作者:許哲豪(Jack)

隨著人工智慧興起,利用「深度學習」技術來進行電腦視覺工作已是很普遍的應用,如影像分類、物件偵測等。通常只需將單張影像送入訓練好的模型中進行推論即可得到輸出結果,但當遇到視訊檔案或串流影片時,逐格(by Frame)影像分析就變得很沒效率,因為影格間時間差距過短(通常為1/30 ~ 1/60秒),場景中的物件位移量(變形量)可能過小,導致影格間得到幾乎相同的計算結果(物件位置、尺寸及分類),浪費計算資源,也讓系統看起來反應過慢。
為了使視訊檔案及串流影片在分析上能加快反應,Intel OpenVINO Toolkit(以下簡稱OpenVINO)整合了GStreamer、OpenCV並提供DL Streamer – GStreamer Video Analytics (GVA) Plugin,讓使用者可以更彈性的設定,使其在影片(連續影像)分析上更具效率。
接下來就幫大家介紹「什麼是串流影片?什麼是GStreamer?」、「如何安裝OpenVINO DL Streamer環境」、「串流影片分析及優化流程」,最後再以一個即時追蹤車輛、行人的範例來介紹如何使用命令列操作,希望能幫大家對DL Streamer有更多認識。
什麼是串流影片?什麼是GStreamer?
相信大家都用過數位相機或攝影機,隨便拍一張照片都是幾百萬甚至上千萬畫素,若在不壓縮情況下,一張超高畫質(Full HD)影像解析為1920 x 1080像素(俗稱200萬或2M),每個彩色像素紅綠藍各使用1 Byte (8 bit)來表示,則要儲存這張影像就要6.22 MByte。
若以這個解析度拍攝每秒30影格(frame)的影片時,則1秒鐘就要186.6 Mbyte,1分鐘11.2 GByte,一台1 TByte (1,000 GByte)的硬碟也不過只能存不到90分鐘影片,所以就有了利用人眼對紋理頻率(平滑、雜亂紋理)、色彩濃度感知能力不同,發明了各種破壞性壓縮方式來縮小影像及影片的檔案大小,如jpg、mp4等格式,讓影像、影片大小縮小數十到百倍,而人眼也很難分辨其差異。
雖然影像壓縮已解決儲存大小的問題,但若想從網路上看一部影片卻要等所有影片都下載完才能觀看,這也太不方便了。於是就有人提出可以把取得影像、壓縮、傳送、解壓縮、顯示變成一個像水管(pipeline)依序分段工作的作法,影片(連續影像)內容就像水一樣在水管中流動,使用者收到一小段資料就可以開始播放,不必等到影片全部下載完才能觀看。
而且影片內容只需暫存在緩衝區,不一定要存在硬碟中,可節省儲存空間,因此透過此種方式傳送的影片就稱為串流影片(Stream Video)。目前像大家常看的Youtube、各種直播或者是網路監控攝影機(IP Camera)都是採用這樣的作法,當然我們也可以把存在硬碟中的檔案當作串流影片讀取,這樣亦可大幅增進播放效率。
