作者:許哲豪 Jack
近幾年「人工智慧(AI)」相關技術已逐漸進入大家的生活中,不論食衣住行、各行各業只要加上「智慧(智能)」二字馬上就變得厲害起來,而想要實現這些,主要得靠「算力」、「算法」、「資料集」及「領域知識」等四大領域技術的完美整合。
幸運地是隨著軟、硬體技術日益成熟及價格快速下降加上開放資料集及預先訓練好的深度學習模型的普及,如今創客(Maker)們想自己動手做(土炮)一些具有人工智慧的創意作品已不再是遙不可及。
去(2018)年五月英特爾(Intel)推出一項免費、跨硬體(CPU、 GPU、FPGA、VPU)、跨深度學習框架(如 TensorFlow、Caffe、Mxnet、ONNX 等)的開放電腦視覺推論及神經網路(深度學習)優化工具包 OpenVINO™ Toolkit(Open Visual Inference & Neural Network Optimization Toolkit)後便受到許多關注。
小弟也不免俗的操作了一波,利用它預訓練好的影像語義分割(Semantic Segmentation)模型進行操作,還寫了一篇「運用 Intel OpenVINO™ 土炮自駕車視覺系統」分享給大家並獲得不少迴響,所以今年想再接再厲更深入探究還有那些玩法,於是挑選了影像「實例分割(Instance Segmentation)」這項技術來實現「智慧監控系統」。
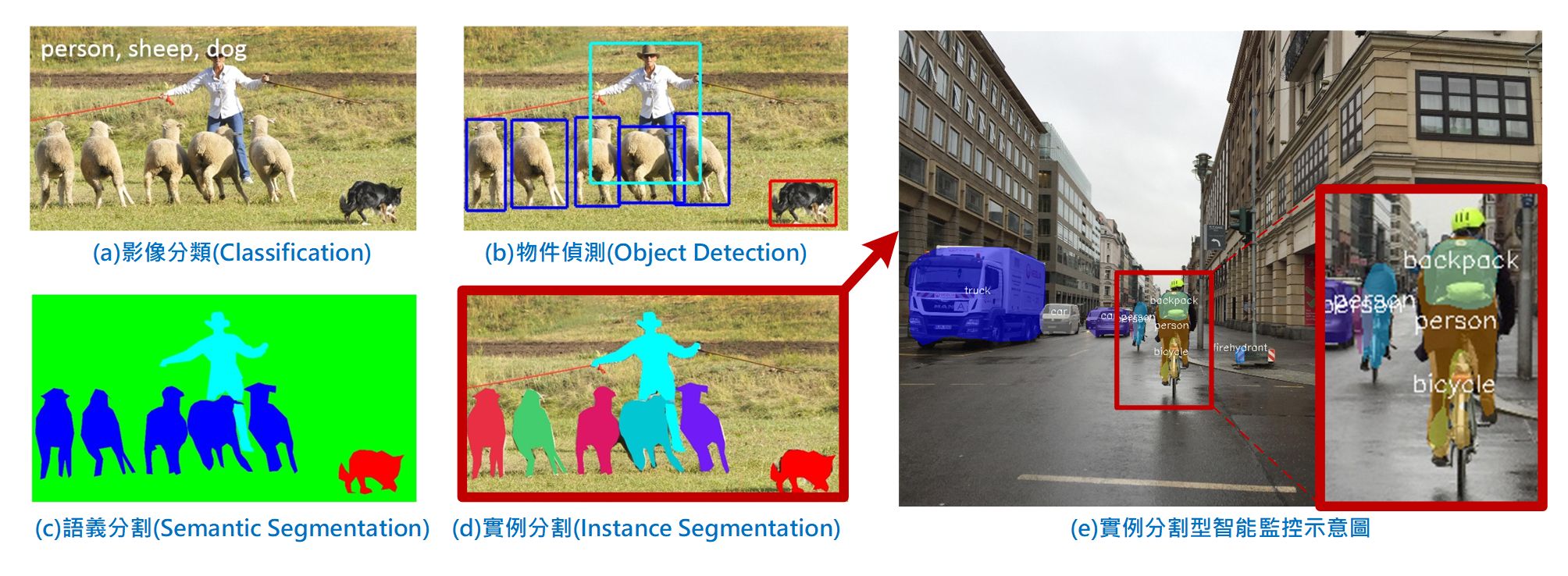
傳統「視頻安全監控(surveillance)系統」只靠攝影機和錄影機組成,主要協助保全人員以視頻方式記錄日常活動及追查可疑人事物,但通常無法提供即時警告。後來逐漸演變成「智慧視頻監視系統(Intelligent Video Surveillance, IVS)」,加入電腦視覺分析功能,藉由各種演算法來完成人臉辨識、人物追蹤、物件偵測、闖入、遺失、遺留等各種功能,以產生即時警示協助保全人員可同時觀察多個場地。
以往這類功能須要靠各種專家來開發,如今有了深度學習的物件偵測技術(如 RCNN, YOLO, SSD 等)(如上圖 b),一般人只需收集夠多的影像及適當標註並加以訓練便可輕易地開發出屬於自己的系統。不過只框出物件位置及辨識內容物的需求越來越不能滿足分析的需求,須要更精準地將物件分割到像素等級,於是就有「語義分割」及「實例分割」技術被產生。
這兩類技術前者只須分辨出物件類型但不區分個體,如上圖 c 所示羊群都被分成同一類(色),而後者如上圖 d 所示則會更精準地分辨出每一個體(實例),如此更能應付真實世界的狀況及對場景中物體及數量的描述。
以往要完成這類技術是非常麻煩地,幸運地是透過 Intel OpenVINO™ 及預訓練模型便可大大降低開發難度,接著就手把手帶著大家來完成「實例分割型智慧監控系統」(如上圖 e)的概念驗證實驗。
OpenVINO™ 系統安裝
去(2018)年 10 月安裝 OpenVINO™ 時是 2018 R2 版,那時還沒提供實例分割預訓練模型。沒想到才過了半年多又升級了五個版本(2018 R3、R4、R5;2019 R1、R2),於是就重新下載安裝 Windows 10 最新版本 2019 R2 版(以下簡稱 19R2 版),安裝程序可參考官方文件或「【AI加速工具】OpenVINO無痛安裝指引」。
