作者:賴桑
Intel 推出 OpenVINO™ 這個 Toolkit 後,真的讓之前做機器視覺(Machine Vision)方面的應用簡單許多,以往得東套一個、西加一個開發工具或程式庫,現在單純在 OpenVINO™的架構下,把精力放在要做的應用就好。
想起前幾年,為了要試試在 Banana Pi M1 這種類似早期樹苺派的單板電腦下跑機器視覺運算(那是 Ubuntu 14 作業系統的年代),先得搞定在 OpenCV 網路上組成 Python 的套件,只好自己找到電路板上的晶片驅動程式 Driver 、安裝必要的 C 函數庫,然後再用 GCC 去編譯了一天一夜才終於成功,如今看來,真是一段黑暗時期!
有了 OpenVINO™ ,由於許多部份 Intel 都幫忙先包裝、訓練過了,想開發機器視覺應用時,只需以應用程式介面(API )方式調用 OpenVINO™裡面的各項服務,一切搞定,甚至還有一大堆可以直接下載來用的範例,馬上能有小成果展現: https://software.intel.com/en-us/OpenVINO-toolkit/documentation/pretrained-models
問題在於,對於 Maker 這種動手派的人來說,只能玩範例怎麼會有意思呢?可是話說回來,若是要讓 OpenVINO™ 辨認的物件(Object)在範例裡面沒有怎麼辦?這有點遺憾… OpenVINO™ 目前設計上比較適合用已有的模型(Models)去跑成果(至於 OpenVINO™ 專用的訓練用的工具包,聽說 Intel 也快出了)。
既然目前主要還是利用別的平台訓練出來的 Models ,套用以後可以做物件偵測(Object detection),那從下方架構圖來看,可以運用Tensorflow、Caffe …等不同的深度學習框架來訓練出合用的 Models,再利用OpenVINO™的 Model Optimizer 這個功能,以轉檔的方式把訓練後的成果轉存給OpenVINO™ 使用,這在 MakerPRO 之前的文章中有提到過。
OpenVINO™ Toolkit架構圖(圖片來源:Intel網站)
可是每次一有新的訓練內容,都得再透過 Model Optimizer 轉檔,好像很麻煩,我在想能不能夠直接在運算能力夠強的後台寫好一個專門的訓練程式,利用 Tensorflow、Caffe…等一直跑,不斷地訓練更新 Models 然後存起來,前台 OpenVINO™的應用只要動態讀進來就有新的訓練成果可以用了?
有經驗又眼尖的大大們這時候應該已經注意到,上方架構圖裡面有個熟悉的名字 – OpenCV!相信有操作過 Object detection 的大大在開發以及測試階段應該都有被上述那些框架惡搞過,尤其跑訓練 Models 的時候。既然OpenVINO™ 內建有 OpenCV,而 OpenCV 的新版本具有 DNN 的設計,那就可以透過 DNN 引入其他平台的訓練過後的 Models來用。
裝備
本文的實驗裝備如下:
- 一台跑 Windows 10 的筆電,配備如下圖
- USB WebCam(如果你的筆電已經有內建的攝影機,接下來的內容會介紹如何管理)

本文採用的筆電(圖片來源:賴桑提供)
安裝的步驟,可以參考這篇文章 - OpenVINO無痛安裝指引。
DNN原理
不過話說回來,這 DNN 又是甚麼?怎麼可能具有如此魅力呢?其實 DNN 全名叫做深度神經網路(Deep Neural Network),而 DNN 的立論基礎,其實來自我之前寫過的一篇文章 – ANN,換句話說 DNN 就是一種 ANN 的延伸型;趁著這篇文,我們把一些重要的觀念跟一併跟大家試著講看看吧!
