作者:許哲豪(Jack)
 身為一個人工智慧(AI)從業人員,好不容易費盡千辛萬苦訓練好一個模型並且得到不錯的推論準確度後,總會遇到客戶抱怨「這個模型太大塞不進我的硬體,這個推論的速度不能再快一些嗎?」。當換了一個較小、速度快一點的模型,又被抱怨「這個推論的準確度不能再高一點嗎?」。此時腦中總會想起星爺的電影「九品芝蔴官」豹子頭的那句經典台詞「我全都要」,難道就沒有折衷一點的辦法,讓我在AI推論速度、準確度和模型大小都能滿足嗎?
身為一個人工智慧(AI)從業人員,好不容易費盡千辛萬苦訓練好一個模型並且得到不錯的推論準確度後,總會遇到客戶抱怨「這個模型太大塞不進我的硬體,這個推論的速度不能再快一些嗎?」。當換了一個較小、速度快一點的模型,又被抱怨「這個推論的準確度不能再高一點嗎?」。此時腦中總會想起星爺的電影「九品芝蔴官」豹子頭的那句經典台詞「我全都要」,難道就沒有折衷一點的辦法,讓我在AI推論速度、準確度和模型大小都能滿足嗎?
Intel OpenVINO算是聽到大家的心聲了吧,日前推出了「Post-Training Optimization Tool (以下簡稱POT)」來幫助大家,在不用重新訓練模型的情況下,只需執行幾個簡單的命令,模型瞬間縮小,且在僅僅損失一點點推論準確度情況下就能得到1.1到3.3倍左右推論速度的提升!
POT究竟用了何種方式才能達成這個結果,接下來就從「何謂量化(Quantization)」、「量化算法(Quantization Algorithms)」、「使用DL Workbench快速優化」、「安裝POT相依套件」等面向來作一些簡單說明,最後再用一個「影像分類MobileNet模型優化」實際案例說明其執行方式及優化結果,希望能讓大家有更愉快的AI落地開發體驗。
何謂量化 (Quantization)
相信大家平常都有在拍數位照片,一張1920×1080(俗稱200萬畫素)解析度全彩的照片原始檔案大小就要6,220.8KB,如果不經過壓縮,大概拍沒幾張記憶卡就爆了,所以就有破壞性壓縮的影像格式產生,如JPG格式。同樣一張照片經過破壞性壓縮後,檔案就只剩不到200KB(不同影像壓縮比例不同),檔案大小縮小了30倍以上,但人眼卻很難察覺其中的差異,而其中最大的功臣就是「量化(Quantization)」及「編碼(Encoding)」技術。於是就有人想到是否可以套用這樣的概念到AI模型壓縮上。
那什麼是量化呢?首先要先了解為什麼要量化。在真實世界中大部份的物理量(如色彩、亮度、音量等)都是連續數值(類比信號),我們很難完整直接記錄所有的內容,於是就有了把類比信號轉換成數位信號再記錄的方式產生。而影響數位信號是否能完美還原成類比信號的兩大參數就是「解析度」及「取樣頻率」。
其中「解析度」又可分為純整數及整數加小數點表示。前者會以2的n次方來表示,而為了配合電腦運算,n通常為8, 16, 32, 64,又可寫作INT8, INT16, INT32及INT64。而後者為了表示小數點,通常採用浮點數表示,常見有半精度(FP16)、單精度(FP32)及倍精度(FP64)浮點數。
