作者:陸向陽
過去有本暢銷書《你要如何衡量你的人生?》,由哈佛企管教授所著,作者發現每年在哈佛畢業生聚會上愈來愈少人感到快樂,甚至有人入獄,而坊間許多的快樂學、幸福學多為個人個案經驗,難普遍適用,因而嘗試運用企管領域的學術研究章法,將企業經營法套用到人生經營上,以便有更廣泛、客觀、公允的人生指導。
類似的,近期TinyML蔚為時尚,許多軟硬體業者都說自己的技術方案表現卓越,例如晶片有更高的TOPS效能,編譯器軟體可以把AI模型壓縮到只有極低的記憶體佔量等,但這些強調或多或少有偏頗,例如使用對自己有利的組態配置設定,或刻意隱瞞卓越表現的背後,其實有諸多的他項犧牲或妥協。
為了能更公允評判Edge AI、TinyML軟硬體的特性表現,因而需要基準(Benchmark)測試,筆者目前找到兩個機構有對此投入,一是MLCommons,另一是EEMBC(Embedded Microprocessor Benchmark Consortium,嵌入式微處理器標竿基準測試聯盟),以下分別說明。
MLCommons的MLPerf Inference: Tiny
MLCommons本來即已針對人工智慧、機器學習的運算效能提出名為MLPerf的基準測試,並再進一步概括分成訓練、推論兩大類。
在訓練中,又可再分成一般訓練或高效率運算訓練兩種,推論方面也有資料中心、邊緣、行動等三種,而針對TinyML又再提出第四種,即MLPerf Inference: Tiny。不同的測類測項也有不同的版本發展進度,目前Inference: Tiny為v0.5版,尚未進入v1.0正式版:
- Training, v1.1
- Training: HPC, v1.0
- Inference: Datacenter, v1.1
- Inference: Edge, v1.1
- Inference: Mobile, v1.1
- Inference: Tiny, v0.5
MLPerf將送測分成Close與Open,前者被要求要遵循一致的規範進行測試,後者則可自行宣告測試結果,但還是要交代改動哪些技術細節與配置。另外送測也分成Available、Preview或「Research, Development, Other」,Available是現在市場上立即可買到的軟硬體所搭組成;Preview是業者提供的技術預覽,預估在下一次新發佈時也會成為Available;Research則是更雛形、前期的送測組合。
