作者:李盛安
良好的教室秩序,教師才能有效進行授課,使教學達到預期的效果。電腦教室的上課過程是一個特別的狀態,是否利用空檔上網、玩遊戲、使用手機,老師在課堂進行時對學生注意力的掌握,以及課程進行中學生練習的專注力與反應、軟體操作的狀況與學習態度等,若能適時地掌控,相信同學能於課堂間較專注學習,教學效果勢必能增加。
目前智慧教室的發展主要在遠距與同步的學習,採取的策略為軟體教具的操作錄影,以及教師與學生端電腦即時操作與回饋,搭配教材與教學平台,來記錄與觀察學生參與課程的時間、紀錄個別學生的學習路徑、掌握學生交作業與課後練習的進度等。
本文將探討能否透過人工智慧與資訊技術的結合,進一步瞭解學生學習過程中的學習狀況與學習態度的資訊,例如學生課堂操作電腦過程時的情緒反應、是否專注於電腦前練習、每次能專注練習的時間長短、是否離開座位與同學討論等。
1. 電腦教室的數位教學平台環境
在電腦教室的班級經營中,為達到教學現場的即時教學效果,如課堂編組方式,讓程度好的同學與學習較慢的同學協同學習,投影機與廣播系統混合使用,使教與學能有效進行(註1)。近年來許多雲端的小組會議系統,如Google Meet可即時錄影與分享上課的過程,加上電腦教室內多已有投影機與內部廣播系統,可以達到教室與遠距同步學習的狀態。