這裡明顯可看出不同的數值表示方式,在儲存空間及解析能力有明顯的差異。以INT8和FP32來舉例比較,INT8只需8個bit來表示整數,最多只能表示2的8次方256位階(+127到-128或者0到255)。而FP32需要32bit來表示整數加小數點,其中1 bit表示正負值,8 bit表示指數(-128到+127),23 bit表示數值,整體可表現的動態範圍大約是在-1.410-45到+3.410+38。
因此資料壓縮最快速的方式就是改變連續(類比)數值「量化」方式,而最直覺的想法就是把高解析度降到低解度,把浮點數降到整數,那儲存空間馬上大幅減少。以FP32轉成INT8來看,儲存空間從32 bit變成8 bit,一下就少了3/4(相當於75%)。而計算從浮點數轉換成整數後,更可透過INTEL CPU的單指令多資料(Single Instruction Multiple Data, SIMD)平行計算指令集(如SSE4.2, AVX2, AVX512等)加速運算,讓計算速度提升數倍到數十倍。如Fig. 1所示。
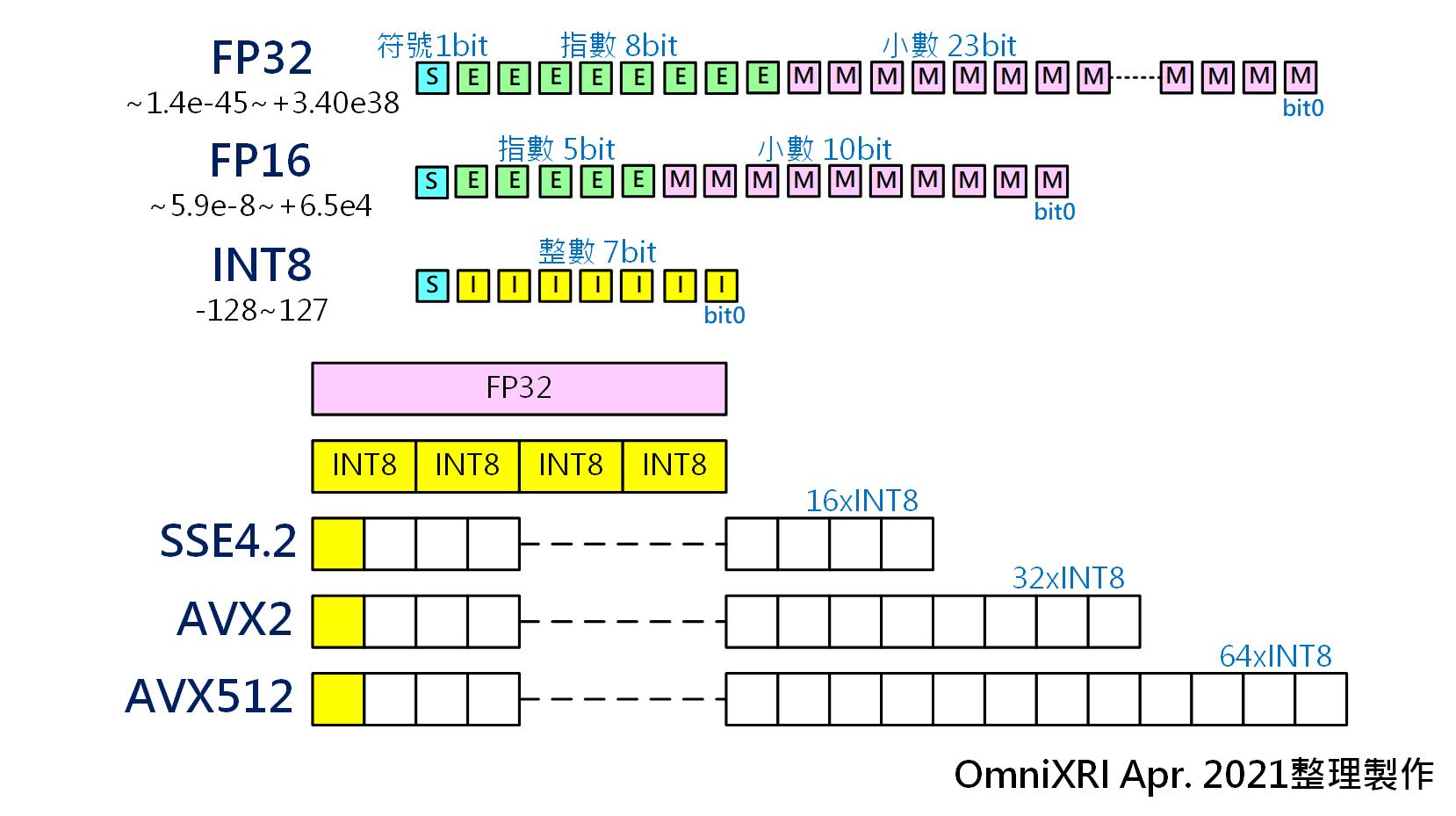
Fig. 1 數值量化及單指令多資料(SIMD)平行運算指令集示意圖。(OmniXRI Apr. 2021整理製作)
量化算法(Quantization Algorithms)
一般來說,為求得深度學習模型有較好的訓練結果,通常會使用FP32做為參數初始的數值表示方式,包括權重值(Weights)及激活值(Activations)。待訓練完成後透過POT插入「偽量化(Fake Quantize)」步驟將FP32降至INT8數值格式,如此便不用重新訓練模型,就可得到較小儲存空間的模型及較快速運算速度。
亦可調整相關參數使其成為「對稱量化(Symmetric Quantization)」或「非對稱量化(Asymmetric Quantization)」。以FP32轉換至INT8為例,首先找出FP32所有參數的最大值(max.)和最小值(min),再將FP32的值重新依比例映射到INT8空間中,如Fig. 2所示。更完整的量化公式可參考[2],這裡就不多作說明。
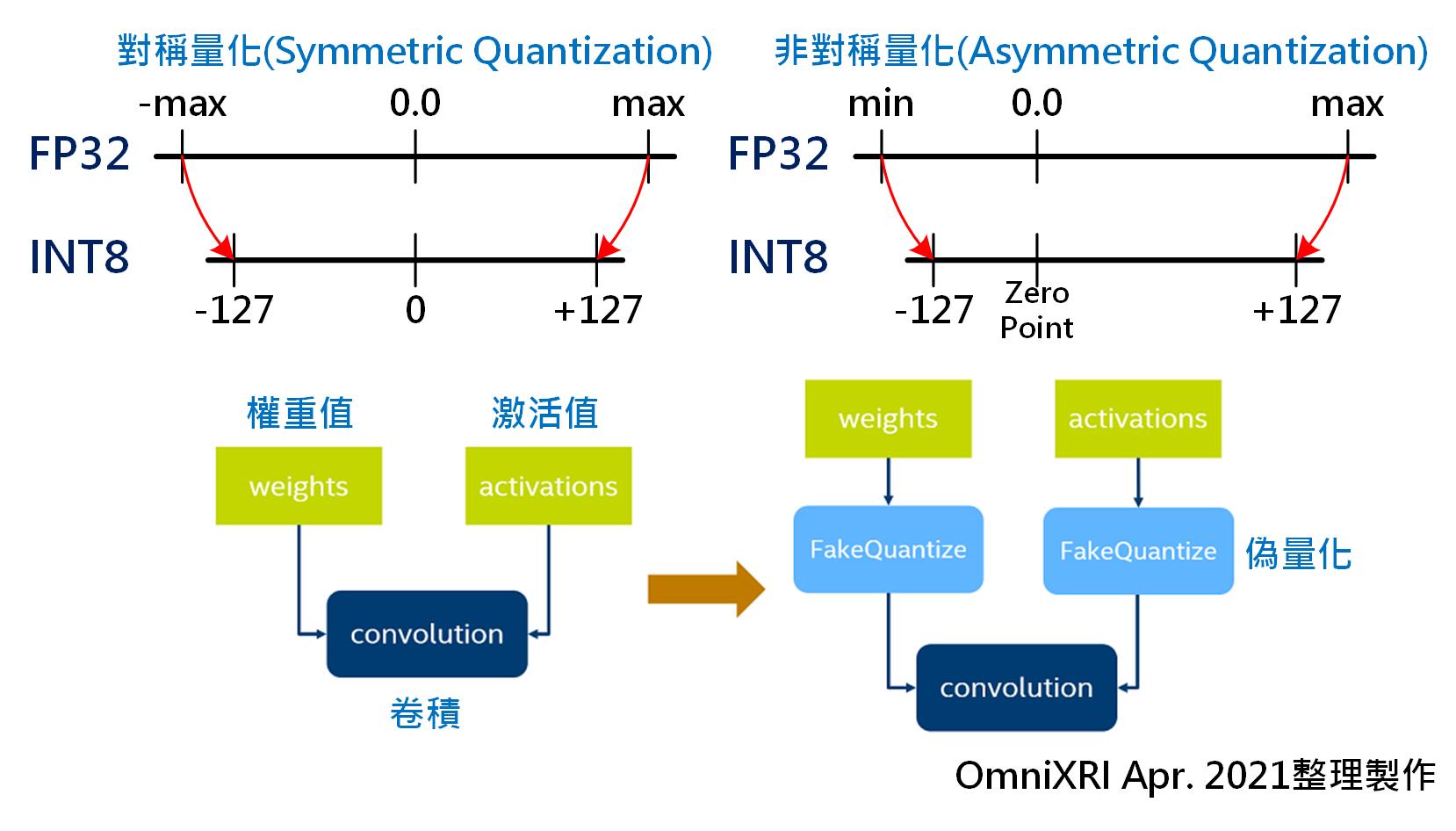
Fig. 2 對稱式、非對稱式量化及偽量化示意圖。[2] (OmniXRI Apr. 2021整理製作)
1. 預設量化(DefaultQuantization):
輸入正常訓練後的模型,將卷積層輸出之激活值範圍做一簡單對齊,減少量化時的誤差。再根據量化前最大及最小值在權重值及激活值自動插入偽量化層。最後基於卷積及全連結層量化誤差調整偏置量(Bias),使得整體誤差保持不變。[3]
