作者:Ted Lee
![]()
會安老師在他的 Thunkable 系列的最後一個投影片「10_Thunkable跨平台行動開發(專案實例).pdf」中,舉出了如圖表 1 的四個呼叫網路服務(web service)的簡易示例:
- Web API 與 JSON 資料剖析:Thunkable 向儲存在 Github 上的 fChart 專案要回了 json.html 網頁中 JSON(JavaScript Object Notation)格式的圖書資料。
- Google 圖書資訊查詢:Thunkable 透過呼叫 Google APIs 來查詢 Google Books 內的 Python 圖書。
- Translator 線上翻譯:Thunkable 透過呼叫 Yandex APIs 來英翻中的結果(Thunkable 的官方解說文件可參考 此處)。
- AI 影像識別:Thunkable 透過呼叫 Microsoft Azure APIs 來辨識物件(Thunkable 的官方解說文件可參考 此處)。

表 1:「10_Thunkable跨平台行動開發(專案實例).pdf」中的四個網路服務串接示例
其中,這四例都是以 Thunkable 的 Snap to Place 舊介面(在圖 1 中取消下方淺紫色色塊右方的核取方塊(checkbox))來實作的。
圖 1:Thunkable 的 Snap to Place 舊介面
接下來,我們將詳細說明以上第四例的設計過程。
題目說明
在手機上,按下 app 畫面上的「照相」按鈕來拍攝物件照片。接著,再按下「識別」按鈕顯示物件辨識後的結果。例如:拍攝手錶照片上傳後,會辨識出「thing,object,indoor,clock,sitting,old,table,dirty/a clock on the wall(東西、物件、室內、時鐘、坐、舊、桌子、髒/牆上的時鐘)」,如本文一開頭的照片所示。App 的完整流程如圖 2 所示。
註:如果讀者對辨識的結果不滿意,可以多換幾個角度拍照試試看。
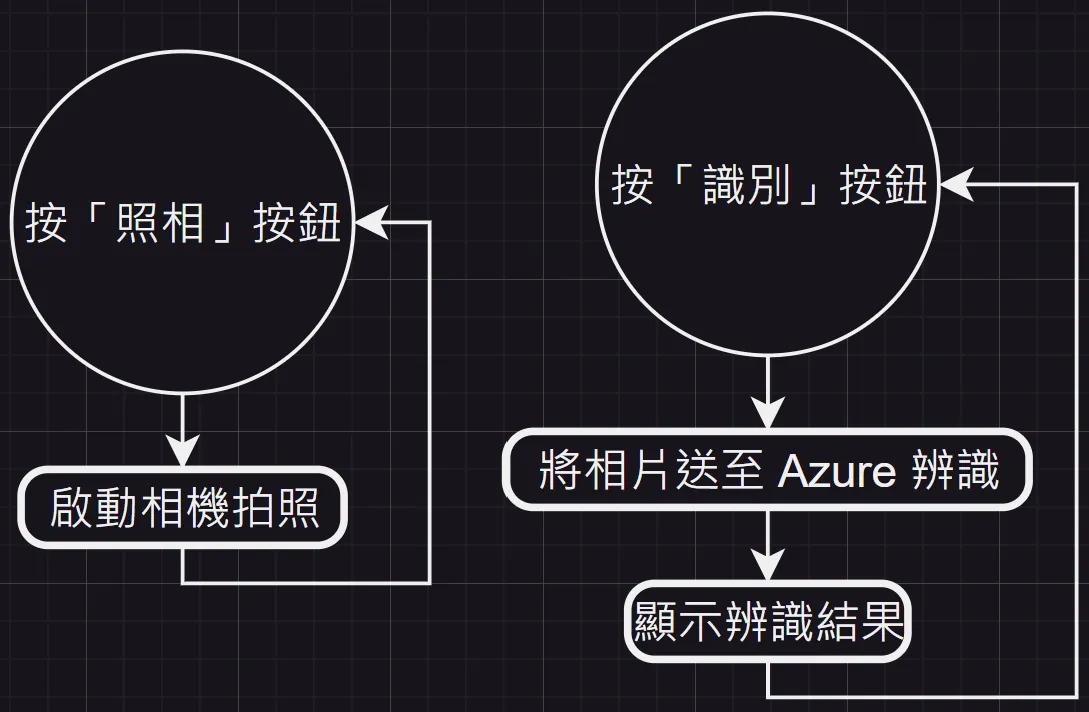
圖 2:處理流程
畫面設計
首先,我們將 app 命名為「scrAI 影像識別」。再根據圖 3 的版面安排,我們以列(Row) rowUP 的佈局方式(layout)由左至右來放置二個按鈕 btnCapture 和 btnRecognize。接著,再排列文字標籤 lblInstruction 與影像 imgPhoto 元件。最後,我們再加入相機 Camera 和影像識別 Image_Recognizer 影像識別兩個隱藏元件(invisible component)。
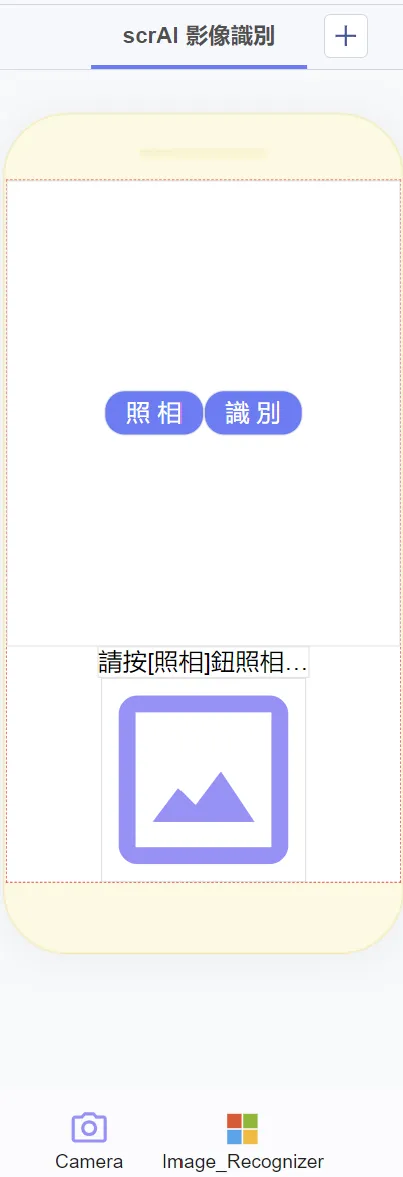
圖 3:App 的畫面設計