電腦教室中的上課狀況該如何透過AI來掌握呢?(圖片來源)
然而,對於電腦教室的線下實體班級經營而言,如何能夠對實質學習過程做適度的紀錄,讓老師可掌握課程實體活動過程中的現況,觀察同學於不同單元練習時能專注學習的時間片段,進而對教學進行有系統的單元進度設計,過去這在班級人數多的教學現場是一項挑戰。
同時,電腦教室常會因螢幕或設備遮蔽,或課堂間學生因小組討論而位置互換或任意走動,這在電腦教室的秩序控管上令人困擾。因此,如何能掌握課堂間學生線下學習狀態,進而可提供日後電腦教室班級經營的改善,達成精準教學的效果,是電腦教室班級經營主要目標。
2. 電腦視覺技術與電腦教室教學情境觀察
(1) 電腦視覺的定義(註2)
電腦視覺(Computer Vision)是研究如何使機器「看」的科學,更進一步的說,用攝影機和電腦代替人眼對目標進行辨識、跟蹤和測量等機器視覺,並進一步做圖像處理,用電腦處理成為更適合人眼觀察或傳送給儀器檢測的圖像。
電腦視覺技術,試圖建立能夠從圖像或者多維資料中取得「資訊」的人工智慧系統,可以用來幫助做一個「決定」的資訊。因為感知可以看作是從感官訊號中提取資訊,所以電腦視覺也可以看作是研究如何使人工系統從圖像或多維資料中「感知」的科學。
(2) 電腦視覺技術可提供的電腦教室自動化紀錄環境
電腦視覺辨識技術近年來的進步,提供許多過去認為很難整理與紀錄資料的一種全新的可能性,舉凡已經深入生活中的車牌辨識、人流計數、車流偵測等,許多過去需要高效能計算設備才能運作的機器視覺軟體,經由這些年電腦設備運作效能的不斷提升,同時耗能也相對的降低的狀態下,透過電腦視覺辨識自動化技術,有機會將過去許多只能由原始影像需要經過人工處理與分析的資料,能夠透過全新的資料蒐集技術的思維,將看似雜亂無法整理的許多基礎資料嘗試紀錄下來,之後再透過大數據分析的技術,將原始資料產生可供利用的知識。
在這樣的思維下,是否能夠透過電腦視覺辨識技術,幫忙老師們在教學現場蒐集電腦教室的上課過程與同學的活動狀態,將線上與線下的教學活動過程有效的統整,達成過去課堂無法得到的回饋效果,使現在的資訊技術可以提供一個全新的思維。
3. OpenVINO電腦視覺與深度學習應用開發套件介紹
2018年後Intel推出了一個新的電腦視覺辨識開發架構稱為 OpenVINO™,這個軟體架構採開放原始碼授權,同時搭配多種已經整理過的機器學習模型,電腦視覺辨識模型是其中的一個部分,機器學習模型透過另外一個開發專案也採開放原始碼授權,稱為Open Model Zoo,因此可以透過Intel的OpenVINO™架構,執行大量的電腦視覺辨識模型,只要使用Intel CPU架構的主機就可以執行,這樣的狀態下過去許多使用Intel CPU架構的電腦教室,直接就可以轉作機器學習推論的平台。
OpenVINO™ 的全名是Intel OpenVINO™ Toolkit,是Intel發展的電腦視覺與深度學習應用的開發平台,可支援 Windows、Linux (Ubuntu、CentOS)、MacOS等作業系統,因此在各種作業系統的平台上面都可以安裝與使用,同時OpenVINO™是開放原始碼的專案,所有的原始程式都可以在Github上面免費下載與使用(註3)。
OpenVINO™除了透過Intel CPU的架構執行外,也可使用Intel CPU內建的GPU顯示晶片作為硬體加速功能,所以看起來以為是Intel CPU的執行架構,其實是將多年來CPU內建顯卡的硬體部分功能打開,瞬間過去的電腦就變成了可以加速執行機器學習的機器,除非在需要特別的硬體的加速狀態下,才需要再去加購Intel針對機器學習推論計算加速的外加硬體。
目前已經販售一段時間的NCS2,可以直接插在USB上面就可以透過OpenVINO™進行加速推論的動作。OpenVINO™有一個特性,會使用Intel硬體指令集進行各種矩陣計算加速的動作,同時支援Intel各種版本的硬體推論加速器,如Intel的CPU處理器、FPGA處理器、GEN顯示卡、GNA高斯神經加速器等硬體,因此對於AMD的CPU電腦是無法執行的。
這一點也是採購電腦視覺硬體上的一個考量點,軟體與硬體的整合度通常是矩陣計算以及後續機器學習開發平台在運作方式軟硬體整合的一個重點,進一步的Open Model Zoo提供許多針對Intel硬體加速的矩陣優化模型,可以更有效率的進行電腦視覺的辨識推論動作,在這樣的狀態下,軟體的支援度、機器學習軟體間各種模型轉換的容易程度,是一個需要考量的重點。
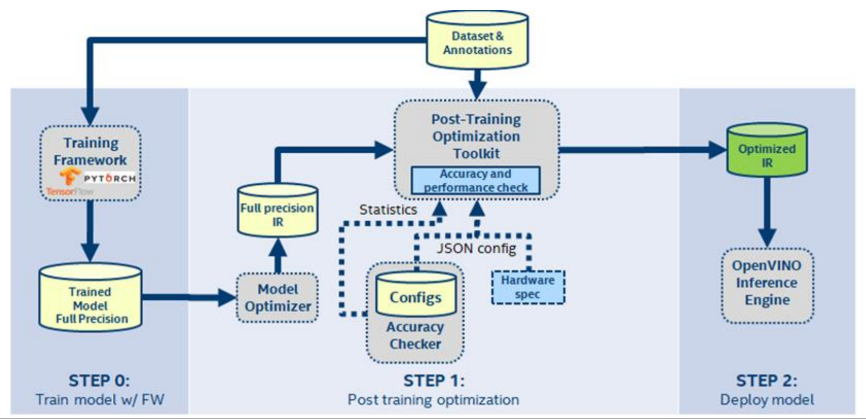
OpenVINO™各種訓練優化工具運作流程
OpenVINO™包含模型優化器和推理引擎,以及各種常見的深度學習運作架構,如Caffe、TensorFlow、Mxnet、ONNX 等訓練好的模型和參數,OpenVINO™主要將Intel本身硬體加速晶片整合起來,進一步的可以執行在各種不同的硬體上,透過Intel的VPU與FPGA的架構,在各種邊緣運算的應用上可達到不錯的效果,同時這樣不同硬體前端都能執行OpenVINO™機器學習開發模式的狀態下,可以大幅度的節省不同機器學習模型套件之間開發的轉換時間。
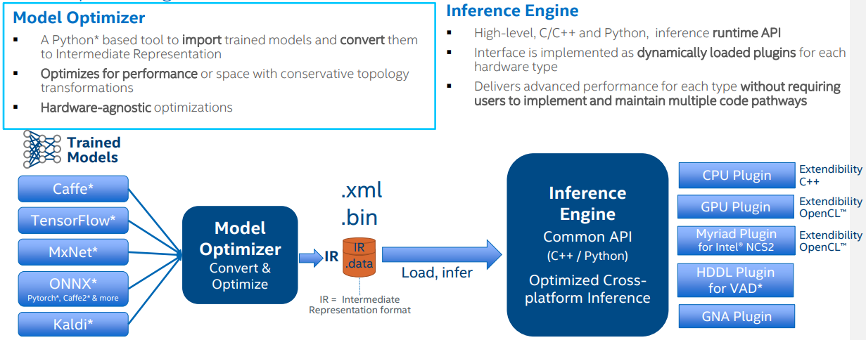
OpenVINO™透過各種框架模型轉換至Inference Engine執行架構
OpenVINO™ 提供的重要功能就是 Model Optimizer 以及 Inference Engine,將訓練好的模型經由 Model Optimizer 生成IR文件(xml 與 bin檔案),若是要使用 Pytorch framework 訓練出來的模型,要先將其轉換為 ONNX 格式,再交給 Model Optimizer 去生成 IR 文件,接著由 OpenVINO™ 的 Inference Engine讀取 IR model 進行推論,使用者就可以透過 OpenVINO™ Toolkit和Inference Engine API 整合至開發的應用程式。
4. Open Model Zoo介紹
Open Model Zoo包括經過優化的深度學習模型和許多的範例程式,希望能夠加快深度學習推理應用的程式開發,Open Model Zoo整理了許多學術上提供的免費預先訓練好的機器學習模型,以及Intel本身預訓練好的不同情境下可使用的電腦視覺模型,因此使用者不需要重新訓練同類型的模型,這樣的過程可以加快許多機器學習的生產與系統建制(註4)。
Open Model Zoo整理好的各種預先訓練好的模型稱為Pre-train Model,之後透過OpenVINO™的模型轉換架構,轉換至OpenVINO™使用的IR運作格式,之後就可以透過Inference Engine執行推論的動作,Open Model Zoo本身已包含許多IR格式的電腦視覺訓練模型,如臉部偵測(Face)、人體偵測(Person)、車輛偵測(Vehicle)、腳特車(Bike)、車牌辨識(License plate)、道路辨識、物件分割、人體骨架特徵點抽取、圖像增強、文字偵測、文字辨識、駕駛人行為等經典的深度學習模型。
