作者:許哲豪(Jack)
 有看過或玩過「神奇寶貝(寶可夢)」的朋友都知道,訓練家們要依怪獸的屬性(火系、草系、電系等)給予適當的培訓,再挑選合適的對象及不斷的對戰磨煉才能有好的戰鬥表現。同樣地,AI模型訓練師也是如此,依據不同的應用場景(影像分類、物件偵測、影像分割等),挑選適合在指定的硬體(CPU, GPU, VPU, FPGA等)上推論的模型,並反覆調整合適的超參數(hyperparameter),如此才能有好的成果。
有看過或玩過「神奇寶貝(寶可夢)」的朋友都知道,訓練家們要依怪獸的屬性(火系、草系、電系等)給予適當的培訓,再挑選合適的對象及不斷的對戰磨煉才能有好的戰鬥表現。同樣地,AI模型訓練師也是如此,依據不同的應用場景(影像分類、物件偵測、影像分割等),挑選適合在指定的硬體(CPU, GPU, VPU, FPGA等)上推論的模型,並反覆調整合適的超參數(hyperparameter),如此才能有好的成果。
由於這樣的調參工作需要耗費大量的時間及精力才能完成,傳統上只靠一堆數字報表來分析調整方向,所以非常仰賴專業工程師的能力才能完成。因此Intel OpenVINO Toolkit(以下簡稱OpenVINO)在2019 R3版之後提供了一項非常方便的網頁式圖形化介面工具「DL Workbench」(Deep Learning Works Benchmark),讓不會寫程式、非專業的工程師也能輕易上手進行模型選用、下載、校正、參數調整、效能比較、瓶頸分析、優化及打包佈署到目標硬體平台上。
接下來就從「如何安裝DL Workbench」、「DL Workbench工作流程」作簡單說明,最後再以「實際案例操作:SSD物件偵測」完整說明AI模型的分析、優化及佈署的步驟。
如何安裝DL Workbench
目前OpenVINO提供多種安裝方式,其中最簡單的方式就是直接到Docker Hub上去下載(Pull)映像檔(Images)。若還不熟悉如何使用Docker安裝歩驟的朋友,可以參考「【Intel OpenVINO教學】如何利用Docker快速建置OpenVINO開發環境」[1]。當然如果想直接在命令列下安裝DL Workbench的朋友也可參考官網說明[2]。不過這裡提醒一下,DL Workbench只有在Linux(Ubuntu 18.04/20.04) Docker環境下才能完整使用Intel系列的CPU, iGPU, Myriad(NCS2), HDDL(VPU)等硬體,而在Windows和macOS使用Docker的朋友則只能使用CPU工作。以下說明皆以Linux環境做為說明。
使用Docker安裝方式的人,只需依下列指令操作即可完成安裝。接著啟動DL Workbench工作環境,啟動時可依不同需求可加上-ENABLE_GPU 或 -ENABLE_MYRIAD 或 -ENABLE_HDDL指令來增加硬體推論能力,如Fig. 1所示。