目前市面上有很多串流影片的處理軟體及開發工具,其中GStreamer [1]就是最廣為人知的開源工具。它主要工作在Liunx上,有很多硬體(CPU, GPU, DSP, CODEC, ASIC等)廠商都對其有優化,使得影音內容在壓縮(編碼Encode) / 解壓縮(解碼Decode)效率大幅提升。
如Fig. 1所示,GStreamer採取功能方塊作法,每個方塊依不同工作項目會有不同輸入(sink)和輸出信號源(src),再依需求將前後串聯起來。以一個影音播放器(player)為例,首先開啟影音檔案,再將其分解(demuxer)成聲音(src_01)和影片(src_02)兩組信號源,再依聲音和影片格式給予對應的解碼器(decoder),最後再由對應的喇叭和顯示器將聲音和影片播出來,完成串流影音檔案播放工作。當然這裡是採取一邊讀取檔案一邊播放的串流型式存在。

Fig. 1 GStreamer串流影音播放工作流程。[2]
如何安裝OpenVINO DL Streamer環境
OpenVINO為了方便大家使用DL Streamer,同樣地在Docker Hub上有提供現成的映像檔(Image)給大家下載,不熟悉如何使用Docker安裝的人,可以參考「如何利用Docker快速建置OpenVINO開發環境」[3]。不過上次文中使用的ubuntu18_dev這個映像檔並不支援DL Streamer, GStreamer, Speech Libraries及Intel Media SDK,所以要重新到Docker Hub拉下(下載)ubuntu18_data_dev這個映像檔,執行下方指令即可獲得映像檔(約8.28 GByte)。不過這些檔案有點大,視網路速度需等待下載時間從數分鐘到數十分鐘不等。
docker pull openvino/ubuntu18_data_dev
#檢查是否下載成功
docker images

Fig. 2 Intel OpenVINO DL Streamer映像檔下載成功畫面。
另外補充一下,若非使用Docker安裝,則要注意軟體工作環境需滿足下列條件。
- OpenVINO 2021.1(Inference Engine 2.1.0)或以上版本
- Linux Kernel 4.15或以上版本
- GStreamer 1.16或以上版本
更多DL Streamer完整說明可參考Intel官方Github openvinotoolkit/dlstreamer_gst。[4]
串流影片分析及優化流程
