作者:Nikita Savelyev、Alexander Kozlov、Ekaterina Aidova與Maxim Prosh
Whisper是OpenAI的通用語音辨識模型,能轉錄多種語言的語音,甚至能處理音質不佳或者過多的背景雜訊;你可以在研究論文、OpenAI部落格、Model Card工具套件以及GitHub儲存庫中找到更多關於該模型的相關資訊。
最近在一篇題為「透過大規模偽標籤進行的穩健知識萃取」(Robust Knowledge Distillation via Large-Scale Pseudo Labelling)的論文中,提出了該模型的萃取衍生版本Distil-Whisper;相較於Whisper,Distil-Whisper的運作速度快了好幾倍,參數量則少了50%,同時其分佈外(out-of-distribution)評估資料的字元錯誤率(word error rate,WER)維持在1%內。
Whisper是以Transformer為基礎的編/解碼模型,也被稱為序列對序列(sequence-to-sequence)模型,能將一個音訊頻譜特徵序列,映射至文字詞元序列。首先,原始音訊輸入透過特徵擷取器(feature extractor)的作用,被轉換為梅爾頻譜(log-Mel spectrogram);接著該Transformer解碼器將頻譜編碼,形成編碼器隱藏狀態的序列;最後,解碼器在先前的詞元以及編碼器的隱藏狀態條件下,自我迴歸(autoregressively)預測文字詞元。
下圖是該模型架構:
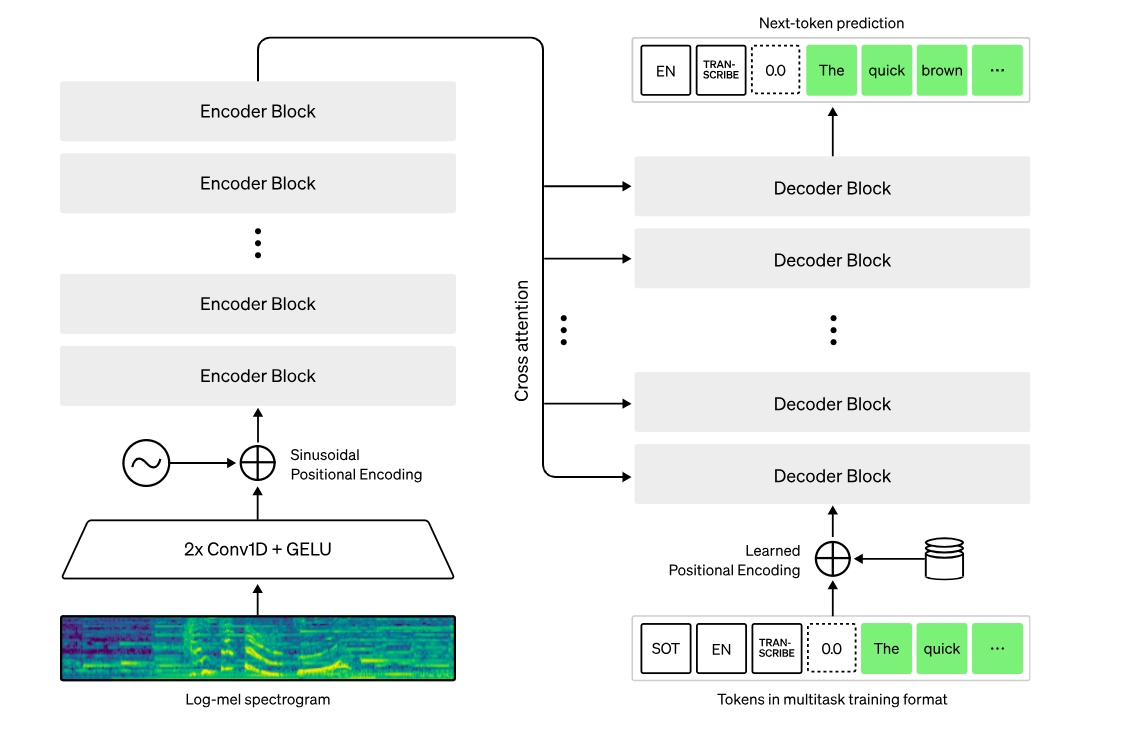
在這篇文章中,我們要示範如何透過Intel硬體與OpenVINO來改善Whisper與Distil-Whisper模型的推論速度;此外我們也會展示以神經網路壓縮框架(NNCF)應用8位元訓練後量化,讓模型運作速度更快。最後我們會從大規模資料集的準確度與性能角度提出評估結果。
本文中呈現的所有程式碼片段都是來自於使用Distil-Whisper以及OpenVINO Jupyter Notebook進行自動語音識別,你可以跟著使用。
將模型轉換為OpenVINO格式
我們將在Optimum Intel程式庫的幫助下從Hugging Face Hub載入模型,這會讓載入與執行針對OpenVINO最佳化的模型更簡單;更多細節可參考Hugging Face Optimum文件。以下的程式碼範例能載入Distil-Whisper large-v2模型,使用OpenVINO進行推論:
from optimum.intel.openvino import OVModelForSpeechSeq2Seq
model_id = "distil-whisper/distil-large-v2"
model_path = Path(model_id)
if not model_path.exists():
ov_model = OVModelForSpeechSeq2Seq.from_pretrained(
model_id, export=True, compile=False, load_in_8bit=False)
ov_model.half()
ov_model.save_pretrained(model_path)
else:
ov_model = OVModelForSpeechSeq2Seq.from_pretrained(
model_path, compile=False)
Distil-Whisper系列的模型可以在這個Distil-Whisper Models集合頁面取得,Whisper模型則能在OpenAI Hugging Face頁面取得。
為了讓載入的模型轉錄輸入音訊,我們首先將模型編譯到選定的裝置,然後透過對應處理器所準備的輸入特徵,呼叫generate()方法:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(model_id)
ov_model.to("AUTO")
ov_model.compile()
# ... load input audio and reference text
input_features = processor(input_audio).input_features
predicted_ids = ov_model.generate(input_features)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(f"Reference: {reference_text}")
print(f"Result: {transcription}")
得出的結果如下,可以看到轉錄的內容等同於參考文字:
Reference: MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
Result: Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.