# 從Docker Hub拉下(下載)DL Workbench映像檔
docker pull openvino/workbench:latest
#下載完成後,檢查可工作映像檔
docker images
#第一次啟動須先下載批次檔 start_workbench.sh,並增加批次檔可執行權限,第二次啟動時就不須執這二行命令
wget https://raw.githubusercontent.com/openvinotoolkit/workbench_aux/master/start_workbench.sh
sudo chmod +x start_workbench.sh
#啟動DL Workbench CPU工作環境,若已有安裝好對應驅動程式,則另可選擇性加上-ENABLE_XXX參數增加硬體推論能力(XXX分別對應Intel GPU, Neural Compute Stick 2 單顆VPU, 多顆Movidius VPUs)
./start_workbench.sh -IMAGE_NAME openvino/workbench -TAG latest [-ENABLE_GPU] [-ENABLE_MYRIAD] [-ENABLE_HDDL]
啟動後,會出現Login token(一長串數字可先複製起來備用)及一個本地端網址(http://127.0.0.1:5665/?token=xxxxxx),接著將滑鼠移至網址處按下左鍵,點選開啟連結(Open Link),或者直接複製這一長串網址貼到瀏覽器上,即可進入DL Workbench網頁式操作畫面,如Fig. 2步驟4所示。若想結束DL Workbench,除了關閉網頁外,還要回到終端機畫面按下 [Ctrl + C] 回到普通命令列狀態。
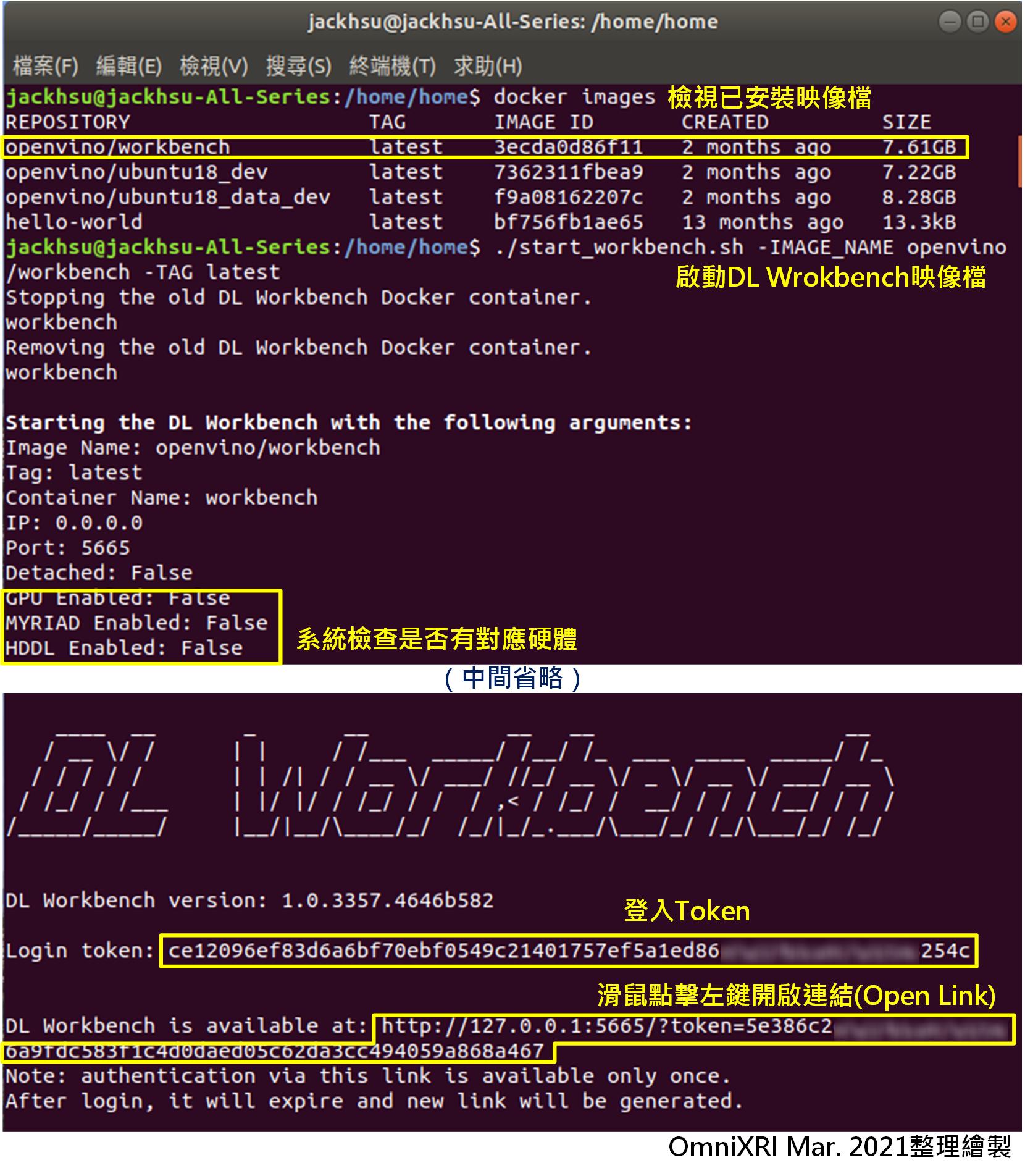
Fig. 1 終端機命令列成功啟動DL Workbench畫面。(OmniXRI Mar. 2021整理製作)
下次若想快速啟動DL Workbench時,可不用執行上面一大串動作,直接開啟網頁,輸入網址 http://127.0.0.1:5665 ,畫面會出現要求輸入Login Token,此時再將剛才的token貼上,按下 [Start] 便可直接啟動。最後按下網頁左上角 [Create] 創建新的工作組態就可以開始測試了,如Fig. 2所示。

Fig. 2快速啟動DL Workbench網頁操作步驟畫面。(OmniXRI Mar. 2021整理製作)
DL Workbench工作流程
在開始實際操作前,先大致說明一下整個DL Workbench的工作流程,方便後面理解後面實際操作項目,如Fig. 3所示。
1.安裝(Install)
