作者:Judith Cheng
如何以高效率在各種裝置上部署人工智慧(AI)功能,是許多系統開發者在近年來面臨的一大課題;有鑑於終端應用的五花八門,對於開發工具是否具備支援多樣化模型的彈性與可擴充性,也成為需求重點。在2018年由處理器大廠英特爾(Intel)推出的開放源碼工具套件OpenVINO,就是能讓使用者輕鬆克服AI推論應用開發挑戰的解決方案,而且它不斷與時俱進,隨著ChatGPT、Midjourney、Stable Diffusion等應用程式在2023年爆紅,它的最新版本也提供了對生成式AI模型的支援。
為了讓廣大OpenVINO社群的老朋友充分了解最新2023.0版本增添了哪些強大功能,同時讓更多新朋友認識該工具套件可提供的優勢,英特爾日前與MakerPRO攜手舉辦了2023年首場DevCon系列線上講座,除了邀請重量級講者──包括英特爾院士暨OpenVINO架構師Yury Gorbachev、英特爾AI傳教士全球負責人盧振興(Raymond Lo)博士與英特爾平台研發協理王宗業──與線上近300位聽眾分享過去五年來OpenVINO團隊持續推動技術進展以及擁抱開源的理念,還有技術專家──英特爾OpenVINO AI 軟體傳教士武卓博士、AI軟體工程師楊亦誠,透過詳細的講解內容以及現場示範,介紹2023.0版本OpenVINO的技術亮點,還有如何利用該工具套件加速部署當前最夯的生成式AI模型,實現高性能推論應用。
打通AI部署的「最後一哩」
王宗業在DevCon開場回顧OpenVINO的成長歷程時表示,該工具平台的開發一開始是為了將日臻成熟的TensorFlow、ONNX等深度學習框架模型與現有機器視覺演算法結合,在以CPU/GPU為核心的裝置上執行,導入像是自駕車、工廠自動化機械手臂等網路邊緣應用,而且該工具平台能支援C++/Python等大多數開發者熟悉的程式語言,容易上手的模型量化/最佳化流程更是大幅降低了使用門檻;從最初的50種模型,到現在對超過300種、包括最新生成式AI模型的支援,五歲的OpenVINO已經成為廣受各界歡迎,實現無數創新應用的AI開發工具,迄今累積超過百萬次下載量。
而王宗業也強調,OpenVINO能有如此迅速的技術進展與亮眼成績,關鍵原因就在於它是以開放源碼的形式誕生,透明化的營運模式能更親近全球開發者社群,迅速獲得來自社群的回饋與貢獻以持續改善、進步,並深入各大學與研究所、甚至高中校園向下紮根,在AI已無所不在的時代讓更多人能輕鬆運用科技實現腦海中的創意,為產業提升生產力與效率的,為日常生活提供安全與便利。在OpenVINO開發團隊扮演要角的Yury以及致力於全球推廣該AI開發解決方案的Raymond也在隨後的對談影片中,重申開放源碼為OpenVINO帶來的價值,除了讓團隊擁有更多的彈性,也確實看到了社群推動技術進展的貢獻。
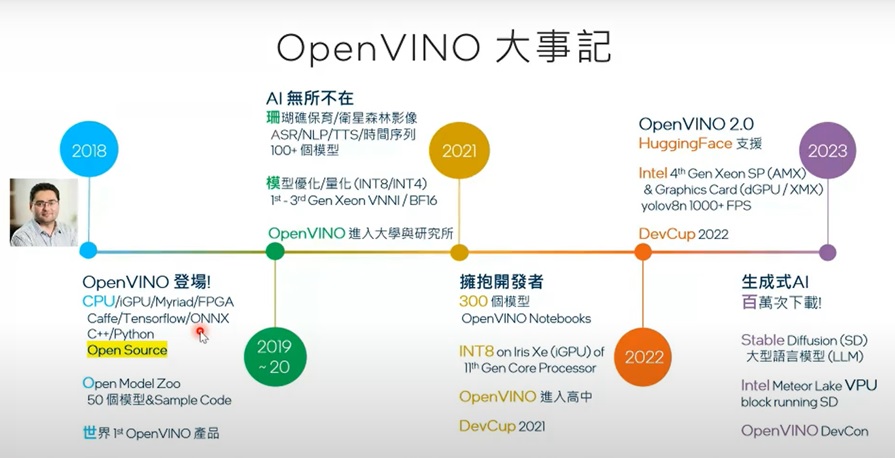
OpenVINO大事記。(圖片來源:英特爾)
Yury也特別提及幾個OpenVINO 2023.0具影響力的重要新功能,其一是對GPU動態形狀(dynamic shapes)的支援,這意味著使用者可以在整合或離散GPU上執行大型語言模型以及各種Hugging Face模型。此外新版本也添加了對Arm處理器的支援,還有在單一NNCF神經網路壓縮框架中整合了包括訓練後量化、訓練時間、模型最佳化等所有功能,並且可以透過Python API來轉換模型,無論是PyTorch、TensorFlow或熱門的TensorFlow Lite模型都能直接饋入,進一步簡化工作流程。
讓AI開發變得更簡單!