OpenVINO目前整合了GStreamer的串流影片工具(VAAPI, labav等)、原有的推論引擎(Inference Engine, IE)、OpenCV等函式庫,搭建出DL Streamer串流影片分析插件(GStreamer Video Analytics Pulgin, GVA),方便讓開發者創建的應用程式能輕鬆地發揮硬體加速計算元件的效能,如Fig. 3所示。
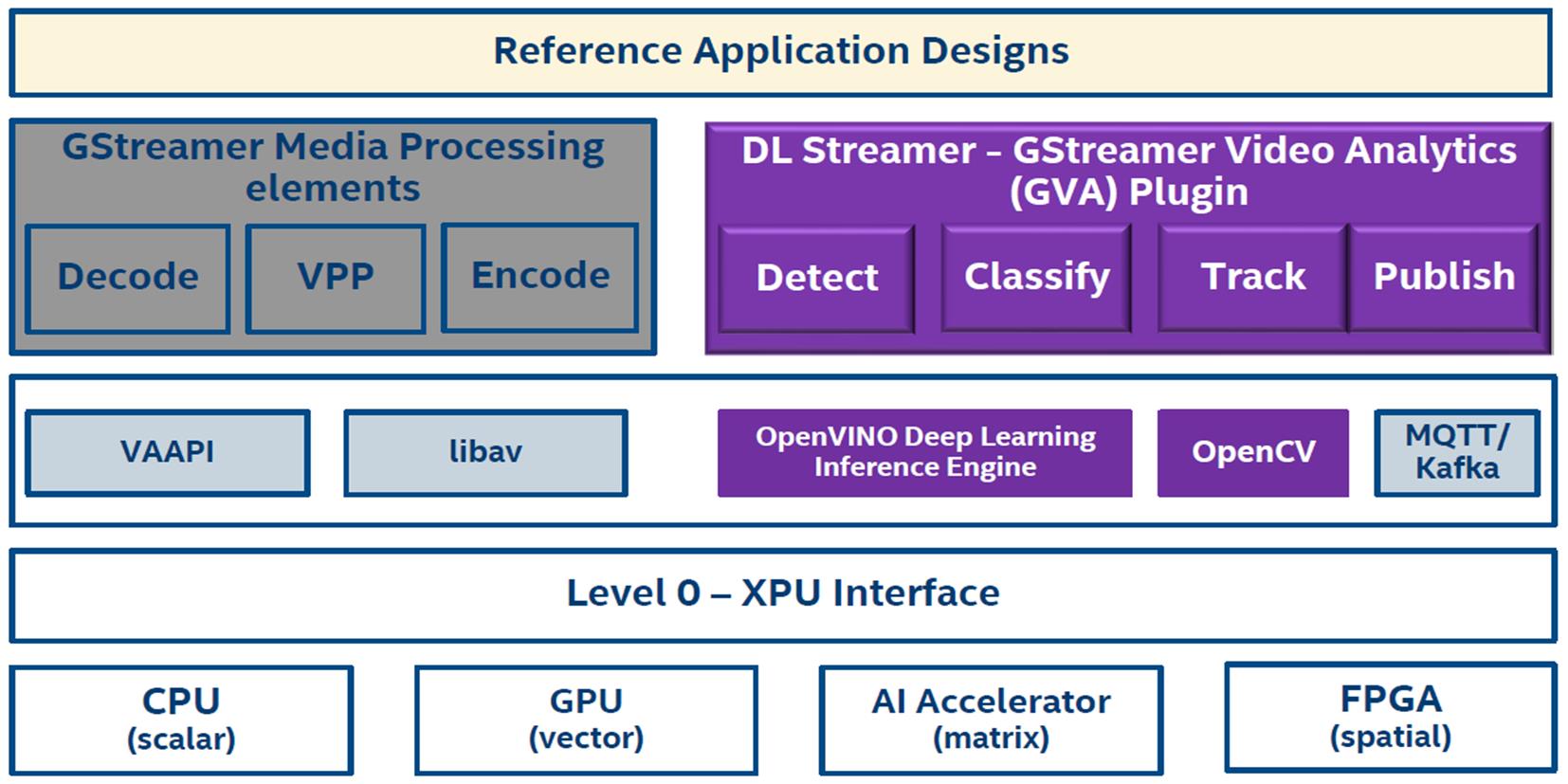
Fig. 3 OpenVINO DL Streamer Software Stack。(圖片來源:Intel IOTG)
接下來就以一個常見的應用來舉例什麼是串流影片分析(Stream Video Analytics)。假設一個商店在門口處裝了一組網路監控攝影機(IP Camera),想要利用拍到的影像來得知進門的顧客是否為重要客人(VIP)或者是黑名單(Blocklist)客戶,此時就要對拍到的連續影像進行人臉辨識,這就是串流影片分析。
一個完整的串流影片分析工作包括接收已壓縮的影片、解碼(解壓縮)、前處理(如影像格式轉換、亮度/色彩/對比調整等)、分析/推論(影像分類、物件偵測等)、後處理(將結果以文字、繪圖等方式疊回原影像上),最後視輸出方式可選擇直接輸出到螢幕顯示或著再重新編碼(壓縮)成檔案儲存回硬碟中,如Fig. 4中間列所示。
其中在推論部份可以是多種工作串接而成的,亦可同時處理二種以上工作,在OpenVINO GVA Plugin中提供了多種函式(元素Element)可供使用、包括偵測(gvadetect)、分類(gvaclassify)、追蹤(gvatrack)、水印(gvawatermark)、發佈(gvapublish)等,而更多完整的介紹及用法可參考官網Github說明[5][6]。如Fig.4上方列即表示使用了偵測、辨識、追蹤及水印等元素來完成推論及顯示工作。
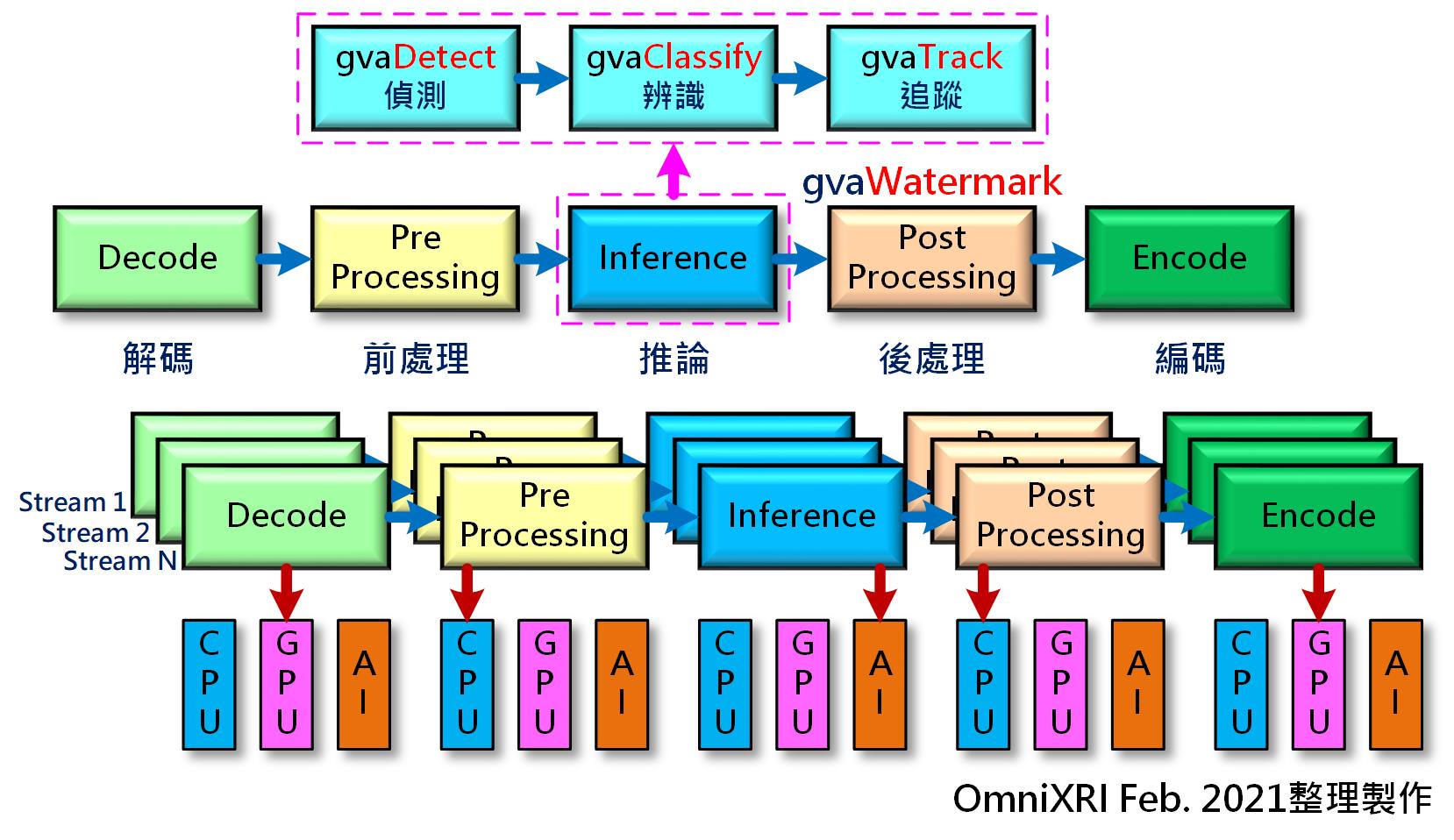
Fig. 4 DL Streamer串流影片分析工作流程圖。(OmniXRI Feb. 2021整理製作)
在這一連串工作中,並不是所有工作都交給CPU來作,而是將其分配給最適合、效率最高的硬體來執行才是最理想的。比方說檔案的存取(硬碟和記憶體間資料搬移)、格式轉換、繪圖等非矩陣運算工作交給CPU,解碼/編碼等大量數學運算交給GPU,而神經網路推論所需的巨量矩陣運算工作則由AI晶片(也可以是GPU, VPU, FPGA, NPU, ASIC等)完成,如此就能得到最佳的工作效率。一般串流影片播放速度大約是1/30秒一個影格(Frame),所以當傳輸及計算速度夠快時,就能同時計算多個串流影片,如Fig. 4下方列所示。
