作者:許哲豪 Jack
上個世紀美國科學家發現一個有趣的現象,許多長期在太空執行任務的男性太空人會產生頭疼、失眠、噁心、情緒低落等症狀,後來發現只要在團隊中加入女性太空人,這個現象便會大幅減低,同時也增加他們的工作效率,於是就有了「男女搭配、幹活不累」的說法產生。
同樣的情況,在電腦視覺開源社群領域以往都單靠 OpenCV 來解決各種影像處理、電腦視覺等問題,近年來隨著「深度學習」技術興起,許多傳統電腦視覺不好處理的問題(如分類、物件偵測、影像分割等)漸漸地也得到改善。以往這兩大技術各自獨立,OpenCV 為整合「深度學習」這項技術, 2017 年 8 月推出 3.3 版,大幅提升 DNN(Depp Neural Network)的模組功能,加入許多常見框架(如 Caffe、TensorFlow、Torch7)與常見模型(如 AlexNet、VGG、ResNet、SqueezeNet),造福許多開源社群的開發者。
(圖片來源:OpenCV Tutorial C++)
2018 年 Intel 推出開源電腦視覺推論及神經網路工具包(OpenVINO)更直接將 OpenCV 整合進去,同時給予非常靈活的彈性應用,讓兩者可各自獨立工作,亦可部份整合或緊密整合,充份體現「OpenVINO 與 OpenCV 搭配,幹電腦視覺的活一點都不累」的精神。

(圖片來源:Forbes)
依據 OpenVINO 的官網教學文件,雖然有給出 OpenVINO 和 OpenCV 各自的範例程式,但對整合測試部份仍沒有太完整的說明,而之前有一些網友誤會用 OpenVINO 自帶的 OpenCV 載入常見框架模型就能發揮其跨硬體平台(CPU、GPU、FPGA、VPU)的特性,因此想藉由這篇文章提供大家一些範例程式,並幫大家比較一下其中差異及執行效能優劣,希望能讓大家在後續使用時更清楚如何整合應用。
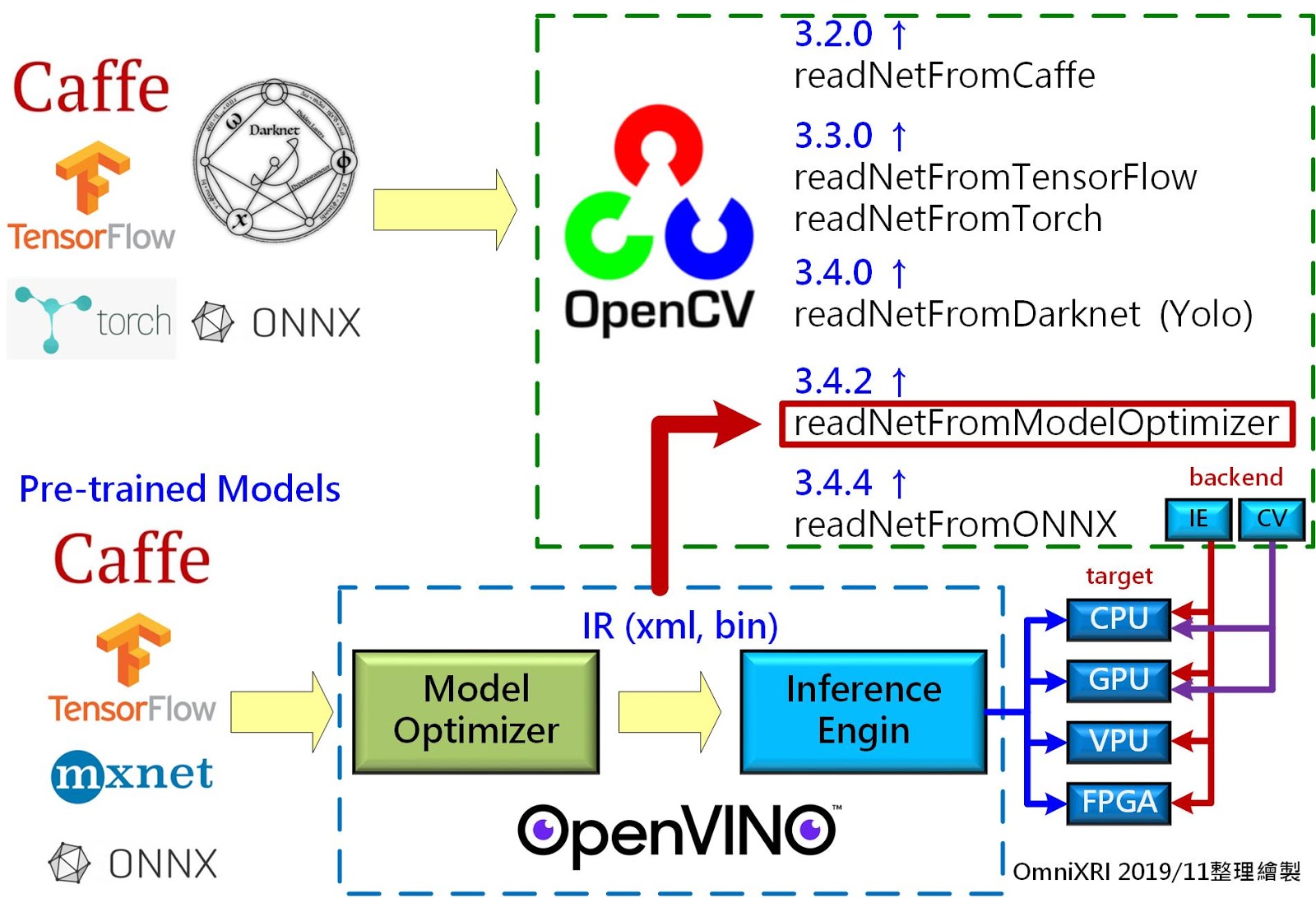
OpenVINO與OpenCV讀取深度學習模型及執行示意圖(OmniXR整理繪製)
首先介紹如何執行一個常見的深度學習模型,如下圖所示大致有三種作法:
1. 將常見框架(Caffe、TensorFlow、MxNet、ONNX)產出的模型透過 OpenVINO 的模型優化器(Model Optimizer,MO)轉換成專用的中介表示檔(Intermediate Representation,IR),即*.xml、*.bin 格式檔案,再透過 OpenVINO 推論引擎(Inference Engine,IE)交由各種不同裝置(如 CPU、GPU、VPU、FPGA)進行推論。