2. 準確度感知量化(AccuracyAwareQuantization):
首先使用預設量化算法對輸入模型進行INT8量化。接著測試驗證資料集量化前及量化後的準確度。若符合指定容許下降的準確度範圍,就結束量化調整動作,得到新的模型權重值及激活值。若推論準確度下降超過指定範圍,則取得逐層對準確度下降的貢獻並排序,即找出造成不準的主要源頭。接著將有問題的層還原為原數值精度(如FP32),再重新驗證推論準確度,直到滿足限制下降的容許度。如果限制下降幅度要求很小,則最差狀況可能將所有INT8內容全部還原回FP32,等於模型參數完全沒調整、沒重新量化。[4]
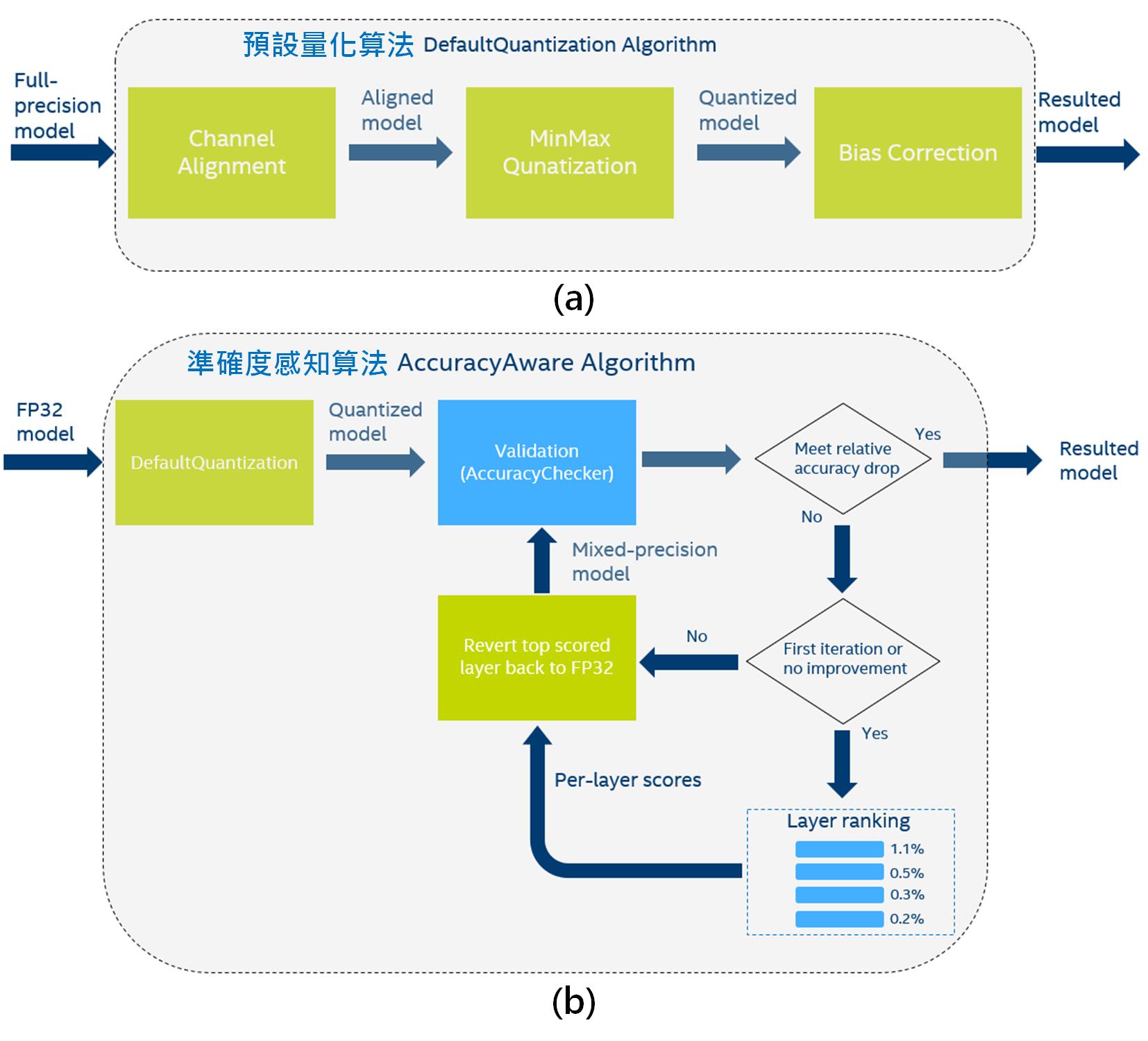
Fig. 3 OpenVINO POT INT8量化算法(a)預設量化[3],(b)準確度感知量化[4]。
使用DL Workbench快速優化
在前一篇文章「不用寫程式也能玩轉深度學習模型 ─ OpenVINO™ DL Workbench圖形化介面工具簡介」[5]最後留了一個小彩蛋,這裡就幫大家補充說明,其實Workbench可在建立基準點時順便選擇優化(Optimize)方式,執行POT來得到轉換成INT8格式的IR(*.bin & *.xml) 中間表示檔案,下載後就可使用,不用寫任何程式,接下來就簡單說明如何操作。
參考[5]實際案例操作執行步驟,當進入[5.建立建立基準點]時,會自動建立第一個基準點,此時可切換到優化[Optimize]頁面,選擇[INT8]選項,就會進到數值校正方式(Calibration Method)選擇,即上一節中提及的POT量化算法。
這裡可選擇[預設量化(Default Method)]或[準確度感知量化(AccuracyAware Method)],若選後者則可再輸入期望容許下降的幅度(%),建議不要太小,以免失去優化速度和模型大小的目的。最後按下[Optimize]鍵就會自動產生新的工作組態,不過這裡可能會視電腦的等級、模型的大小、複雜度及容許下降幅度,需要等待數分鐘到數十分鐘不等的轉換時間。完整操作流程如Fig. 4所示。
當產生新的工作組態後,應該會自動計算第一次的測試結果,包括輸出速度(Best Throughout, FPS)、延時(Respective Latency, ms)及準確度(Accuracy)。若數值空白則按一下更新符號(藍色旋轉箭頭)進行重新計算。由Fig. 4案例來看,經過優化(INT8預設量化)後,輸出速度快了1.6倍,延時也降了1.6倍,而準確度只掉了1%,表現相當不錯。當然不同的模型及優化後的改善幅度也會有所不同。
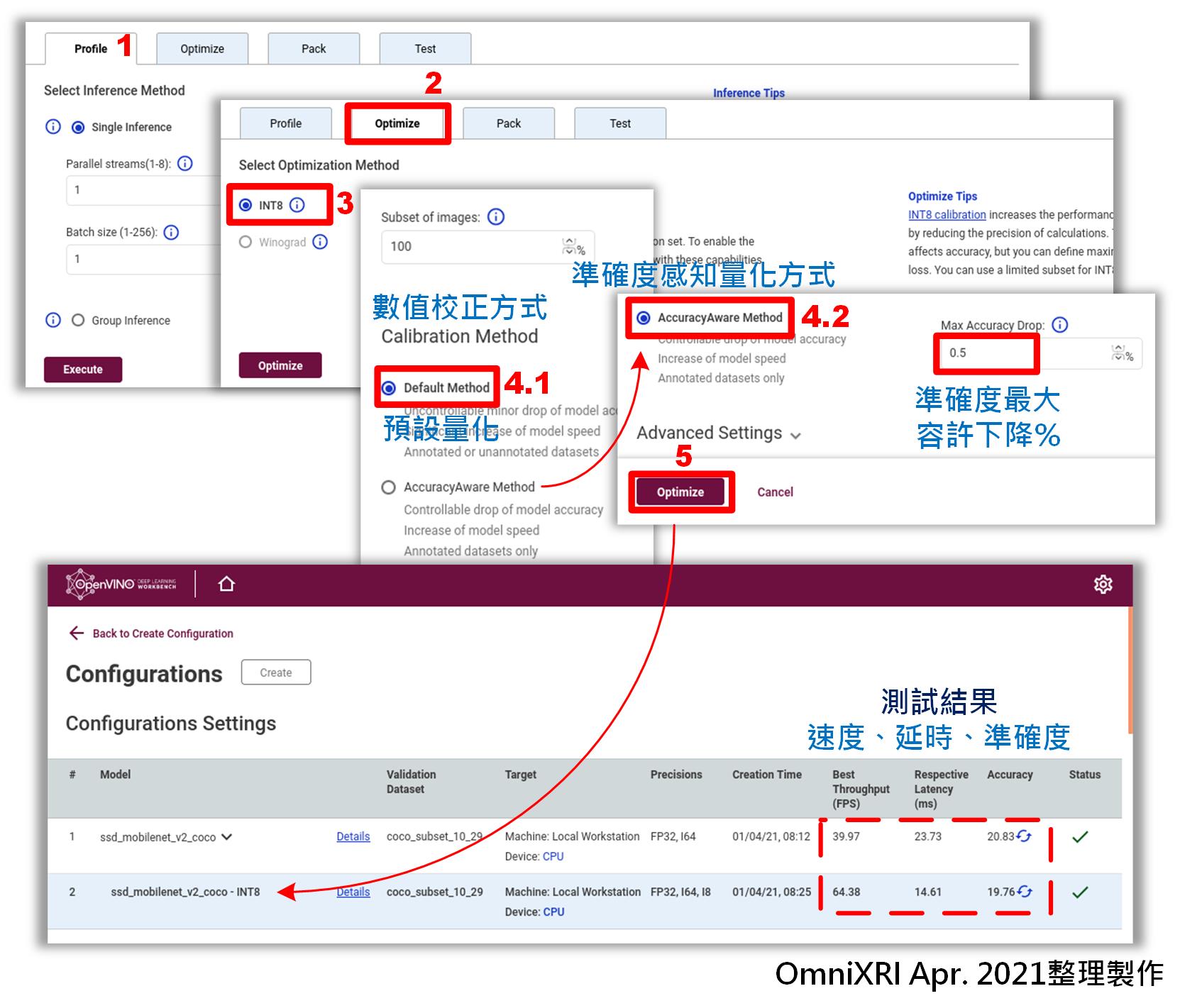
Fig. 4 DL Workbench使用POT優化操作流程圖。(OmniXRI Apr. 2021整理製作)
安裝POT相依套件