此次安裝後發現有一些地方和以前有很大不同,以下簡單說明。
- 舊版預設安裝路徑在 c:\intel,而 19R2 版是在 C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242 下,當執行部份範例程式會產出輸出影像檔,但通常這個路徑有寫入權限限制,會導致看不到輸出結果檔(不准寫入),所以建議先把範例程式複製到其它無寫入管制的路徑下再執行。
- 19R2 版依官方安裝全部程序後,其結果會跑到 C:\Users\ 使用者名稱 \Documents\Intel\OpenVINO 下,之後相關編譯內容(*.exe, *.dll)及下載的預訓練優化模型 IR 檔(*.bin, *.xml)都會在這個路徑下,請記得,以免找不到家。
- 舊版不提供模型本身,只提供預訓練優化模型 IR 檔,且這些檔案會直接放在 X.XXX\deployment_tools\intel_models 下(XXXX.X.XXX 為版本號),可直接使用。而目前 19R2 版由於提供許多模型原始檔案(約 14GB)及預訓練模型優化檔(約 3.8GB),如果全部放入安裝程式會造成檔案太大,所以改成須要時再自行下載。預訓練模型清單可參考官網,更進一步下載及轉檔方式可參考官網說明。如果不想透過程式方式下載亦可直接到官方提供的載點自行選擇合適的項目下載。
影像實例分割範例
為了完成此次任務,很快就在官方文件庫中找到找到 Python 展示範例及預訓練模型「instance-segmentation-security-0050」使用說明。根據文件說明這個模型主要整合了 Mask R-CNN, Resnet 50、FPN、RPN 及 Microsoft COCO 80分類資料集所訓練完成的,模型參數有近三千萬個,推論一次約需46.6 GFLOPS,輸入資料格式可以是靜態影像,動態視頻或電腦上的網路攝影機(webcam)。若輸入為靜態影像則輸出亦是,若為動態視頻則直接在電腦螢幕上顯示結果,包含原始影像及在已識別的物件上著色及顯示物件名稱(如上圖 e)。
一般說到影像公開資料集第一個會想到「ImageNet」,雖然它也有提供影像分割的資料集,但在影像分割上使用「Microsoft COCO」資料集似乎更多一些,因為它的辨識難度略高於 ImageNet。這個資料集在影像分割上共提供了 123,287 張影像, 886,284 個物件(實例),80 個分類(如下圖),包括人、交通工具、街道物件、動物、飾品、運動器材、廚房用品、食物、家具、電子產品、家電、室內用品等,此次用到的預訓練模型就是以此資料集進行訓練。
另外 Microsoft 還提供專屬網頁方便快速查詢類型、編號及下載,本文所引用的測試圖片也是從這裡取得,共取得不同類型 12 張,編號分別為 48850、120103、123921、135666、153368、218716、321539、333407、390073、447574、494913、581061,如有需要更完整的資料集或個別類型的圖檔,可自行查閱。
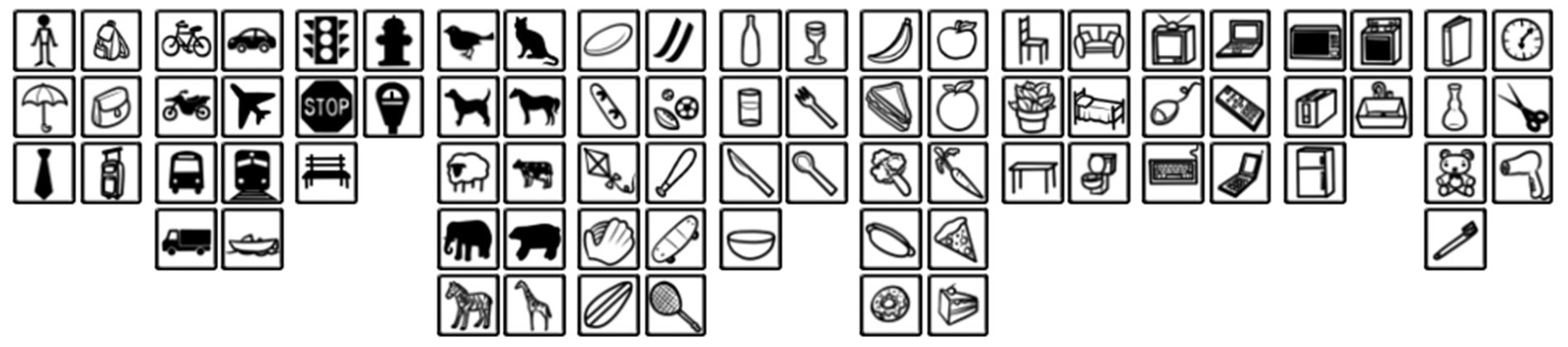
COCO影像分割資料集80分類(圖片來源:source)
接下來就開始說明如何執行這個範例。
- 先下載模型檔(*.bin, *.xml)到指定工作路徑
