpenCV & RealSense附屬動態連結函式庫(*.dll)即會產生在C:\Program Files (x86)\Intel RealSense SDK 2.0\samples\x64\Release\ 下。
目前SDK中提供了二十多個範例,包含深度(D400系列)及追蹤(T265系列)攝影機範例。在深度感測器範例中包括有如何取得及顯示各個攝影機影像(彩色、紅外線及深度)、點雲資訊及感測器參數設定等應用。
不過顯示部份預設是使用其SDK配合OpenGL渲染(Render)方式繪圖,所以並不一定合適製作自己的人機介面(UI)及對影像內容(個別像素)進行運算,因此另有範例說明如何整合OpenCV進行顯示(ImShow)、前後景分離(GrabCut)及深度神經網路物件偵測(DNN)等進階範例,更多說明可參考官網文件[8]。
另外為了讓大家更了解RealSense SDK產生的串流(彩色、深度及紅外線)影像如何擷取及轉換成OpenCV Mat格式,方便後續製作自己的人機介面、顯示及計算使用,可參考「【3D感測器】如何擷取Intel RealSense™串流影像到OpenCV」[9]。
YOLOv3訓練小蕃茄影像
本文主要是以小蕃茄做為機械手臂視覺系統的模擬採收對象,但是一般常見開放資料集(如ImageNet, MS COCO)都沒有合適的,所以只好自己收集、標註資料集。由於撰寫本文時非生產季節加上沒有合作的伙伴可以提供實際農場取像,於是只好上網買了一串塑膠製的小蕃茄,外觀看起來非常逼真,作為本次實驗的對象。
本次實驗取像及測試的環境如圖4所示。筆電上預先裝好RealSense SDK及OpenVINO SDK,並插入神經運算棒(Intel NCS 2)作為加速計算用。RealSense D435插入筆電的USB 3.0埠(不支援USB 2.0),小蕃茄距離D435約30公分,分別對小蕃茄正面和背面取像作為樣本。為了快速取得大量樣本,令攝影機每隔10個影格(0.33秒)拍一張照,拍攝其間以手移動小蕃茄位置及角度,以獲得更多樣性的樣本。
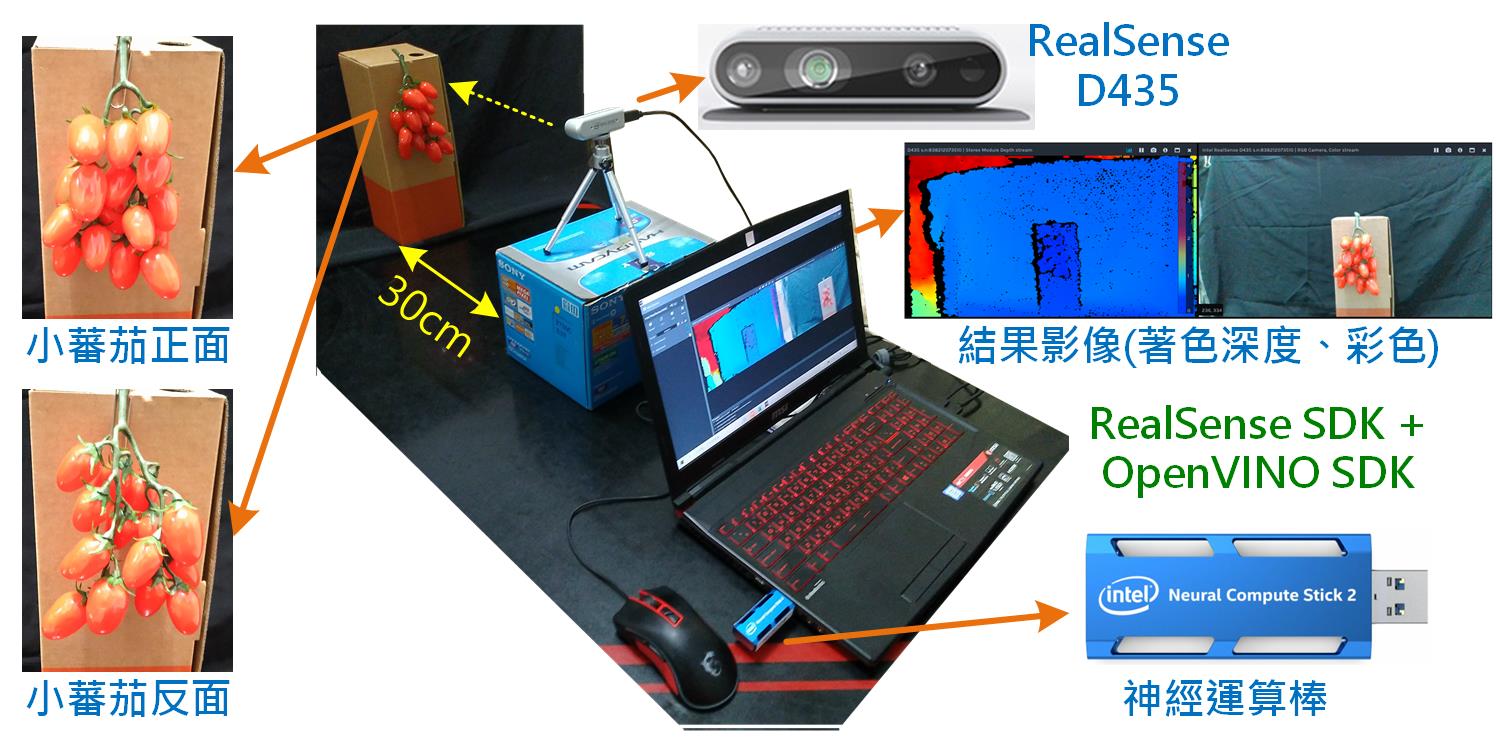
圖4 取像及測試工作環境示意圖(OmniXRI整理製作)