Open Model Zoo中包含一個模型下載器,稱為Model Downloader,downloader.py程式可以進行各種模型的下載至使用者端,如果下載的格式不是IR格式,可以使用Model Converter,把Downloader下載的模型轉換為OpenVINO™可以使用的IR格式,最後可以在OpenVINO™中動態的切換運作的模型,針對同樣的輸入資料進行各種不同形式的推論,同時Model Converter可以支援將自己訓練好不同機器學習套件的模型檔案轉換至IR檔,之後可以統一透過OpenVINO™同時呼叫整合各種訓練模型的成果,大量節省整合與開發系統的時間。
Open Model Zoo提供了許多的範例程式,包含C++與Python的程式,使用者可以使用命令列的形式執行,這些程式的原始程式碼對有心學習OpenVINO™各種模型快速地串接使用,以及將程式碼套用至使用者本身開發程式,進而可以很容易地將原本開發系統加入深度學習演算法。同時,透過程式介面可取得原生推論數值,進而很容易地儲存至後端資料庫,最後由視覺化工具繪製成可供參考的圖表,提供人們快速做出決策。
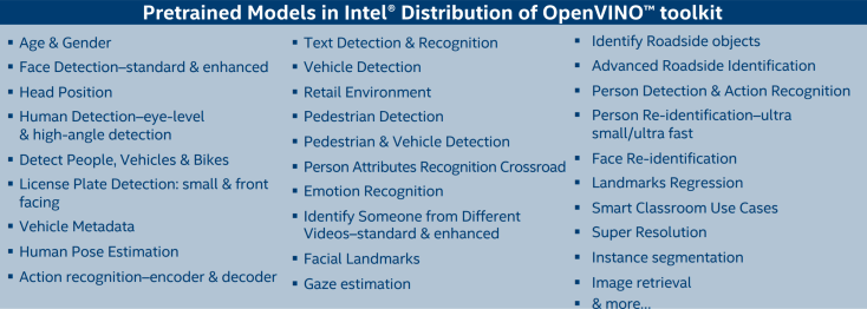
Open Model Zoo提供之各種開源模型列表
5. Open Mode Zoo與影像相關辨識模型
因為機器學習的核心運作在矩陣計算,因此Open Model Zoo持續蒐集的模型種類未來不限制在影像辨識,聲音辨識與分類的模型在未來也將會提供。Open Model Zoo主要是維護和管理OpenVINO™中深度學習的模型,包括Intel預訓練的模型和第三方開源的模型。這些模型都是經過Intel官方驗證過的,可以直接拿來使用。
Open Model Zoo中包含超過40個Intel預訓練模型,使用者可以免費下載使用,並且模型列表會持續不斷的更新,而公共模型中包含超過50個論文發表或與可供轉換至IR版本的模型,包括目標檢測/目標分類/語義分割/人臉識別等,可供使用者學習和整合至自己開發的系統使用。
Open Model Zoo中提供OpenVINO™使用的預先訓練模型,包含了針對Neural stick(MYRIAD)的FP16版本及非MYRIAD的FP32版本,較新的版本提供了FP16-INT8版本11代CPU內建的Iris Xe GPU等支援8位元整數計算的硬體執行與操作,使用者可以由https://github.com/opencv/open_model_zoo下載各種預訓練好的模型,本文中主要用到了四種模型,分別為物件偵測、臉部辨識、情緒分析以及姿態偵測。
1. 物件偵測
物件偵測包含臉部偵測執行的模型face-detection-adas-0001.xml 和人體偵測person-detection-retail-0013.xml,使用object_detection_demo範例程式執行,物件偵測範例程式可以支援多種的模型種類結構,包含ssd、centernet、faceboxes、retinaface以及yolo等,本文使用的模型剛好都是ssd的形式,透過object_detection_demo可以執行非常多種類形式的模型範例。
2. 臉部偵測
要先下載人臉偵測模型 face-detection-adas-0001.xml 和人臉關鍵點模型 facial-landmarks-35-adas-0002.xml 兩個模型,face-detection-adas-0001這個模型是由Caffe轉換過來,使用Mobilenet為base CNN並利用depth-wise縮減維度,在1080P影片可偵測到最小人臉為90×90 pixels,頭部尺寸大於64px的準確率可高達93.1%。
3. 情緒分析
emotion-recognition模型使用AffectNet dataset中的五種情緒進行訓練(http://mohammadmahoor.com/affectnet/),這五種是:neutral、happy、sad、surprise、anger,正確率約70.20%。
4. 姿態辨識(註5)
一般來說人的姿態是包括3D(上下左右前後)位置資訊,但被拍成2D照片或視頻後,自然失去深度(前後位置)資訊,所以僅能就人的肢體重要關節(關鍵)點位置進行分析,進而建立人體骨架及姿態。Open Model Zoo提供的human-pose-estimation模型為使用卡內基梅隆大學(CMU)感知計算實驗室開源的OpenPose18點骨架資料格式。OpenPose18關鍵點格式和常用的微軟COCO17關鍵點格式非常相似,最主要差別是編號序順不同及OpenPose多了脖子點作人體中心點,對於圖像中的每個人都會檢測人體姿勢,由關鍵點和它們之間的連接組成身體骨架。
human-pose-estimation-0001是多人 2D 姿態估計模型(基於 OpenPose 方法),使用經過調整的 MobileNet v1 作為特徵抽取,而human-pose-estimation-0002、human-pose-estimation-0006、human-pose-estimation-0007是使用 EfficientHRNet 方法(Associative Embedding framework)的多人 2D 姿態估計模型。
human-pose-estimation-0001包含 18 個關鍵點,分別為耳朵、眼睛、鼻子、頸部、肩部、肘部、手腕、臀部、膝蓋和腳踝,而human-pose-estimation-0002、human-pose-estimation-0006、human-pose-estimation-0007包含 17 個關鍵點,分別為耳朵、眼睛、鼻子、肩膀、肘部、手腕、臀部、膝蓋和腳踝。
6. 本文提出的教學資源平台構想
以下說明透過線上線下環境,整合出一個可能在大部分電腦教室運作的教學環境。
電腦教室活動紀錄可以立即使用測試的項目:
- 電腦教室的人流紀錄
- 學生盯電腦畫面的時間紀錄與分析
- 於座位出席的時間變化紀錄與分析
- Google ClassRoom繳交課堂單元練習的電腦作業時間。
- 同學進入教室後有無全程戴口罩的觀察與分析。
- 電腦課中的人流紀錄。
- 小組討論中組員的情緒變化與專注度紀錄與分析。
這些資料對於未來的學生輔導,不同課程在設計分組的班級經營上,相信會達到一定的效果。相對的也可以彌補大量只有線上課程活動,不知道線下互動狀態實體世界缺憾。
7. 運作情境與範例
本文以東擎NUC BOX-1185G7E工業用電腦進行開發,其硬體環境為Intel i7第11代CPU,軟體環境使用Ubuntu 20.04.2 LTS為作業系統,執行OpenVINO™ 2021.3.394作為影像推論引擎,透過Open Model Zoo的範例程式與模型分別執行影像的視覺預測,執行過程中可分別得到各自詳細影片辨識結果的數值型資料,如Human Pose預測模型,可以同時得到影像中多個人體推論骨架的特徵點,最後將這些預測的結果再標註回原始的圖像,得到影像推論的輸出,進一步可以同時將這些骨架資料儲存並進一步的分析。

