作者/圖片來源:CAVEDU 教育團隊
Jetson Inference是官方推出的體驗套件,它提供了三種最常見的AI應用於電腦視覺的類型,imagenet用於圖像辨識 ( Image Recognition )、detectNet用於物件辨識 ( Object Detection )、segNet用於語意分割。
API 的介紹再這裡,今天會想辦法盡量深入了解,以往的文章只有初步探討與實作,這次會帶到更多的細節,而我們今天都是使用 Python的程式執行。
建置環境
建置方法
我們跟著教學走會先遇到 Hello AI World,再這裡是教大家怎麼去建置 Jetson Inference的環境,有兩種使用方法:
- 使用Docker Container ( 30 分鐘 )
- 從來源建置 ( 1.5小時 )
通常為了教學順暢,會從頭建置燒錄SD卡,但有時映像檔過於龐大,搬運不易,所以使用 Docker來做相對而言會比較容易,如果想要從頭建置可以參考這邊。
今天我們使用Docker來運作,開始之前須要先將jetson Inference下載下來:
$ git clone --recursive https://github.com/dusty-nv/jetson-inference
$ cd jetson-inference
$ docker/run.sh
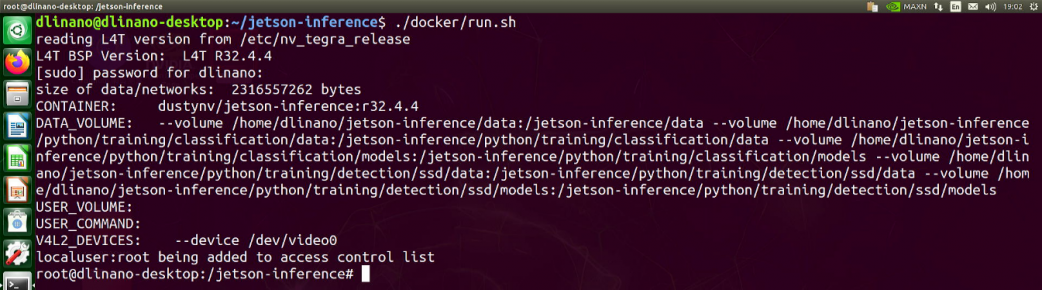
執行run.sh之後會自動根據你現在的JetPack版本去DockerHub抓取對應的容器 (Contrainer),並且如果你有使用攝影機的話這時候也會自動讀取。
Docker Container
關於Docker Container的敘述這邊簡單介紹一下,可以想像是一個獨立的虛擬環境,使用者,進入容器之後會與你原生系統的檔案區隔開來,但也是可以透過「掛接」的方式到容器中,像這次如果直接執行run.sh的話,會自動將jetson-inference/data掛載到docker的 /jetson-inference/build/aarch64/bin/ 當中,所以你可以在外部新增或刪除圖片。
