作者:賴桑
透過機器視覺(Machine Vision)的應用越來越多,過往要實作這方面的應用對一般人而言是有一定的門檻,但透過OpenVINO™這樣的工具可降低這個門檻,因為它已經把開發機器視覺應用的基本結構簡單化,所以對於想開發AI應用的人來說頗有幫助。上次我寫了一篇關於如何套用現有的模型(Model)來做物件偵測(Object Detection),剛好看到CH大/曾成訓之前在Raspberry Pi上做了一台麵包結帳機,所以就手癢自己用Windows 10 PC來跑OpenVINO™的這個應用看看~
本篇所需設備超級簡單:就一台Windows 10 PC跟一個外接的羅技Logitech C170 WebCam,其實也不一定要外接WebCam,鏡頭可以拍到要辨認的麵包就行了!本次我看過整個CH大的大作後,重工成只靠軟體能執行就可以運作。
說真的,這次CH大的功勞不小,就算訓練出來的Model還不是很精準,可是當作展示範本已經工程浩大!畢竟訓練(Training)其實是機器學習(Machine Learning)裡比寫應用更麻煩的一段,因為到底要怎麼訓練(幾層?幾個神經元?)才能夠讓模型逐漸收斂到我們堪用的程度,這可是截至目前為止,沒有標準答案!
系統運作原理
系統其實只是一直處在迴圈Loop狀態下,不斷地進行物件偵測而已:
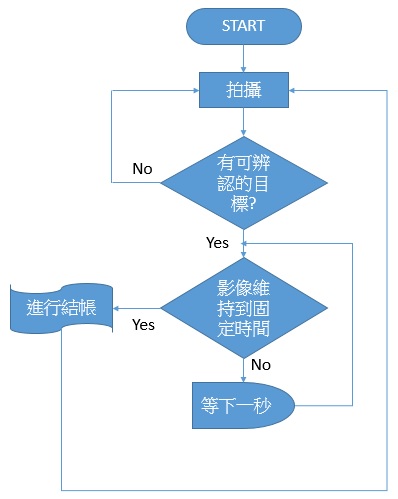
系統運行流程大要(圖片來源:賴桑)
程式碼的基本解說
但程式上的寫法,就得特別跟各位講解一下了!原則上程式碼總共分成三個檔案:

還請記得執行本程式前,先確定我們需要的Python3 Packages都有安裝好!由於主角是Intel OpenVINO™,所以請先參考官網之前已經公布的文章,在你的Windows 10 PC上安裝。再者,用命令提示字元,安裝剩餘的Python3 package,就可以用Python3來執行看看範例先了。安裝剩餘的Python3 package所需元件的指令:
pip install –upgrade easygui imutils
接著看看執行的效果!從影片中可以看到,麵包被攝影機拍攝到,然後畫面上有可以辨認的目標又維持大約八秒一直沒變化,我們的範例程式就結算金額:
再來就從main開始看,比較值得注意的是一開頭關於能辨識的目標定義;這是因為訓練當時,樣本只有這幾個…XXD
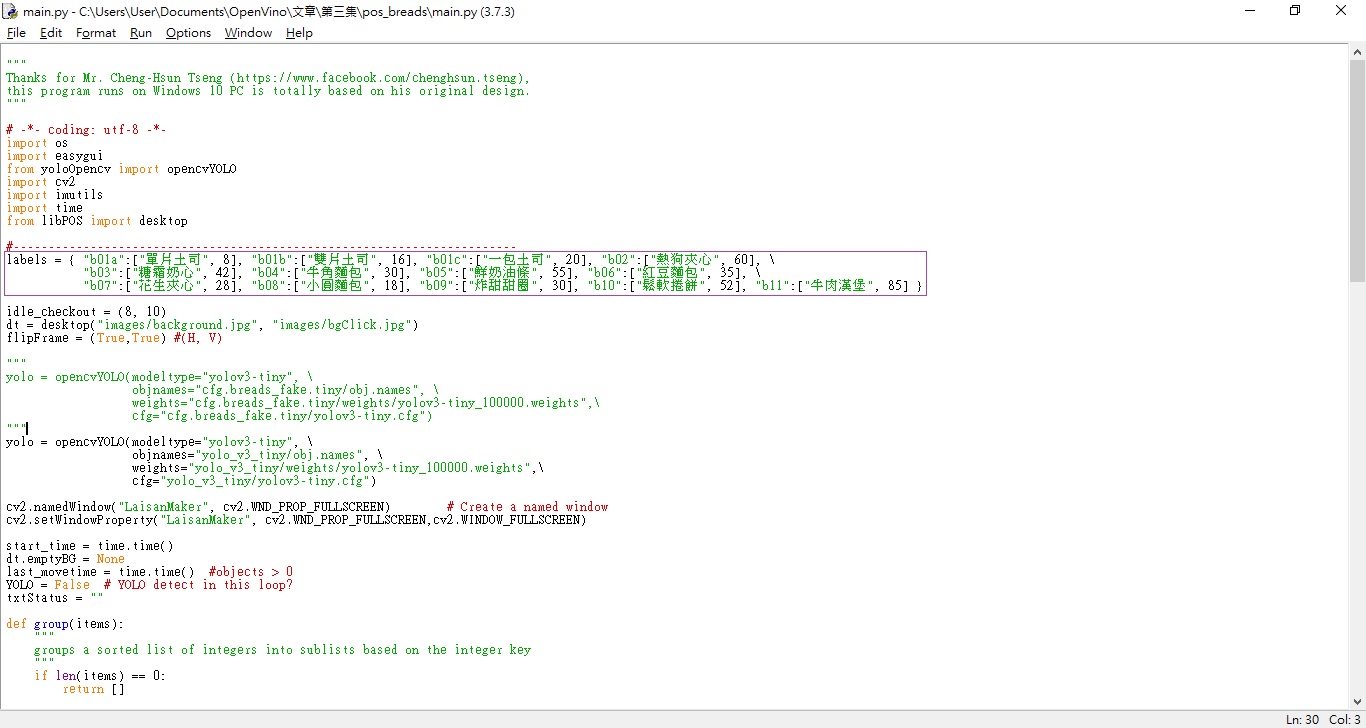
目前可以辨認的麵包影像(圖片來源:賴桑)
再來是我們要載入的模型,請記得:模型不同的話,那P2出現可以辨識的目標,就有可能是不同的!這點可以從yolo_v3_tiny子目錄下看到,其中obj.names這個檔案就是能辨認的目標代號,這個代號要符合P2中那些麵包品項的對應,不然就牛頭不對馬嘴了。
另外的obj.data就是紀錄訓練成功後的彙整資訊;obj.names檔案裏面這些資訊就是對照到main裡面labels的,labels每一個項目有三項資訊,看得出來吧:目標代號、中文名稱、單價。