本文執行Open Model Zoo使用之東擎工業用電腦, 內含Intel第11代CPU,以及WiFi-6無線網路晶片
執行過程以Open Model Zoo範例中之object_detection_demo、gaze_estimation_demo、human_pose_estimation_demo、interactive_face_detection_demo四個程式為主體,object_detection_demo透過face-detection-retail-0005辨識模型為基礎,用以辨識課堂學生的臉部位置。
gaze_estimation_demo需要透過5個模型的辨識流程,以此取得學生臉部的角度與眼球的方向,分別為face-detection-adas-0001、head-pose-estimation-adas-0001、facial-landmarks-35-adas-0002、open-closed-eye、gaze-estimation-adas-0002等辨識模型,透過這5個模型分別可以標定臉部的位置、頭部的角度、人臉的35個特徵點、開閉眼的狀態,最後依此推論眼球角度的方向。
interactive_face_detection_demo需要透過5個模型的辨識流程,以此取得學生臉部情緒特徵的狀態,分別為face-detection-adas-0001、head-pose-estimation-adas-0001、facial-landmarks-35-adas-0002、age-gender-recognition-retail-0013、emotions-recognition-retail-0003,透過這5個模型分別可以標定臉部的位置、頭部的角度、人臉的35個特徵點、性別與年齡,最後依此推論臉部情緒的分類。
human-pose-estimation-0001僅需一個模型便可同時推論照片中多個人體的骨架特徵點位置,其中人體骨架推論模型目前在Open Model Zoo可供使用的類型共有4種,human-pose-estimation-0001對於骨架推論可以維持在速度較快且較為正確的情況,human-pose-estimation-0005、human-pose-estimation-0006、human-pose-estimation-0007主要針對不同大小的輸入尺寸進行訓練,在不同尺寸的輸入圖形大小時,可以測試使用不同的骨架推論模型,分別觀察那一個模型較為適合應用的情境。
以下透過電腦教室課堂進行時手機紀錄的照片作為範例,主要以拍攝角度與文中使用到的辨識模型種類作為說明。

