作者/圖片提供:黃金屋 the project G

你有沒有過類似經驗?
走進一家書店,在地經營逾半個世紀,滿滿的書,寸步難行,但花了幾個小時卻找不到想要的書?
你和老闆娘都不確定這裡有沒有你要的那本書, 也許它被埋在底下了。
帶著小失望的心情走出店外,與年邁老闆娘閒聊:
考慮把這些書上傳雲端嗎?
老闆娘表示,不符成本,請一位打字小姐,基本薪資,可能一年也得額外增加幾十萬成本。
於是乎,就產生了本次專案的構想:AI邊緣裝置。
最初理想之雙贏成果:
如果能開發出一台AI邊緣裝置,輕巧、能走進這些書櫃開始進行辨識工作,自動辨識書封面文字,上傳雲端,顧客上門,只許上雲端查詢是否有想要的書,找書、結帳。老闆也能節省成本、提供顧客更好的找書體驗、提昇銷量。
從零開始的開發過程
本次專案孕育而生,在完全沒有AI開發基礎的情況下要如何開發出當初的理想成果呢?
以下是我的開發過程,我將以完全新手的角度去記錄整個開發過程:
硬體:
- 2013 老Macbook Air i5 雙核心 1.3 GHz
- 樹莓派+ Intel NCS2

樹莓派失敗過程:
2個多月來的開發過程, 我花最久的時間就是在樹莓派的編譯,反覆爬了很多文章,從完全沒經驗的新手,一步步觀察錯誤碼、爬文、花了很多時間在Cmake 與make 上,最終發現樹莓派裡的text-detection-demo 似乎沒有被放進去樹莓派版的OpenVINO裏面,所需的text-detection 和text-recognition models 都已下載好了,就只差 text_detection_demo。
嘗試從Github 下載 Open_Model_Zoo 至樹莓派,但也最後也無法成功找到該demo。
最後甚至把老Mac 裡的 text-detection-demo 的 Cmakefile 、和樹莓派裡的 /opt/intel/openvino_2021/deplyment_tools/inference_engine/samples/cpp/Cmakelist 、以及樹莓派裡的 /opt/intel/openvino_2021/deplyment_tools/inference_engine/samples/cpp/object_detection_sample_ssd/Cmakelist 拉出來比對形成三國鼎立的局面,心想如果嘗試改變text-detection-demo Cmakefile 讓它符合樹莓派用語,也許就能在樹莓派裡使用,天真的想法最終領悟了這之中是很複雜的Cmake過程,以目前我的理解是無法完成:
唯一慶幸的是,也就是因為這樣反覆error、爬文 、搞壞了樹莓派、重新安裝、 漫長的Cmake 和make -j4 -l 4 && sudo make install 過程, 我學會了打Linux 指令更快一些了吧。
總之,樹莓派開發最終失敗,不過很期待未來能學習更多,讓我能完成這部分的開發。
DL Workbench 開發失敗成果:
本來想說既然我缺一個text-detection-demo ,只差臨門一腳就可以實現在樹莓派上,進行書本封面辨識,不如自己訓練一個模型丟進去樹莓派, 然而礙於硬體效能太差,光是進入DL Workbench 頁面就費盡千辛萬苦了,下載了Docker 也差點讓儲存容量爆炸。
再匯入模型的過程中,從25%-50% 似乎要花上數月時間….