前面已介紹除可直接一步一步安裝在電腦上,亦可支援使用Docker映像檔方式安裝DL Workbench。另外OpenVINO也支援以Dev-Could方式安裝,方便沒有採購硬體的人,先利用Intel提供的雲端測試平台來選用合適的硬體。
2.模型(Model)
如果自己不會設計AI模型的人可透過OpenVINO內建的模型下載器(Model Downloader)選用Intel已預訓練好參數的模型(Pre-Trained Open Model Zoo),或者使用公開模型(Public)。當然也可支援自己開發並訓練好的模型。不過這裡只支援Caffe, MXNet, ONNX, TensorFlow和PyTorch格式的模型轉換,最後會都轉換成OpenVINO支援的中間表示(Intermediate Representation, IR)格式模型網路描述及權重檔案(*.xml, *.bin)。
3.準備模型(Prepare Model)
由於導入的模型有可能過大,因此可透過OpenVINO內建的優化工具(Optimizer)協助處理網路架構調整以減少計算量。另外一般訓練好的模型參數(網路權重)多半都是使用32位元浮點數(FP32)來表示,為達到更高推論效能,這裡亦可協助校正(Calibration),將32位元浮點數(FP32)轉換到16位元浮點數(FP16),甚至是8位元整數(INT8)。雖然在不同場景下可能會損失幾個百分點的推論精度,但好處是參數所需記憶體可縮至1/2到1/4間,而運算速度則可增加2到3倍。
4.資料集(Dataset)
為了測試選用的模型,這裡可以導入(Import)自行準備符合常見的公開資料集(如ImageNet, Pascal VOC, MS COCO等)格式的資料集。或者使用生成(Generate)高斯雜訊變相產生小型資料集來輔助簡易性測試,但請注意這種方式僅適用影像分類模型測試,且因不含標註資料,所以不適用精確度測量及校準工作。若手上沒有現成資料集可用的人,亦可參考官網[3]說明,下載常見的ImageNet, Pascal VOC, Microsoft COCO等公開資料集。
5.建立基準(Benchmark)
準備好模型、資料集及選用欲執行的硬體環境後,便可根據平行流(Parallel Streams)及批次數量(Batch Size)設定值開始進行推論並建立一個基準點(如 4a),其內容包含產出速度(Throughout, Frame Per Second, FPS)、延遲(Latency, ms)。若不滿意推論結果,則可重新調整上述參數,建立多個基準點,方便後續比較何種組合會有較好效能。
6.分析(Analyze)
為了更容易理解模型每個環節的工作負擔,這裡提供了很多可視化表格及圖形來幫助理解,包含模型主要執行耗時分佈(Execution Time by Layer)圓餅圖(如 4b)、每一層(Layers)的結構、名稱、推論耗時、輸出精確度(如Fig. 4c),模型整體網路節點連接關係圖,模型優化前後(IR及nGraph)的網路結構(如Fig. 4d),另外還會搭配顏色表示各節點耗時,方便後續模型建立者調整結構及更進一步參數。