首先,從 上述這篇ANN 的文章中可了解其基本概念,可是怎麼看起來好像少提了甚麼?自適應 Adaptive!從維基百科查的結果…有看沒懂。甚麼叫做 Adaptive 呢?從英文的字義來看,就是具有自動能夠根據變化進行調適的意思,其實這是控制系統(Controlling System)的一種設計理念。
舉例來說:很多 Maker 常玩的四軸無人機就是一種 Adaptive 系統,你看那無人機在空中停旋的時候,無人機是不是會自動根據現場的風向、風速還有你的命令,在電池還能供電的情況下繼續運作?
可這怎辦到的?那是因為從控制系統的觀點來看,無人機上的感測器會不斷感測周遭的環境資訊,這些資訊傳給無人機的控制器後,控制器對機身的姿勢不時地進行校正。當然!一旦風力過強、電力不足…等狀況發生時,控制系統也無法保證有效運轉,那你可能就得準備花錢修理了!
從控制系統的角度來看,任何 NN 都能夠做到 Adaptive!
以DNN來說,通常指超過一層以上 Hidden layer 的情況,而 DNN 在這裡的用途,就是為了要把 Input layer 跟 Output layer 之間產生計算上的對應關係,此外 DNN 還有個好處:不論線性還是非線性都可以。
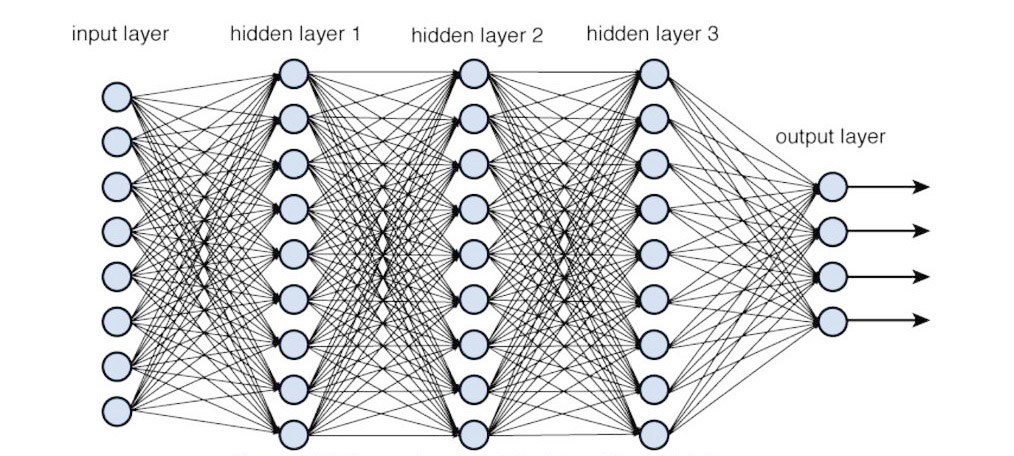
多隱藏層的DNN架構(圖片來源)
最重要的,對於 Output layer 上,DNN 可以算出每種 Output 對應的可能性,不難想像了吧:DNN 就像是象棋裡面的過河卒子一樣,一直向著 Output layer 展開計算然後拼命向前衝那一型(術語叫做 feedforwarding)。
然後回想到物件偵測的應用上,攝影機的一個畫面中可能出現很多物體,那針對畫面中的物體,到底哪幾個可以辨認、可信度又有多高…正是我們想要的:已經先把可以處理的 Output 分類好,每次都從 Input 去計算到底這些分類出來的 Output 各自機率有多少,然後透過這些各自機率值來看要不要採信。
恰好不是?事實上也可以用 CNN 搭配 Softmax 這類激勵函數(Activation function)辦到,不過 DNN 剛巧在這裡做得無縫接軌,當然就拿來用啦!這也再次證實了我曾講的:NN 沒有所謂好壞對錯,只有甚麼樣的情況下適合。
實際試試
請先外掛一台 USB WebCam 攝影機,沒有的話,筆電上內建的網路攝影機就湊合著用吧!程式碼的部分,就用 Python3 寫,本來 OpenVINO™ Toolkit 就內定有 Python3 的支援。記得要把 MobileNetSSD_deploy.caffemodel 、 MobileNetSSD_deploy.prototxt 兩個檔案也一併放到跟 openvino_real_time_object_detection.py 程式檔案同個目錄下,透過 IDLE 來跑。
打開 OpenVINO_real_time_object_detection.py 程式檔案,程式碼如下:
from imutils.video import VideoStream
from imutils.video import FPS
import numpy as np
import argparse
import imutils
import time
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
COLORS = np.random.uniform(0, 255, size=(len(CLASSES), 3))
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe('.\MobileNetSSD_deploy.prototxt', '.\MobileNetSSD_deploy.caffemodel')
#For I don't have NCS2 yet! XXD
#net.setPreferableTarget(cv2.dnn.DNN_TARGET_MYRIAD)
print("[INFO] starting video stream...")