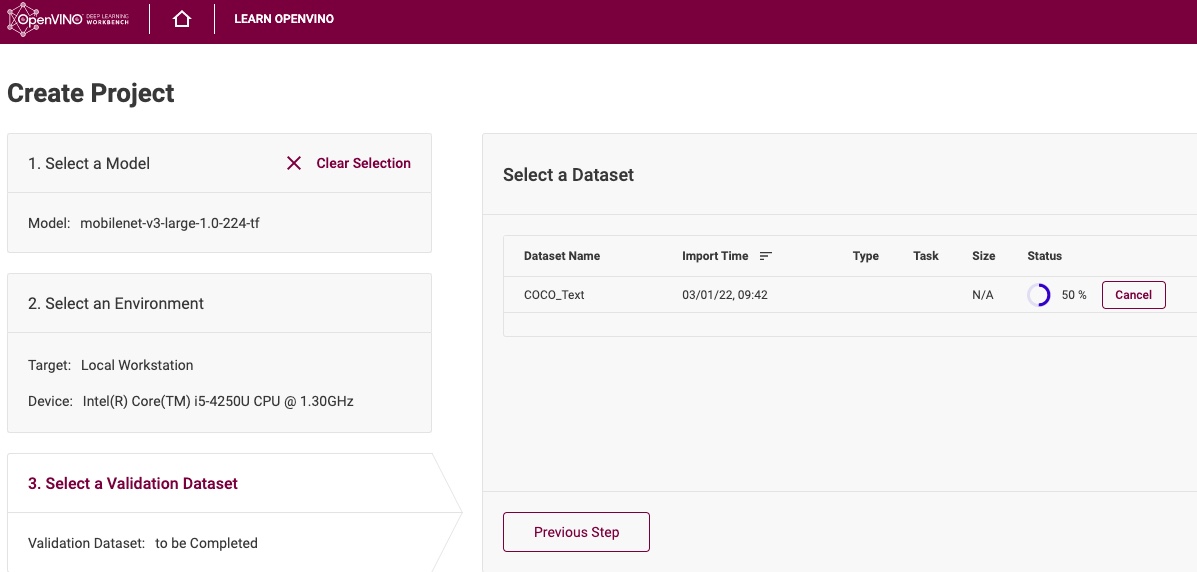
最後進入到調整超參數的部分,才發現沒想像中簡單,以目能力不足,故暫時作罷。
老Mac開發失敗成果:
整個專案不知不覺就經歷了2個多月,雖然樹莓派開發失敗,難掩失落心請,但還是決心奮戰到底,其實我的老Mac 一直都有安裝完 OpenVINO Toolkit , 但由於某種固執的性個吧,總是想看到樹莓派先完成的一天, 現在心終於軟化了,改使用2013年、128G、4G記憶體、i5雙核心、1.3GHz的老Mac 進行開發。
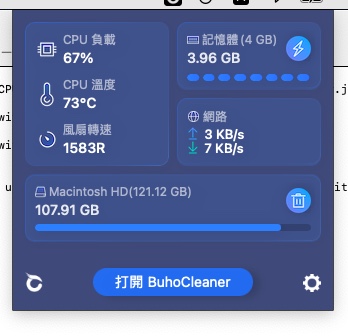
如下圖可以看見,老Mac 溫度飆升至70度,這是家常便飯。
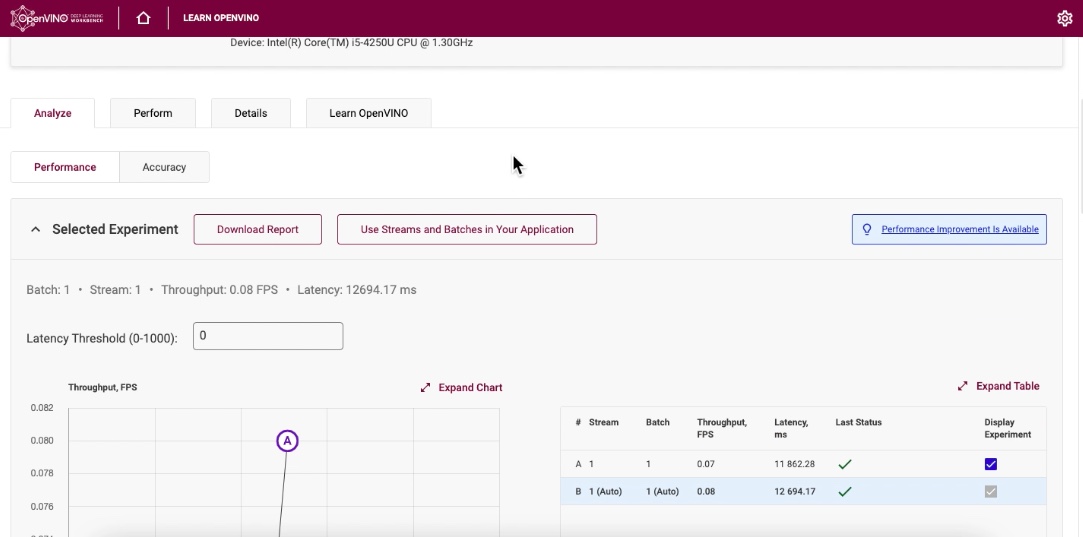
這次選用text-detection-0004 + text-recognition-0012,不過還是開發出來了,但仔細觀察,其實什麼文字也沒有辨識出來,全是亂碼。
這之中出了什麼問題?