若不想使用DL Workbench來取得POT優化結果,亦可以使用命令列方式進行操作。首先要說明的是OpenVINO POT並不在開源的範圍,無法從官方Github上取得,只能透過一般正常安裝包取得,安裝POT前須先安裝好OpenVINO Toolkit完整版。以下就使用Ubuntu 18.04環境安裝來進行說明,依序要安裝好「模型優化器(Model Optimizer, MO)」、「準確度檢查器(Accuracy Checker, AC)」及「訓練後優化工具(Post-training Optimization Tool, POT)」。
#預設在Unbuntu上安裝完OpenVINO後會存放在 /opt/intel/openvino_2021 路徑下,不同版本請自行修改路徑名稱
#1.進入命令列模式後,一定要先設定環境變數,不然後面很多操作會出現錯誤,找不到對應工作路徑及變數。
cd /opt/intel/openvino_2021/bin/
./setvars.sh
#2.接著切換路徑,安裝模型優化器(MO)預要求項目。
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/install_prerequisites
sudo ./install_prerequisites.sh
#3.若成功,回到上一層,執行下列命令,顯示MO各參數說明文字。
cd ..
python3 mo.py -h
#4.切換路徑,安裝並執行準確度確認器(AC),顯示AC各參數說明文字。
cd /opt/intel/openvino_2021/deployment_tools/open_model_zoo/tools/accuracy_checker
python3 setup.py install
accuracy_check -h
#5.切換路徑,安裝並執行訓練後優化工具(POT),顯示POT各參數說明文字。
cd /opt/intel/openvino_2021/deployment_tools/tools/post_training_optimization_toolkit
python3 setup.py install
pot -h
影像分類MobileNet模型優化
接下來就以常見的影像分類模型MobileNet-v2來說明如何利用POT執行優化工作。
1.環境設定、下載模型並轉換至IR格式
首先依據上一節說明把模型優化器(MO)、準確度檢查器(AC)及訓練後優化工具(POT)安裝好,創建一個可供下載模型的路徑並下載模型。接著把下載到的模型轉換成OpenVINO專用的中間表示格式IR(*.bin, *.xml)檔案,包含FP16及FP32數值精度。更多公開模型類型及名稱可參考[6]說明。
mkdir /home//Models
cd /home//Models
#下載mobilenet-v2模型,這裡可替換成其它常用公開模型