訓練出來的模型中可以辨認的標的物代號(圖片來源:賴桑)
所以,主程式yolo這部分就是宣告與載入所需要用的模型;而每個模型裡面,必然是由許多神經元形成拓樸,個神經元上面會含有權重Weights,這些權重就存在yolo_v3_tiny\weights子目錄下,有個yolov3-tiny_100000.weights的檔案。

載入本程式需要的模型跟定義 (圖片來源:賴桑)
每次程式就不斷拍攝,遇有可以辨認的目標就放入shoplist裡面;還有,libPOS這個檔案中會根據物件的數量(有人一次買多個相同的紅豆麵包啊!)才去結帳。
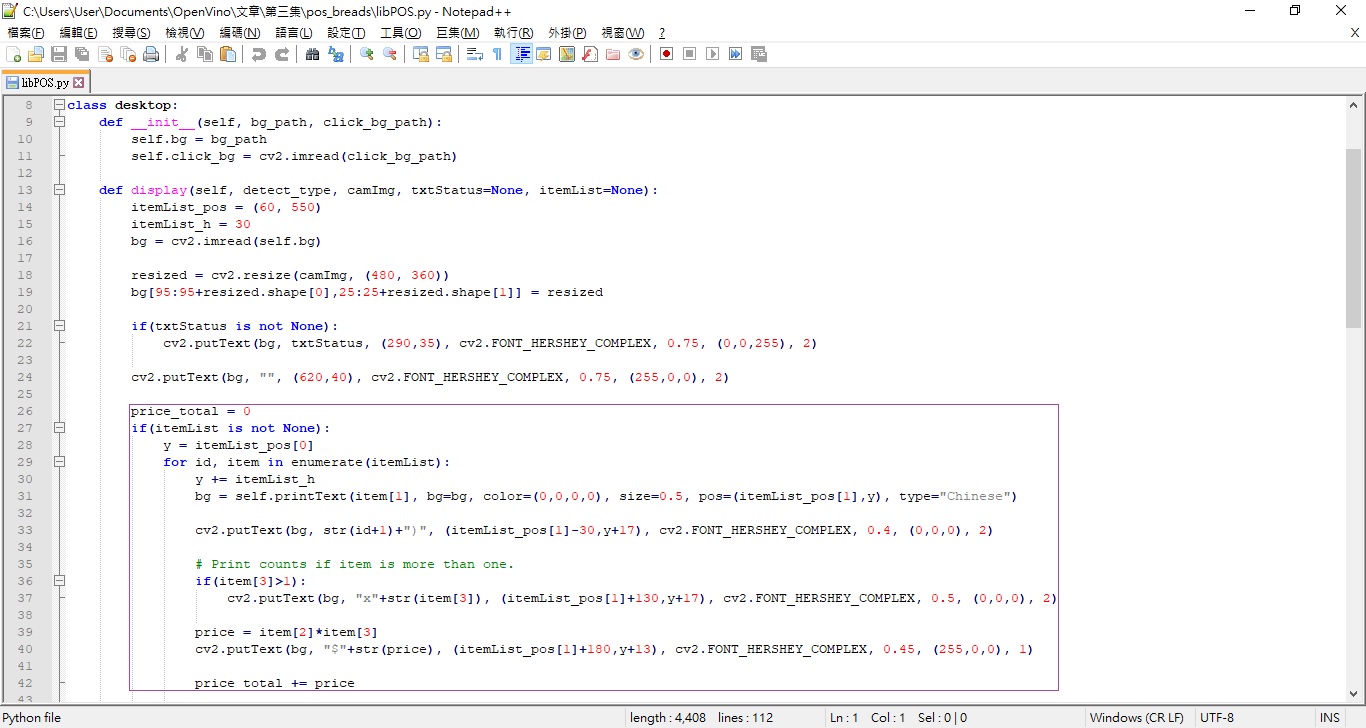
根據可以辨識的項目與個數進行結帳(圖片來源:賴桑)