下載DNN模型、安裝PyTorch
按下Enter開始建構環境,建置環境的過程中還有兩個要進行下載的動作,分別是「下載DNN模型」、「是下載PyTorch」,整個run的過程耗費時間相當久,但你也會注意到大部分都是因為要下載DNN模型的關係;基本上PyTorch會選擇Python3.6版本的,模型除非自己要其他的不然就是直接按確定就可以了,預設的情況下圖片分類會載兩個、物件辨識會載四個、語意分割會載六個模型。
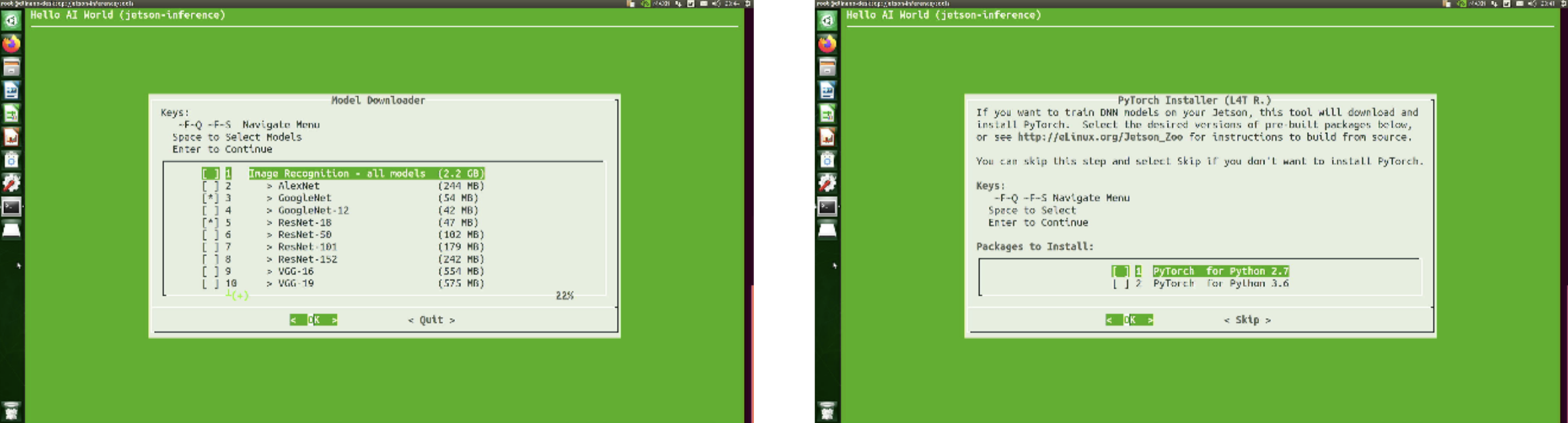
如果不小心按到Skip跟Quit可以再到jetson-inference/tools裡面去執行程式,就會看到跟剛剛一樣的畫面了:
$ cd tools
$ ./download-models.sh
$ ./install-pytorch.sh
順道一提,我發現一個很好玩的現象,如果我們直接在上一層來呼叫程式的話會出現不同的顏色,這或許是NVIDIA的小彩蛋?
小技巧分享,在Jetson Nano當中要安裝套件其實有時候蠻麻煩的,像是PyTorch跟Tensorflow都要去找特定版本安裝,如果你已經有Jetson-Inference又想要在原生環境中安裝PyTorch的話,可以直接執行jetson-inference/tools/install-pytorch.sh ( 不用進docker ),給他一段時間他就會在你的原生系統中安裝好PyTorch跟TorchVision囉!這其實跟從頭建置環境的原理一樣,可以注意到的地方是跟在docker當中不同他只讓我下載Python3.6版本的。
執行位置與方式
一般的執行方式
剛剛已經完成整個環境的建置了,接著需要先移動到運行程式的資料夾:
$ cd jetson-inference/build/aarch64/bin
$ ls

從上方的圖可以個別找到 imagenet、detectnet、segnet三個檔案,這三個是我們這次主要的運作程式,有.py代表是Python程式所撰寫的,而沒有附檔名的部分則是C++程式所撰寫,而這些都已經是執行檔了,所以都可以直接執行!