cd C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\deployment_tools
\tools\model_downloader
python3 downloader.py –name instance-segmentation-security-0050 –output_dir C:\Users\jack_\Documents\Intel\OpenVINO\
一般應該還要執行 converter.py 進行原始模型轉換成 IR 檔動作,但這個模型官方已轉好不須再執行轉換動作,接著模型會被下載到指定路徑下的 \Security 下,再順著 \Security 路徑一直下去最後會看到 /FP16 和 /FP32 兩個檔案夾,分別為不同精度的模型檔。其中 /FP32 下的 bin 檔大約 115MB,而 /FP16 下的 bin 檔約 58MB。原則上 CPU 和 GPU 兩種都可用,而 VPU(神經運算棒 NCS)只能用 FP16。
- 切換至工作目錄執行範例
cd C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\deployment_tools\open_model_zoo
\demos\python_demos
python3 main.py -m C:\Users\使用者名稱\Documents\Intel\OpenVINO\模型所在路徑\FP32\instance-segmentation-security-0050.xml –label coco_labels.txt –image 待分析影像檔名稱.jpg -l C:\Users\使用者名稱\Documents\Intel\OpenVINO\inference_engine_demos_build\intel64\Release
\cpu_extension.dll
其中 -m 是指定模型檔(*.bin, *.xml)所在路徑及模型名稱,而 —label 是 80 分類的標籤檔,方便直接把文字顯示在結果影像上,最後 –image 指定待分析的影像檔名稱,最後的參數亦可變成分析視頻檔案 -v video.mp4 或指定電腦上的網路攝影機 -v 0 (一般攝影機編號為 0)。而最後一個參數 -l(小寫 L) 最為重要,須指定 cpu_extension.dll 的所在位置,缺了它程式就無法正確執行。
經測試多組影像後,發現這組實例分割模型在 FP16 和 FP32 的分割效果表現幾乎沒有差異執行結果(如下圖所示),而執行推論時間在不同影像上結果可能不同,有些時間差不多,甚至 FP32 快 FP16 一點點,而有些 FP16 則快了 FP32 約 1/3 的時間,所以在實驗影像類型(物件數)及反覆執行次數不足下很難判定究竟是否 FP16 一定快過 FP32。
雖然原本在官方文件上在參數表中有 -d 指定工作裝置(CPU、GPU、MYRIAD)的參數,但實際上卻無法執行,一執行就崩潰。經過一番查詢後,最後發現這組模型並不支援 GPU 和 VPU(NCS),所以請下次想使用預訓練模型時先官網確認一下,以免產生無法使用的悲劇。

實例分割結果(上)FP16(下)FP32(圖片來源:Jack提供)