2. 利用 OpenCV ReadNetFromModelOptimizer 函式(3.4.2 以上版本才有支援)直接讀取OpenVINO 模型優化器(MO)產出的 IR 檔案(xml、bin)進行推論工作,但記得執行前需指定後台(Backend)為 DNN_BACKEND_INFERENCE_ENGINE(不能設為 DNN_BACKEND_DEFAULT 或 DNN_BACKEND_OPENCV)及執行目標(Target)為 DNN_TARGET_CPU、DNN_TARGET_GPU 或 DNN_TARGET_MYRIAD。
3. 將常見框架(Caffe、TensorFlow、Torch7、DarkNet、ONNX)產出的模型直接交由 OpenCV 專屬的函式 ReadNetFromXXXX(XXXX 表示不同框架)讀取,並指定計算後台及目標執行後續的推論工作。若指定後台為 IE 形式,則目標可像 OpenVINO IE 一樣執行,能在 CPU、GPU、VPU 上執行,主要使用 Intel MKL-DNN, clDNN, Movidius VPU 函式庫進行加速運算工作;若指定後台為預設(DNN_BACKEND_DEFALUT、DNN_BACKEND_OPENCV)則只能使用 CPU(SSE, AVX, parallal_for 指令集)及 GPU(OpenCL, OpenCL_FP16)運行。
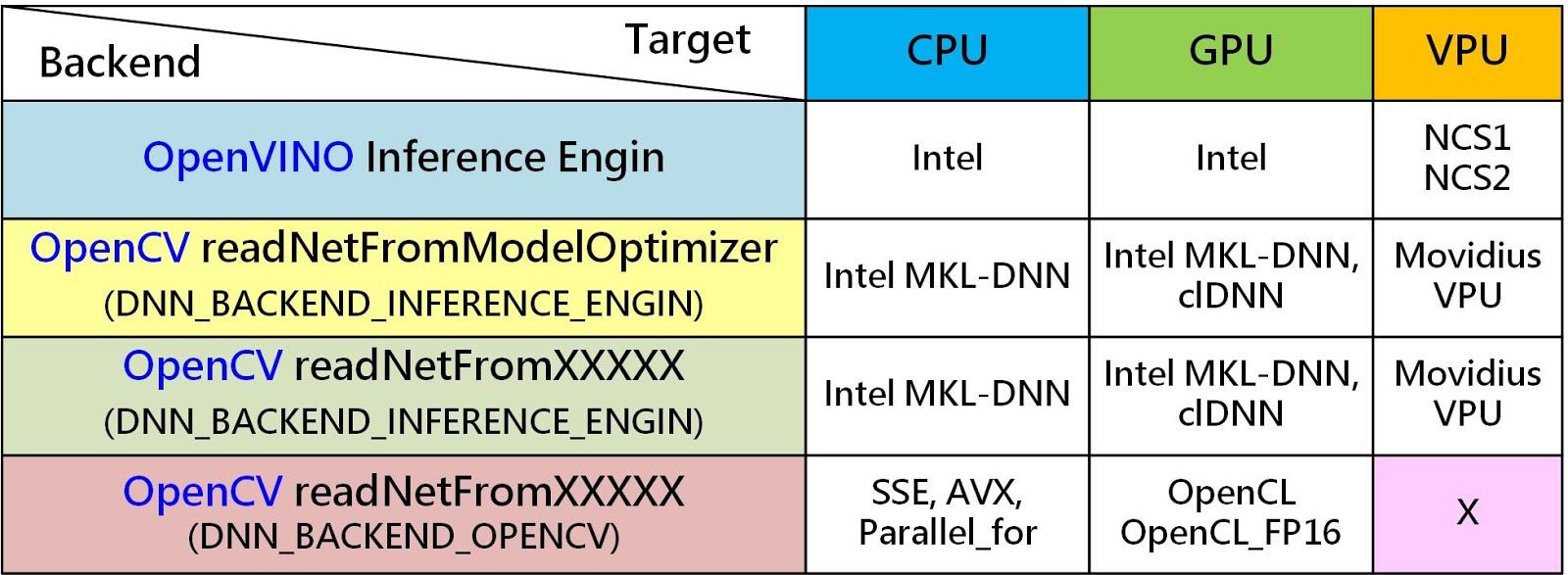
不同執行後台及目標平台支援項目。(OmniXR整理製作))
由上表可看出,若單獨使用 OpenCV,其支援性不如 OpenVINO 來的完整,因此若想使用 Intel OpenVINO 提供的預訓練模型 IR 檔,那麼使用 OpenCV ReadNetFromModelOptimizer 函式便是最簡易的方式,不過這種方式的執行效能會略低於直接使用 OpenVINO。
當如果完全不使用 OpenVINO 情況下也是可以透過 ReadNetFromXXXX(XXXX 表示不同框架)讀取特定框架產生的模型,再利用 CPU 及 GPU 進行推論,這樣雖然有較大的使用彈性,但卻會失去一些執行效率。