7.佈署(Deploy)
待反覆步驟5和6找到最佳效能點後,便可打包佈署到實際硬體上執行,如此就能不用寫半行程式就能輕鬆完成模型分析、優化、佈署工作。不過要注意的是這項功能目前僅提供Ubuntu(Linux)使用。
若想更完整了解以上說明步驟,亦可參考官方提供的基礎教學影片[4]及進階教學影片[5]。

Fig. 3 DL Workbench工作流程圖。(OmniXRI Mar. 2021整理製作)
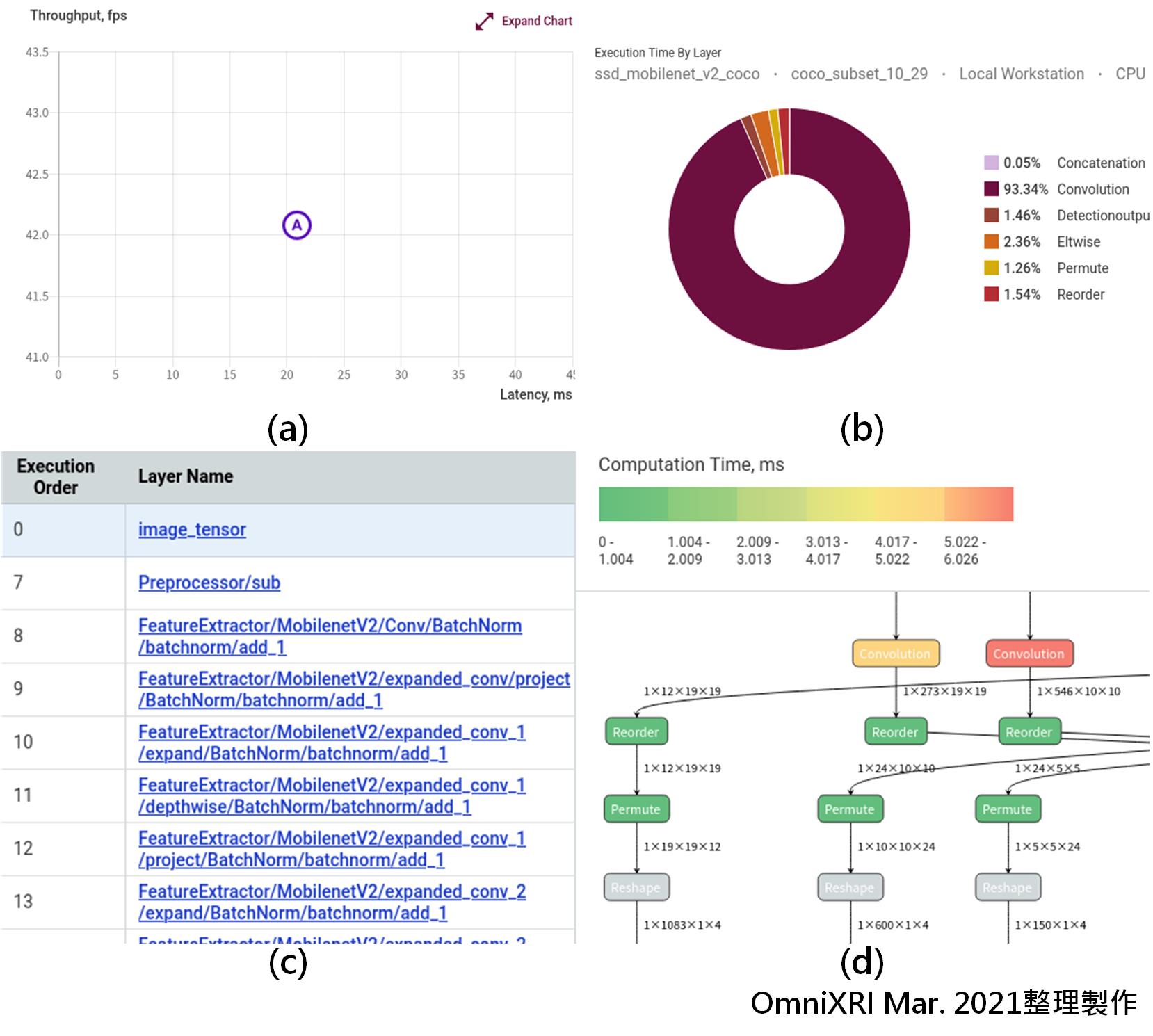
Fig. 4 DL Workbench可視化工具,(a)輸出速度/延遲時間基準點圖,(b)各層執行時間圓餅圖,(c)各層資訊表,(d)網路結構圖及耗時表示。(OmniXRI Mar. 2021整理製作)
實際案例操作:SSD物件偵測
接下來就用一個實際的例子來說明如何操作DL Workbench。
1.資料集預處理
如果手上沒有現成的資料集可供測試,可以參考官網[6]的說明下載需要的公開資料集及標註檔(Annotations)。這裡以COCO 2014資料集舉例說明。點選網頁[6]上Download COCO Dataset下的[2014 Val images](約6.2G Byte)和[2014 Train/Val annotations](約241M Byte)下載影像集(val2014.zip)和標註檔(annotations_trainval2014.zip)。
接著建立一個資料夾(/home/<使用者名稱>/Work)來存放這兩個檔案。再來以點選網頁[6] Cut COCO Dataset下的 the script to cut datasets另存新檔到剛才建立的資料夾中。最後執行資料集減量(cut)的動作,只保留少部份檔案,方便DL Workbench導入(import)測試,完成後會自動產生新的壓縮檔並存放在/home/<使用名稱>/Work/subsets/coco_subset_10_29.tar.gz。完整執行命令如下所示。
#再執行cut_dataset.py,依指定路徑(*_dir)取得原始檔案,設定指定數量(output_size)的影像,最後輸出到output_archive_dir路徑下。
#這裡的python是指3.x不是2.x,若電腦中同時有兩種版本請改用python3
python /home//Work/cut_dataset.py \
--source_images_archive_dir=/home//Work/val2014.zip \
--source_annotations_archive_dir=/home//Work/annotations_trainval2014.zip \