悲劇故事難道到這裡就結束了嗎?就請大家繼續往下看。
Mask R-CNN影像實例分割範例
上述 Python 的範例不能在 GPU 和 VPU 上執行,實在有點令人遺憾。不過在原來那組模型中有提到使用 Mask R-CNN 的核心技術來進行實例分割,所以將其當成關鍵字努力查找官網後,發現其實有提供物件偵測 Mask R-CNN 的實例分割 C++ 範例。本以為只要開啟 Visual Studio 2017 讀入專案檔編譯完後就能執行,但李組長眉頭一皺發覺案情並不單純,因為在 OpenVINO™ 安裝路徑下根本找不到任何專案檔,只能在其下的 \deployment_tools\open_model_zoo\demos\mask_rcnn_demo 下找到範例源碼。
後來才發現 Visual Studio 的專案檔 Demos.sln 竟然跑到 C:\Users\ 使用者名稱 \Documents\Intel\OpenVINO\inference_engine_demos_build 下。開啟後直接進行編譯即可,但記得要選 x64,而編好的執行檔會出現在 \inference_engine_demos_build\intel64\Release 下。這裡除了編譯好一堆執行檔(*.exe)外,另外還會產生兩個重要檔案 cpu_extension.dll、format_reader.dll,缺了它們那些執行檔可就英雄無用武之地了。
接下來想啟動執行檔 mask_rcnn_demo.exe 時,卻發現竟找不到可用模型 IR 檔(*.bin, *.xml),而前面範例的「instance-segmentation-security-0050」在這裡是動不了的。在官網上幾經查找,原來 OpenVION 有提供四組 TensorFlow 原始格式的 Mask R-CNN 的預訓練模型,如下所示。(括號內數值表示模型凍結檔(*.pb)大小)
mask_rcnn_inception_resnet_v2_atrous_coco_2018_01_28 (254 MB)
mask_rcnn_inception_v2_coco_2018_01_28 (64.0 MB)
mask_rcnn_resnet50_atrous_coco_2018_01_28 (138 MB)
mask_rcnn_resnet101_atrous_coco_2018_01_28 (211 MB)
下載解壓縮後發現其檔案包含 Tensorflow 未凍結和已凍結模型檔(*.pb),而 OpenVINO™ 有提供相關工具程式轉換,但可惜的是官方文件中並沒有正確的轉換範例,導致花了好幾天在網路上爬文才找到正確的解決方案,接下來以最小的模型 mask_rcnn_inception_v2_coco_2018_01_28 來說明如何將 *.pb 轉換 IR 格式(*.bin, *.xml)。
- 首先執行轉換 Tensorflow 模型的預備工作
cd C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\deployment_tools\model_optimizer
\install_prerequisites
install_prerequisites_tf
cd..