另外 OpenVINO 只能處理深度學習的推論工作,但推論前的讀取影像(靜態圖檔或動態視頻)、事前處理(如調整尺寸、色彩等)及推論後在結果影像上繪製文字、圖框、像素著色等工作還是得仰賴 OpenCV 的繪圖指令完成,至於推論結果的數據(矩陣資料)處理工作則需靠像 Numpy 或其它矩陣(向量)函式給予協助。
範例程式說明
接下來就以 Python 程式為例,簡單說明三種方式使用上的差異。這裡主要是利用 OpenVINO 2019 R2 版本的自帶範例做為基礎再進行修改:
C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\inference_engine\samples\python_samples\classification_sample\classification_sample.py
OpenVINO 這個版本自帶的 OpenCV 為 4.1.1 版,而這個範例主要應用的預訓練模型是 SqueezeNet Version 1.1 版 Caffe 框架產出的模型,其訓練資料集為 ImageNet 1000 分類資料集。由於透過 OpenVINO Model Downloader 下載時只能得到 IR 檔(*.xml、*.bin)及 1000 分類標籤檔(*.labels),因此如果要給 OpenCV 直接使用,還需另外至 Github OpenCV Model Zoo Public 下載原始 Caffe 訓練好的 SqueezeNet1.1 模型*(.prototxt、*.caffemodel。
測試時會提供一張「car.png」的跑車圖檔,輸出結果會產生 1000 類的機率(或稱置信度),經排序後會顯示機率前五名的分類識別碼(ID),機率值(probability)、標籤說明文字及各階段的花費時間,以方便大家比較其中地差異;這邊為了說明差異,只秀出呼叫推論函式最主要的程式碼,省略推論結果的顯示部份。
三種不同推論方式完整程式說明及模型、權重、標籤檔請參考 OmniXRI Github。
- classification_openvino.py
直接讀取 IR 檔(*.xml、*.bin)並使用 OpenVINO 推論引擎進行推論。使用此方式仍需執行 OpenVINO 環境變數設定檔「C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\bin\setupvars.bat」,不然會報錯找不到相關檔案。
model_xml = "squeezenet1.1.xml" #指定IR模型檔(*.xml)