電腦教室課堂進行中手機紀錄的照片
1. 單獨模型驗證結果
- gaze_estimation_demo推論結果
以下分別說明各範例的執行效果,首先以由教室位置前排拍照作為說明,透過gaze_estimation_demo偵測前排正面視角的推論。透過以下的指令執行 /root/omz_demos_build/intel64/Release/gaze_estimation_demo。
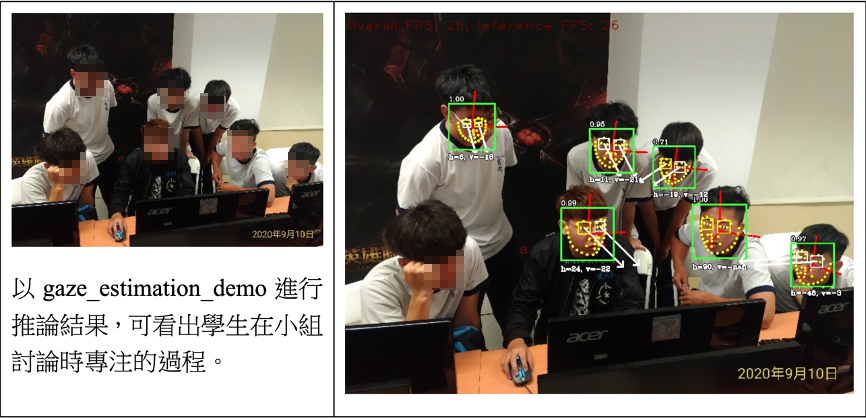
將A5.jpg進行辨識,執行結果如下:

以gaze_estimation_demo進行推論結果,左原始圖像,右推論結果
可以看出同學是否正在練習,或者暫時在休息的狀態,如果透過攝影機,可以進行每秒鐘連續的觀察,未來可以透過這樣的連續觀察資料,了解不同題型的題目,學生需要花費多久的時間練習,同時,也可以分析不同題型或是課堂進行多久時間後,需要安排其他的學習活動或進行階段性的休息。
以gaze_estimation_demo進行推論結果,左原始圖像,右推論結果
- object_detection_demo推論結果
透過object_detection_demo偵測班上目前學生的人臉數量,透過這個過程可方便了解課堂學生在座人數的觀察。

在影像資料來源較為單一的時候,可以透過臉部區域偵測的模型來進行同學是否在位子上面的觀察。

以object_detection_demo透過face-detection-adas-0001進行推論,左原始圖像,右推論結果
同時object_detection_demo透過 –r的參數格式,可以將推論的結果輸出,由此可以將輸出內容導出至後端的紀錄檔案或資料,得到即時的觀察結果。
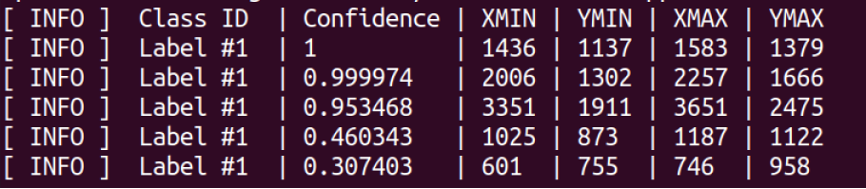
進一步的在後排的同學臉部影像模糊或攝影機角度受限,以及人臉被物件遮蔽的情況下,使用person-detection-retail-0013模型進行相同輸入影像的偵測。

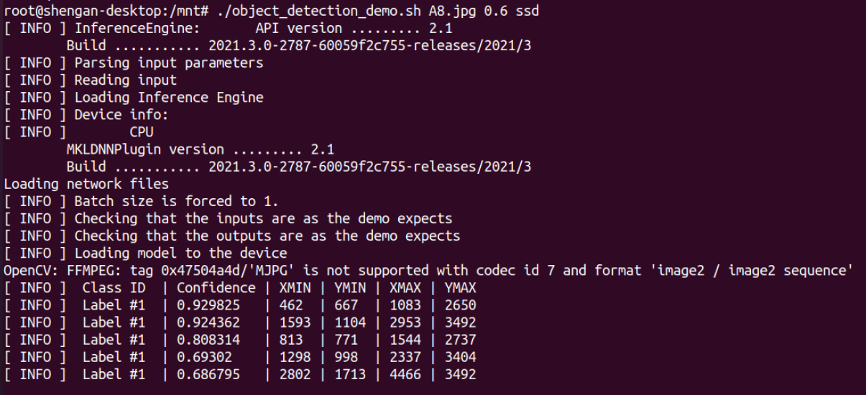
以person-detection-retail-0013模型執行A8.jpg預測的結果

以object_detection_demo透過person-detection-retail-0013進行推論,左原始圖像,右推論結果
底下我們用電腦教室的斜對角拍照,觀察face-detection-adas-0001與person-detection-retail-0013分別的執行結果,其中會發現person-detection-retail-0013在辨識同學的狀態上表現還不錯。

以object_detection_demo進行推論結果,左原始圖像,右推論結果
- human_pose_estimation_demo推論結果
進一步透過human_pose_estimation_demo,藉以偵測同學於電腦教室座位上的姿勢,如手部是否正在操作滑鼠或鍵盤、同學間討論與互動的狀態,透過姿態可以得到部分的資訊,同時,如果學生累了趴在桌上休息,也可以得到相關的訊息,由此可以得到許多過去在電腦教室教學進行過程中,很難取得與累積的教學互動過程。
底下是human-pose-estimation-0001推論的結果:

以human_pose_estimation_demo推論姿勢,左原始圖,右推論結果

以human_pose_estimation_demo推論姿勢
學生練習時的照片遠拍在human_pose_estimation_demo的程式執行狀態下,相對因為教室配置的狀態,很難呈現學生練習的狀態,同時發現human-pose-estimation-0001、human-pose-estimation-0005、human-pose-estimation-0006、human-pose-estimation-0007等不同的human-pose-estimation模型,會得到同一個輸入影像,但是相對不太一樣的結果,因此可以再進一步的觀察跟比較那一個模型推論的結果較適合蒐集資料的視角。

以human_pose_estimation_demo以另外一種視角推論
可以發現透過不同的human-pose-estimation模型,在這裡可以觀察到human-pose-estimation-0001與human-pose-estimation-0005的結果較適合做後續的應用。


以human_pose_estimation_demo朝正面單邊拍照影像辨識的結果
最後可以發現嘗試直接由前面正拍得照片,在這裡可以觀察到human-pose-estimation-0006的結果較適合做後續的應用,同時也會發現human-pose-estimation對於影子的辨識結果,在human-pose-estimation-0006、human-pose-estimation-0007的時候會發生這種現象。
- interactive_face_detection_demo推論結果
最後透過interactive_face_detection_demo,藉以偵測同學於電腦教室座位座位上的臉部情緒,臉部情緒目前僅能做為某一種參考,原始辨識的訓練資料可能不完全對應學習者的學習與情緒狀態,因此很可能對應辨識的結果並不能反映目前學員的學習情緒。