--output_size=20 \
--output_archive_dir=/home//Work/subsets \
--dataset_type=coco \
--first_image=10
若想自行準備資料集的朋友可參考官網[7],其中Common Objects in Context (COCO)就有說明COCO檔案安排格式,如Fig. 5所示。

Fig.5 DL Workbench自備COCO資料集格式,(a)一般分類/物件偵測,(b)影像語義分割,(c)超解析度。(OmniXRI Mar. 2021整理製作)
2.導入模型及轉換參數精度
為了方便後續同時測試CPU及Neural Compute Stick 2 (MYRIAD),可使用下列命令啟動DL Workbench。
不過這裡經實測後發現,如果你的電腦上沒裝過標準版的Distribution of OpenVINO toolkit for Linux[8],而只有安裝Linux Docker環境時,將無法使用iGPU和NCS2(MYRIAD)。若使用Windows Docker環境(Windows 10 + Widnows Subsystem for Linux 2 [WSL2] + Ubuntu 18.04)時則只能使用CPU,因為目前微軟在WSL2上GPU和USB驅動程式支援性仍不完整。
接著就可以進到DL Workbench網頁式操作畫面,開始設置工作組態(Active Configurations)。這裡需要設定四個項目,包括模型(Models)、目標(Target)、環境(Environment)及資料集(Dataset)。使用前要確定網路是暢通的,因為接下來的工作會需要從網路上下載許多資料。
首先按下[Create]鍵創建一組新的組態,導入(Import)現成的公開模型及預訓練好的模型,由於線上預訓練好的模型項目太多,可以直接輸入模型名稱快速檢索出想要的模型。由於這個範例要測試物件偵測功能,所以選用「ssd_mobilenet_v2_coco」,再來選擇模型的參數精度(FP16/FP32)進行轉換(Convert),完成後就會在模型區出現模型名稱、產生日期、參數精度、模型大小,狀態欄會顯示是否還在傳輸中,完成後會產生一個綠色的勾勾。完整流程如Fig. 6所示。
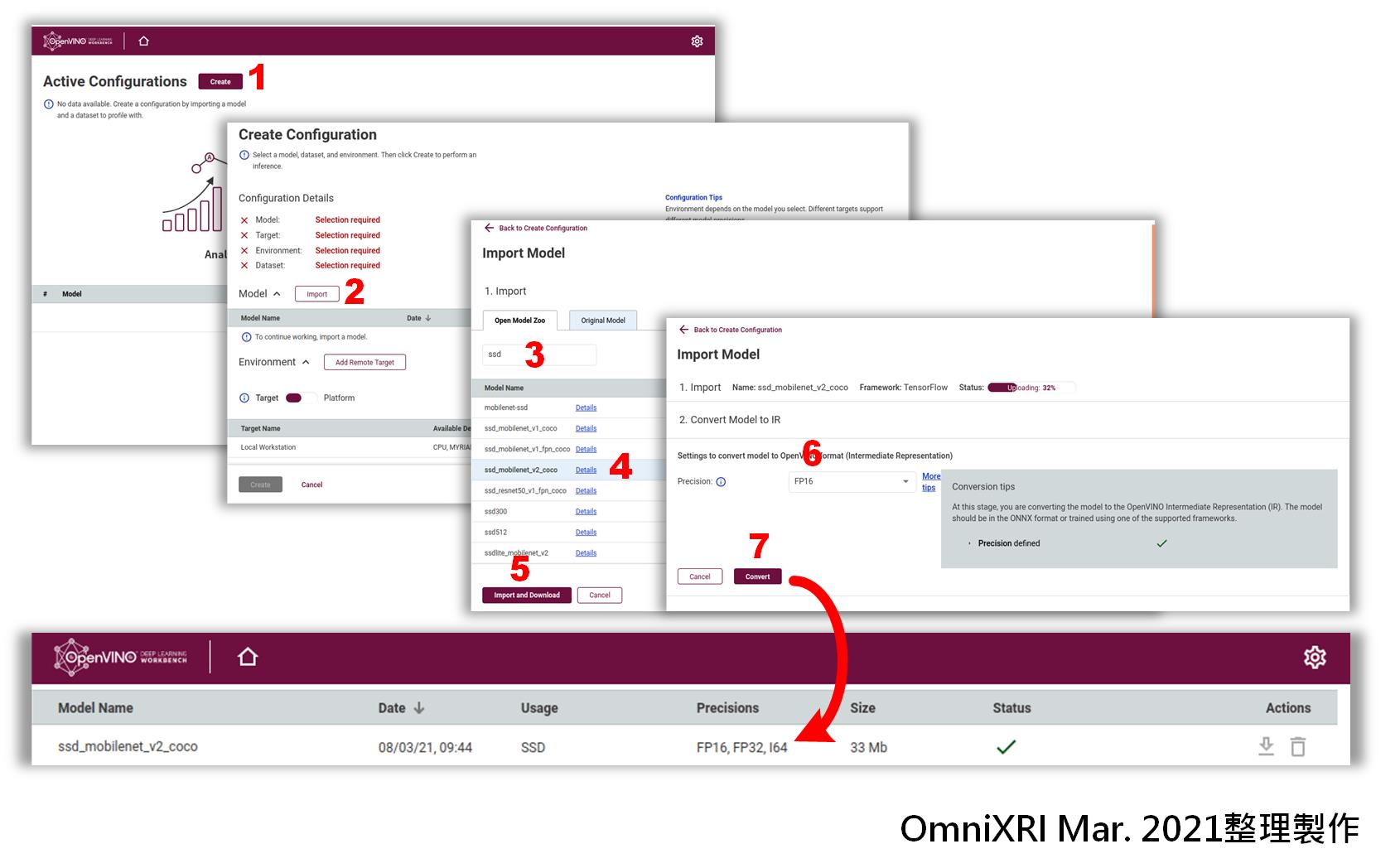
Fig. 6 設定DL Workbench推論模型流程。(OmniXRI Feb. 2021整理製作)
若不想使用現成的模型,亦可切換到原始模型(Original Model)頁面,依系統要求自行提供對應格式的模型(網路)及參數(權重值),再按[Import Model]即可導入自定義模型。目前可支援OpenVINO IR, Caffe, MXNet, ONNX, TensorFlow等格式。