- 執行模型優化器(Model Optimizer)
Python3 mo_tf.py –input_model Tensorflow原始模型存放路徑\mask_rcnn_inception_v2_coco_2018_01_28\frozen_inference_graph.pb –output_dir 優化模型輸出路徑\mask_rcnn\FP32 –data_type FP32 –batch 1 –tensorflow_object_detection_api_pipeline_config 原始模型存放路徑\mask_rcnn_inception_v2_coco_2018_01_28\pipeline.config –tensorflow_use_custom_operations_config “C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\deployment_tools\model_optimizer
\extensions\front\tf\mask_rcnn_support.json”
其中各項參數作用分別如下:
–input_model 指定 Tensorflow 原始模型凍結檔(*.pb)。
–output_dir 指定 IR 檔輸出路徑,由於可轉換成不同精度(FP16、FP32),所以輸出路徑最好取對應名稱以免找錯。
–data_type 是指定轉換精度可為 FP16 或 FP32。
–batch 依官網說明只能設為 1。
–tensorflow_object_detection_api_pipeline_config 指定 Tensorflow 原始模型之配置檔。
–tensorflow_use_custom_operations_config 指定模型優化器的延伸設定檔
尤其是最後兩項在官網上根本沒說明,導致 IR 檔根本轉不出來,要特別注意。由於一次只能轉一種精度,所以 FP16 和 FP32 要分兩次轉,切記因轉出之檔案名稱相同,所以一定要分兩個目錄存放。若想測試其它三種模型效果,請自行更換輸入模型名稱,如法炮製即可。
好不容易終於可以順利執行了,輸入下面指令,看到結果影像 out0.png 生成,感動到不行。
mask_rcnn_demo -m模型路徑\FP32\mask_rcnn_inception_v2_coco.xml -i 輸入測試影像路徑及名稱
雖然結果影像看起來好像不錯,但卻只有在偵測到的物件上畫了外框和在塗色,卻沒有物件名稱顯示圖上。於是自行修改了原始範例程式,並加上 COCO 80 類標籤及各段程序執行時間計算功能,方便追蹤物件偵測正確性及執行效率,完整程式碼請參考小弟的 GITHUB。
不過事情沒這麼順利,執行後發覺物件外框及塗色部份還算正確,和前一個範例跑出來的結果類似,但標籤名稱可就不這麼正確,有些更是錯的離譜,甚至有些 Class ID 還超過 80,實在讓人難以理解。為了這個問題在網路上爬文快一星期最後終於找到原因,是因為原作最早是分為 92 類,後來去除少用和類似的項目變成 80 類,而目前大部份的人都是採用後者,沒想到這個模型竟然是用最早的 92 分類來訓練,才會導致標籤名稱錯誤,經修正程式改成 92 類標籤對照表後就正常了。
接著用同一張影像以前一個範例和這個範例輸出結果比較,發覺這個範例跑出來塗色的部份位置很不準有時還會少一大塊,於是又上網爬文找答案,花了許久時間,終於在 Intel Developer Zone Forums 找到答案,原來是 OpenVINO™ 預設是 BGR 格式的彩色影像,但有的模型訓練時是採 RGB 格式彩色影色,因此在執行模型優化器轉出時要在最後再上一個參數 –reverse_input_channels 使其反轉,如此才會得到較正確的結果。從下圖中可明顯看出,未反轉色彩前,影像分割的效果明顯有缺失,圖中右邊大象的前腳未能正確被分割出來。

