TensorFlow團隊工程師日前(11/29)在官方Blog宣佈,TensorFlow Lite 和 XNNPack 全面支援FP16的半精度推論(Half Precision Inference),同時指出,透過在 ARM CPU 上啟用半精度推論,能將TensorFlow Lite 的XNNPack backed的浮點推論性能提高了一倍,進而有助於讓AI功能部署到較舊和較低階的設備之上。
傳統上,TensorFlow Lite 支援機器學習(ML)模型中的兩種數值運算方式:1. 使用 IEEE 754 單精度(FP32)格式的浮點數運算,以及2. 使用低精度整數(INT8)進行量化。雖然單精度浮點數提供了最大的靈活性和易用性,但它們的代價是對儲存和記憶體的需求增加了 4 倍,並且與 8 位元整數計算相比,效能需求也更大。
該文指出,相較之下,半精度(FP16)浮點數運算方式提供了一種有趣的替代方案,可以平衡易用性和效能:處理器需要傳輸的位元組數減少兩倍,而每個向量運算會產生兩倍的元素。憑藉這一特性,與傳統 FP32 方式相比,FP16 推論能實現浮點模型的 2 倍加速。
半精度推論已經在 Google Assistant、Google Meet、YouTube 和 ML Kit 的應用中經過了實戰測試,並在各種神經網路架構和行動裝置上展示了接近 2 倍的加速。以下是作者針對電腦視覺任務常見的九個公共模型做出的Benchmark:
- MobileNet v2 image classification [download]
- MobileNet v3-Small image classification [download]
- DeepLab v3 segmentation [download]
- BlazeFace face detection [download]
- SSDLite 2D object detection [download]
- Objectron 3D object detection [download]
- Face Mesh landmarks [download]
- MediaPipe Hands landmarks [download]
- KNIFT local feature descriptor [download]
這些模型在 5 種流行的行動裝置上進行了基準測試,包括最新和較舊的裝置(Pixel 3a、Pixel 5a、Pixel 7、Galaxy M12 和 Galaxy S22)。平均加速如下圖所示,數字越高表現越好。
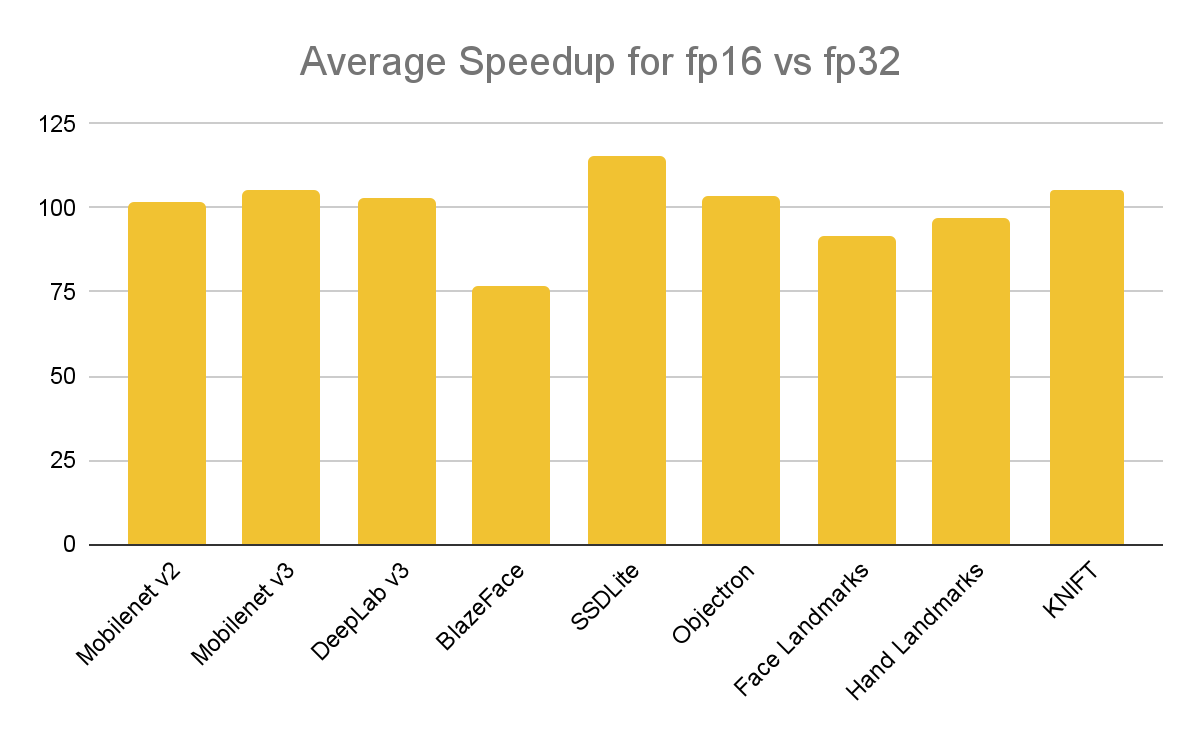 除了大多數 ARM 和 ARM64 處理器之外,最新的英特爾處理器(代號 Sapphire Rapids)透過 AVX512-FP16 指令集也已支援本機 FP16 運算,而最近發布的 AVX10 指令集有望使此功能在 x86 平台上廣泛使用。TensorFlow團隊計劃在未來版本中針對這些指令集最佳化 XNNPack。
除了大多數 ARM 和 ARM64 處理器之外,最新的英特爾處理器(代號 Sapphire Rapids)透過 AVX512-FP16 指令集也已支援本機 FP16 運算,而最近發布的 AVX10 指令集有望使此功能在 x86 平台上廣泛使用。TensorFlow團隊計劃在未來版本中針對這些指令集最佳化 XNNPack。
(責任編輯:歐敏銓)

- 結合TAIWAN AI RAP平台資源 國研院推賦能方案及實戰工作坊 - 2026/06/18
- Nordic以超低功耗邊緣AI與無線連線技術引領物聯網創新 - 2026/06/16
- AI伺服器記憶體需求持續上揚 LPDRAM供給缺口難弭平 - 2026/06/15
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