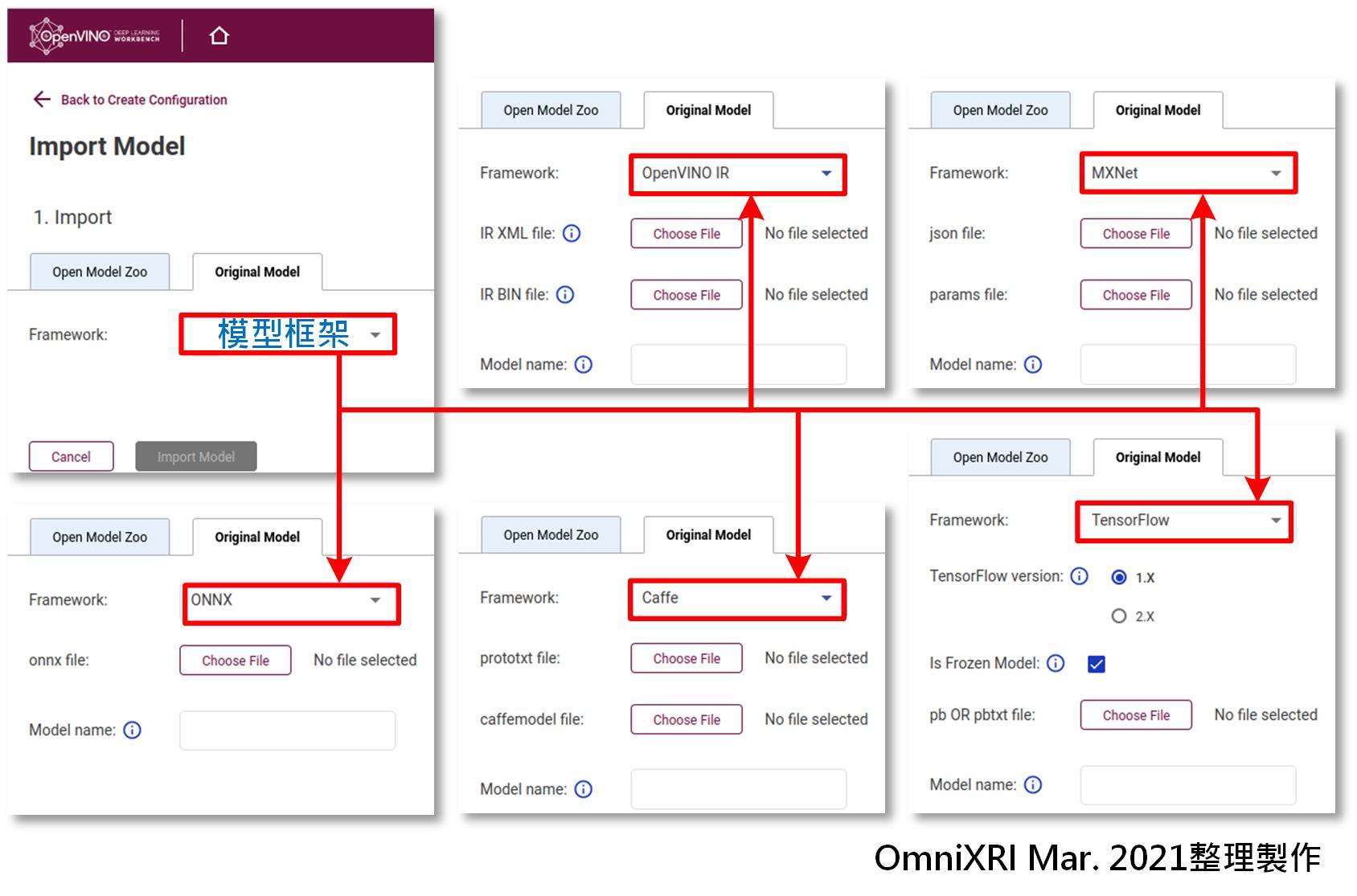
Fig. 7 DL Workbench導入自定義模型。(OmniXRI Mar. 2021整理製作)
3.導入資料集
點選Validation Dataset旁的[Import]鍵,進入導入驗證資料集頁面,按[Choose File]鍵,選擇歩驟1產生的coco_subset_10_29.tar.gz,按下[Import],即可完成導入資料集。如Fig. 8所示。
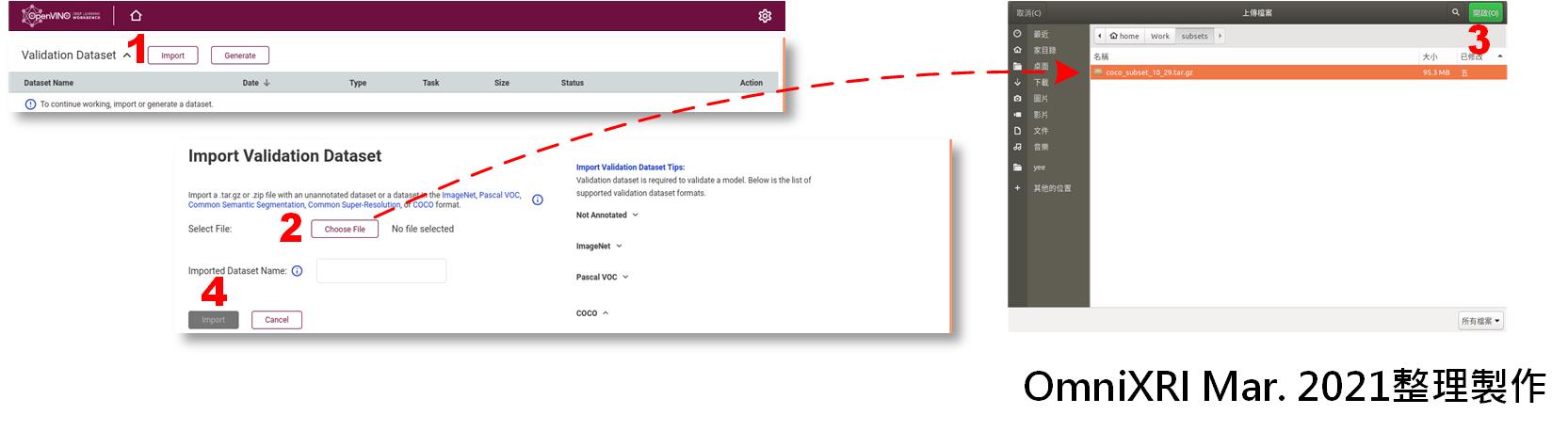
Fig. 8 DL Workbench導入資料集。(OmniXRI Mar. 2021整理製作)
4.設置目標/環境
這裡可看到目前有CPU和MYRIAD (NCS2)兩種裝置可供選擇,可先選擇其中一種(CPU),點選模型和資料集後即可按下頁面最下方的[Create]建立第一種組態。如Fig. 9所示。這裡要注意的是,若模型及資料集未備妥前(尚在傳輸或轉換中)是無法設置目標及環境。
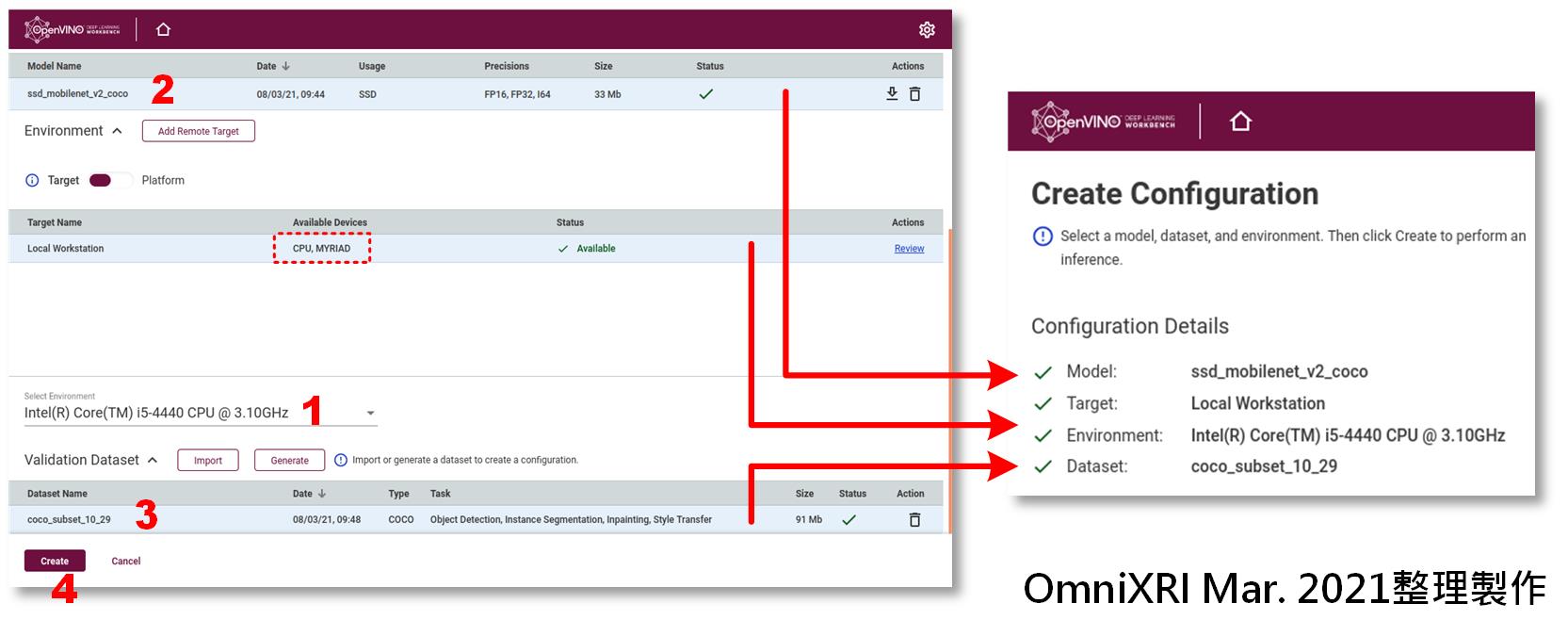
Fig. 9 DL Workbench設置目標環境並建立組態。(OmniXRI Mar. 2021整理製作)
5.建立基準點
按下[Create]建立第一組組態後,就會進入組態頁面,並進行第一次推論,自動產生第一個基準點。推論時會視執行硬體不同需要等待一小段時間,完成後會得到最佳的輸出速度(Best Throughout, FPS)、延遲時間(Respective Latency, ms)及推論精確度(Accuracy),並於效能綜合圖表上繪出一點參考點。
通常預設為單獨推論(Single Inference),使用者可自由定義欲測試的平行流(Parallel Infers)及批次量(Batch Size),再按下[Execute]鍵來測試不同條件的推論效能。若嫌一直手動調整太麻煩,亦可使用群體推論(Group Inference),直接點選欲測試的組合,按下[Execute]鍵就泡杯咖啡慢慢等結果出來。從產出的圖表就可一眼看出何種組合的效能最好,做為後續打包輸出的依據,如Fig. 10所示。
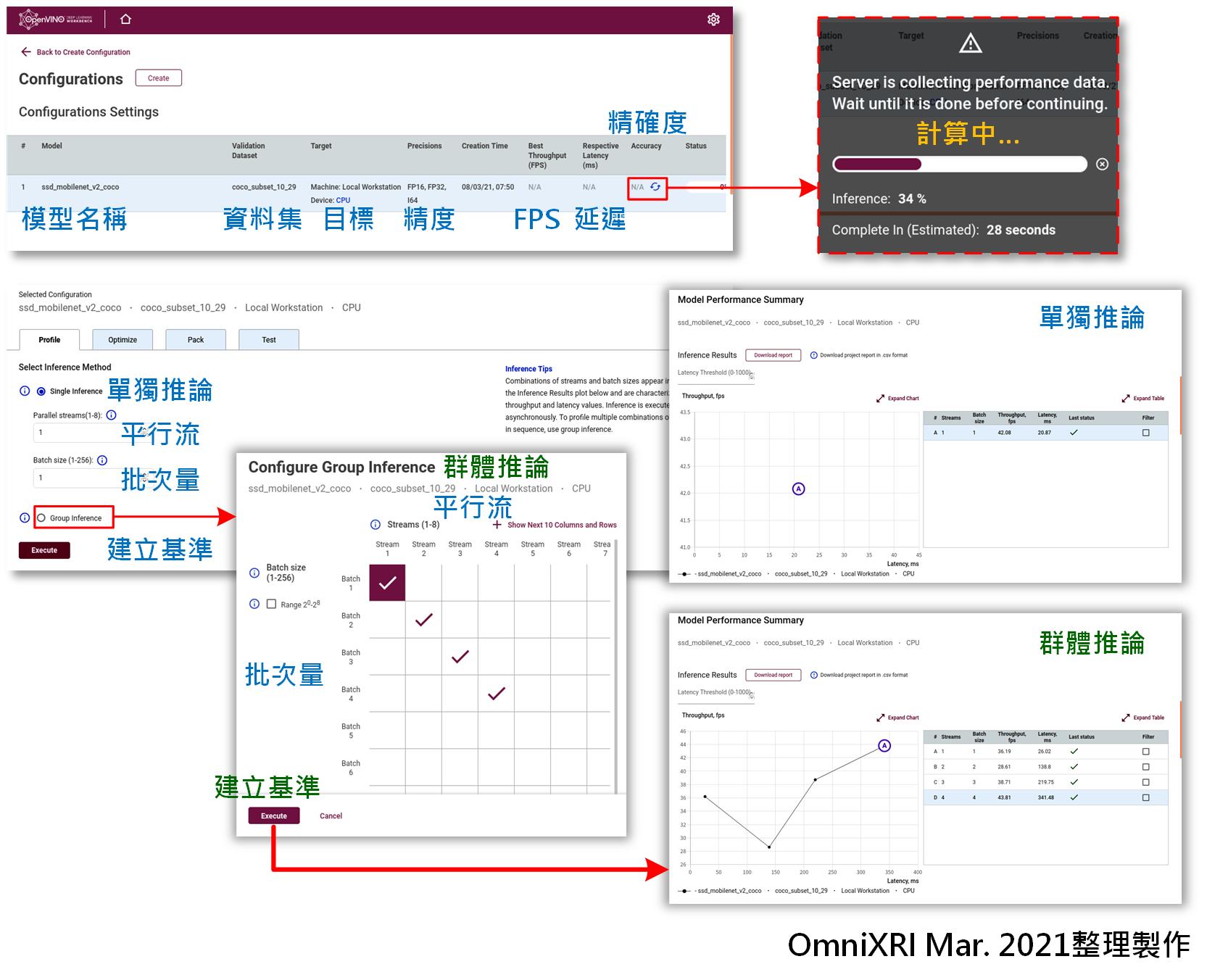
Fig. 10 DL Workbench建立基準點及結果圖。(OmniXRI Mar. 2021整理製作)
6.基準點效能比較
測試效能除了可以使用單獨或群體測試外,亦可進行多種硬體的推論效能比較。首先點選頁面上方的[Create]重新回到步驟4,此時只需改選裝置為[Intel Movidius Myriad X VPU] (NCS2),其它模型和資料集不變,移到頁面最下方按下[Create]鍵就能新增一組組態,再次進到步驟5。此時可參考步驟5,將所有動作重複一遍,產出相同參數結果方便進行比較。