模型優化器色彩反轉影像分割結果(左)未反轉;(右)有反轉(圖片來源:Jack提供)
接著針對不同影像測試 FP32 和 FP16 影像分割結果差異,這部份大部份的影像及被分割的物件差異不大,但有時剛好在檢出門檻附近時,有時檢出物件數量會有所變動。因此損失一點精度來換取運算效率還是可以接受的。
接下來再測試是否可以指定運算裝置參數 -d,分別設為 CPU、GPU 及 MYRIAD(或稱 VPU,即神經運算棒 NCS 一代或二代),結果皆能順利產出,且物件偵測及影像分割結果一致,只有載入模型和推論運算速度不同。本以為使用 GPU 速度會快過 CPU,沒想到推論速度雖有提昇但載入模型速度則慢上許多,載入模型到 VPU 也有同樣問題。因為目前測試每張影像時都重新載入模型所以比較耗時,若載入模型一次而推論數百張,或這一點載入時間可能就能忽略了。
原本以為測到這裡就可以結束了,但突然發現先前用「instance-segmentation-security-0050」感覺上分割效果比「mask_rcnn_inception_v2_coco_2018_01_28」來的好一些,且物件偵測正確性乎也好一點。於是採用和前先類似模型「mask_rcnn_resnet50_atrous_coco_2018_01_28」來進行測試,其結果雖有改善,但不論在速度及分割效果上仍輸「instance-segmentation-security-0050」一些。另外由於這個模型較大,所以只有 CPU 和 GPU 可以執行,而 VPU 則在載入模型時就已崩潰,程式提前結束。各個模型可執行的裝置及執行的精度可參考下表。
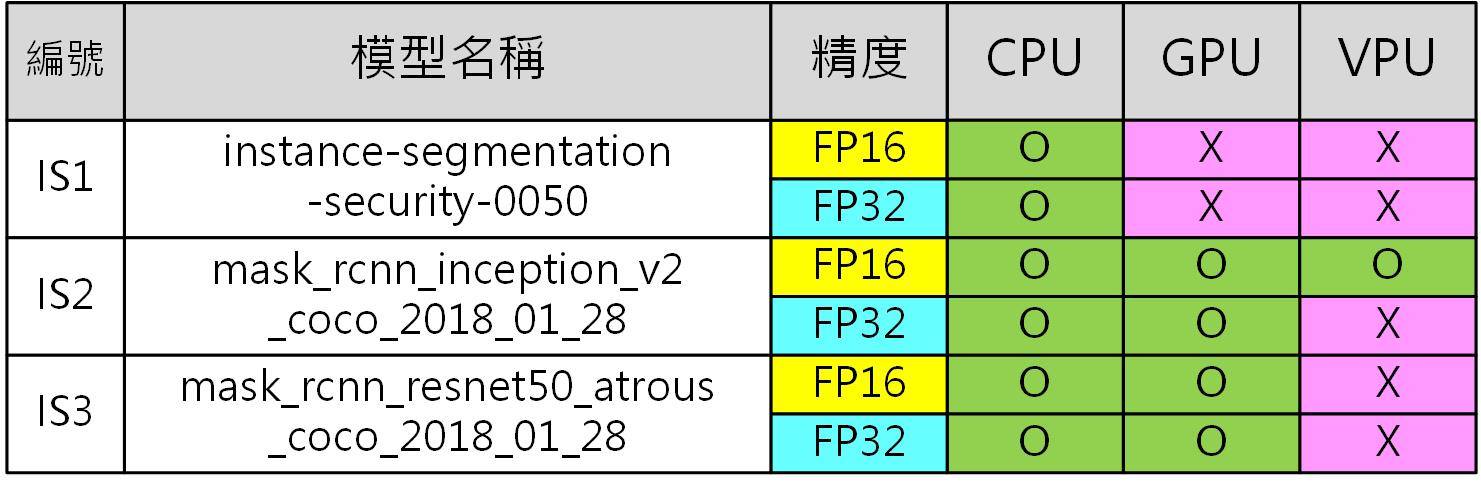
更完整物件偵測及影像分割效果的比較可參考下方圖片。

影像實例分割比較(左)IS1;(中)IS2;(右)IS3(圖片來源:Jack提供)

影像實例分割比較(左)IS1;(中)IS2;(右)IS3(圖片來源:Jack提供)
之前在測試時,不論用 CPU 或 GPU,只要在相同模型及精度時,其物件偵測結果及影像分割結果完全沒差,只有推論速度有差別。但在比較神經運算棒一代(NCS1)及二代(NCS2)執行結果時竟發現有很多差異,以下就簡單說明。
- 偵測到的物件位置雖幾乎相同,但從 7 中可看出在小數點部份明顯有差異。
- 物件偵測到的數量不同部份則可能是物件可信度(機率)剛好在門檻值附近,所以被排除造成數量不同。
- 影像分割的形狀(輪廓)有些許不同,代表每個像素被分配到不同類別時的機率可能因計算出的結果有些微差異造成。
- NCS2 載入模型速度比 NCS1 慢了三十多倍,但推論執行速度則快了三倍多,一般應用來說模型只須載入一次,之後則一直進行推論,因此載入時間就可忽略。
以上狀況個人猜想可能是兩代產品在浮點數計算方式有非常微小的差異,所以當大量矩陣連乘計算後產生誤差,而至於真正的原因為何,就留待 INTEL 工程師慢慢研究了,而我們只需按圖施工就能保證影像實例分割的應用一定成功。

第一代(左)及第二代(右)神經運算棒實例分割比較(圖片來源:Jack提供)
小結
經過數週的努力終於讓影像實例分割可以順利在 Windows 版 OpenVINO™ 上實現,不論是 CPU、GPU 還是 VPU(NSC1 或 NSC2)都能順利執行,透過本文還可了解到如何不踩坑將 Tensorflow 訓練好的模型順利轉換成 OpenVINO™ 能使用的 IR 檔(bin, xml),相信以本文為基礎再發展成更完整、更多加值應用的「智慧視頻監控系統」就不再是難事了。
參考資料
- 【AI_Column】運用Intel OpenVINO土炮自駕車視覺系統
- Microsoft COCO: Common Objects in Context
- OpenVINO pre-trained models (open model zoo) instance-segmentation-security-0050