猜測可能的原因很多: 硬體太差、燈光太昏暗、距離太遠、 也許我使用的模型不對?!
開始著手調整。
老Mac的最終成果:
作品反思
看到最終完成作品,我觀察到幾個想要的成果了:
- 文字辨識成功:其實不用完美辨識所有文字,未來能再加上自動上傳雲端資料庫就可以方便顧客查找,同時也節省了人力的輸入, 能搜尋到書本封面上的關鍵字,即可知道這家書店值不值得我們進去找書挖寶了。
- 光源、噪點影響比重大:這跟我原本天真的認知有落差,算是被現實打醒, 不同書的材質會再經過光源照射後會有不同的曝光效果,這會影像辨識結果, 看來要帶著AI邊緣裝置走進昏暗的書堆中,也許要先思考如何解決光源不足的問題,是否要重新裝潢? 或是裝置加裝燈源? 或是乖乖地 一本本書全部搬出來,在一個設置好的作業進行辨識,然後在一本本搬回去上架,但這樣還是得花費人力了。
- 5G:如果真的要帶著邊緣運算裝置,走進書堆中辨識,希望在不大量搬動書的情況下完成作業(這是我最初最初的想法) 那麼也需要有極快的網路速度。
- 硬體:誠如上不影片,用2013老Macbook 去做推論的成效非常差, 這也不禁讓我開始思考一個問題…….
什麼樣的硬體可以達到更好更快的推論成效??
於是乎我使用了 Intel DevCloud 裡的 Sample Application ,而在範例裡也剛好有 OCR 文字辨識邊的硬體裝置測試。