model_bin = "squeezenet1.1.bin" #指定IR權重檔(*.bin)
ie = IECore() #建立推論引擎
net = IENetwork(model=model_xml, weights=model_bin) #載入模型及權重
input_blob = next(iter(net.inputs)) #準備輸入空間
out_blob = next(iter(net.outputs)) #準備輸出空間
net.batch_size = 1 #指定批次讀取數量
n, c, h, w = net.inputs[input_blob].shape #取得批次數量、通道數及影像高、寬
image = cv2.imread("car.png") #指定輸入影像
image = cv2.resize(image, (227, 227)) #統一縮至227x277 for Squeezenet
image = image.transpose((2, 0, 1)) #變更資料格式從 HWC 到 CHW **重要**
exec_net = ie.load_network(network=net, device_name="CPU") #載入模型到指定裝置(CPU, GPU, MYRIAD)並產生工作網路
res = exec_net.infer(inputs={input_blob: image}) #進行推論,輸出結果陣列大小[1,1000,1,1]
- classification_opencv_ir.py
利用 OpenCV ReadNetFromModelOptimizer 函式直接讀取 OpenVINO IR 檔案(*.xml、*.bin)進行推論工作,使用此方式也需執行 OpenVINO 環境變數設定檔「C:\Program Files(x86)\IntelSWTools\openvino_2019.2.242\bin\setupvars.bat」,不然會報錯找不到相關檔案。
model_xml = "squeezenet1.1.xml" #指定IR模型檔(*.xml)
model_bin = "squeezenet1.1.bin" #指定IR權重檔(*.bin)
net = cv2.dnn.readNetFromModelOptimizer(model_xml, model_bin); # 讀取IR檔