- Install Intel® Distribution of OpenVINO™ toolkit for Windows* 10
- 【AI加速工具】OpenVINO無痛安裝指引
- Overview of OpenVINO™ Toolkit Pre-Trained Models
- Model Downloader and other automation tools
- Intel OpenVINO Pre-trained models (Open Model Zoo)
- Instance Segmentation Python* Demo
- instance-segmentation-security-0050
- COCO Dataset Explorer
- Inference Engine Demos
- TensorFlow* Object Detection Mask R-CNNs Segmentation C++ Demo
- Converting a TensorFlow* Model
- OmniXRI GITHUB Instance Segmentation
(責任編輯:楊子嫻)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
- 【Arduino UNO Q專欄02】軟體開發初體驗 - 2026/05/21
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2021/07/13
你好,我在第二步時候遇到困難,麻煩指教。
” 2. 切換至工作目錄執行範例
cd C:\Program Files (x86)\IntelSWTools\openvino_2019.2.242\deployment_tools\open_model_zoo\demos\python_demos
python3 main.py -m C:\Users\使用者名稱\Documents\Intel\OpenVINO\模型所在路徑\FP32\instance-segmentation-security-0050.xml –label coco_labels.txt –image 待分析影像檔名稱.jpg -l C:\Users\使用者名稱\Documents\Intel\OpenVINO\inference_engine_demos_build\intel64\Release\cpu_extension.dll ”
我在cmd運行以上後,什麼東西都沒有出現,是不是欠缺了那些步驟?
另外,模型所在路徑是不是隨便開一個folder就可以了?
謝謝
2021/07/13
請問您是否忘了把命令中「中文字」的部份改成您Windows中的真正路徑名稱了呢?或者你是使用2020或2021版本的OpenVINO造成不相容的問題?
由於這篇文章年代較久了,OpenVINO已進展到2021.4 LTS版本了,舊的範例可能無法對應新的版本,建議您可參考下列兩個網址的範例
https://docs.openvinotoolkit.org/latest/omz_demos_instance_segmentation_demo_python.html
https://docs.openvinotoolkit.org/latest/omz_demos_segmentation_demo_python.html
如果這兩個範例仍不容易理解,那也可以參考我在Github上開源的幾個範例,這些範例可直接在Google Colab上直接執行OpenVINO及範例,很方便學習。
其中Colab_OpenVINO_Sound_Segmentation.ipynb較為接近此篇文章的用法。
https://github.com/OmniXRI/Colab_DevCloud_OpenVINO_Samples