一言以蔽之,2023.0版本OpenVINO的終極目標就是讓開發者「更容易進行AI部署和加速」;在接下來的演說中,武卓與楊亦誠從四個主軸──更簡單的工作流程、出色的可移植性與性能、更多的深度學習模型、簡便的安裝──詳細講解其中的技術亮點。
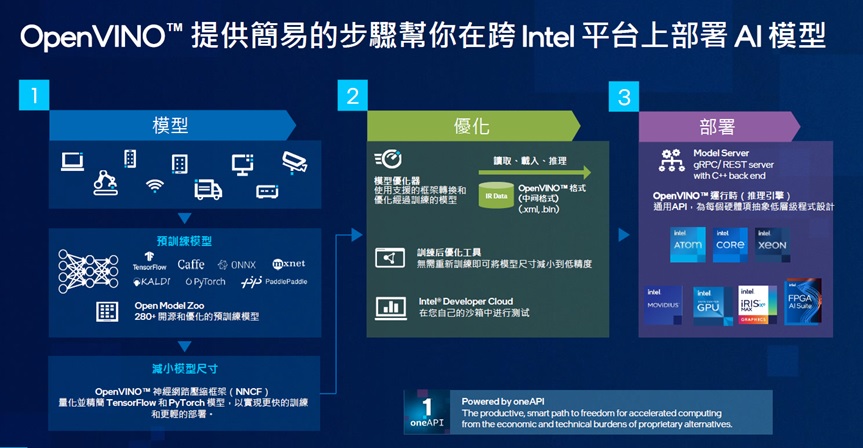
OpenVINO要讓AI開發變得更簡單。(圖片來源:英特爾)
在簡化工作流程部分,新版本讓開發人員無需離線將TensorFlow或TensorFlow Lite格式模型檔轉換為OpenVINO IR格式,檔案會在執行時自動轉換,以更容易地從模型訓練轉移到模型部署;其次,原本OpenVINO有單獨的工具用於訓練後量化(POT)和量化感知訓練,新版本將這兩種方法合併到NNCF中,有助於減少模型大小、記憶體佔用面積和延遲,並提高運算效率。此外,新版本OpenVINO將各種裝置上的推論性能預設以高性能模式運作,以往使用者必須自己將IR轉換為FP16,才能使GPU在FP16模式下執行,現在所有裝置都可以自動選擇預設推論精度。
如前面Yury提及,新版本OpenVINO增加了對GPU的動態形狀支援──在使用GPU時,不需要將模型改為靜態形狀,這為編寫程式碼時提供了更多的靈活性,特別是NLP模型,也提升了工具的可移植性與性能。新版本的模型快取(model caching)也有所改善,能減少GPU和CPU的首次推論延遲;此外新版本亦支援CPU外掛程式的執行緒調度(thread scheduling),能藉由在Intel第12代CORE及以上版本的CPU的效率核心(E-cores)、性能核心(P-cores)或兩者一起執行推論來最佳化性能或功耗。
在新版OpenVINO,AI開發者還可以找到更多對生成式AI模型的更多支援,包括BLIP、Stable Diffusion 2.0,以及對文本處理模型的支援、對Transformer模型的支援,例如S-BERT、GPT-J等,還有對Detectron2、Paddle Slim、Segment Anything Model (SAM)、YOLOv8、RNN-T等模型的支援,而開放源碼的OpenVINO除了下載容易,也擁有強大的社群資源提供各種應用範例。
無痛部署生成式AI高性能推論
當紅的生成式AI正在各個產業領域受到矚目,透過以高靈活性大規模生成並運作數據,該技術無論在遊戲、設計或電子商務等領域,預期都將有無窮發展空間;市場研究估計,生成式AI市場將在接下來10年以42%的年複合成長率持續擴張,在2032年達到1.3兆美元的規模。不過生成式AI的部署並非簡單任務,如武卓與楊亦誠所言,生成式AI因為模型尺寸大、佔用的記憶體空間也較大,再加上推論速度較慢、模型最佳化難度高,無法在不同的硬體上靈活執行工作負載。

生成式AI具備無限應用潛力。(圖片來源:英特爾)
針對生成式AI的部署痛點,OpenVINO也能提供讓開發流程變得更簡單的解決方案,讓模型尺寸縮小、減少記憶體佔用空間,同時加快推論速度、策略性最佳化模型,使工作負載得以靈活在各種CPU與GPU上執行。武卓與楊亦誠除了在DevCon現場展示以OpenVINO執行Stable Diffusion模型,並與線上近300位聽眾在問答時間熱烈互動,亦預告將在下一場預定於9月5日舉行的DevCon系列講座,與開發者分享深度量化技術的最新趨勢,並示範零售業智慧排隊管理系統(Samrt Queue)的應用部署實作,有興趣的開發者千萬別錯過!
課程回顧:
【OpenVINO™ DevCon#1】聚焦新版OpenVINO™ 2023.0 與生成式AI模型
參考閱讀:
- 最新版OpenVINO 2023.0問世:更輕鬆部署、加速AI應用!
- 利用OpenVINO部署HuggingFace預訓練模型的方法與技巧
- 不用買顯卡 OpenVINO 也能玩 Stable Diffusion V2!
- AI分割一切:用OpenVINO加速Meta SAM大模型
- 更多OpenVINO專欄文章

- RISC-V躍居AI推論時代運算主流 台灣供應鏈迎接「開放」新契機 - 2026/06/18
- 量子運算加速邁進可用階段 英飛凌分享技術布局策略 - 2026/06/17
- 【COMPUTEX 2026】Edge AI走向現實生活 Alif展示多元低功耗應用 - 2026/06/11
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