接著說明如何提升推論效率,如同本文一開始提到的,若對串流影片的每一幀影格都去作推論,則系統執行效率會變得很差,不易達成每秒30影格的計算,如Fig. 5左上圖所示(這裡僅以偵測為例,另可加入分類辨識及其它工作項目)。
為改善執行效率,可令物件偵測及分類次數減少,因為影格間物件的位置、尺寸、外形可能變動不大,不需一直執行推論工作。如Fig. 5左下圖所示,物件偵測和影像分類的間隔數量可以設成不同(亦可相同),而影格間隔數量則視影片中物件移動速度而定。但是採用這種方式有個缺點,有些影格可能不進行推論,所以會造成沒有結果內容可以疊合回原影像中,畫面會有閃爍情況發生。
若想更精準表示物件的微小位移,則使用傳統的物件追蹤方式會比直接使用神經網路進行物件偵測來得快上許多。只要在兩個偵測影格中間加入追蹤動作,就可自動為中間影格找出物件的位置,改善物件偵測位置偏差及畫面閃爍問題,如Fig. 5右圖所示。目前有提供兩種追蹤模式,zero-term會給予每個物件一個獨立編號(unique ID)方便在任一影格中查找,而short-term則會找出影格間最接近的內容位置。
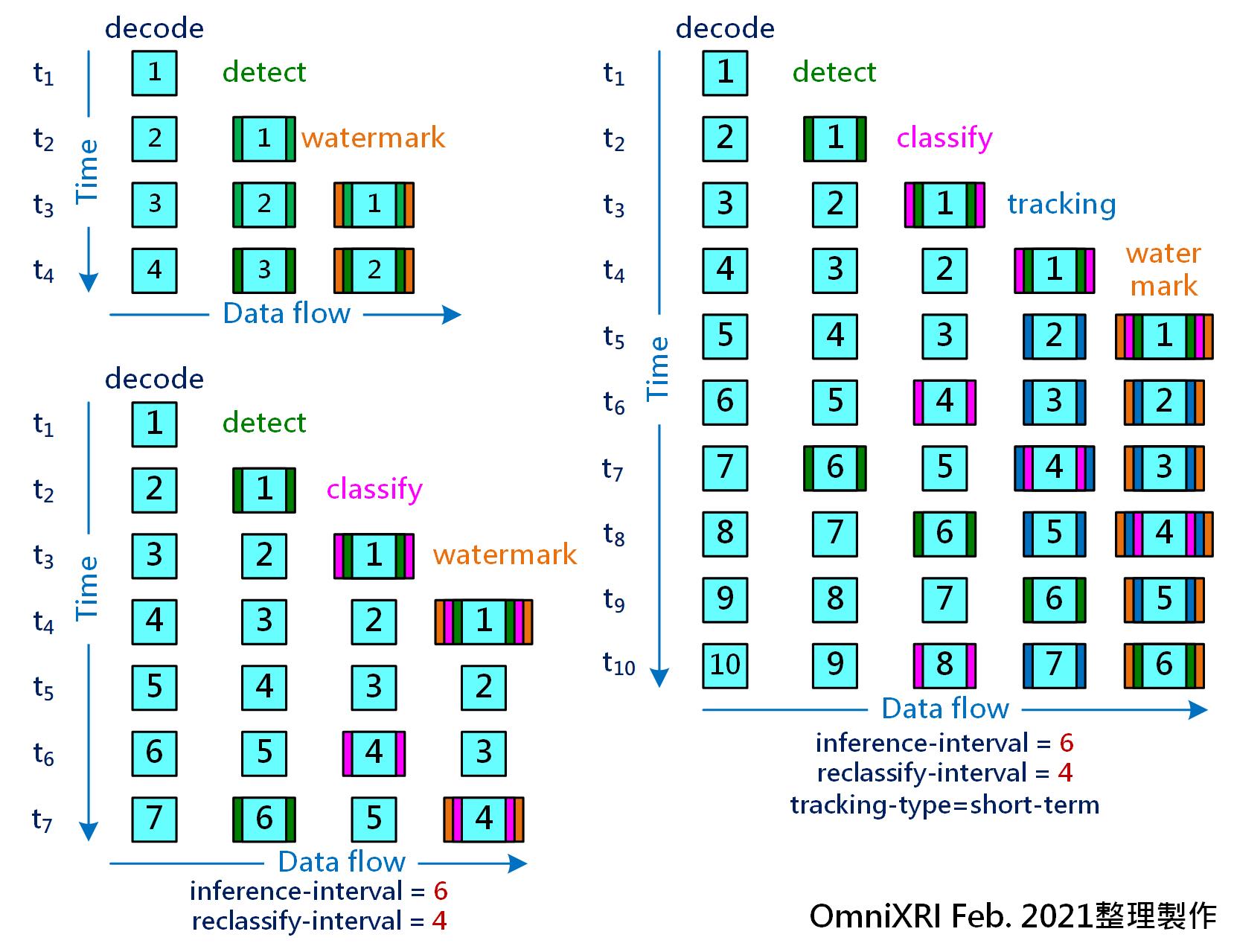
Fig. 5 串流影片分析優化方式比較圖。左上圖:每一幀影格全部都作物件偵測,無優化。左下圖:每6個影格偵測一次,4個影格分類一次。右圖:間隔偵測及分類並加入追蹤補足。(OmniXRI Feb. 2021整理製作)
更多OpenVINO中GStreamer及DL Streamer的原理及使用方式可參考官方提供的Youtube影片說明[7][8][9][10]。
DL Streamer範例說明
目前DL Streamer提供多種執行範例,包括直接命令列指令(gst-launch)、C / C++ / Python程式等,接下來就以直接命令列指令方式來進行介紹。啟動Docker後這些範列預設會安裝在 /opt/intel/openvino_2021.2.185/data_processing/dl_streamer/samples 路徑下(openvino後方數字代表對應版本)。執行範例前要先下載相關預訓練模型及參數檔,其工作命令如下所示。
xhost +local:root
#以Docker方式運行DL Streamer 範例之命令,其中另增加--user root使用者權限,
方便在Docker中安裝文字編輯器(nano, vim等)
docker run -it --device /dev/dri:/dev/dri --device-cgroup-rule='c 189:* rmw' -v