$ ./imagenet
$ ./imagenet.py
遠端的執行方式
這三個程式需要注意的地方如果使用「遠端」的方式要執行程式,需使用含有 “-console”的程式,不然會因為遠端軟體無法開啟圖片 ( OpenGL視窗 ) 而導致程式中斷,兩隻程式其實內容是一樣的但是在程式的前半段會去偵測是否有 console的字樣,有的話會開啟Headless模式。
$ cat imagenet.py
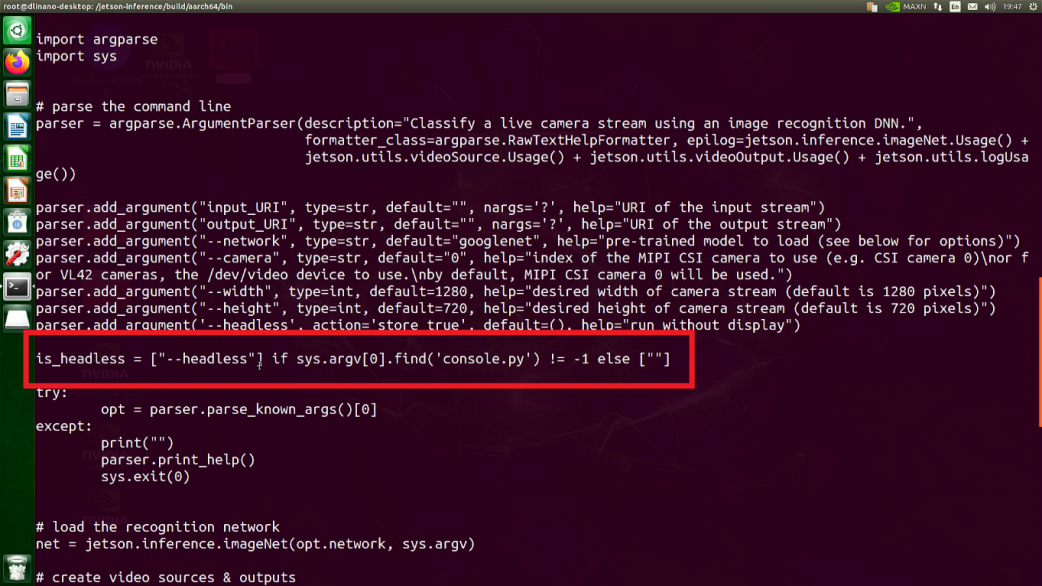
常用參數
這三個CV任務的外部參數皆是相同的,這邊講外部參數的意思是指在命令列執行程式的時候後面可以給定特定參數的數值,這樣的使用方法非常方便不用再開啟檔案調整;這邊三個電腦視覺任務常用的參數主要就是,要輸入到神經網路的內容是「檔案」、「影片」還是「即時影像」。
1.如果是檔案或影片的話我們可以直接填寫檔名,此外還會搭配一個輸出的檔名:
$ ./imagenet images/orange_0.jpg images/test/output_0.jpg
$ ./imagenet jellyfish.mkv images/test/jellyfish_resnet18.mkv
2.如果是即時影像,他們主要提供CSI (Camera Serial Interface)、V4L2 (Video4Linux)、RTP/RTSP (Real Time Streaming Protocol ) 三種協定,各別使用的方法是:
$ ./imagenet.py csi://0
# MIPI CSI camera
$ ./imagenet.py /dev/video0
# V4L2 camera
$ ./imagenet.py /dev/video0 output.mp4
