作者:Felix Lin
我們已經知道OpenVINO是個強大且容易使用的AI推論工具,並且在智慧製造與智慧零售上有不少落地應用就是使用OpenVINO進行優化與部署。但對於小型開發團隊或是才正要切AI領域的入門者來說,資料的取得與訓練模型可能就是要落實AI應用的第一道障礙了。
有鑑於此,OpenVINO Toolkit的子專案Open Model Zoo就直接提供了超過300個以上立即可用的預訓練AI模型(Pre-Trained Model),並且涵蓋了超過50種不同類型的範例程式原始碼。接下來這篇文章將帶各位探索這個有豐富資源的Open Model Zoo寶庫!
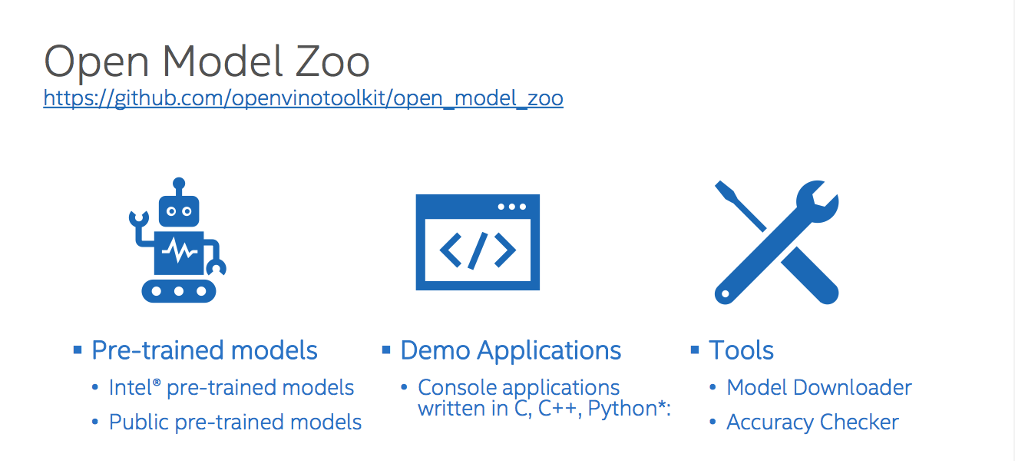
Open Model Zoo包含的三個主要項目
Open Model Zoo的內涵
Open Model Zoo涵蓋了三項主要的內容:預訓練模型Pre-Trained Models、展示應用範例Demo Applications以及工具Tools。這恰好了補足OpenVINO需要的深度學習模型以及使用者應用程式,不管是還未選定模型亦或是想要體驗各類模型可以達成的應用,都可以先搭配Open Model Zoo率先進行測試與評估模型,但實際要產出應用時也可以直接參照Demo程式碼進行修改,達到事半功倍的效果!。
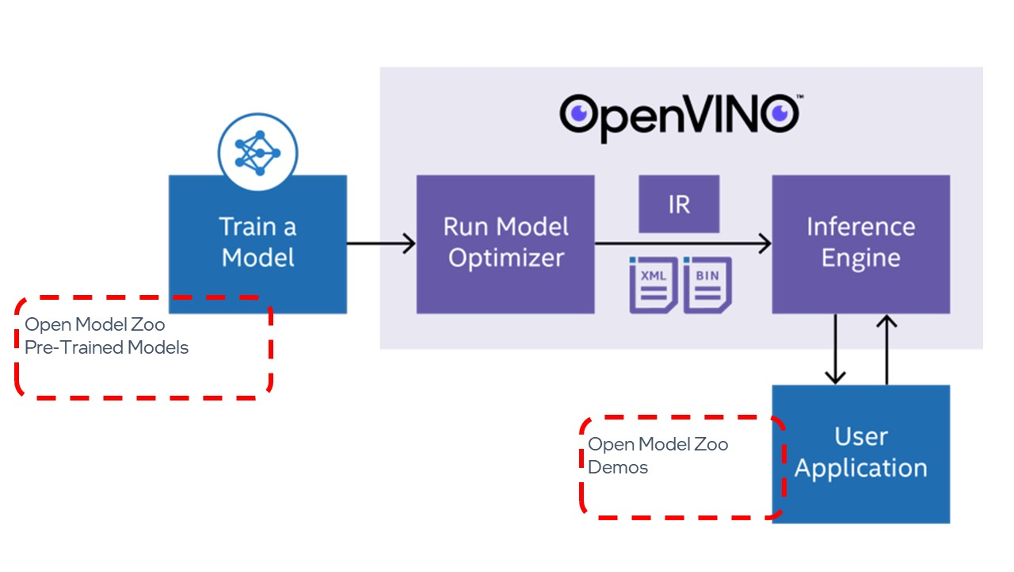
藉由Open Model Zoo資源配合OpenVINO所需素材
預訓練模型Pre-Trained Models
Pre-Trained Models分為兩個來源:Intel與Public。Intel提供的模型比較偏向特定應用,在已經預想好的應用情境之下訓練與調教特定功能AI模型。好比車輛屬性模型可以判定車子的顏色與種類,適合運用在出入口攔檢站;而年齡與性別預測的模型則方便應用在智慧零售,借此判定各類銷售商品的受眾喜好。
Public則是來自於其他公開的AI模型,比較屬於一般用途。諸如經典的MobileNet影像分類、YOLOv4物件偵測、Mask R-CNN實例分割,以及其他Speech Recognition語音識別、Depth Estimation深度預估等模型。接下來的篇幅會列舉一些有趣的預訓練模型與應用範例與各位分享。