vs = cv2.VideoCapture(0)
# vs = cv2.VideoCapture(1)
time.sleep(2.0)
detected_objects = []
while True:
ret, frame = vs.read()
frame = imutils.resize(frame, width=1280, height=720)
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (600, 600)), 0.007843, (300, 300), 127.5)
net.setInput(blob)
detections = net.forward()
# loop over the detections
for i in np.arange(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > args["confidence"]:
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
detected_objects.append(label)
cv2.rectangle(frame, (startX, startY), (endX, endY), COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
# show the output
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
cv2.destroyAllWindows()
來解說一下程式碼中的一些重點,其中第 9 到 12 列這裡,是個從外部接受參數的程式段,有個地方我覺得蠻有意思的:
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
第 10 列的意思是超過定義的機率值(程式碼中是default=0.2,也就是 20% 的可信度)就被程式挑選出來,在下文實際執行的影片中,可看到在鏡頭前出現可辨識物件時即會被框選出來,並標示該物體的名稱(如bottle)以及機率。
再看第 14 到 17 列,就是程式能偵測出來的有那些物體,這些物體(瓶子、公車、汽車、貓、椅子…)當然是套入已訓練後的模型,模型裡面包含這些物體的定義,這才有辦法處理呀!
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
我們是套用網路上已經有人用 Caffe 訓練過後的模型,這在第 21 列就可以看到:
net = cv2.dnn.readNetFromCaffe('.\MobileNetSSD_deploy.prototxt', '.\MobileNetSSD_deploy.caffemodel')
除了 Caffe 外,像是 TensorFlow…等,也都可以喔!
接下來,就跟你用的攝影機有關係了,由於我用了兩個攝影機(筆電一個,外掛一個),第 27 列這裡可看到:第 0 號是筆電自己的,第 1 號是 USB WebCam。如果你沒有兩個攝影機,你就得根據你的攝影機來調整參數,不然解析度、螢幕畫面的大小,可就不保證你會滿意!
vs = cv2.VideoCapture(0) # vs = cv2.VideoCapture(1)
這樣要是有多個攝影機,要怎樣管理有概念了吧?
再來就是這個程式主要做的事情了,其中第 34 到 37 列這裡跟照相機、螢幕可以呈現的效果有關,你的攝影機如果沒那麼高檔或者螢幕的解析度比較低,這幾列的參數就調整看看,其中第 32 列就是叫照相機抓影像:
ret, frame = vs.read()
然後把抓來的影像利用第 34 到 37 列根據照相機以及解析度調整:
frame = imutils.resize(frame, width=1280, height=720)
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(cv2.resize(frame, (600, 600)), 0.007843, (300, 300), 127.5)
最後交由第 39 跟 40 列進行辨認,稍早不是有提到,DNN 就是把 Input 透過超過一層的 Hidden layer 產生計算結果能對應出 Output 各個的機率值,即所謂feedforwarding – 這樣對於 DNN 做甚麼,印象清楚些了吧!
