作者:Felix
今年七月物件偵測模型 YOLO(You Only Look Once)官方終於釋出承接 YOLOv4 的後繼版本 YOLOv7,由中研院王建堯(Chien-Yao Wang)博士等人共同發表論文與實作程式碼。相關的技術原理已經有眾多大神的文章作說明,筆者就不在此丟人現眼了。然而比較特別的是此版本使用了 pyTorch 框架實作 YOLO 架構,並且導出模型,這就讓使用上更加方便彈性了!本篇文章將使用 OpenVINO 轉換 YOLOv7 模型,使其提高在邊緣裝置上的 AI 推論效能!
OpenVINO 2022.1 環境準備
筆者執行開發環境的筆電 CPU 為 Intel Core i7-8565U,作業系統為 Ubuntu 20.04 ,本篇後續的操作均在此電腦執行。OpenVINO 版本使用 2022.1 Python 開發環境的建置可以參照 OpenVINO 官方說明文件分別安裝 runtime 執行環境與 dev開發工具,過程在此就不多作贅述了,留意安裝後OpenVINO版本為 2022.1即可。完成後執行以下指令進入 OpenVINO python虛擬環境開始進行本次實作。(虛擬環境路徑依據建置過程可能會有所不同)
下載與測試 YOLOv7
首先當然是到 YOLOv7 官方 github 下載專案:
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
接著要取得預訓練好的權重,根據不同的輸入影像大小以及參數量有不同的預訓練模型,如yolov7x、yolov7-w6、yolov7-d6等,在此筆者就以推論速度為考量下載yolov7.pt,各位有興趣也可以都下載進行測試。
安裝所需的python 套件,預計會花費十分鐘左右的時間。
完成後就可以來測試YOLOv7的即時推論,帶入參數 weight 指定剛剛下載的預訓練權重,參數 source 則是輸入資料,可以帶入照片或影片的檔案路徑,這邊帶入 0 意思為編號0號的影像擷取裝置,也就是筆者電腦內建的 webcam。
載入完成後就會看到即時預覽的畫面,同時在終端機上會顯示偵測到的物件以及所花費的時間。可以看在筆者電腦上跑一張推論需要花費將近半秒鐘的時間,以一台商務筆電的性能來說,也只能說是中規中矩。
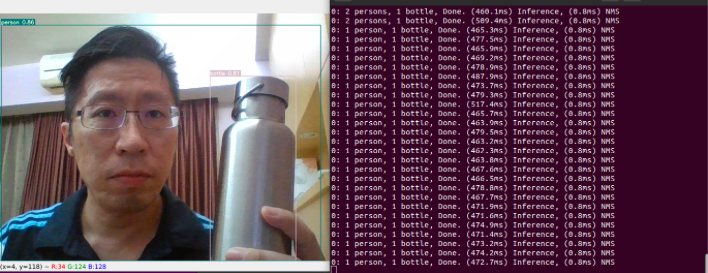
除此之外也測試一下圖片的推論,帶入權重、信心度、影像資料、以及影像路徑,這裡使用 yolo 專案內的影像進行推論:
推論完成的輸出資料會放置於 runs/detect/exp* 路徑下,每次執行都會產生一個新的資料夾,留意輸出訊息中的路徑。執行以下指令開啟推論完成的照片,可以看到結果相當不錯,連被遮擋的物件也都被順利偵測出來!