預訓練模型分類
常見的電腦視覺任務
在找尋可應用的模型之前,我們先回顧一下目前在深度學習領域當中經常處理的電腦視覺任務,包含影像分類、圖像分割(語義分割)、物件偵測與實例分割。影像分類可以說是最基礎的電腦視覺任務,即便實用度不高,但卻是深度學習演算法很重要的根基。
由於分類模型只能夠針對一張圖像得出一個分類結果,若影像當中有兩種以上類別,則會造成失準產生錯亂。因此開始發展出了圖像分割的模型,其先把圖片中的所有像素進行分群,再把每一群進行影像分類。雖然這麼做能個在同一張圖像裡面找到多個物件,但是付出大代價就是龐大的運算量,除了效能不彰外,能個分類出來的類別也是相當受限。
接著就發展出了物件偵測,藉由演算法先找到可能物件的所在區域,再進行分類運算,除了分類的物件種類有效提升外,並且也足以做到即時的影像運算了。最終則是實例分割,其功能除了物件偵測外,還可以將物件切割成像素等級,並且記錄下個物件不同的ID以利進行連續影像的追蹤。
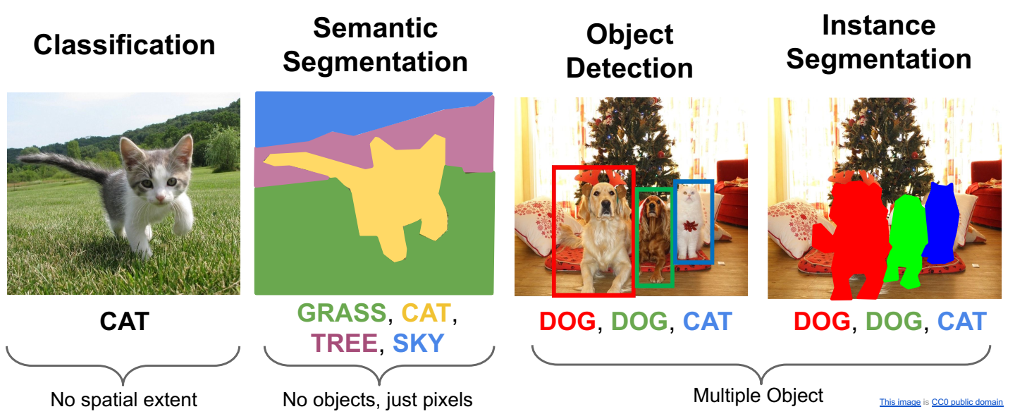
常見的影像視覺任務(source: CS231n Stanford University)
影像分類模型(Classification Models)
Public Pre-Trained Model中包含將近八十種經典的影像分類模型,都是以ImageNet這個大型影像資料集的一千種分類的圖像資料進行訓練,其中也不乏Top-1 Accuracy第一順位精確度超過八成以上的模型。
影像分割模型(Semantic Segmentation Models)
如同前面介紹影像視覺任務所提及,影像分割的運算量龐大且辨識物件種類不多,即便如此,若是我們鎖定一個應用領域,讓其只辨識特定幾種必要物件,其實仍有不錯的實用價值的。像是在封閉道路上運行的車子,我們也許只要能判讀出馬路、路沿石、標線、車子等幾個重要物件,其實也就能做到自動導航或是輔助駕駛等功能了!別忘了,有許多震驚世人的創新也都是使用一些早期技術再加上一點新概念罷了!