python3 /opt/intel/openvino_2021/deployment_tools/open_model_zoo/tools/downloader/downloader.py --name mobilenet-v2
#完成下載後會在 /home//Models/public/mobilenet-v2路徑下看到Caffe格式模型檔 mobilenet-v2.caffemodel及mobilenet-v2.prototxt,不同模型可能由不同框架產生(如TensorFlow, PyTorch, ONNX…)
#轉換模型變成OpenVINO中間表示格式IR檔案(*.bin, *.xml)
python3 /opt/intel/openvino_2021/deployment_tools/open_model_zoo/tools/downloader/converter.py --name mobilenet-v2
#完成轉換後會在 /home//Models/public/mobilenet-v2路徑下產生/FP16及/FP32二種數值精度格式的IR檔(*.bin, *.xml)
2.模型原始數值精度的性能基準測試
為了得知後續優化程度,這裡可以先進行一些性能基準測試(Performance Benchmark),了解原始數值精度(FP16 / FP32)的表現,經計算後可得到其延遲時間(ms)及輸出速度(FPS)。
python3 /opt/intel/openvino_2021/deployment_tools/tools/benchmark_tool/benchmark_app.py -m /home//Models/public/mobilenet-v2/FP32/mobilenet-v2.xml
#這裡是以Intel Core i5-4440 @3.10GHz * 4, 8GB RAM, Ubuntu 18.04.5 LTS 64ibt環境進行測試,完成測試後會得到如下數值。
Latency: 17.09 ms
Throughput: 222.71 FPS
3.準備資料集
這裡不限何種資料集,可自行準備,只要滿足OpenVINO的規範即可,建議選用ImageNet, VOC, COCO等常用資料集格式會較方便。這裡以ImageNet來舉例,首先到ImageNet官網[7]申請一個帳號,點選同意用於非商業用途,它會寄出確認信,點擊回覆後就能開通,但請注意他們不接受hotmail或gmail的電子信箱申請。
接著切換到下載(Download)頁面,移到最下方Download links to ILSVRC image data,點選2012,挑選Validation images(all tasks) 6.3GB下載驗證影像集,另外可從[8]下載到這個資料集的標註檔。若只是想測試一下整個POT工作流程,不想大費周章,這裡幫大家準備了一個從上述資料[7][8]摘錄出來的超迷你影像分類用資料集和標註檔(只有100張影像)方便測試使用,請勿移作其它用途。下載網址如下,再將其解壓縮至/home/<user name>/Models下即可。