這次我測試了五種硬體進行文字辨識、其中一台因某中未知原因導致沒有數據,請忽略它。
下圖,數字越高代表每秒處理應片張數速度越多,效能越好。
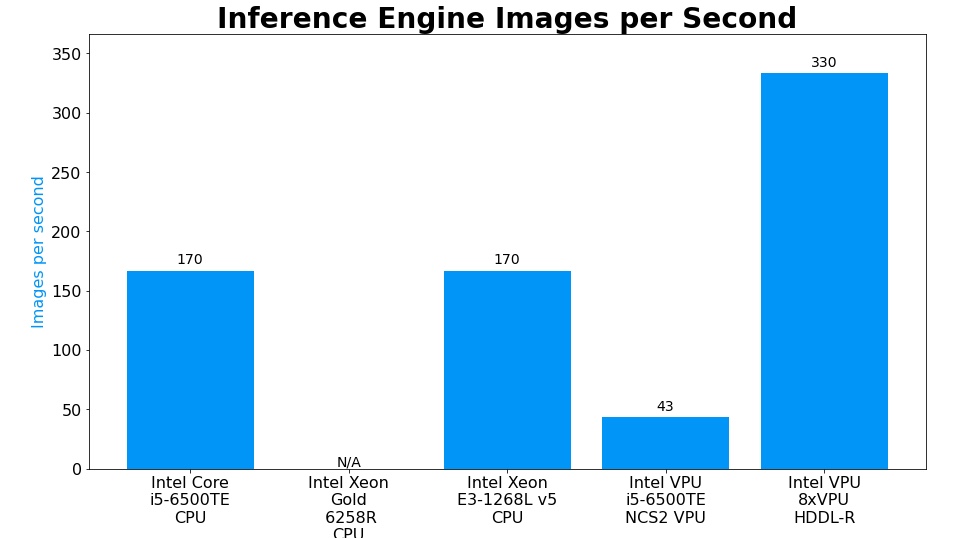
下圖,撇除無數據的那台,數字越低代表推論速度越快。
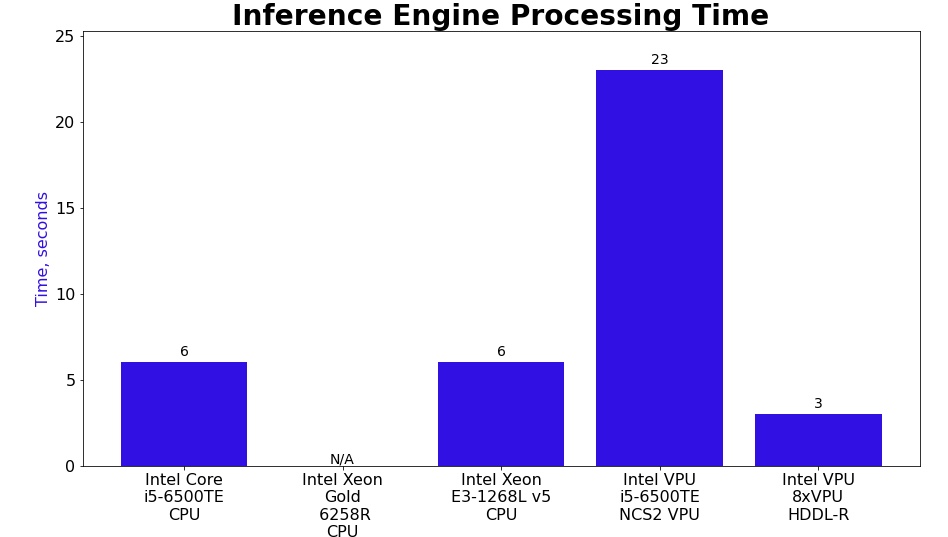
其中有一台,特別吸引我注意:Intel VPU 8xVPU HDDL-R
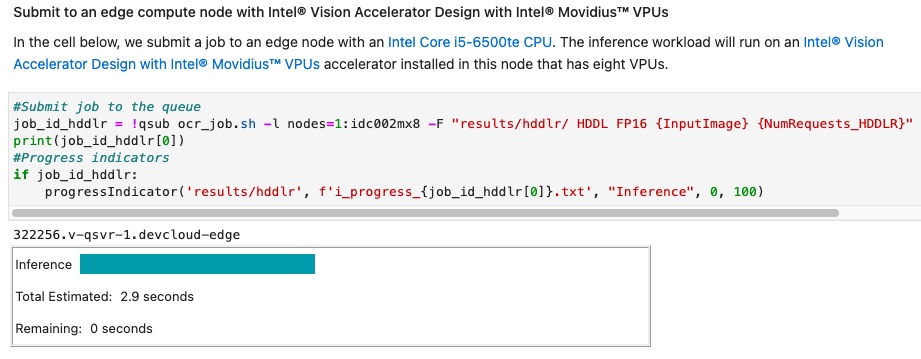
它能在短時間即完成整個推論結果。
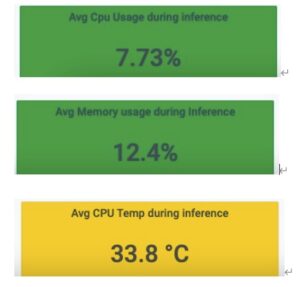
接著我把Intel VPU 8xVPU HDDL-R 分析報表叫出來看, 結果也是很滿意:
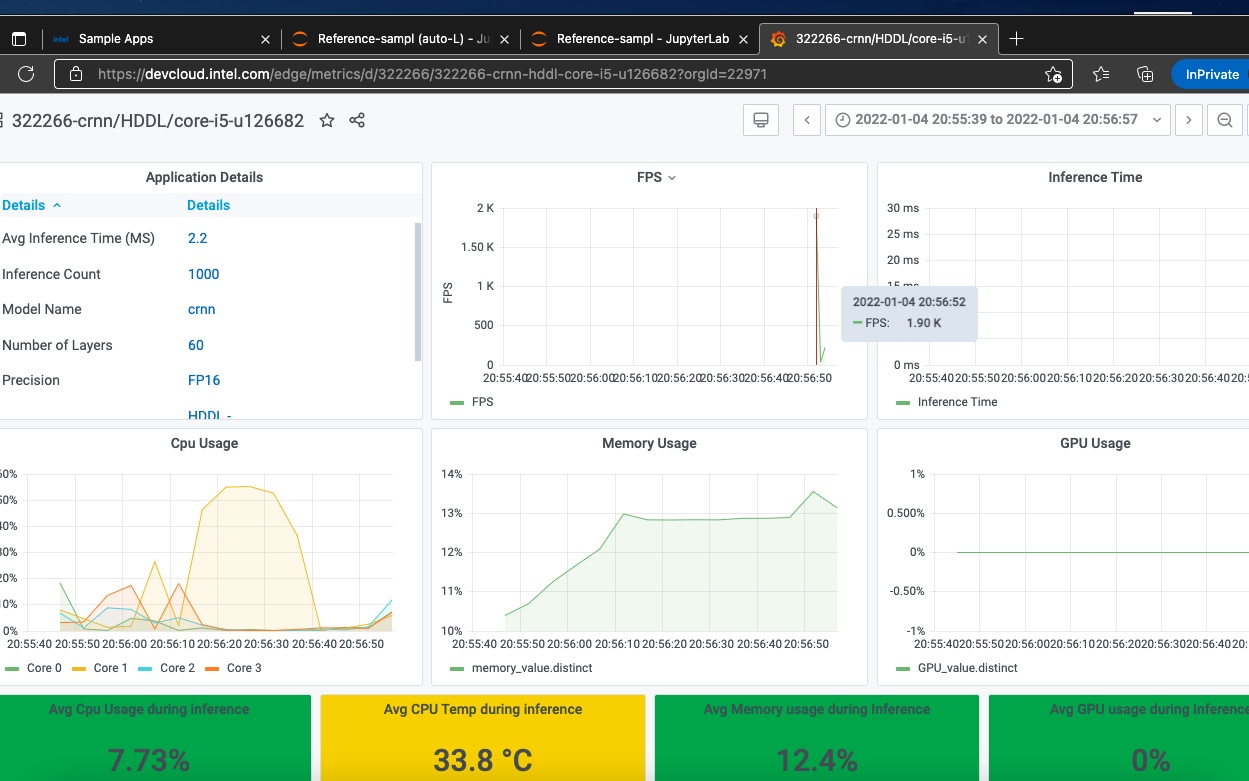
相比我的老Macbook,Intel VPU 8xVPU HDDL-R 表現特別亮眼。
可以看到它在CPU使用率、記憶體使用率、CPU溫度表現上都遠遠完勝老Mac。
結論
