作者:尤濬哲
目前人工智慧領域中目前最受到重視的應該還是影像辨識這塊,利用攝影機取代人類的眼睛來觀察世界是一個非常重要的應用,近幾年來的自駕車的快速發展靠的就是人工智慧在影像辨識上的能力快速提昇,其他應用包括電子圍籬、人臉辨識…等等,都必須仰賴這方面的技術,以筆者曾在某大賣場執行「人流統計」專案來說,就是利用人體辨識加上物件追蹤技術來達成。
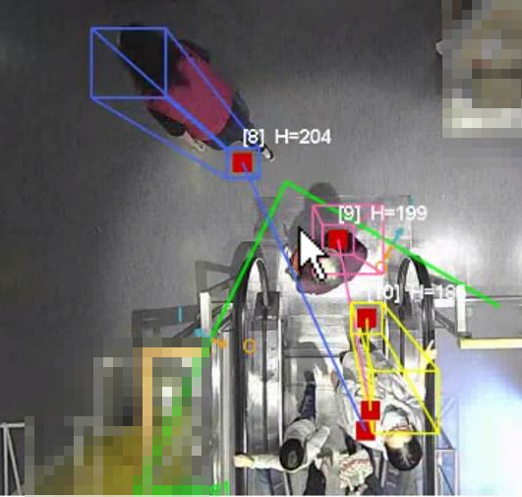
人流辨識
一般來說,要達成這類的專案,除了要熟悉人工智慧的演算法、模型訓練建構之外,還必須了解不同的影像源的讀取解碼,例如熟悉Python影像辨識的夥伴應該都會使用OpenCV來開啟視訊單一擷取裝置,那麼如果現在影像來源不只一個,甚至是不同種類來源時,就會導致程式架構越來越複雜,難以撰寫。
舉例來說,一個NVIDIA邊緣運算裝置(例如Jetson Nano)要辨識4個不同影像來源,例如,1.CSI鏡頭、2.USB鏡頭、3.RTSP串流、4.mjpeg串流,除了資料格式不同,不同類型的影像來源沒辦法全部單獨使用OpenCV處理了,這樣就會導致工程師在建構系統最重要的人工智慧運算核心的部份,卻還必須同時處理影像解碼相關細節問題,就太浪費時間了。
不過以上還算是小問題,試想若有四個影像來源時,你的程式要如何在四個鏡頭的擷取出物件資訊呢?一般狀況,大部分的工程師採用的是「輪循」的作法,也就是像大樓管理員這樣輪著看,一隻一隻的監視器的看,不過這樣的作法有什麼問題呢?
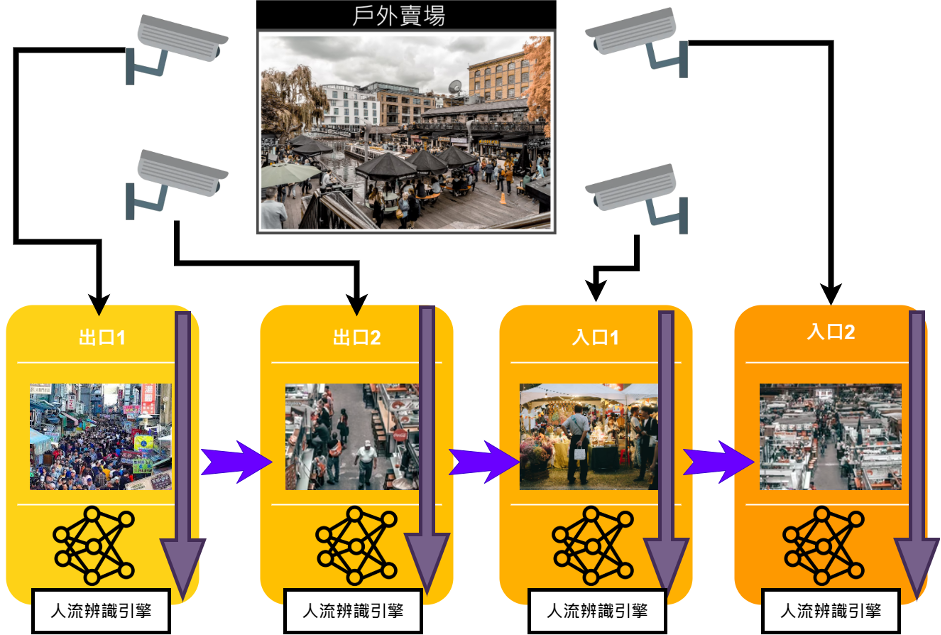
賣場人流監測架構圖A
我們想像一下,如果在一個賣場架了四個影像來源(如上圖),要用這些影像來源來分析賣場的人流數據,根據上面的作法,就是一隻一隻輪著看,擷取到影像後,以AI模型進行分析,取得人流數據後,再換另外一隻鏡頭,重複上面的動作,這時候讀者有沒有發現,人流辨識引擎是同一個,但是卻重複辨識了四次,但這卻是最花時間的,這樣浪費時間的重複工作,有沒有可能可以省下來呢?