本 app 上使用到的所有元件類型、命名及其屬性皆詳列於圖 4 和圖 5。
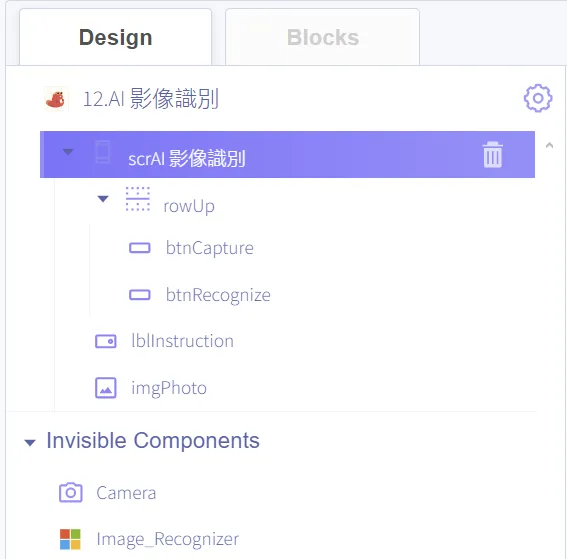
圖 4:App 內使用的所有元件
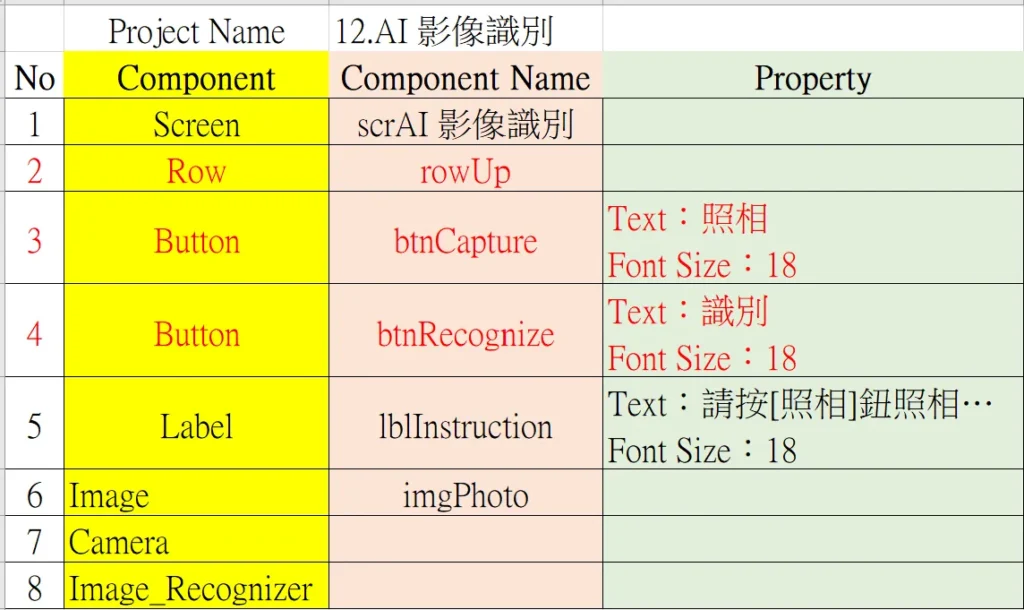
表 2:App 內所有元件名稱及其對應的屬性表列
程式設計
本 app 的使用流程為:先按下 app 畫面上的「照相」按鈕拍照(呼叫拍照的 call…with outputs…then do… 紫色積木)。然後,再按「識別」按鈕即可得到上一個步驟所拍攝照片的辨識結果(呼叫 call…image…with outputs…then do 紫色積木後會自動將拍好的照片送到 Azure 去辨識並會回傳辨識結果的文字串)。
完整的程式碼如圖 5 所示。
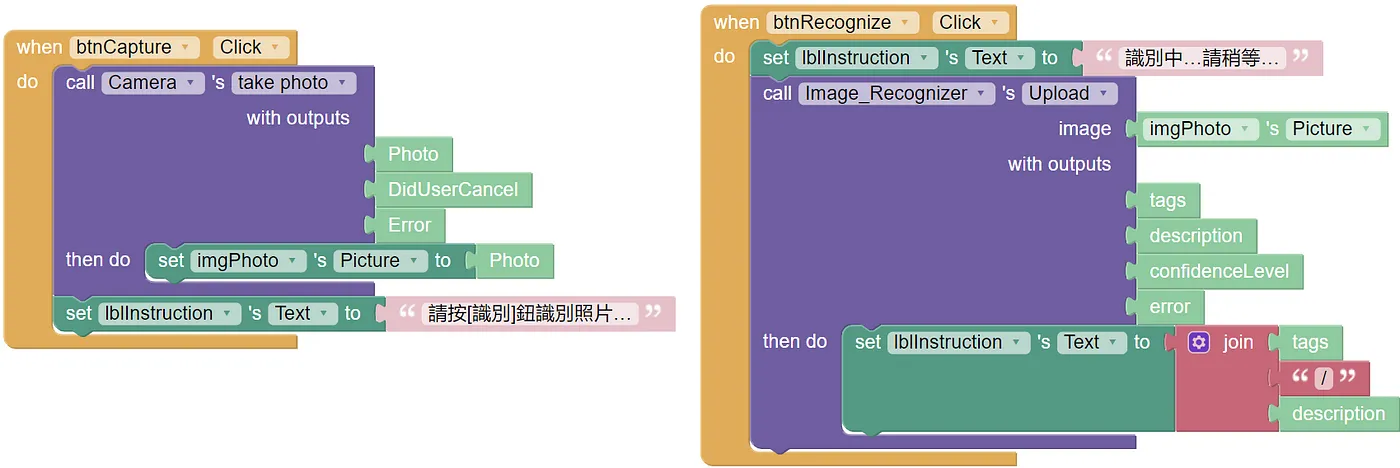
圖 5:App 的完整程式碼
(作者為本刊專欄作家,本文同步表於作者部落格,原文連結;責任編輯:謝涵如)

- 用GenAI自動拆解程式碼學習:GenAI時代的新程式學習法 - 2025/12/29
- 「動手」之前 你需要了解電腦系統的基礎知識點! - 2025/11/28
- GenAI拆解學習:以「健康手環監測系統」示例 - 2025/10/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