引用東海大學教授 吳兆田博士 2021年11 月 29 日在臉書上對於數位轉型的評論:「數位轉型」是一個大招牌,只要跟它沾上邊,就會有話題。如果只是裝設感應設備,寫個程式優化生產流程,只是「生產自動化」,30幾年前就有了。將所有流程中紙本管理文件數位化,稱為「數位化」,20年前就很成熟了。我相信您有興趣的應該是「管理思維及模式的數位優化」,以及結合不同科技與平台帶來商業模式的突破創新,才稱為「數位轉型」。
從新手開發者和尋書顧客角度,整個的開發過程很有趣, 邊做邊學, 最後成果也重新讓我反思當初構想的「理想結果」實際上是有很多困難需要克服的:燈源、硬體、5G、成本,而站在經營者的角度, 若想導入AI許是整個書店需要新裝潢提升照明、建構5G基礎設施、或是請人搬運書籍…. 等問題與挑戰。
最後,這樣的AI邊緣裝置是否可行呢? 走到這一步,我會回答「可行!」
期待未來能和更多厲害的工程師交流、學習、最終整合這一切,完成當初想像的雙贏局面!
延伸閱讀
由於url 連結太多,故貼出截圖表示,這些是我反覆爬文做出此專案的文章:

(本文作品為《2021 Intel DevCup x OpenVINO Toolkit競賽》概念組參賽提案,文章經作者同意轉載;原文連結;責任編輯:唐育琪)

- 【Maker Project】從零開始的二手書文字辨識 - 2022/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