為了節省後續標註及訓練時間,所以只取得正面92張,背面79張,合計171張樣本影像。當然這樣的數量對深度學習的訓練是非常不夠的,這裡只是為了說明工作流程,所以暫時忽略後續訓練及偵測正確性的高低。由於如何標註、訓練資料集的工作步驟頗多,所以請直接參考【AI_Column】如何以YOLOv3訓練自己的資料集─以小蕃茄為例[10]。
經初步測試後,正確率實在有點糟糕,可能是小蕃茄(待偵測物件)重疊的太嚴重且訓練及驗證集的數量太少,同時又沒有利用資料擴增手段改善。因此只能先用訓練集來充當測試集,當然這只是為了方便解釋後面的工作流程,一般正常情況下是絕不允許拿訓練集或驗證集來測試的,因為這樣很容易落入過擬合區間造成正確率會異常飆高的問題。
若先排除上述過擬合問題,測試集被框到的小蕃茄數量明顯比實際少很多,且很容易出現過大或過小的框,所以就在程式中加入長寬尺寸及比例來限制不正常的物件被偵測到。經過限制後被框到的小蕃茄位置及尺寸大致都還算正確,可是置信度高低差很多,有些甚至低到0.1(10%)以下,所以只好將置信度的門檻值設低一些,才不致於找不到任何物件,但缺點就是誤判的機率就增高了。
至於正面及反面何者偵測較為正確,正面會辨識率略高於反面,猜想可能是綠色的蒂頭沒有很確實被訓練到吧?另外雖然標註時已針對遮蔽小於1/2的小蕃茄都有加以標註,但實際上辨識出來的結果仍以形狀較完整的被偵測到的機率較高。如圖5即是小蕃茄在正面及反面以OpenVINO™執行YOLOv3的偵測結果。而圖6及圖7分別是原始影像及物件偵測結果影像動畫GIF檔示意檔,完整171張版動畫GIF檔請參考[11]。

圖5 小蕃茄偵測結果影像,左:正面,右:反面。(OmniXRI整理製作)

圖6 小蕃茄原始影像檔(OmniXRI整理製作)

圖7 小蕃茄偵測結果影像檔(OmniXRI整理製作)
物件偵測加深度影像整合測試
經過前面的努力後終於可以進到最後的整合階段了,透過OpenVINO™執行YOLOv3物件偵測功能並正確找出數個小蕃茄位置後,接下來就要開始判定那個小蕃茄優先採收。一般農民會從最靠近自己或最外層的開始採收,換一個說法就是距離最近的,此時RealSense D435的深度影像功能就派上用場了。不過事情有這麼簡單嗎?