轉換到 ONNX 與 IR 模型格式
接下來為了將預訓練模型 yolov7.pt 使用 OpenVINO 加速,需要將其轉為 ONNX 模型格式,再丟到模型優化器 mo。為此確保開發環境已安裝好 OpenVINO ONNX 套件,執行以下指令進行安裝:
接著我們使用 YOLOv7 專案的程式將模型匯出為 ONNX 格式:
執行完成則會產生 yolov7.onnx 檔案。若在匯出時產生以下錯誤訊息 『 ONNX export failure: Exporting the operator silu to ONNX opset version 12 is not supported. Please open a bug to request ONNX export support for the missing operator.』 代表目前開發環境上的 pyTorch 版本過舊,無法支援新的運算子,可以使輸入以下指令來更新 pyTroch:(此問題也有被提出在github 上的 issue#89,提供給各位參考)
在進行模型最佳化前,先使用 benchmark_app 進行模型的效能評估,同時查看模型相關資訊。
觀察輸出如下,在 [Step 6/11] Configuring input of the model 顯示模型的輸入與輸出資訊,input 為 images, output 為 ‘output’、’516’、’528’,在接下來模型優化器會使用到此作為參數。
[Step 1/11] Parsing and validating input arguments
[ WARNING ] -nstreams default value is determined automatically for a device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 2/11] Loading OpenVINO
[ WARNING ] PerformanceMode was not explicitly specified in command line. Device CPU performance hint will be set to THROUGHPUT.
[ INFO ] OpenVINO:
API version............. 2022.1.0-7019-cdb9bec7210-releases/2022/1
[ INFO ] Device info
CPU
openvino_intel_cpu_plugin version 2022.1
Build................... 2022.1.0-7019-cdb9bec7210-releases/2022/1
[Step 3/11] Setting device configuration
[ WARNING ] -nstreams default value is determined automatically for CPU device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 4/11] Reading network files
[ INFO ] Read model took 301.17 ms
[Step 5/11] Resizing network to match image sizes and given batch
[ INFO ] Network batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model input 'images' precision u8, dimensions ([N,C,H,W]): 1 3 640 640
[ INFO ] Model output 'output' precision f32, dimensions ([...]): 1 3 80 80 85
[ INFO ] Model output '516' precision f32, dimensions ([...]): 1 3 40 40 85
[ INFO ] Model output '528' precision f32, dimensions ([...]): 1 3 20 20 85
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 384.81 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] DEVICE: CPU
[ INFO ] AVAILABLE_DEVICES , ['']
[ INFO ] RANGE_FOR_ASYNC_INFER_REQUESTS , (1, 1, 1)
[ INFO ] RANGE_FOR_STREAMS , (1, 8)
[ INFO ] FULL_DEVICE_NAME , Intel(R) Core(TM) i7-8565U CPU @ 1.80GHz