interactive_face_detection_demo推論臉部情緒,左原圖,右結果
本文主要初步嘗試何種影像資料能夠進行相關模型的推論應用,目前觀察在斜角角度上的資料有機會進行使用,唯需要某個角度校正的演算法,將有歪斜的角度照片,進行臉部角度校正,以利後續的模型推論。同時,關於情緒辨識與學習過程與成效的關聯,尚待未來進一步更深入的分析與研究。
2. 整合型模型應用結果
以下分別透過四張照片的推論情境作為範例,分別以左前視角、側面往前正拍、右前視角等三種類型的照片作為範例,以及一般教室正面照作為一般教室的範例,以object_detection_demo、gaze_estimation_demo、human_pose_estimation_demo、interactive_face_detection_demo四個程式分別執行之結果。可以分別的看出各模型對於電腦教室在不同的角度與視角下,可以提供分別不同狀態的資訊。如以臉部為主的訓練模型以及姿態為主的訓練模型,確實在同樣的照片輸入下,可以對學習者的學習狀態資訊提供許多互補的效果。

左前視角透過四種預測程式執行的結果

側面正拍透過四種預測程式執行的結果

右前視角透過四種預測程式執行的結果
最後於一般的教室的情況下,由正面拍攝影像,透過gaze_estimation_demo、human_pose_estimation_demo、object_detection_demo、interactive_face_detection_demo等執行結果如下,可作為日後攝影機放置位置與角度的參考。


一般教室由講桌處往前拍之四種預測程式執行結果
透過上述各種資料與Open Model Zoo的模型執行結果,相信大家對於教室情境下,如何使用影像視覺辨識技術在教室場域應用的潛在可能性,有了一些基本的概念。目前業界專業的影像擷取設備公司,已經有與本文相關的電腦視覺辨識開發套件可以選用,例如聰泰影像擷取設備公司的深度影像視覺開發套件,已經內含相當多更專業的影像辨識模型,由下圖中可以看到,影像模型包含著教育、頭部與身體辨識、臉部特徵(含5個與68個特徵點抽取模型)、人體骨架特徵抽取(17個點)、演講者追蹤等非常適合在智慧教室現場使用的影像辨識模型可供使用。
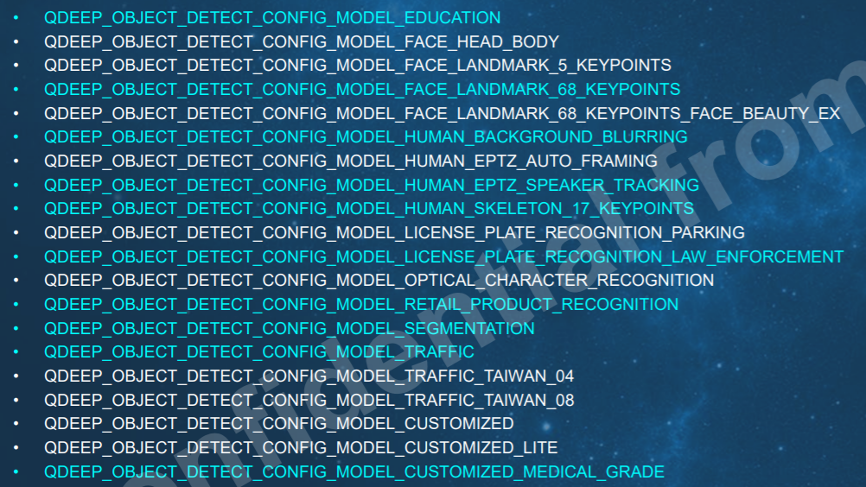
聰泰科技提供的深度影像辨識開發模型
同時在教育現場的情境管理與分析上,聰泰工業級電腦包含自行研發的多路影像擷取設備的解決方案,能完整的支援OpenVINO的架構,此種狀態對於智慧教室的邊緣運算前端整合平台與後端管理平台,已經能提供完整的影像擷取、儲存、即時影像分析、串流傳輸、即時回放等一條龍的智慧教室服務。
在這樣的狀態下,聰泰提供的API,讓使用者很容易的將各種即時辨識的資料結果,進一步整合至使用者既有的軟體平台與後端資料庫,方便日後大數據與各種異質型資料的整合與應用。

聰泰科技提供的智慧教室情境分析平台
上圖中為聰泰的智慧教室情境分析平台,可以看到透過影像的情緒分析模型,學習者間的學習狀態可以即時的掌握,並且能夠很快的辨識出目前進行的單元教學內容,同學間是否相對無法集中精神。授課教師因此可以透過學生行為反饋的資訊,即時的進行課堂步調的調整。