賣場人流監測架構圖B
聰明的你,有沒有想到一個方式,也就是如果我們把架構改成上面這樣,也就是影像進來以後,先合併進單一batch後,再將影像利用AI引擎進行辨識,就可以節省重複的工具,進而省下大量時間了,而這也就是NVIDIA的DeepStream技術的特點之一。
DeepStream的技術全解析
不過DeepStream技術也不只是這樣而已,筆者這裡總結DeepStream 5.0 功能,能更輕鬆地在邊緣端建構和部署 AI 應用程式:
- 支援 NVIDIA Triton 推論伺服器
- Python 支援
- 遠端管理和控制應用程式
- 安全通訊
- 透過 Mask R-CNN 執行個體
1.Triton服務
Triton是一個很特別的服務,因為以往Deepstream必須使用TensorRT模型,TensorRT能最佳化效能,但在特定情況下需要開發者自定義模型最佳化,而Triton則是能直接讀取各種模型,包括大家最常使用的Tensorflow、Keras、ONNX、PyTorch、 Caffe2 NetDef等等。
不過TensorRT還是NVIDIA最推薦的,使用TensorRT效能將會超過Triton,不過Triton的靈活性最高,使用者必須在靈活度與效能上做個選擇。

(資料來源)
2.Python支援
由於Deepstream是由C/C++撰寫,因此原先僅支援C進行開發,不過由於Python在AI及資料分析領域已成為主流,大部分的人工智慧工程師也都使用Python來建立模型,因此新版的Deepstream也支援Python進行API呼叫及撰寫,為了讓Python工程師能快速上手,Python 範例應用程式可以從 GitHub 儲存庫 NVIDIA-AI-IOT/deepstream_python_apps 下載。現在 Python模組已成為 DeepStream SDK 套件的一部分。
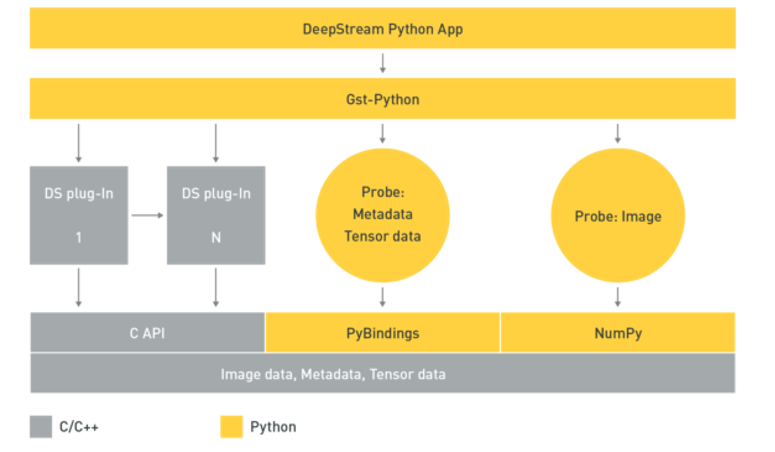
3. 遠端管理和控制應用程式
邊緣運算裝置也是需要連網服務的,例如將辨識完成的數據資料上傳到雲端紀錄,或者接收雲端的新指令或參數等,而DeepStream 5.0 已可支援雙向通訊,以傳送和接收雲端至裝置的訊息,此功能對於各種使用狀況都非常重要,例如觸發應用程式記錄重要事件、變更操作參數和應用程式配置、無線更新(over-the-air,OTA)。