「李組長眉頭一皺,發覺案情並不單純」,從圖8中可看出有幾個問題:
1. 深度攝影機的視野略大於彩色攝影機一些,導致小蕃茄在二組影像中的位置及尺寸也略有不同。
2. 深度影像並不是很完整,有些破碎,尤其在物件邊緣更是嚴重,甚至有陰影區(深度呈現黑色區域)無法計算出深度問題。
3. 小蕃茄被框到的區域像素很多,就算對應到正確的位置,深度資料不只一筆要以何者為主。
4. 小蕃茄本身直徑約10~20mm,而D435能穩定表達的深度差大約5~10mm(視外在光源及攝像品質而定),所以不同深度或相鄰小蕃茄可能存在極接近甚至相同深度值,導致同時有數個小蕃茄產生相同採收順序。
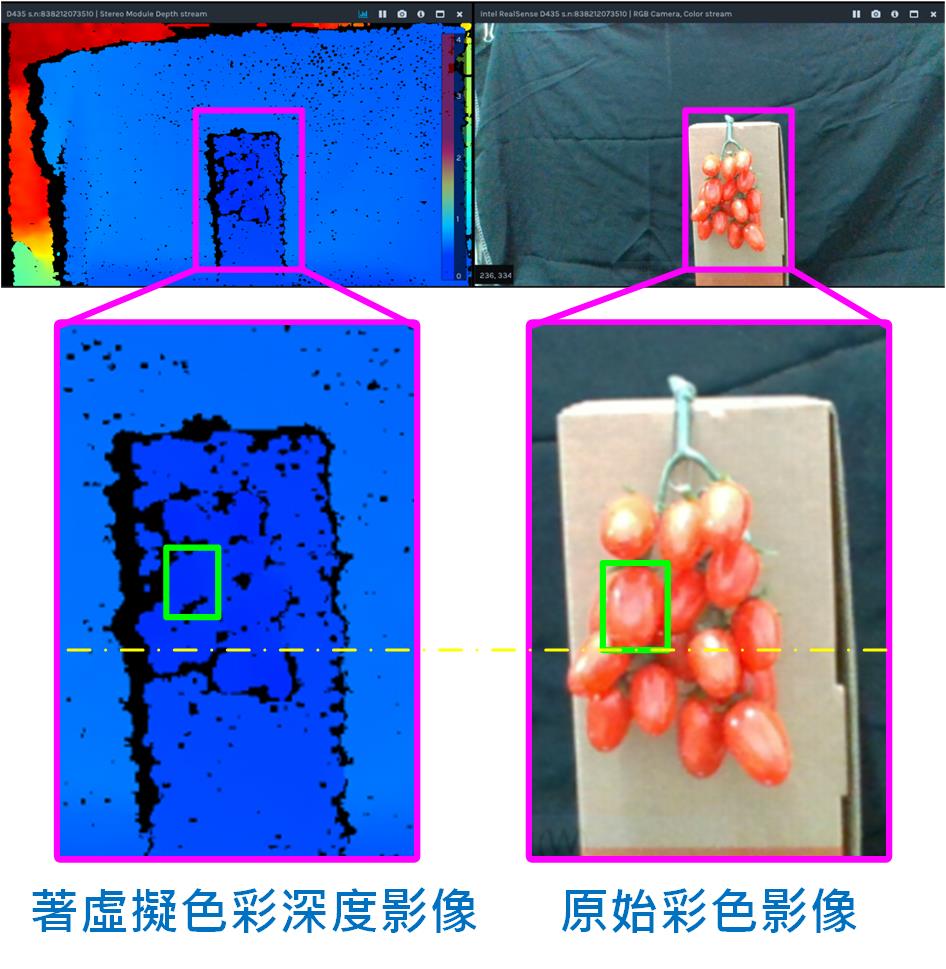
圖8 RealSense D435深度影像與原始彩色影像比對。(OmniXRI整理製作)
從上述問題大概可知要讓機器手臂視覺系統穩定辨識出待抓取物件的距離真的不簡單,這裡並不給出唯一解法,只是提供一些可能的做法,其它的留待有興趣的朋友繼續研究改善,以下就提供一些個人解題思考方向。
- 首先是視野問題,若被檢出物件較大(是指佔畫面比例而非實際外觀尺寸)則可忽略此一問題,但待檢物像小蕃茄尺寸時,則可能需要作簡單視野校正工作,令深度影像放大、平移一些以符合彩色影像位置,如此就可取得較正確深度資訊。
- 再來深度解析度不足問題可能不易克服,這屬於硬體限制,但對於更穩定檢出部份則可以依實際現場狀況微調RealSense D435的Laser發射功率。當攝影機太靠近待測物時,若Laser發射功率太強則會造成紅外線影像不是像圖3b所示有一堆細小光點,而是會變成一片慘白,那會造成不易計算正確視差(深度)。
- 關於要以何點的深度(距離)做為機械臂向前伸的距離,最簡單的想法就是以框的中心點作為基準即可,但不幸的是這個點可能沒有值或者值受到干擾而和實際有很大差距。如果容許較長的計算時間,則可考慮把框內所有深度值排序後取中位數或者以高斯分佈(中間優先權越重,越往外側權重越低)計算深度值均值。當然若考量計算時間,則可在框中心取一小塊(如10×10點)直接取平均值亦可。
- 最後是遇到深度相同問題時,則建議從物件框中心較靠外側、上方的小蕃茄開始採收,如此較不會發生,下方小蕃茄被其它擋住,機械爪不易進入剪切問題。
寫到這裡,回頭重新上網查了一下,發現Intel RealSense官網也有提供一個第三方以OpenVINO SSD物件偵測模型結合RealSense D415的簡單範例[12],另外在Github上也有一個結合MobileNet-SSD和RealSense D435的範例[13],有興趣的朋友可以參考一下。本文所有相關程式碼及訓練、標註資料集皆已開源,請參考:https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot
結論
本文雖然未真正將視覺物件偵測及深度量測成果應用到真正的機器手臂上,但該有的物件(小蕃茄)標註、訓練、推論(偵測)及深度資訊整合的框架及工作流程卻一樣不少,雖然目前偵測正確性不高,但只要擴大取得資料集的數量及多樣性,用更長的時間訓練資料集,加上完整的機器手臂運動座標校正,相信一定能更接近實用目標,剩下的工作就期待有心人繼續完成了。