https://github.com/OmniXRI/OpenVINO_POT_Test_Data
4.IR格式原始精度模型的準確度驗證
在/home/<user name>/Models路徑下建立準確度檢查器(Accuracy Checker)組態檔案mobilenet_v2.yaml,內容如下。其中datasets下的data_source即為準備好的資料集路徑,而annotation_file則為標註檔案路徑及名稱,要手動修改為自己準備好的路徑,其它更進一步相關參數設定可參考[9]。
- name: mobilenet-v2
launchers:
- framework: dlsdk
device: CPU
adapter: classification
datasets:
- name: classification_dataset
data_source: ./MiniImageNet
annotation_conversion:
converter: imagenet
annotation_file: ./MiniImageNet/val.txt
reader: pillow_imread
preprocessing:
- type: resize
size: 256
aspect_ratio_scale: greater
use_pillow: True
- type: crop
size: 224
use_pillow: True
- type: bgr_to_rgb
metrics:
- name: accuracy@top1
type: accuracy
top_k: 1
<ul>
<li>name: accuracy@top5
type: accuracy
top_k: 5
接著就能以下列命令執行準確度評估了。
結果如下所示。
accuracy@top1: 73.00%
accuracy@top5: 92.00%
5.模型量化
在/home/<user name>/Models路徑下建立訓練後優化工具組態(POT Configuration)組態檔案mobilenet_v2_int8.json,內容如下。其中model下的model和weights指定的是原始(FP32)數值精度的IR格式模型(.xml)及權重檔(.bin),而engine下的config則是指定上一步驟產生的mobilenet_v2.yaml,最後指定模型INT8量化演算法類型,即為compression下algorithms下name下的DefaultQuantization。這裡name亦可選擇”AccuracyAwareQuantization”,但要在params下新增一項”maximal_drop”: 0.01,來指定優化時最大容許準確率下降幅度。