聰泰科技智慧教室一條龍影像情境即時分析平台
最後可以從上圖了解聰泰的教室教學平台提供的服務,因為聰泰本身就是影像擷取設備的製造公司,對於各種影像來源設備已有多年的整合經驗,因此在多年的平台累積過程中,聰泰科技智慧教室提供的一條龍服務,同時包含教材錄製、即時串流派送、影片即時回放、深度視覺影像分析結果、即時視覺化呈現等專業的軟硬體設備整合,這樣的條件對於一般智慧教室需要許多不同廠商之間的影像設備整合與測試的狀態下,相對明顯的聰泰在效能調校與後端資料整合應用的成熟度,對於使用者未來在設備的採購上,能提供一個更清楚有效的策略。
總結
如何透過人工智慧達到更好的電腦班級經營,讓課程的進行可以更順利、師生互動可以更和諧,是教學現場最大的挑戰,經由電腦視覺化技術的日漸普及,過去需要高成本的設備,如今有機會透過一般民間日常的電腦設備達成。這樣的過程顯示,已經有機會達成初步自動化資料蒐集的智慧班級經營教室,期盼在更專業成熟的設備環境出現之後,更能有效地提升教師的班級經營及學生的學習成果。
班級經營的紀錄自動化,將能夠大幅度的降低教師在課堂進行時大量教室管理及掌握學生學習狀態的時間,本文嘗試透過目前可以使用的開放式原始碼與開放式推論模型計畫的專案,導入電腦化班級經營的可能性,如果台灣的教育界能夠透過Intel OpenVINO的開源成果,推廣一個可供教師在教室內使用,較為輕量級的邊緣運算架構的班級經營輔助套件,相信將能大幅度提升教學品質與課後學習的回饋與成效分析。
參考資料
參考資料
註1 今周刊. (2020, December 15)。兩年5億元力推數位教學,新北打造智慧學習環境。
註2 電腦視覺(2020, September 19). Retrieved from 維琪百科,自由的百科全書;
註3 Intel OpenVINO(2021)。Intel®DistributionofOpenVINO™toolkitOverview,Training Slides-Part1
註4 Open Model Zoo (2021)。Overview of OpenVINO™ Toolkit Pre-Trained Models
註5 Z.Cao, G.Hidalgo, T.Simon, S.-E. Weiand Y. Sheikh, “OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields, “in IEEE Transactionson Pattern Analysisand Machine Intelligence, vol.43, no.1, pp.172-186, 1 Jan. 2021, doi:10.1109/TPAMI.2019.2929257.
Google作業(2021)。使用學習管理系統 (LMS) 專用的 Google 作業工具,輕鬆分發、分析及批改學生作業。
陳學淵,郭蕙琳,丁一賢(2001)。電腦教室之班級經營。輔導與諮商教學與資源中心網站支援計畫,2001年暑假研究所教育學分暑修班
附錄
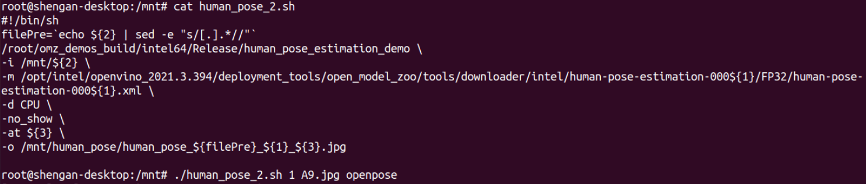
Open Model Zoo下載 human-pose-estimation模型指令
oot@shengan-desktop: /opt/intel/openvino_2021.3.394/deployment_tools/open_model_zoo/tools/downloader ./downloader.py –print_all | grep human human-pose-estimation-0001 human-pose-estimation-0005 human-pose-estimation-0006 human-pose-estimation-0007 human-pose-estimation-3d-0001 在OpenVINO的安裝路徑下,open model zoo的tools子目錄下,使用downloader.py下載human-pose-estimation-???? (這四個問號要打, 可以一次下載多個相關的模型) /opt/intel/openvino_2021.3.394/deployment_tools/open_model_zoo/tools/downloader透過 ./downloader.py –name human-pose-estimation-????
(責任編輯:謝涵如)

專長:醫療資訊系統、生物資訊、雲端運算、大數據、人工智慧、分散式系統、行動裝置程式設計、軟體工程、行動資訊系統、數位圖像處理
- 以3D感知開啟智慧機器人新時代:從深度相機到OpenVINO的邊緣智慧革命 - 2025/12/12
- OpenVINO 2024.2姿態模型效能評估:以OpenPose、YOLOv8與3D-Pose為例 - 2024/08/05
- 優化OpenVINO模型效能:參數設定影響實測 - 2021/08/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!