~/.Xauthority:/root/.Xauthority -v /tmp/.X11-unix/:/tmp/.X11-unix/ -e
DISPLAY=$DISPLAY -v /dev/bus/usb:/dev/bus/usb --rm --user root
openvino/ubuntu18_data_dev:latest
#啟動Docker完成會出現下列提示字元,最後數字為OpenVINO安裝版本
openvino@e3a20b255ff3:/opt/intel/openvino_2021.2.185$
#接著更新Docker中系統套件及安裝文字編輯器nano方便後續修改範例程式
apt update
apt install nano
#下載範例程式所需模型及參數,相關範例程式亦於此路徑下
cd data_processing/dl_streamer/samples
./download_models.sh
#完成下載後預設會將模型及參數存放在
/home/openvino/intel/dl_streamer/model 路徑下
由於啟動Docker的命令中有 – – rm,所以每次離開後會清空所有新增內容,再重新啟動時要重新執行上述安裝及下載動作,以免造成範例無法運行問題。更多這個映像檔不同啟動方式及參數,可參考Intel 官方Docker Hub / openvino / ubuntu18_data_dev說明[11]。
在 /data_processing/dl_streamer/samples/gst_launch/ 下主要是提供以gst-launch命令列方式執行串流影片分析的範例,有人臉偵測及辨識、語音事件偵測、車輛行人追蹤、中介資料發佈等應用,這裡會以車輛行人追蹤分析為例進行說明。
首先進到 /vehicle_pedestrian_tracking 路徑下,執行vehicle_pedestrian_tracking.sh 即可看到執行結果。
cd /data_processing/dl_streamer/samples/gst_launch/vehicle_pedestrian_tracking
#執行車輛行人追蹤分析範例,可選配輸入三項參數,亦可不輸入使用預設值
./vehicle_pedestrian_tracking.sh [輸入影片] [偵測間隔幀數] [推論精度]
為更清楚說明執行參數目的及運作指令方式,以下就將vehicle_pedestrian_tracking.sh 內容完整顯示於Fig. 6並補充說明如下:
- 輸入影片(FILE):可支援本地端(硬碟中)影音檔案(*.mp4等)、網路攝影機(Webcam)、串流攝影機(IP Camera)網址(rtps://)或者一般網路串流檔案(http://)。本範例預設值為 https://github.com/intel-iot-devkit/sample-videos/blob/master/person-bicycle-car-detection.mp4 ,意思就是不輸入此項參數時會自動上網讀取這個串流影片,注意電腦必須連網才能正確執行。
- 偵測間隔幀數(DETECTION_INTERVAL):為加速串流影片分析,可設定間隔幀數(Frame)減少計算,其概念如 5左下圖所示。可另外搭配下方追蹤項目使用,補齊中間影格的偵測工作。預設為10,以一般影片影格速度(FPS)為每秒30幀來算,相當於1/3秒偵測一次。對於物件移動緩慢的場景已足夠使用,可視需求調整長短。
- 推論精度(INFERENCE_PRICISION):可依需求選擇不同推論精度,預設為FP32,即推論模型的權重值是以32位元浮點數表示。若想加快計算可選擇FP16(16位元浮點數)或INT8(8位元整數),當然這樣可能會犧牲一點推論的正確性。
以上三組為可自由設定的參數,若只想使用預設值可不輸入,若只想修改偵測間隔幀數,此時第一項參數必須設成 “” (空字串)令其使用預設值,否則將無法正確運作。
除了這些自由設定參數外,範例中還有許多參數可以調整,但需自行以文字編輯器(如nano, vim等)載入再修改。以下分別說明幾個重要參數。
- 推論裝置(INFERENCE_DEVICE):預設為CPU,可自行修改成GPU, MYRIAD, HDDL等不同裝置。但使用GPU前要確定是INTEL 6到10代繪圖處理器Iris或HD系列,或者11代Xe,OpenVINO是不支援NVIDIA或AMD的GPU。另外於模型大小不一,所以不保證所有模型一定可以在CPU以外裝置上使用。另外提醒,若使用手動安裝OpenVINO在Linux上的人要注意,需另外安裝Intel OpenCL驅動程式,否則將無法正確使用GPU。
- 追蹤型式(TRACKING_TYPE):預設為short-term,另可選擇zero-term。主要用於協助補齊偵測及分類未工作之影格的計算。
- 重新分類幀數間隔(RECLASSIFY_INTERVAL):預設為10,這個數字可和偵測間隔幀數相同亦可不同,視需求而定。同樣地也可搭配追蹤型式補齊未分類中間幀數的分類結果。
在這個範例中主要使用四個GVA Plugin並搭配指定模型來完成工作,包括:
- gvadetect:負責車輛、腳踏車、行人偵測,對應person-vehicle-bike-detection-crossroad-0078。