至於images子目錄下,那就是背景圖,還有fonts子目錄下,就是中文TrueType字型,我是採用微軟的標楷體;在main以及libPOS都有引入。
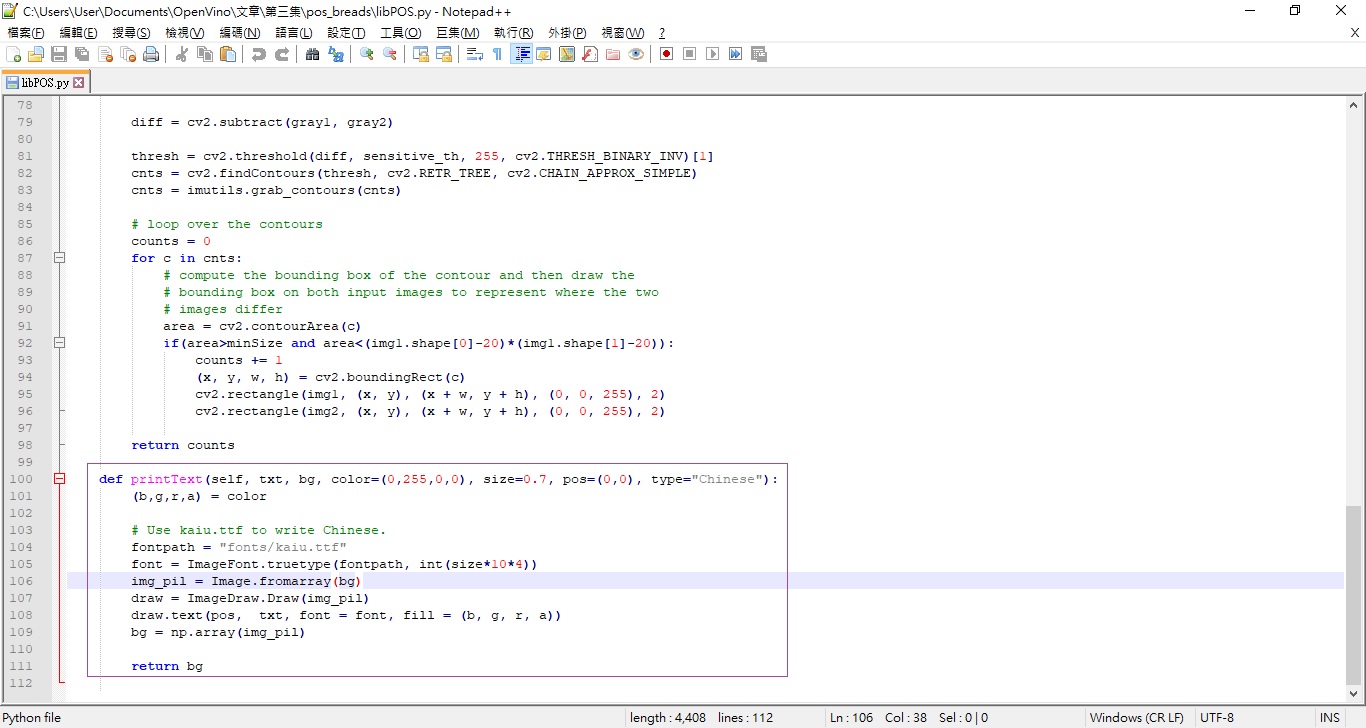
顯示TrueType中文字樣(圖片來源:賴桑)
簡單描述目前常見的物件辨識運算原理
我們這個範例主要是透過Yolo演算法訓練完成後,讓Intel OpenVINO™直接套用這個訓練的模型,做到影像中麵包的辨認。但可能有些人對於到底電腦怎做得到分辨出圖片裡面我們想要的物件在哪邊的原理還不清楚,這邊跟各位建立一個簡單的觀念。
我們在前面的文章中討論過CNN的原理,但詳細上怎達成的?還是很模糊…那簡單看個範例!我們拿下圖當作範例一步步拆解:

圖1 範例照片(圖片來源:賴桑)
首先要先聲明:範例圖(圖1)裡面有紅框框,這個在現實的狀況並不存在!我們也沒在麵包的影像上面都加過框啊~只是純粹為了方便讓大家看到所以才加的。首先把範例圖拆成3乘以3共九個區塊(現實的會拆很多),然後對每個區塊都做物件偵測:

圖2 拆成九個區塊(圖片來源:賴桑)
假定我們要偵測的共三種,分別是行人、汽車與機車,那麼說來每個區塊就可以把結果,個別列成一個表:

跟著就照圖2分隔的方法,一個個區塊取出來!根據A1的內容如圖3:

圖3 取出A1這一區塊(圖片來源:賴桑)
所以A1的表就會是:

那再取得A2,這時候很明顯A2是可以偵測出有車輛的才對!

圖4 取出A2這一區塊
所以,A2的表應該要是:

依此類推,我們會有3乘以3也就是九個這樣的表,每個表裏面有四筆紀錄,所以總共會成為9區塊乘以4筆,也就說全部共36筆紀錄。用流程圖看就是:
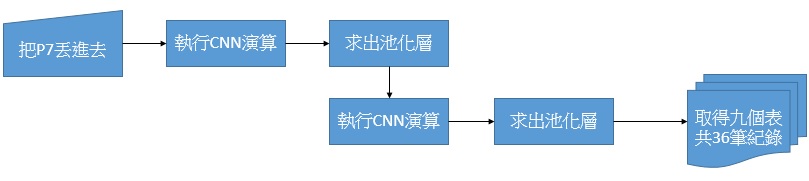
簡單用流程描述Yolo(圖片來源:賴桑)
這就是現階段機器視覺上達成物件偵測的基本由來與原理。想當然,現實的演算法有一大堆,好比RCNN是改成邊界框的方式來進行偵測…等。此外,按照剛剛的案例,應該很容易聯想到了:反正每個區塊都會標示「有沒有物件被偵測到」、「偵測到哪種物件」這兩筆紀錄,那我都針對每個表中,這兩筆紀錄中有標示出現我要偵測的物件去處理,不是更快又簡單?反正沒有的我不管就好啦,畢竟演算法還是人腦想出來的啊!
小結
從這次的實際開發中我也學到不少!很多之前機器視覺上的原理過往沒機會實作,透過寫這篇文去網路上找了一大堆教學文件然後一個個比較,再利用Windows 10來試OpenVINO™跑成果,越來越有成就感!
可是話說回來,這次也凸顯出了OpenVINO™這個Toolkit的好處 – 能夠很容易讓機器視覺的應用開發上手,要不然光那一大堆程式碼要維護,搞到哪年才能弄出台POS的展示範例?
但是OpenVINO™目前的版本還沒有提供Train功能在裡面,這點蠻可惜的!所以訓練模型的時候,像我最近弄水果影像辨識就是用Keras,可是Keras沒直接支援OpenVINO™的Model Optimizer可以進行轉檔,所以我們為了把H5轉成TensorFlow的PB,兩個多禮拜來搞到天翻地覆~~希望明年Intel OpenVINO™推出的新版本,可以把這些也包進去,那就更簡單不過了!
(責任編輯:王姵文)

- 【開箱評測】用Mbed上手開發DSI 2599開發板 - 2020/08/03
- 【OpenVINO™教學】自製麵包影像辨識POS機的應用 - 2019/12/24
- 【邊緣運算】OpenVINO好夥伴 — athena A1 Kit x86單板 - 2019/11/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2020/01/03
1. Thanks for your detailed comments.
2. Keras model can be converted into tensorflow model (call it TF_Keras), then you can let this TF_Keras be fed into MO to get the openvino-based weights. However, you must take care the following facts:
2.1 Output/input/deimnesions (for Model layers): may be modified as required;
2.2 Precision: 32 bit/64 bit/
That is all. It is midnight, good night !!