目前是而DeepStream透過 Gstnvmsgbroker (MSGBROKER) 外掛程式進行裝置到雲端的通訊,可調用較低層級的轉接器函式庫。這裡我們可以選擇 Kafka、AMQP、MQTT 或 Azure IoT等資料傳遞方式,目前來說邊緣裝置使用MQTT比例大幅增加,而DeepStream支援MQTT也就更能搭配不同的IoT裝置服務,進行遠端M2M管理。
4.安全通訊
IoT裝置越來越多,但是最重要且最常忽視的層面就是安全性,如何安全的傳輸資料,並避免裝置被駭客綁架,這些都需要更好的安全傳輸協定,而 DeepStream 5.0 使用以 TLS 為基礎的加密進行安全通訊,進而確保資料的機密性。
DeepStream 5.0 支援兩種形式的用戶端驗證:以 SSL 憑證為基礎的雙向 TLS 驗證,以及以使用者/密碼機制為基礎的 SASL/Plain 驗證。用戶端驗證讓代理程式可以驗證與其連線的用戶端,並根據其身分選擇性地提供存取控制。SASL/Plain 是使用熟悉及易於設定的密碼驗證機制,雙向 TLS 則是以用戶端憑證進行驗證,並提供一些可以建置穩健之安全性機制的優點。
5.Mask R-CNN 執行個體分割
目前物件偵測技術越來越成熟,不過目前常見的物件偵測(例如YOLO)只能提供到 bounding box,對於需要更精確位置資訊的應用來說是不足的,例如自駕車的系統需要能取得道路的大小、位置、方向等,如果只能產生Box,那道路只有一個超大佔滿畫面的Box,卻無法提供有用的資訊。
以下面的案例來說,若只有左邊的物件,並無法得知馬路的方向,物件的相對位置及大小,而右邊的物件分割效果則可以提供更多的資訊,包括馬路的方向,讓自駕車可以確認轉彎的角度及方向。
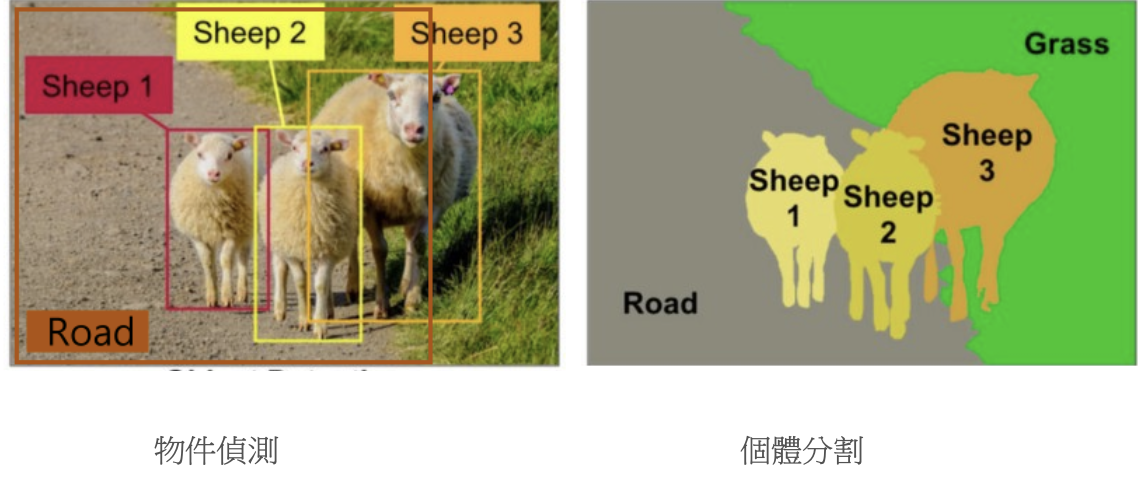
目前Deepstream已經提供 Mask R-CNN模型,可以從 TAO NVIDIA-AI-IOT/deepstream_tao_apps#tao-models GitHub 儲存庫下載預先訓練模型,此模型是用來利用行車記錄器的資料所訓練出來的車輛辨識模型,不過若讀者想要使用該模型來辨識更多自己的物件,可以參閱遷移學習的部份,會指引讀者如何增加辨識的物件。
綜合而言,DeepStream 5.0 提供了許多實用功能,可以輕鬆地開發邊緣端部署的 AI 應用程式。您可以使用 Python API 操作和 Triton 伺服器快速進行原型設計,並輕鬆建立AI的應用。