參考文獻
[1] Sweet Pepper Harvesting Robot (2018) https://youtu.be/DUgjFaYyecE
[2] 採收機器人_視覺篇 http://omnixri.blogspot.com/2018/08/blog-post_28.html
[3] 採收機器人_夾爪篇 http://omnixri.blogspot.com/2018/09/blog-post_28.html
[4] 採收機器人_機器手臂篇 http://omnixri.blogspot.com/2018/10/blog-post.html
[5] 3D感測可行技術與開發工具剖析 https://omnixri.blogspot.com/2019/09/intel-realsense-dev-meetup13d.html
[6] Intel® RealSense™ Depth Camera D400-Series https://software.intel.com/realsense/d400
[7] 【3D感測器】Intel RealSense™ SDK無痛安裝指引 https://omnixri.blogspot.com/2019/10/3dintel-realsense-sdk.html
[8] Sample Code for Intel® RealSense™ cameras https://dev.intelrealsense.com/docs/code-samples
[9] 【3D感測器】如何擷取Intel RealSense™串流影像到OpenCV http://omnixri.blogspot.com/2019/11/3dintel-realsenseopencv.html
[10] 【AI_Column】如何以YOLOv3訓練自己的資料集─以小蕃茄為例 https://makerpro.cc/2019/12/train-your-dataset-with-yolov3/
[11] Github YOLOv3偵測小蕃茄原始及結果影像檔 https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3/Result
[12] Github realsense_object_distance_detection https://github.com/movidius/ncappzoo/tree/master/apps/realsense_object_distance_detection
[13] Github PINTO0309/MobileNet-SSD-RealSense https://github.com/PINTO0309/MobileNet-SSD-RealSense
(責任編輯:王姵文)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
- 【Arduino UNO Q專欄02】軟體開發初體驗 - 2026/05/21
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