接著按下[Compare]就能進入比較頁面進行兩組組態的測試結果比較,若有兩組以上組態則一次只能勾選兩組進行比較。這裡除了基本效能圖表外,另有平均延遲時間、各層執行時間及更多圖表資訊,可依需求自行參考,如Fig. 11所示。
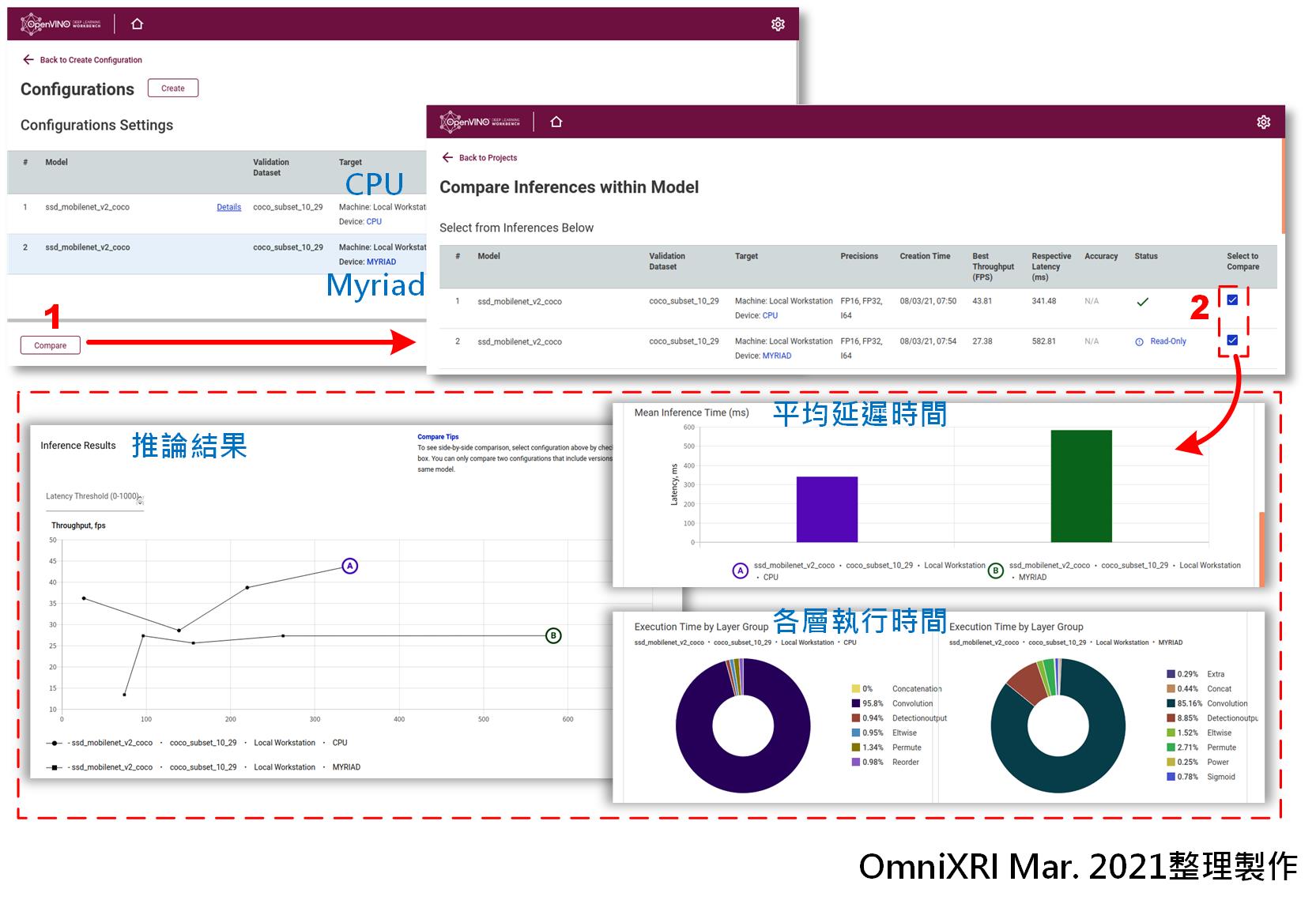
Fig. 11 DL Workbench多組態基準點效能比較。(OmniXRI Mar. 2021整理製作)
7.上傳影像測試
經過上面一連串設定及找到最優配套後就可以來測試一下模型推論能力,這裡支援直接上傳單張測試影像來實驗。首先切換到[Test]頁面,按下[Select Images]上傳待測試的影像,或者直接把影像拉到這個框裡面。接著按下[Test]進行測試,預測(Predicitions)結果就會出現在右方。顯示結果內容包括一組可調的臨界值(Threshold)和高於臨界的物件,同時會顯示物件的分類編號(Class ID #)和置信度(Confidence)。點選物件編號時,左側亦會繪製出對應的內容。若覺得偵測出的物件太少,可將臨界值調低,再確認一下。
另外目前COCO偵測結果只有用數字編號(Class #00)表示,並沒有直接標籤(Label)文字標示,不容易直接確認結果。如果想更確認編號對應內容,可參考[9]說明。一般COCO有91分類和80分類(從91類刪除部份),而現在對應的是91分類的標籤。
接著就用幾張圖來實驗一下結果,第一組貓和狗,一張物件重疊(Ex. 1-1)、一張物件分開(Ex. 1-2)。第二組蘋果和香蕉,一張物件重疊(Ex. 2-1)、一張物件分開(Ex. 2-2)。初步實驗結果可看出SSD_MobileNet_v2_COCO這組預練訓模型對於重疊的物件似乎分辨能力較弱些,而較大較分開的物件則辨識能力尚可接受。不過這樣的實驗數據太少,所以結論可能不完全正確,僅供參考。測試內容如Fig. 12所示,而測試結果如Fig. 13~16所示。
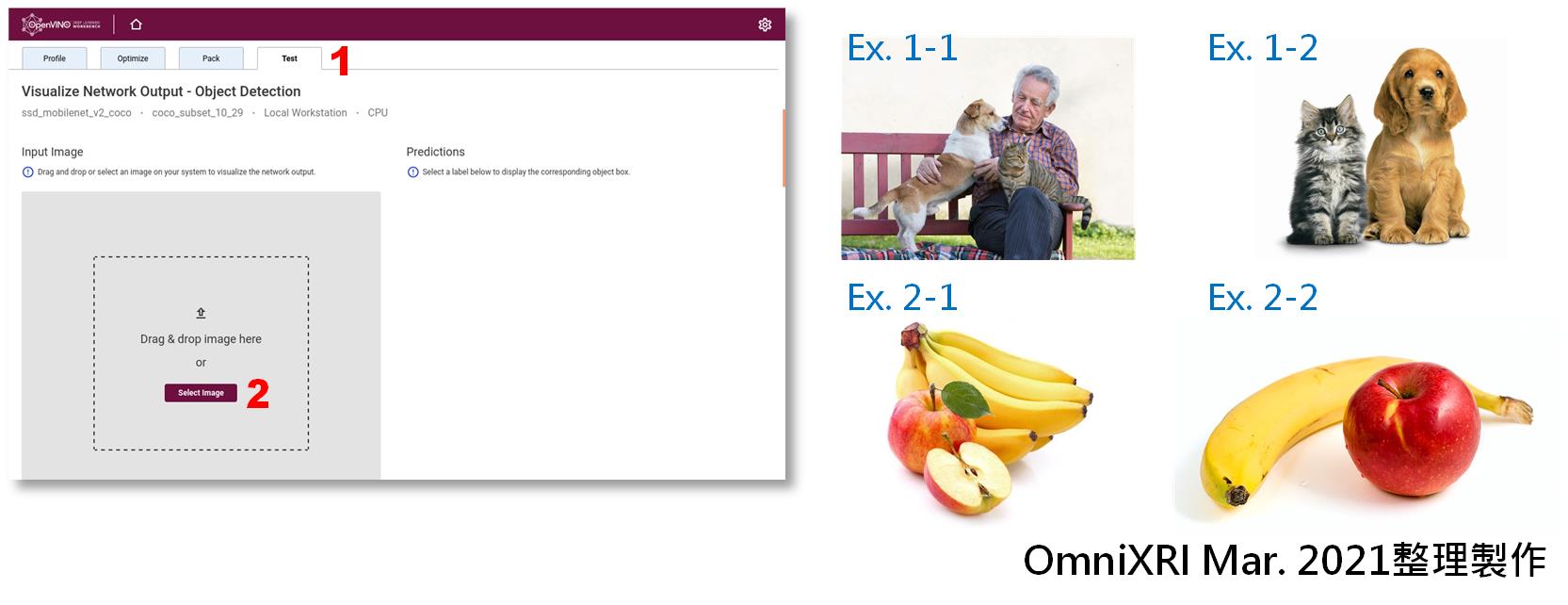
Fig. 12 DL Workbench進行物件偵測流程及測試樣本影像。(OmniXRI Mar. 2021整理製作)

Fig. 13 Ex. 1-1物件偵測實驗結果。(OmniXRI Mar. 2021整理製作)

Fig. 14 Ex. 1-2物件偵測實驗結果。(OmniXRI Mar. 2021整理製作)

Fig. 15 Ex. 2-1物件偵測實驗結果。(OmniXRI Mar. 2021整理製作)

Fig. 16 Ex. 2-2物件偵測實驗結果。(OmniXRI Mar. 2021整理製作)
8.打包輸出