net.setInput(blob)
detections = net.forward()
值得一提的是:第 37 列有個blobFromImage 指令,blob 在電腦的術語裡面其實是 Binary Large Object 的簡寫,說穿了就是一種以很長一串 0、1 二進位表示的物件。那為什麼會冒出來這東西呢?其實,DNN 也是需要自己能夠接受的 Input 格式,這個 blobFromImage 指令就是命令程式先把第 32 到 36 列照相機抓進來的畫面,經過縮放處理之後,再轉換成 DNN 可以接受的 Input 格式,才給 DNN 去當成 Input。
至於第 42 到 55 列,那就更容易理解了吧!辨識完成後 Output 各個不是會有對應的機率值?程式就根據第 14 到 17 列的那些物體當基礎,看看機率上哪個能有第 10 列講的信心值,有的話就框起來、標示是哪種物體、還有對應的機率是多少。
# loop over the detections
for i in np.arange(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > args["confidence"]:
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
label = "{}: {:.2f}%".format(CLASSES[idx], confidence * 100)
detected_objects.append(label)
cv2.rectangle(frame, (startX, startY), (endX, endY), COLORS[idx], 2)
y = startY - 15 if startY - 15 > 15 else startY + 15
cv2.putText(frame, label, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, COLORS[idx], 2)
實際執行的物件辨識結果如下:
延伸應用
既然透過 DNN 可以讓已有訓練後的模型當成檔案一樣被套入,如此一來,是不是可以繼續在OpenVINO™ Toolkit環境中用同一支程式來辨識更多種,或更精確的物件呢,也就是把已訓練好的模型先存下來,需要時將第 14 到 17 列的 CLASSES 內容清空再重新讀取新的文字檔案,再讀入模型檔案並刷新程式呢?
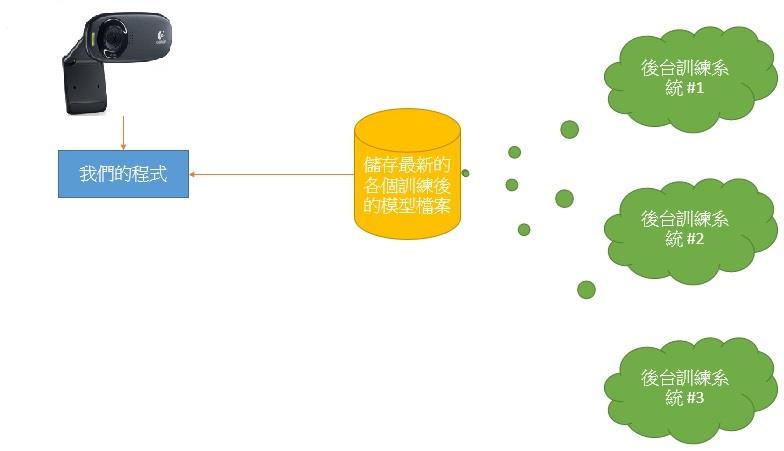
讓OpenVINO™能動態套入各種模型的構想(圖片來源:賴桑提供)
能這樣就太方便了,因為 OpenVINO™ Toolkit 自己也有 Model Optimizer 可以幫忙把別的模型轉檔成專門的統一格式,此外 Intel 也提供好多可以用的模型,這樣就能動態地套用不同的模型隨時因應需要。
小結
趁著這篇我們順便把怎麼用OpenVINO™ Toolkit 的簡單方式、DNN 用來套入已有訓練後的模型,這兩個特色跟大家一起分享,接下來我打算針對:
- 透過不同的影像擷取方式(哪條法律規定照相機只能接筆電!?)
- 用甚麼樣的方式可以提升效能
這樣一來 OpenVINO™ Toolkit 的使用便利性,就很容易被越多應用場景採用。
(責任編輯:楊子嫻)

- 【開箱評測】用Mbed上手開發DSI 2599開發板 - 2020/08/03
- 【OpenVINO™教學】自製麵包影像辨識POS機的應用 - 2019/12/24
- 【邊緣運算】OpenVINO好夥伴 — athena A1 Kit x86單板 - 2019/11/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/08/01
這篇文章給了我很棒的方向,原來完全不需要用到OpenVINO直接用OpenCV就能搞定Tensorflow訓練好的模型.