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_INFERENCE_ENGINE) #設定後端平台(只能設INFERENCE_ENGINE)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) #設定目標執行裝置(CPU, OPENCL, OPENCL_FP16, MYRIAD, FPGA)
image = cv2.imread("car.png") # 讀取輸入影像
out_blob = cv2.dnn.blobFromImage( #取得輸出格式[1, 3, 227, 227]
image, #輸入影像
scalefactor=1.0, #輸入資料尺度
size=(227, 227), #輸出影像尺寸
mean=(0, 0, 0), #從各通道減均值
swapRB=False, #R、B通道是否交換
crop=False) #影像是否截切
net.setInput(out_blob) # 設定網路
res = net.forward() #進行推論,輸出結果陣列大小[1,1000,1,1]
- classification_opencv_caffe.py
直接由 OpenCV 專屬函數 ReadNetFromCaffe 讀取 Caffe 訓練好的模型(*.prototxt、*.caffemodel),指定計算後台(BACKEND)及目標(TARGET)即可進行推論工作。這裡的後台可選擇 Intel OpenVINO的推論引擎或預設後台,當使用預設後台(DNN_BACKEND_DEFAULT 等於DNN_BACKEND_OPENCV)時只能支援 CPU 及 GPU;若選擇 OpenVINO INFERENCE_ENGINE 時,則目標執行裝置就可包括 CPU、GPU、VPU、FPGA,另外也請記得執行 OpenVINO 環境變數設定檔 「C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\bin\setupvars.bat」,不然會報錯找不到相關檔案。
prototxt = "squeezenet_v1.1.prototxt" #指定Caffe格式參數檔
caffemodel = "squeezenet_v1.1.caffemodel" #指定Caffe格式模型檔
net = cv2.dnn.readNetFromCaffe(prototxt, caffemodel) #載入Caffe模型