送測的組合要宣告提交者(通常是業者名稱)、裝置(通常是板卡名稱)、處理器、加速器、軟體等,測試的應用情境則有4項:
- Visual Wake Words,視覺喚醒字
- Image Classification,影像分類
- Keyword Spotting,關鍵字蹤跡識別
- Anomaly Detection,異常偵測
每個情境都有對應的資料、模型、精準度等,然後效能以延遲的毫秒(mS)數來計算,時間愈短效能愈佳。另外,測項也可以從功耗角度來評估,單位是微焦耳(µJ),不過目前多數業者只測延遲,不測功耗。2021年6月至今的MLPerf Inference: Tiny測試數據可參考此連結。
EEMBC的MLMark
與MLCommons不同,EEMBC打從2000年中起就有制訂與經營一系列有關嵌入式應用的測試基準,如OABench、ConsumerBench等,一路至今已有10多項測試,而針對超低功耗(Ultra-Low Power, ULP)晶片方面也有ULPMark系列的測試,並在2019年第三季針對ML需求提出MLMark。
EEMBC過往以來發起與經營的嵌入式基準測項(來源:EEMBC)
MLMark宣稱用於邊緣級裝置(Edge Class Device),比較像是MLCommons的MLPerf Inference: Edge,但後續也將能適用於更嬌小的TinyML。MLMark比較不像MLPerf那樣是以效能、功耗兩項為主,而是提供一個共通基準,以便衡量犧牲精度時可提升多少效能?犧牲準確性時可獲得多少效能?或其他各種權衡取捨的公允比較。
MLMark目前已比較幾套系統,如NVIDIA的Jatson Nano與Jetson Xavier AGX、Google的Edge TPU、Intel的Myriad X,或Huawai(華為)的Kirin(麒麟)970,以及NXP/Freescale的i.MX8M等。
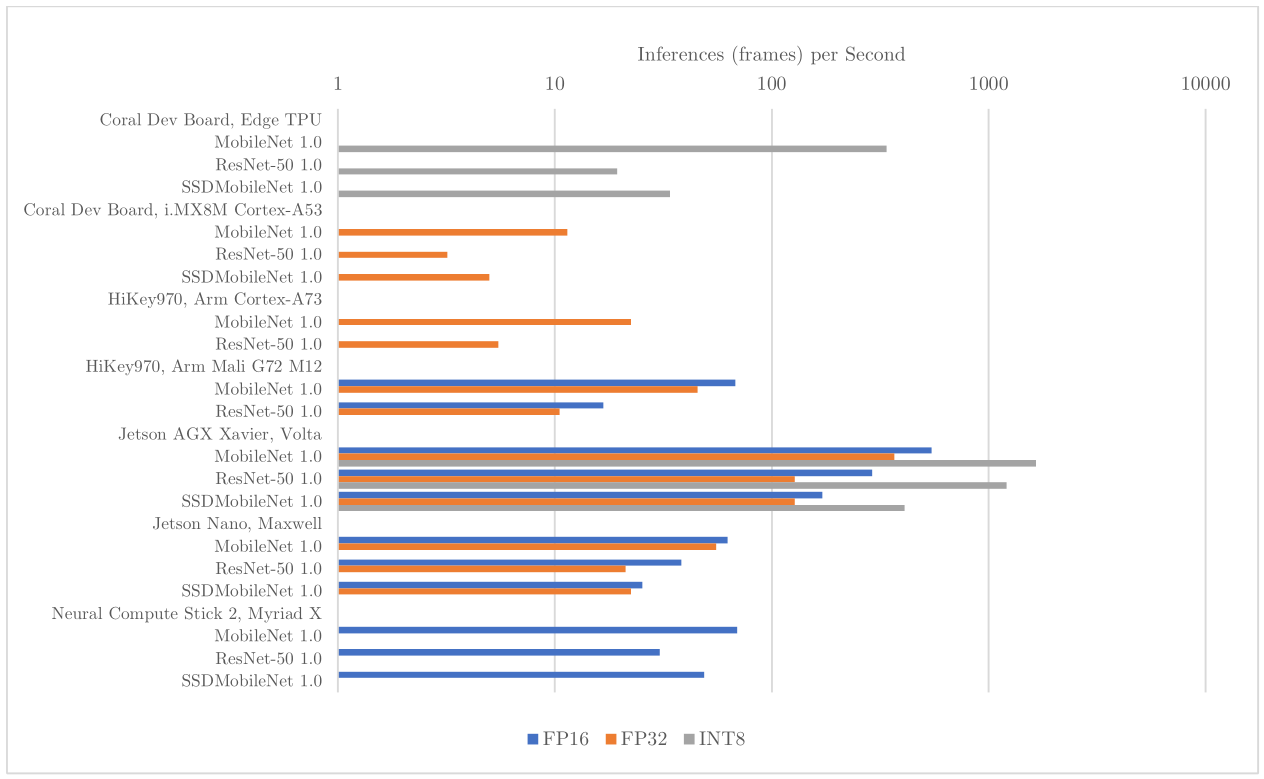