以NNCF執行訓練後量化
NNCF透過將量化層添加到模型圖(model graph)中,然後利用一個訓練資料集的子集來初始化這些額外量化層的參數。在量化期間,有些層(例如MatMul與Convolution)被轉換為以INT8而非FP16/FP32精度執行;如果量化過的運作被參數化,其相對應的權重變數也會被轉換為INT8。
通常量化程序包含以下步驟:
- 建立量化用的校準資料集;
- 執行quantize()以取得量化過的編碼器與解碼器模型;
- 使用save_model()函數序列化INT8模型。
Whisper模型由編碼器與解碼器子模型組成;此外,對解碼器模型來說,相較於所有後續的呼叫,其forward()簽章與第一次的呼叫是不同的。在第一次呼叫時,鍵值(key-value)快取是空的,不需要解碼器推論;從第二次呼叫開始,鍵值快取被饋送至解碼器。
因為這樣,這兩種情況會以兩個分開的OpenVINO模型呈現:openvino_decoder_model.xml與openvino_decoder_with_past_model.xml;由於第一個解碼器模型只被推論過一次,對於將之量化沒有太大意義,因此我們對先前模型的編碼器與解碼器施行量化。
量化的第一步是收集校準資料,我們需要為兩個模型收集一定數量的模型輸入。為此我們以InferRequestWrapper類別實例(class instance)修補OpenVINO模型請求物件(request objects),那會在推論過程中截取模型輸入,並將它們儲存在一個清單中。我們根據librispeech_asr資料集驗證分割(validation split)中大約50個範例來推論模型。
def collect_calibration_dataset(ov_model: OVModelForSpeechSeq2Seq, calibration_dataset_size: int):
# Overwrite model request properties, saving the original ones for restoring later
original_encoder_request = ov_model.encoder.request
original_decoder_with_past_request = ov_model.decoder_with_past.request
encoder_calibration_data = []
decoder_calibration_data = []
ov_model.encoder.request = InferRequestWrapper(original_encoder_request, encoder_calibration_data)
ov_model.decoder_with_past.request = InferRequestWrapper(original_decoder_with_past_request,
decoder_calibration_data)
calibration_dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
for sample in islice(calibration_dataset, calibration_dataset_size):
input_features = extract_input_features(sample)
ov_model.generate(input_features)
ov_model.encoder.request = original_encoder_request
ov_model.decoder_with_past.request = original_decoder_with_past_request
return encoder_calibration_data, decoder_calibration_data
利用收集到的編碼器與解碼器模型校準數據,我們可以繼續進行量化這件事。透過以下程式碼,我們可以檢驗編碼器模型的量化呼叫;解碼器模型也可利用類似的程式碼。
quantized_encoder = nncf.quantize(
ov_model.encoder.model, # ov.Model object of the encoder model
nncf.Dataset(encoder_calibration_data), # calibration data wrapped in a nncf.Dataset object
subset_size=len(encoder_calibration_data), # number of samples to calibrate on (all are chosen)
model_type=nncf.ModelType.TRANSFORMER, # providing the information that Whisper encoder is of
# a Transformer architecture
advanced_parameters=nncf.AdvancedQuantizationParameters(smooth_quant_alpha=0.50) # Smooth Quant
# algorithm reduces activation quantization error; optimal alpha was obtained through grid search
)
ov.save_model(quantized_encoder, quantized_model_path / "openvino_encoder_model.xml")
在兩種模型都被量化與儲存之後,量化過的Whisper模型能被載入,並以前面展示過的同樣方式執行。以下比較以原始模型以及量化過的模型所產生之轉錄結果:
Original : Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.
Quantized: Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.