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) #設定後端(DNN_BACKEND_DEFAULT, DNN_BACKEND_HALIDE, DNN_BACKEND_INFERENCE_ENGINE, DNN_BACKEND_OPENCV, DNN_BACKEND_VKCOM)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) #設定目標執行裝置(DNN_TARGET_CPU, DNN_TARGET_OPENCL, DNN_TARGET_OPENCL_FP16, DNN_TARGET_MYRIAD, DNN_TARGET_VULKAN, DNN_TARGET_FPGA)
image = cv2.imread("car.png") # 讀取輸入影像
out_blob = cv2.dnn.blobFromImage( #取得輸出格式 [1, 3, 227, 227]
image, # 輸入影像
scalefactor=1.0, # 輸入資料尺度
size=(227, 227), # 輸出影像尺寸
mean=(0, 0, 0), # 從各通道減均值
swapRB=False, # R、B通道是否交換
crop=False) # 影像是否截切
net.setInput(out_blob) # 設定網路
res = net.forward() #進行推論,輸出結果陣列大小[1,1000,1,1]
實驗結果說明
依照上面的範例程式,分別進行測試。
下圖是使用 OpenVINO 讀取 IR 檔在不同裝置下執行的結果,可以看出影像辨識能力(Top5 ID 及機率)幾乎沒有差異,整體執行時間是 CPU 比較快,但單純就推論來看則是 GPU 較快,這其中最大的差別就是模型的載入時間,若只讀一張圖測試,GPU 推論整體執行時間就沒有優勢,但若大量執行或是讀視頻時,那模型載入時間就可忽略不計。
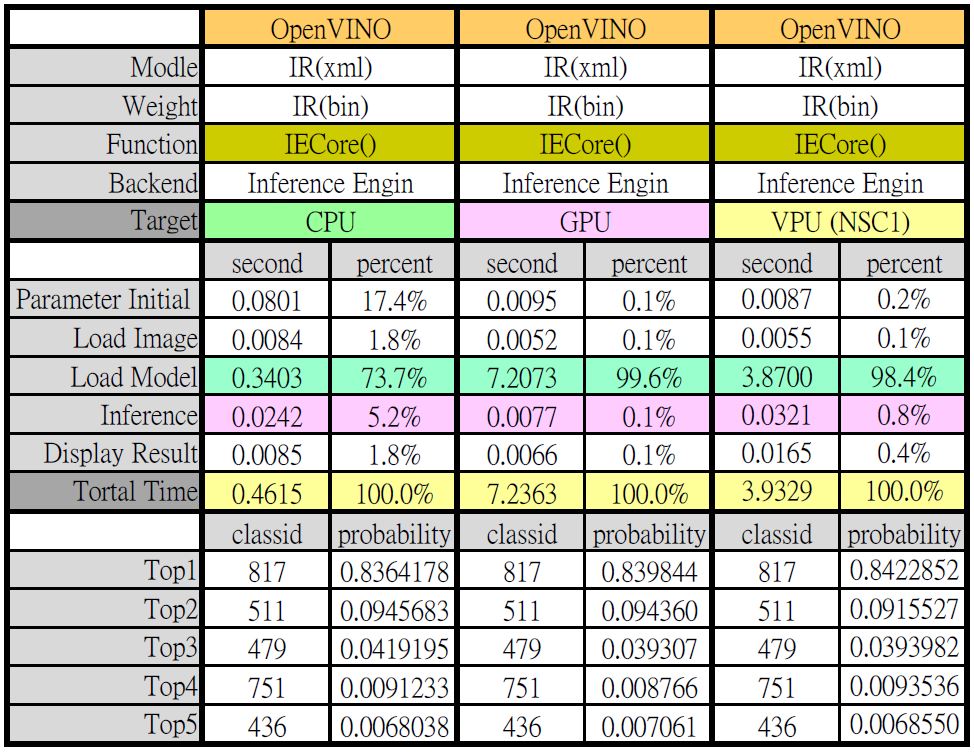
使用 OpenVINO 直接讀取 IR 檔,並在不同裝置上執行(圖片來源:Jack 提供)
下圖是使用 OpenCV 配合 ReadNetFromModleOptimizer 函式直接讀取 OpenVINO IR 檔並在不同裝置上的執行結果。同樣地,影像辨識能力(Top5 ID 及機率)幾乎沒有差異,但這裡出現一個奇怪的現象,GPU 的推論時間明顯變高許多,有些不合理,至於是什麼原因造成,可能需要更多實驗來分析,這裡暫不下結論。