- gvainference:負責人員及車輛屬性推論,分別對應person-attributes-recognition-crossroad-0230 及 vehicle-attributes-recognition-barrier-0039。
- gvatrack:負責補齊未進行物件偵測及分類推論中間影格的分析結果。
- gvawatermark:負責將分析結果產生的圖框和文字疊合回原影像中,方便使用者了解運行速度及是否有正確偵測及分類推論。
- videoconvert:影片格式(色彩空間)轉換。
- fpsdisplaysink:渲染(Rendering)輸出結果到螢幕速度。
更完整的參數說明可參考官網[12]。
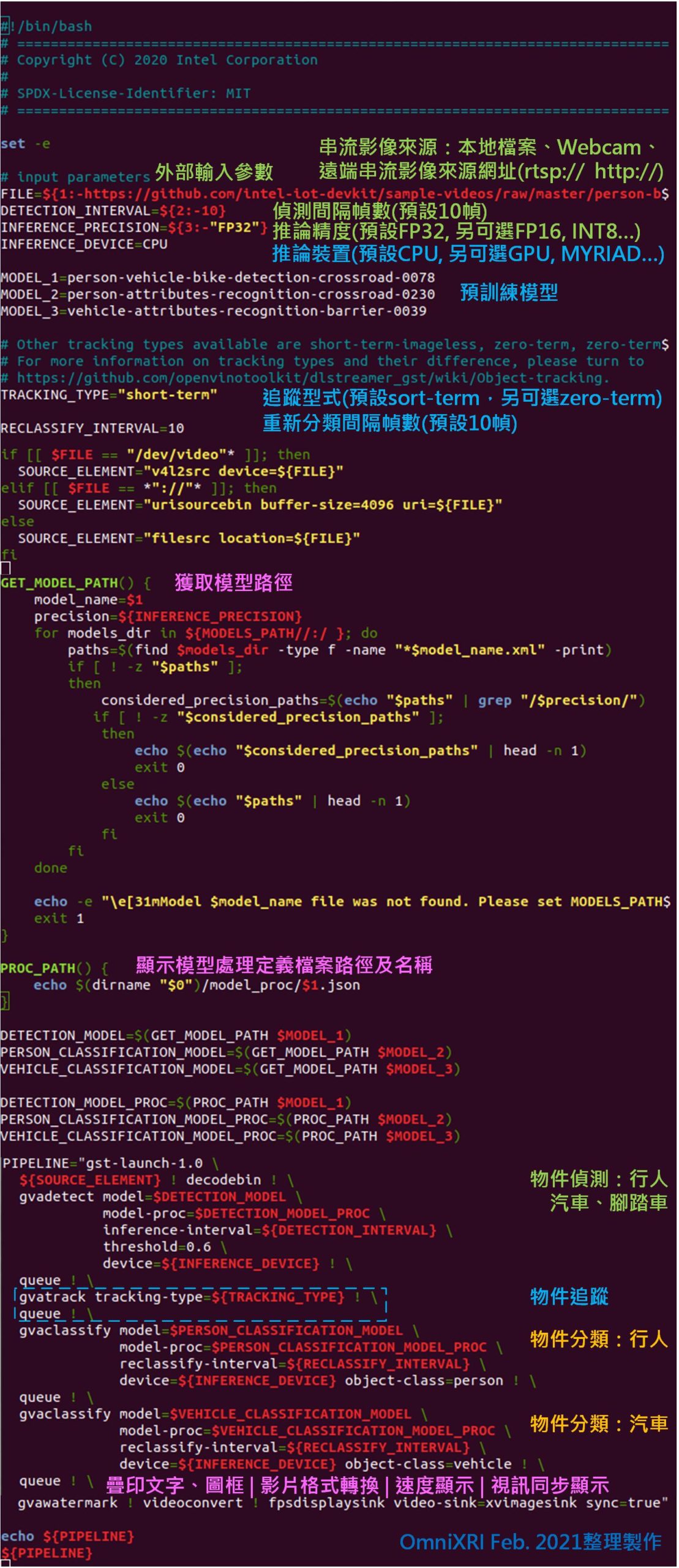
Fig. 6 以命令列方式進行串流影片車輛行人分析範例(vehicle_pedestrian_tracking.sh)說明。(OmniXRI Feb. 2021整理製作)
再來簡單比較一下在不同參數下執行結果。測試條件為:Intel Core i5-4400 @3.1GHz 4核4執行緒,8 GByte記憶體,OpenVINO Docker Image : ubuntu18_data_dev (OpenVINO 2021.2.185 for DL Streamer)。分別以下列三種方式進行比較。其中不啟動追蹤方式即是將Fig. 6中物件追蹤(藍色虛線框)那二行指令刪除。實驗結果如Fig. 7所示。
- 偵測、分類間隔皆為1且不啟動追蹤:執行時CPU四核平均使用率8%,推論負擔極重,平均速度 12.02 FPS。每一個影格都會秀出偵測到的物件及分類結果。
- 偵測、分類間隔皆為10且不啟動追蹤:執行時CPU四核平均使用率5%,推論負擔極輕,平均速度11.67 FPS。每十個影格會秀出秀出偵測到的物件及分類結果,故畫面會有點閃爍。
- 偵測、分類間隔皆為10且啟動追蹤:執行時CPU四核平均使用率65%,推論負擔中等,平均速度11.60 FPS。由於有啟動追蹤功能,所以每一個影格會都會秀出偵測到的物件及分類結果。
整體來說只測試一個串流影片還沒讓CPU耗盡所有算力,所以應該還可以同時接受多個影片(串流攝影機、網路攝影機)或更多分析項目。另外加長偵測及分類幀數間隔明顯令系統計算量大幅減少。若再加上追蹤功能後,除可滿足逐格分析外又不會耗損太多算力,這樣就可容納更多串流影片一起工作。
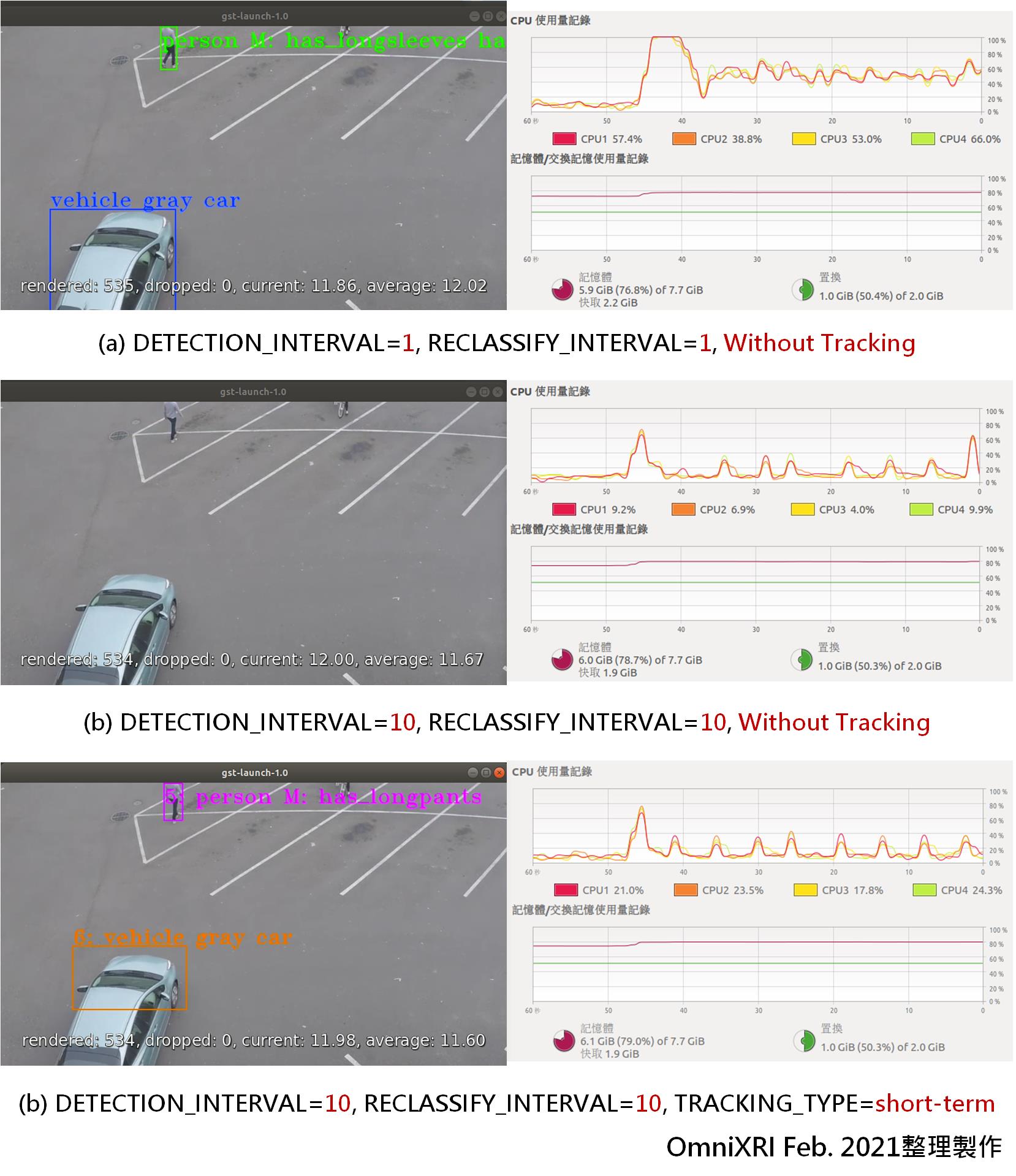
Fig. 7 不同測試條件實驗結果,左行為輸出影像,右行為CPU及記憶體使用情況。(OmniXRI Feb. 2021整理製作)
小結