為了後續可更方便佈署到對應目標工作環境及讓程式設計師能直接編寫及呼叫對應函式,這裡亦提供打包輸出,不過目前只支援Linux。打包內容包含所選擇執行目標(硬體)相關函式、模組、Python API及安裝腳本。首先切換到[Pack]頁面,勾選所需項目,再按下[Pack]就會開始打包成一個壓縮檔(*.tar.gz)並詢問欲存放的路徑,如此即完成所有程序。如Fig. 17所示。
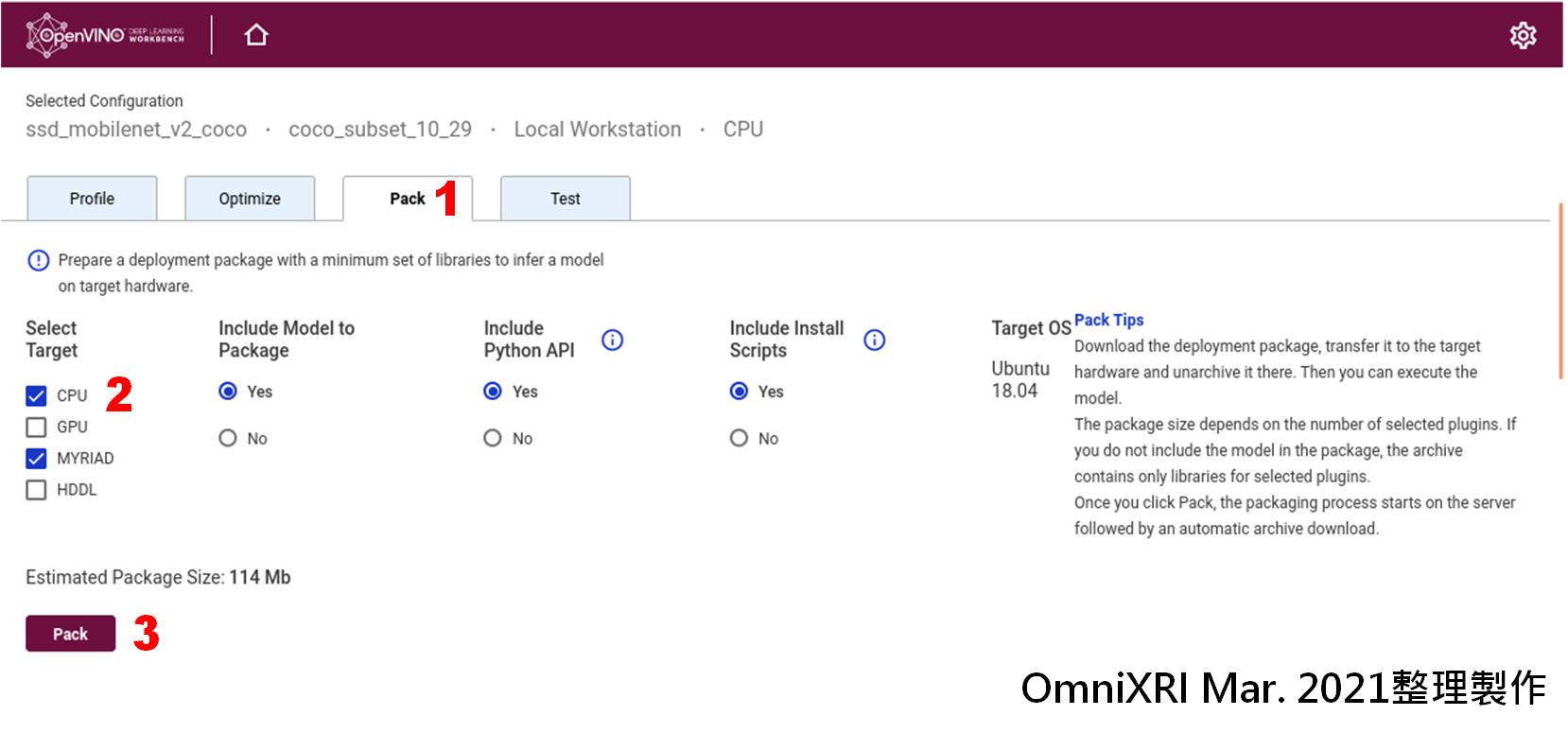
Fig. 17 DL Workbench打包選項及程序。(OmniXRI Mar. 2021整理製作)
小結
透過以上的說明及實例操作,相信大家應該對Intel OpenVINO Toolkit中的DL Workbench有了一些初步的認識,圖形化的介面更是讓使用者可以輕鬆上手,一目瞭然。對於那些不會或不想寫程式就想要快速實驗想法的人及需要耗費大量心力調參的工程師來說,這項工具確實縮短了開發及測試時間。後續還有更多優化及提升推論效能的工作,就留待下回分解,敬請期待。
參考文獻
[1] 許哲豪,”【Intel OpenVINO教學】如何利用Docker快速建置OpenVINO開發環境”
[2] Intel OpenVINO Toolkit, “Install the DL Workbench”
[3] Intel OpenVINO Toolkit, “Download and Cut Datasets”
[4] Intel, “DL (Deep Learning) Workbench | OpenVINO™ toolkit | Ep. 42 | Intel Software”
[5] Intel, “DL (Deep Learning) Workbench – The Full Flow | OpenVINO™ toolkit | Ep. 43 | Intel Software”
[6] Intel OpenVINO Toolkit, “Download and Cut Datasets”
[7] Intel OpenVINO Toolkit, “Dataset Types”
[8] Intel OpenVINO Toolkit, “Install Intel® Distribution of OpenVINO™ toolkit for Linux*”
[9] Amikelive Technology Blog, “What Object Categories / Labels Are In COCO Dataset?”
延伸閱讀
[A] 許哲豪,”串流影片分析慢吞吞?看OpenVINO™ DL Streamer如何加速效率”
(責任編輯:林亮潔)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2021/03/15
這個好玩!如果Keras也有GUI可以用在開發階段上,那就太讚了!