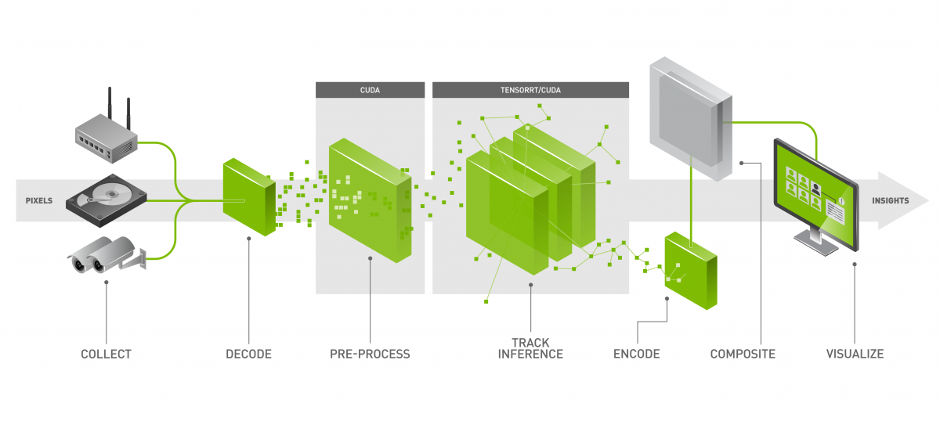
DeepStream效能實測
為了能實際測試DeepStream的功能,我們將利用Jetson Nano安裝DeepStream SDK,並進行YOLO的4個來源分析測試,以了解DeepStream的優勢。
首先準備一台Jetson Nano,記憶體2G或4G皆可,筆者在2G的版本上執行雖然會報錯記憶體不足,但是執行上沒問題,但是還是建議採用4G的版本。
關於DeepStream SDK的安裝可以參考本文。
安裝完畢後,可以透過內建的DeepStream APP範例進行簡單測試,範例位在DeepStream安裝的資料夾:/opt/nvidia/deepstream/deepstream-6.0/samples/configs/deepstream-app$ 內,檔案列表如下:
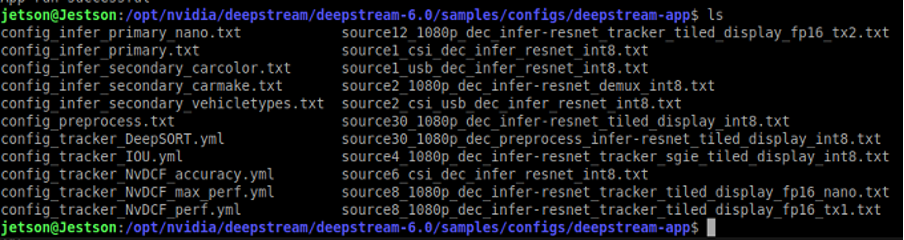
第一次練習時,我們可以挑選專為JetsonNano專用的範例:
source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
由範例的檔案名稱可以知道,這是一個讀取8個來源(Source)、使用resnet模型、影像為平鋪(tiled)、FP16精度、且專為Nano所設計的範例。執行時,要在前方加入命令deepstream-app -c ,因此完整的指令如下:
deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
執行過程中,可能會有多次的警告或報錯,但等候約3-5分鐘後,即可看到執行畫面:
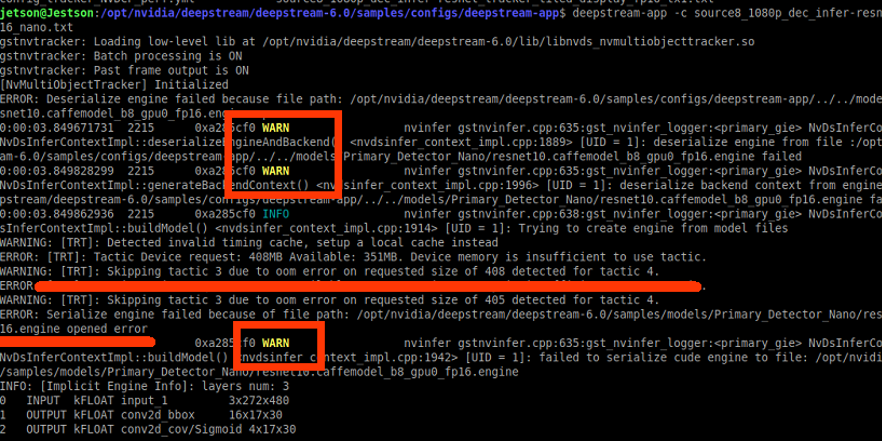
執行過程中,報錯或警告。
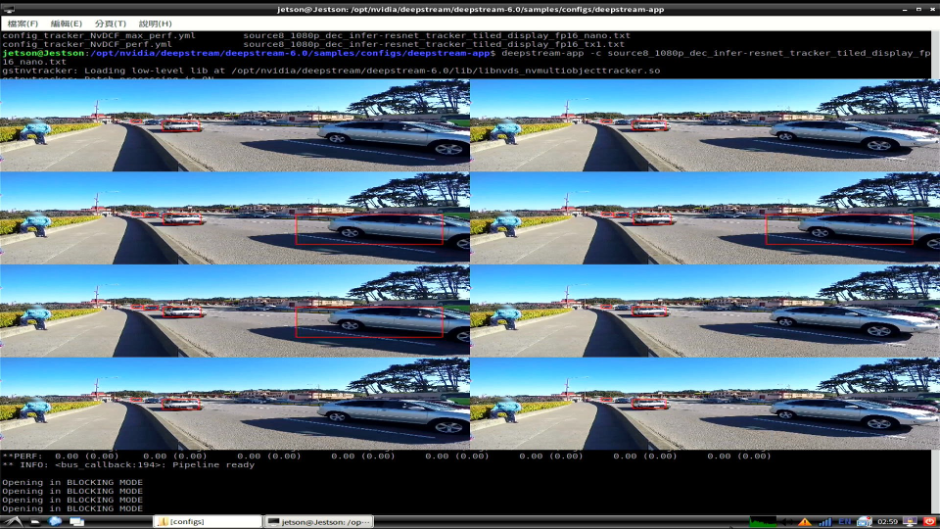
8畫面物件偵測追蹤
雖然這個範例是採用八個畫面同時輸入並做物件偵測,本範例可以偵測的對象為汽車(Car)、自行車(Bicycle)、人(Person)、路標(RoadSign)四個物件,由於沒有指定來源影像,所以八個影像來源都是使用內建的影片作為代表,所以才會出線上圖很奇怪的八個分隔畫面內容卻都相同,其實這是要模擬一次讀入八個不同影像的簡易示範。
接下來我們來修改設定檔,讓她能讀取2個USB影像並同時進行分析判斷,首先須使用超級使用者來開啟編譯文字程式:
sudo gedit
開啟後,選擇開啟上述的範例檔:source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
在區塊[tiled-display]中,修改總影像來源為1×2=2個影像來源:
[tiled-display]
enable=1
rows=1 #1列
columns=2 #2欄
width=1280
height=720
gpu-id=0
#(0): nvbuf-mem-default - Default memory allocated, specific to particular platform
#(1): nvbuf-mem-cuda-pinned - Allocate Pinned/Host cuda memory, applicable for Tesla
#(2): nvbuf-mem-cuda-device - Allocate Device cuda memory, applicable for Tesla
#(3): nvbuf-mem-cuda-unified - Allocate Unified cuda memory, applicable for Tesla
#(4): nvbuf-mem-surface-array - Allocate Surface Array memory, applicable for Jetson
nvbuf-memory-type=0
接下來就是指定影像來源,由於範例是使用一個檔案模擬8個輸入,因此只有[Source0]標籤,我們將[Source0]修改為USB裝置後的寫法後,並複製成2個來源,其寫法如下:
[source0]
enable=1 #是否啟用
type=1 #種類1(USB鏡頭)
camera-width=640 #影像寬度640
camera-height=480 #影像高度480
camera-fps-n=30 #最高fps 30
camera-fps-d=1 #最低fps 1
camera-v4l2-dev-node=1 #影像來源節點
[source1]
enable=1 #是否啟用
type=1 #種類1(USB鏡頭)
camera-width=640 #影像寬度640
camera-height=480 #影像高度480
camera-fps-n=30 #最高fps 30