在現今網路發達的年代,不論是智慧零售、智慧安防、智慧城市等各種應用都離不開串流攝影機或網路影片的傳送方式。有了像Intel OpenVINO DL Streamer這類智能分析工具後,就能更容易滿足大量輸入,快速推論的需求。本文篇幅有限無法一一展現這項工具的所有面貌,剩下部份就有待大家多多去探索了。
參考文獻
[1] GStreamer open source multimedia framework
[3] 許哲豪,” 【Intel OpenVINO™教學】如何利用Docker快速建置OpenVINO開發環境”
[4] Github – openvinotoolkit / dlstreamer_gst
[5] Github – openvinotoolkit / dlstreamer_gst / Elements
[6] GStreamer Video Analytics (GVA) Plugin
[7] Intel Software, “Full Pipeline Simulation Using GStreamer | OpenVINO™ toolkit | Ep. 47 | Intel Software”
[8] Intel Software, “Full Pipeline Simulation Using GStreamer Samples | OpenVINO™ toolkit | Ep. 48 | Intel Software”
[9] Intel Software, “DL Streamer Tracking Element | OpenVINO™ toolkit | Ep. 64 | Intel Software”
[10] Intel Software, “DL-Streamer Python Custom Element | OpenVINO™ toolkit | Ep. 66 | Intel Software”
[11] Docker Hub openvino/ubuntu18_data_dev, “Intel® Distribution of OpenVINO™ toolkit Docker image for Ubuntu* 18.04 LTS”
[12] Intel OpenVINO Toolktit, “Vehicle and Pedestrian Tracking Sample (gst-launch command line)”
(責任編輯:林亮潔)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
- 【Arduino UNO Q專欄02】軟體開發初體驗 - 2026/05/21
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