[ INFO ] OPTIMIZATION_CAPABILITIES , ['FP32', 'FP16', 'INT8', 'BIN', 'EXPORT_IMPORT']
[ INFO ] CACHE_DIR ,
[ INFO ] NUM_STREAMS , 4
[ INFO ] INFERENCE_NUM_THREADS , 0
[ INFO ] PERF_COUNT , False
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS , 0
[Step 9/11] Creating infer requests and preparing input data
[ INFO ] Create 4 infer requests took 0.78 ms
[ WARNING ] No input files were given for input 'images'!. This input will be filled with random values!
[ INFO ] Fill input 'images' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 4 inference requests using 4 streams for CPU, inference only: True, limits: 60000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 860.03 ms
[Step 11/11] Dumping statistics report
Count: 96 iterations
Duration: 64118.68 ms
Latency:
Median: 2184.34 ms
AVG: 2645.58 ms
MIN: 2076.72 ms
MAX: 3766.81 ms
Throughput: 1.50 FPS
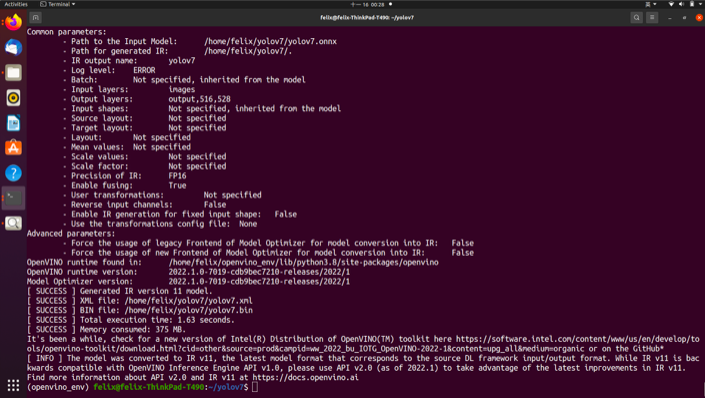
執行以下模型優化器指令,分別帶入輸入模型 yolov7.onnx、輸入層 images、輸出層 output,516,528 以及資料格式 FP16 等參數,這邊使用半精度的浮點數 FP16 來加速推論。
優化完成的提示訊息也顯示此 IR 模型為 v11 版本,建議使用推論引擎 2.0 的 API 來達到較佳的效果,也就是 OpenVINO 2022.1 之後版本。
使用 OpenVINO 加速推論
得到優化完成的 IR 模型檔,就可以開始進行 OpenVINO 的推論了!然而程式也不需要吾人從頭開發,github 上已有強者大神提供 OpenVINO C++ 與 Python 範例,輸入以下指令下載該專案:
git clone https://github.com/OpenVINO-dev-contest/YOLOv7_OpenVINO_cpp-python.git
cd YOLOv7_OpenVINO_cpp-python/python/
輸入以下指令安裝必要套件:
確認已具備了必要套件即可執行 OpenVINO 推論,參數 -m 代表指定的模型,可以選定 IR 或是 ONNX 格式, 參數 -i 代表輸入照片檔案。輸入以下指令使用 IR 模型推論:
或是使用 ONNX 模型推論:
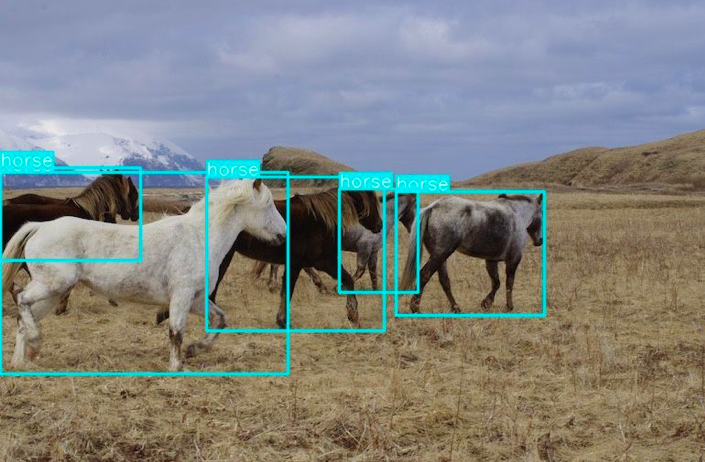
完成推論後會產生一個名為 yolov7_out.jpg 的檔案,開啟此檔案來檢視推論輸出,可以看到推論輸出和原始 YOLOv7 兩者的結果幾乎無異!
Benchmark 效能比較
最後筆者也在開發平台上使用 benchmark_app 將 yolov7.pt 以不同的模型格式以及推論硬體做比較,其結果如下表。此結果皆是在筆者的商務筆電上以 Intel Core i7-8565U 跑出來的結果,並不代表所有的處理器以及在真實邊緣裝置上的數據,僅提供給各位讀者做個參考依據。可以看見使用 CPU 與 GPU 進行 ONNX 模型推論僅有 1.85 FPS 與 2.5 FPS,和前述使用 yolov7 detect.py 推論的 FPS 相當。而在轉換為 IR 格式後進行 GPU 推論約有 5.51 FPS 的效能,提升約有 220%!
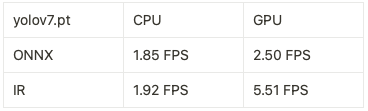
不同模型格式及推論硬體比較表
小結
近期 YOLOv7 可以說是台灣之光,在 AI 界造成不小回響,而邊緣裝置上的應用實作後續也可預期將會陸續發酵。即便本次實作僅做到使用照片輸入進行推論,但也已經打通了 OpenVINO 串上 YOLOv7 的主要流程架構,搭配其他工具後續要完成影像串流應該也非難事,這部分就留給各位開發者們去做延伸了!筆者在過程中也測試了最新的 OpenVINO 2022.2 版本,也都可以順跑執行上述程式,提供給想要使用 YOLOv7 實作專案的朋友做個參考!
(責任編輯:謝嘉洵)

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!