"model": {
"model_name": "mobilenet-v2",
"model": "./public/mobilenet-v2/FP32/mobilenet-v2.xml",
"weights": "./public/mobilenet-v2/FP32/mobilenet-v2.bin"
},
"engine": {
"config": "./mobilenet_v2.yaml"
},
"compression": {
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "performance",
"stat_subset_size": 300
}
}
]
}
}
接著就能以下列命令執行訓練後優化工具,產生INT8格式的模型及權重了。
執行後會產新的路徑/results/mobilenetv2_DefaultQuantization/<Date_Time>/optimized,而結果會置放於此,其中為執行當下時間,重複執行時會產生不同時間(目錄名稱),結果顯示如下所示。
INFO:compression.engines.ac_engine:Inference finished
INFO:app.run:accuracy@top1 : 0.69
INFO:app.run:accuracy@top5 : 0.94
若想更了解POT組態設定,可參考[10]。
6.執行模型量化後性能基準比較
最後執行下面指令來確認INT8量化(優化)後得到的效果。這裡要注意<Date_Time>須為上一步驟產生的路徑。
執行結果如下所示。感覺上和前面以DL Workbench執行ssd-mobilenet_v2-coco效果差滿多的,在推論速度部份只有提升約9.8%,Top 1準確度還不錯只掉了約1%,模型(xml)檔案則因增加許多Fake Quantization層描述,所以變大一些,但權重(bin)部份則減到剩原來的26.7%,相當於減去3/4的檔案大小,對於記憶體的需求減輕不少壓力。
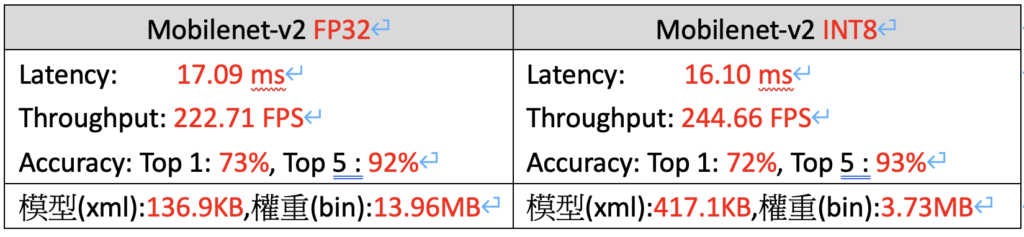
經測試多種模型後得知,速度提升可能從0.01倍到3倍多,會隨模型開發框架(如Caffe, TensorFlow, ONNX…)、搭配資料集結構(如ImageNet, VOC, COCO…)、模型應用類型(如影像分類、物件偵測、影像分割、骨架關鍵點偵測等…)及電腦運算時的系統資源(CPU, RAM…)配置不同,可能都會得到差異頗大結果,因此想快速找出最優解,則利用DL Workbench圖形化介面來操作會更加便利。最後補充一個INTEL官方的POT介紹影片[11],方便大家更進一步了解這項工具。
小結