MLMark測試不同系統在不同精度下的效能fps,長條圖愈長效能愈佳(來源:EEMBC)
或者相同模型下使用不同權重精度的效能,如都是使用MobileNet模型,一個使用FP32精度,另一使用INT8,效能可以差91倍之多。或者,相同模型相同精度但框架不同,一為TensorFlow,另一為TFLite(TensorFlow Lite),兩者效能卻相近(31.7fps vs. 30.2fps),TFLite僅微幅跌落。
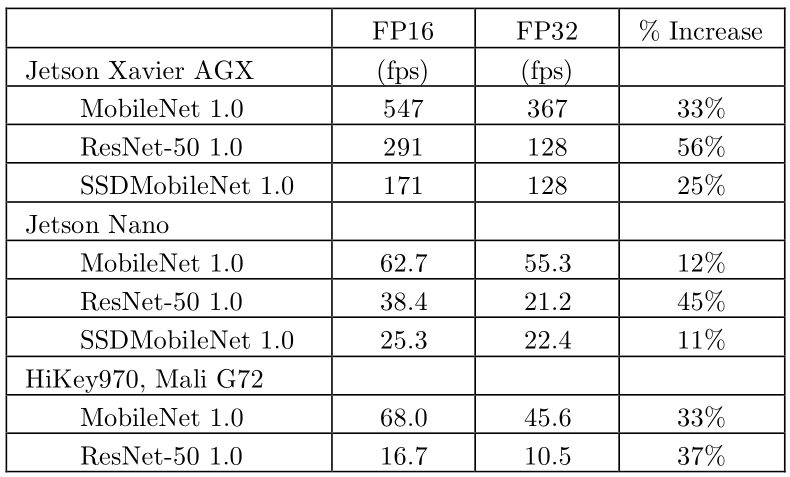
MLMark測試比較,相同系統、相同模型,將精度從FP32改成FP16可獲得11%~56%不等的效能提升(來源: EEMBC)
MLMark目前已是正式v1.0.0版,且依據EEMBC的規劃,後續v1.0.x版會加入更多送測系統並加入分數項,而後v2.0會有新測試平台以及功耗更限縮的測試(言下之意更趨近與因應TinyML需求),不過這些規劃原訂2020年可以實現,至今卻尚未有更新資訊。
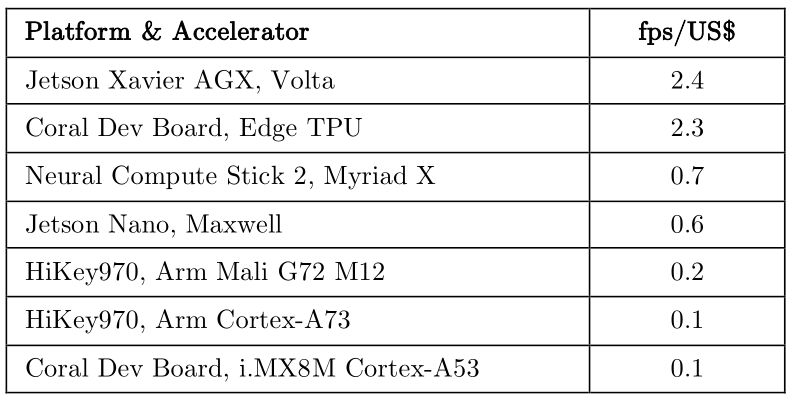
MLMark測試,每1美元可以買到的效能fps,目前以Jetson Xavier AGX最佳(來源:EEMBC)
結語
為了能評判Edge AI、TinyML軟硬體的表現,本篇文章從基準(Benchmark)測試開始說明,並對相關規範進行講解,而且無論MLPerf Inference: Tiny或MLMark,都在官網與GitHub上有更詳整的技術細節揭露,請參考「延伸閱讀」,有興趣的人可再進一步參看。
(責任編輯:唐育琪)
延伸閱讀

- 受保護的內容: 【活動報導】Hack to Refund第一季:挑戰MAX32655FTHR開發板實作任務 - 2026/06/14
- 樹莓派新鮮事:硬體價格調漲、1GB與3GB新版本策略 - 2026/05/28
- 創客新鮮事:Arduino Core轉向Zephyr、可查Token耗量的微型顯示器 - 2026/05/25
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