人臉偵測模型(Face Detection Models)
Open Model Zoo包含為數不少的人臉偵測模型,可以看出命名規則為face-detection-xxxx-nnnn,其中xxxx是應用領域,如ADAS(Advanced Driver. Assistance Systems先進駕駛輔助系統)、Retail智慧零售等。而nnnn則是版本代號,不同版本之間用的深度學習框架、參數量、計算量、準確度、輸入影像大小等可能都會有所不同,可以進一步從官方文件資料去比對。
經常會一起與人臉偵測模型搭配應用的則有Head Pose Estimation頭部姿勢估算與Gaze Esimation眼神凝視估算。頭部姿勢模型可以抓取人臉是仰望、俯瞰或是側臉等資訊;凝視模型則可以取得人物眼神觀看的角度。藉由使用這些的搭配可以套用的應用情境就相當廣泛了,譬如在零售店鋪當中,我們可以估算消費者對特定產品的好奇心以及注視的時間長短,用客觀數據分析不同性別年齡對商品的喜好程度,藉以提高銷售成功率或是新產品推出時的目標客層設定。


人體偵測模型(Person Detection Models)
辨識與標記人體的模型可說是最廣泛的AI模型之一,不但可以用於監視攝影機系統來判讀是否有人員進出或入侵,也可以應用於人流管制統計等應用。除此之外Intel也有提供適合應用在特定場域的人體偵測模型,譬如偵測教師動作(站立、寫板書或展示)與學生動作(舉手、筆記、站立、坐下)等。
將以上模型整合後就是智慧教室應用範例的內容了!這樣的應用可以觀察在教室內學員與老師的互動狀態,以及可以分析在講授那一段課程時學生特別專注或是特別不投入,藉此能讓老師有所反饋來進一步調整教學方式。

人物屬性模型(Person Attribution Models)
人物屬性模型可以識別出人物的客觀資訊,如衣著顏色、衣著長短、性別、有無背包、衣褲長短等訊息,有了此類訊息可以有效協助警方處理社會案件,好比從路口監視器中的影像透過走失者的衣著特徵進行尋人,或是追查嫌犯都可以在短時間收斂出可能的行跡,藉此提高辦案效率。
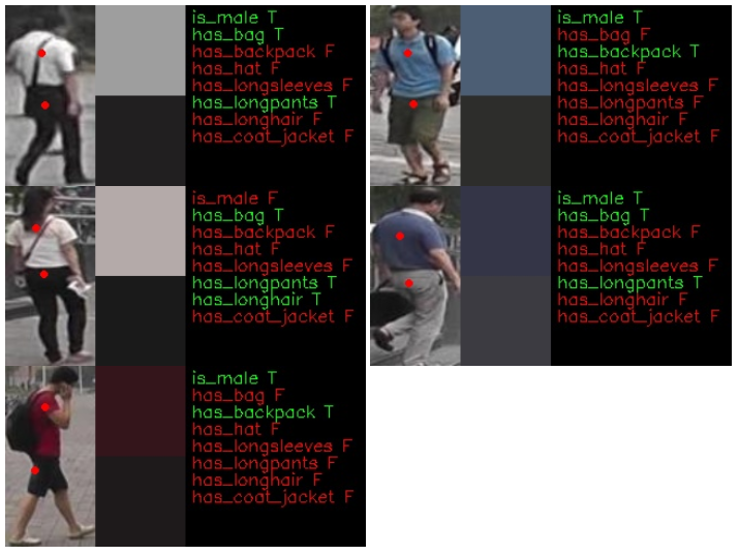
人體姿勢預估模型(Human Pose Estimation Models)
人體姿勢模型可以辨識出人體外,還可以標記出十餘種重點位置,像是眼睛、耳朵、鼻子、肩膀、手肘、手腕等。在應用上可做為運動選手的姿勢糾正輔助工具,協助選手調整運過程的姿態,提高表現能力並且減少運動傷害等。又或者是能做為互動式裝置藝術的輸入資訊。

物件偵測(Object Detection Models)
除上述幾種算是變種的物件偵測模型外,Open Model Zoo自然也少不了經典的物件偵測模型,在Public Pre-Trained類別內提供38種實用的物件偵測模型,依據訓練的資料集來源不同可以偵測出20或90種不同類型的物件。許多時候在一般的應用情境當中,直接套用現成的物件偵測模型就已經足以應對多數狀況了!

SSD MobileNet V2物件偵測模型應用
實例分割(Instance Segmentation)
實例分割是目前機器視覺任務中最為複雜運算量最大的一個項目,因為其對於影像細節掌握更為要求,導出更貼近人眼實際觀看的結果,也是現今自駕車或是輔助駕駛最常使用的視覺模型之一。主流演算法多以Mask R-CNN搭配ResNet或EfficientNet等不同的CNN神經網路組建而成。資料集則是使用有80或90分類的COCO進行訓練。Open Model Zoo有提供10個實例分割的預訓練模型可以運用。(包含Intel Pre-Trained 5個與 Public Pre-Trained 5個)

小結
本篇零零總總看了不少Open Model Zoo裡面的模型,但其實在此專案裡面仍有不少模型還未提及的,除了常見的視覺任務外,還有像景深判讀、文字識別、影像重建乃至於到語音分類、文字轉語音等各類模型都有不少潛在的應用機會。有興趣實際操作的夥伴們不妨參考我們前篇在DevCloud上實作OpenVINO推論的文章,直接在雲端體驗OpenVINO各個有趣的模型吧!
(責任編輯:謝涵如)

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