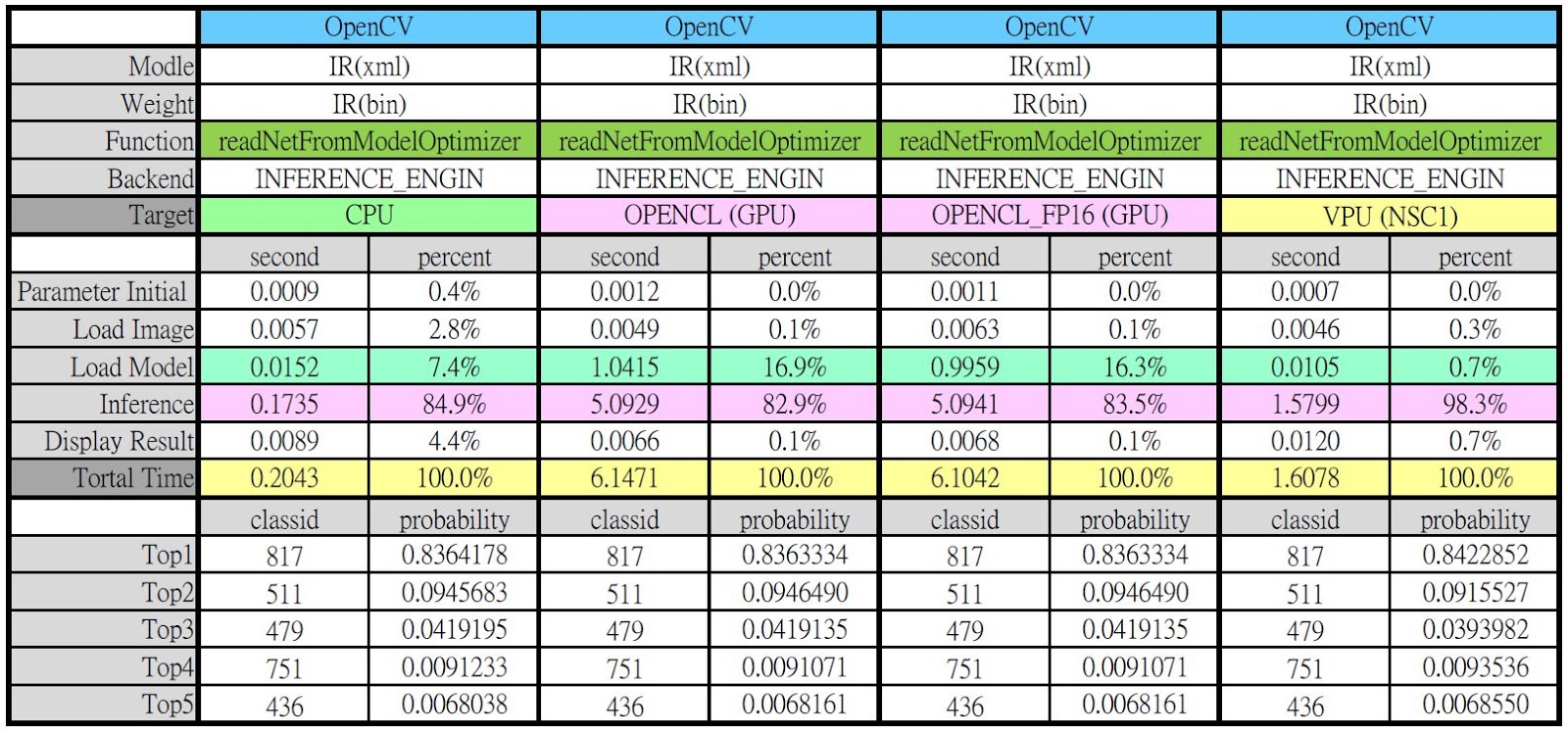
使用 OpenCV 直接讀取 IR 檔,並在不同裝置上執行(圖片來源:Jack 提供)
下圖是使用 Caffe 產出的 Squeezenet 模型在不同後台(OpenVINO、OpenCV)相同裝置(CPU)下執行的結果。由數據可看出,影像辨識能力(Top5 ID 及機率)幾乎沒有差異,若從整體時間表現來看,OpenCV 直接讀取 Caffe 模型執行推論效率最好,但只從推論表現來看則是 OpenVINO 最快,其中最主要的差異就是讀取模型的時間。

不同方式執行Caffe產出之Squeezenet模型結果。(OmniXR整理製作)
最後以 OpenCV 直接讀取 Caffe 模型並在不同裝置(CPU、GPU)進行推論,如下圖所示,影像辨識能力(Top5 ID 及機率)幾乎沒有差異,但這裡同樣發生 GPU 計算耗時比 CPU 多出許多的問題,有待更進一步研究其造成的原因。
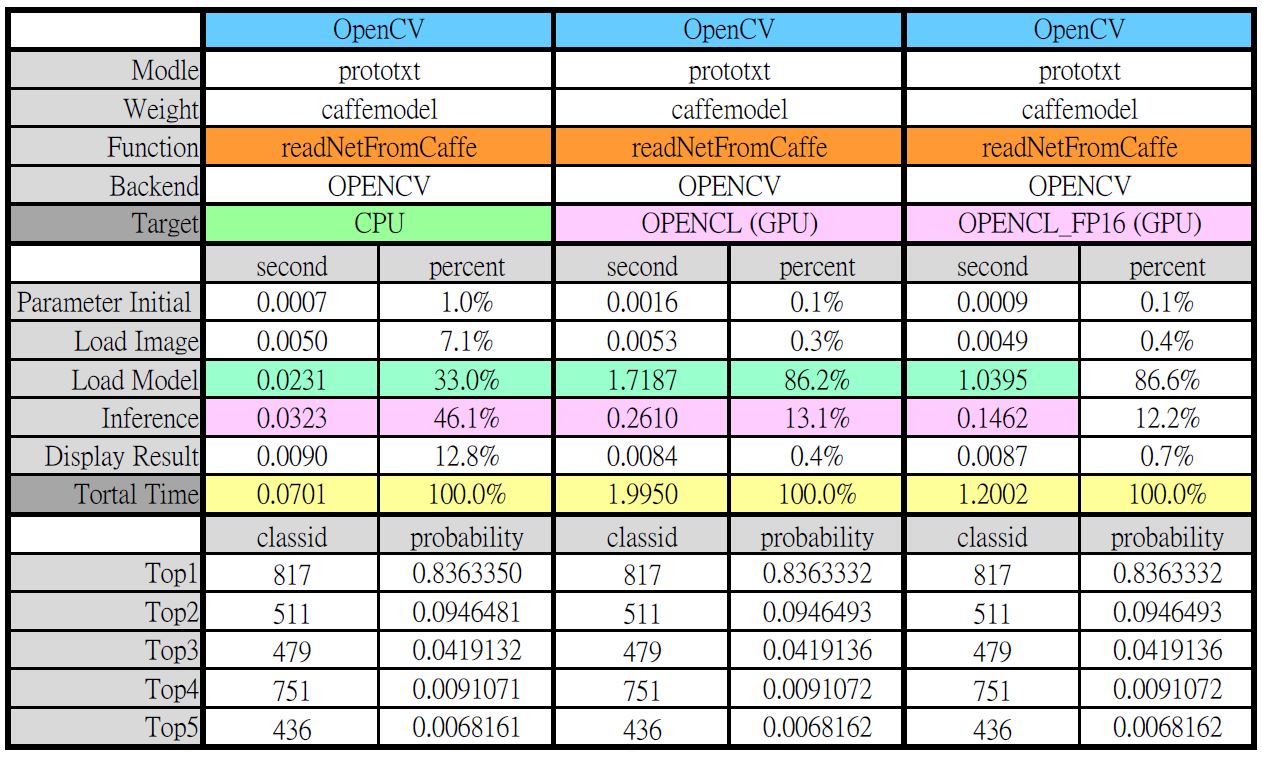
OpenCV直接讀取Caffe模型在不同裝置執行結果。(OmniXR整理製作)
小結
OpenCV 以往是電腦視覺中最不可或缺的開源工具,如今新增了 OpenVINO 這項開源工具更能強化「深度學習」技術在電腦視覺的相關應用,只要有效搭配 OpenCV 和 OpenVINO,從此電腦視覺的活就怎麼幹都不會累了!
參考資料
- OpenCV DNN 模組線上說明文件(version 4.1.1)
- OpenVINO 線上說明文件(version 2019_R2)
- OpenCV 之 DNN 模塊,實現深度學習網絡的推理加速
- OpenVINO Toolkit Image Classification Python Sample
- Github OpenCV Open Model Zoo Models Public SqueezeNet version 1.1
(本文轉載自歐尼克斯實境互動工作室、原文連結;責任編輯:賴佩萱)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2020/12/20
一年後看到這篇文章, 直接用yolo的設定檔跟模型直接跑OpenVINO已經可以直接支援, 感覺OpenVINO的OpenCV套件也很厲害, 是個很有趣的組合 😀