一般AI工程師最苦惱的推論速度、準確度及模型大小,經過Intel OpenVINO的訓練後優化工具(Post-Training Optimizztion Tool, POT)處理後,不用寫半行程式,就能馬上讓模型縮小到原有1/2甚至1/3,推論速度提高1.1到3倍,準確度還只掉一點點。若再搭配OpenVINO DL Workbench圖形化介面使用,工作效率就更高了。話說回來,這麼好用的工具千萬不要讓老板知道,工程師只能自己偷偷用,不然工作就做不完了。
參考文獻
[1] Intel OpenVINO Toolkit, “Post-Training Optimization Toolkit”
[2] Intel OpenVINO Toolkit, “Quantization”
[3] Intel OpenVINO Toolkit, “DefaultQuantization Algorithm”
[4] Intel OpenVINO Toolkit, “AccuracyAwareQuantization Algorithm”
[4] Intel OpenVINO Toolkit, “Tree-Structured Parzen Estimator (TPE)”
[5] 許哲豪,” 【Intel OpenVINO™教學】不用寫程式也能輕鬆上手AI模型分析、優化、佈署─DL Workbench圖形化介面工具簡介”
[6] Intel OpenVINO Toolkit, “Overview of OpenVINO™ Toolkit Public Models”
[7] ImageNet
[8] ImageNet ILSVRC 2012 annotation file
http://dl.caffe.berkeleyvision.org/caffe_ilsvrc12.tar.gz
[9] Intel OpenVINO Tool Kit, “Deep Learning accuracy validation framework”
[10] Intel OpenVINO Tool Kit, “Post-Training Optimization Best Practices”
[11] Intel OpenVINO Tool Kit, “Post Training Optimization Tool | OpenVINO™ toolkit | Ep. 68 | Intel Software” (Youtube)
*延伸閱讀
[A] 許哲豪,”【Intel OpenVINO教學】如何利用Docker快速建置OpenVINO開發環境”
[B] 許哲豪,”【Intel OpenVINO™教學】GStreamer串流影片智能分析不再慢吞吞─看Intel OpenVINO DL Stream如何加速影片推論”
(責任編輯:謝涵如)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