你可以看到,量化過的distil-whisper-large-v2轉錄內容是相同的。
評估通用語音資料集
我們以通用語音(Common Voice)13.0版語音轉文字資料集評估Whisper與Distil-Whisper large-v2模型;我們使用的是內含1萬6,372個音訊樣本的en/test分割,總計有27個小時左右的錄音。
評估以三種類型的模型來完成:原始PyTorch模型、原始OpenVINO模型,以及量化過的OpenVINO模型;此外,我們以三種Intel CPU來執行測試:Cascade Lake Intel Core i9-10980XE、Ice Lake Intel Xeon Gold 6338,與Sapphire Rapids Intel Xeon Gold 6430L。
我們量測以上所有組合的轉錄時間與精確度。在針對模型量測時間的時候,我們加總所有音訊樣本的generate()呼叫持續時間;轉錄精確度以Accuracy = (100 – WER)來表示,其中WER為詞錯誤率(Word Error Rate)。我們計算每一個音訊樣本的精確度,並取得整個資料級的平均值;結果如下表所列:
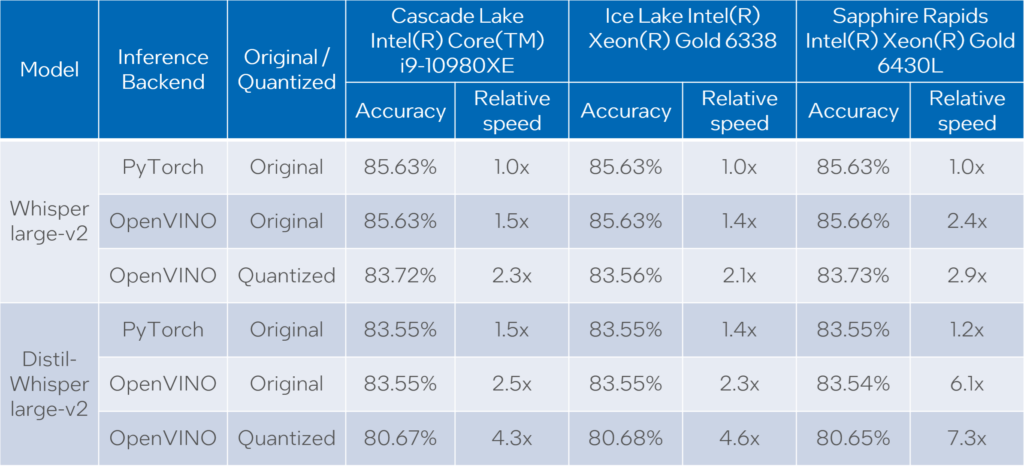
請注意,我們以相對條件來報告轉錄時間,如此一來每顆CPU的值在其相對應的欄位中就被標準化;資料集中音訊資料的持續時間為27.06小時,每顆CPU上的Whisper large-v2 PyTorch絕對轉錄時間分別是:
- Core i9-10980XE為20.35小時;
- Xeon Gold 6338為14.09小時;
- Xeon Gold 6430L為15.03小時。
根據以上結果,我們可以得出以下結論:
- 在所有案例中,OpenVINO模型比PyTorch模型的執行速度快了1.4倍到5.1倍,精確度則幾乎相同;
- 與原始PyTorch模型相較,量化過的OpenVINO模型可提供2.1倍至6.1倍的性能提升,精確度則下降約2~3%。
注意:在這篇文章中,我們聚焦於呈現性能數值;量化後模型的精確度可以透過更仔細的校準資料選擇來改善。
結語
我們示範了如何以OpenVINO與Optimum Intel載入並執行Whisper與Distil-Whisper模型進行音訊轉錄任務,以及如何使用NNCF對這些模型執行INT 8訓練後量化。接著我們在橫跨多種CPU的裝置上,以大規模語音轉文字資料集評估這些模型。
評估結果顯示,OpenVINO模型的性能相較於PyTorch模型有顯著提升,而且轉錄品質沒有損失;當我們運用INT8量化,性能甚至有更進一步的提升,精確度下降幅度也在可容忍範圍內。
注意事項與免責聲明
CPU性能會因為使用、配置與其他因素有所不同,更多資訊請參考: www.intel.com/PerformanceIndex。性能結果是根據截至配置中所示日期的測試,可能無法反映所有公開可用的更新。 沒有任何產品或零組件是絕對安全的。Intel技術可能需要硬體、軟體或服務啟動。文中提及的產品可能包含設計缺陷或勘誤表(errata)中已知的錯誤,這可能導致產品偏離已發布的規格;目前特徵勘誤表可依要求提供。
測試配置:3.00GHz Intel Core i9-10980XE處理器,搭配128GB、3000MHz DDR4記憶體, Ubuntu 20.04.3 LTS作業系統;2.00GHz Intel Xeon Gold 6338處理器,搭配256GB、3200MHz DDR4記憶體,Ubuntu 20.04.3 LTS作業系統;1.90GHz Intel Xeon Gold 6430L處理器,1024GB、4800MHz DDR5記憶體,Ubuntu 20.04.6 LTS作業系統。
上述測試由Intel在2023年12月進行,使用267-distil-whisper-asr notebook匯出模型,以及whisper evaluation notebook進行模型評估。
(參考原文:Optimizing Whisper and Distil-Whisper for Speech Recognition with OpenVINO and NNCF;編譯:Judith Cheng)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