camera-fps-d=1 #最低fps 1
camera-v4l2-dev-node=2 #影像來源節點
影像來源節點本例分別為1、2,而這個數字可以利用指令「ls /dev」來查詢,以筆者的案例來說,查詢結果找一下Video裝置即可發現該機器所安裝的影像裝置。
完成後,將檔案令存為:
source2_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
並一樣以deepstream-app指令來執行本檔案:
deepstream-app -c source2_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
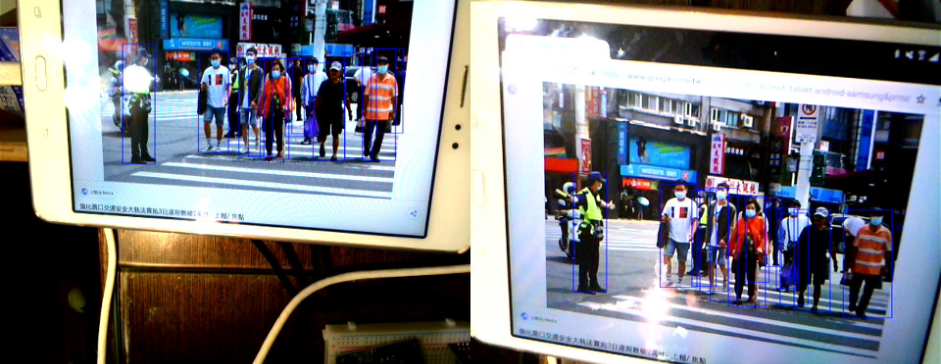
當程式載入完畢,即可看到兩個USB鏡頭看到的畫面,為了測試,筆者是使用平板電腦的畫面當作輸入,而辨識結果也相當優良,大部分的人都有被找到。
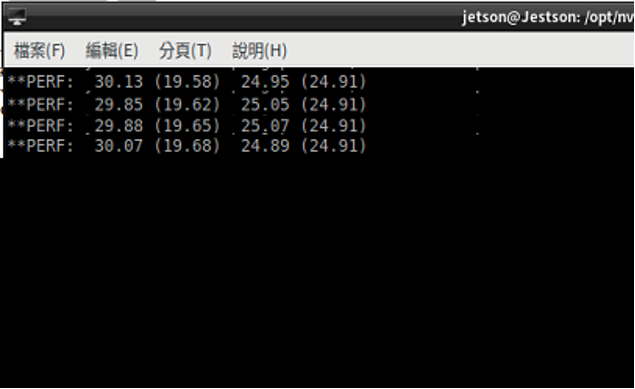
除此之外,在雙畫面的狀況下觀察效能fps的表現則相當優良,平均都在20左右。
鏡頭1:瞬時fps30.13,平均19.58
鏡頭2:瞬時fps24.95,平均24.91
小結
經由以上的測試,我們可以發現利用DeepStream可以將不同來源的影像加以合併,並同時進行檢測,減少影像重複辨識的時間,當使用環境需要同時辨識多個影像來源時,例如社區大樓可能一次包含多達數十個監視器,就可以利用deepstream功能進行影像合併並同時監測人員的動態。
此外,本次實測發現Jetson Nano是邊緣運算相當好的利器,在雙影像時還能有如此高性能的AI運算表現,實在令人驚豔,而Jetson Nano的功耗與體積都相當合適用於邊緣運算,且2G的版本售價不到2千元,也是能進行DeepStream的運算,對於使用者來說是一個非常好的選擇。
(責任編輯:謝涵如)

學歷:中山大學資訊管理研究所 博士
- 舊瓶裝新酒還是新瓶裝舊酒?Jetson Orin Super效能實測 - 2025/03/12
- 低成本空氣品質感測器 – 夏普 GP2Y10開箱實驗 - 2023/03/16
- 【ESP32專欄】ESP32 MQTT與深度睡眠 - 2022/06/20
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