# save to video file
除了三個電腦視覺的任務之外,他還有提供一些工具,比較常用的可能是給你檢查影像串流的 camera-viewer,因為影像來源有很多種,最常用的是CSI跟USB但也有網路串流的部分 (rtsp),或者說是圖片、影片都有可能,所以無法確保Jetson Inference能否開啟攝影機的話可以使用這個程式,其中參數 –camera 預設是0,是CSI攝影機的,但我這邊都使用USB網路攝影機所以需要額外宣告。
$ ./camera-viewer /dev/video0
其餘功能
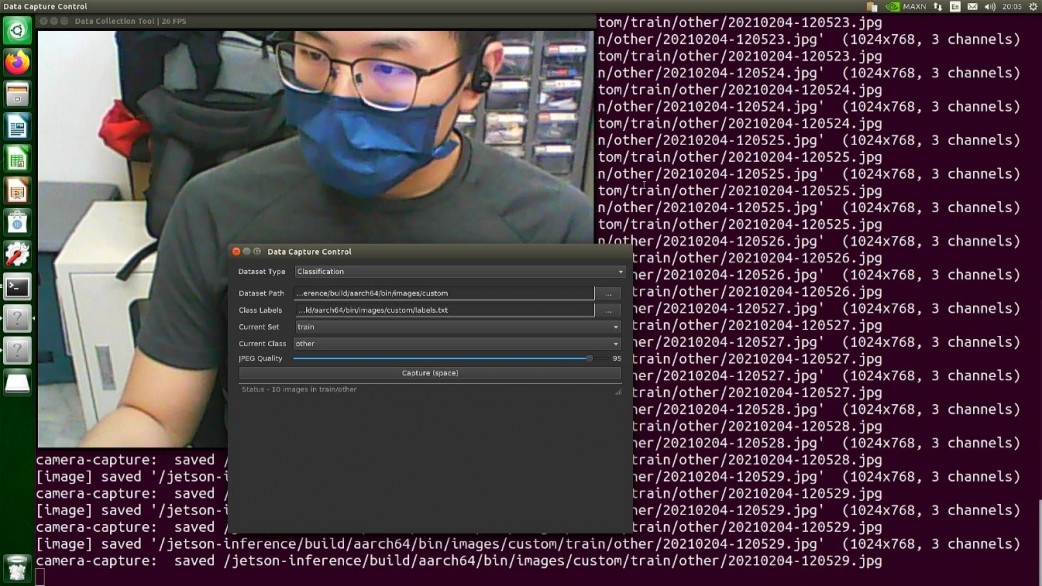
那也有提供一個程式可以蒐集資料,選擇儲存位置、選擇標籤檔,選擇類別,全部都選定之後便可以開始進行拍照。
$ ./caemra-capture /dev/video0
圖片分類Image Classification
執行 Imagenet
Jetson Inference提供的第一個範例是圖片分類,執行方法就如同上面介紹執行方法一樣,這邊我們使用 black_bear這張圖片,並且將推論完的圖片儲存在test當中:
$ cd build/aarch64/bin
$ ./imagenet.py ./images/black_bear.jpg ./images/test/black_bear.jpg
推論完會將輸出的資訊覆寫在圖片上:

如果要使用USB網路攝影機運行即時影像的話則是使用:
$ ./imagenet.py /dev/video0
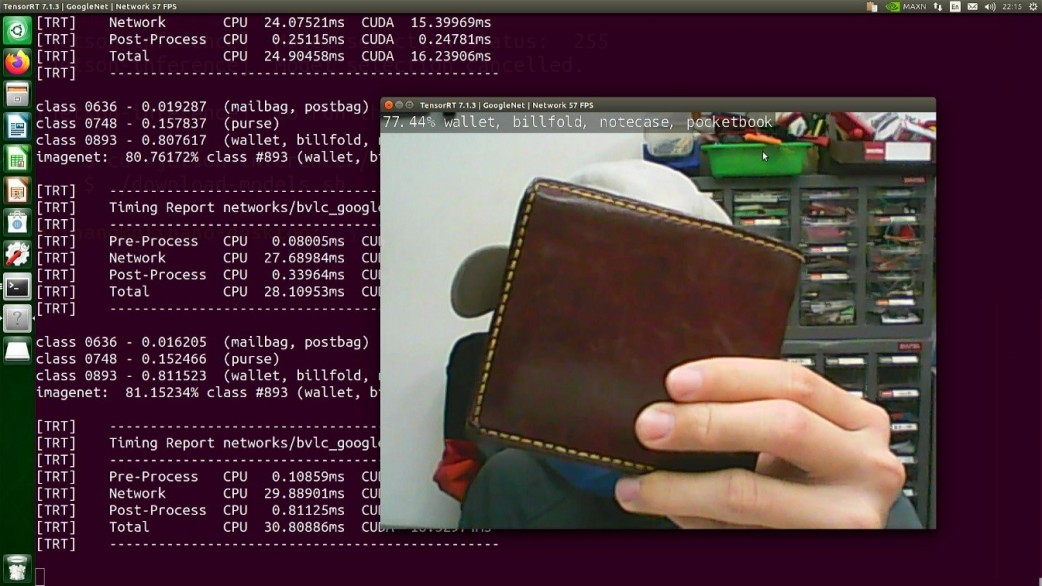
這邊也提供影像的DEMO:
可以辨識哪些種類?
神經網路模型可以辨識的類別會取決於當初訓練的數據集,Jetson-Inference在影像分類的部分採用的數據集是ILSVRC ImageNet,這個數據集擁有1000個常見的類別,所以基本上日常所見都可以被辨識出來,詳細的介紹連結如下:
可以使用哪些神經網路模型?
我們預設使用的神經網路模型是Googlenet,除此之外還可以使用不同的模型進行辨識,圖片分類可用的神經網路模型有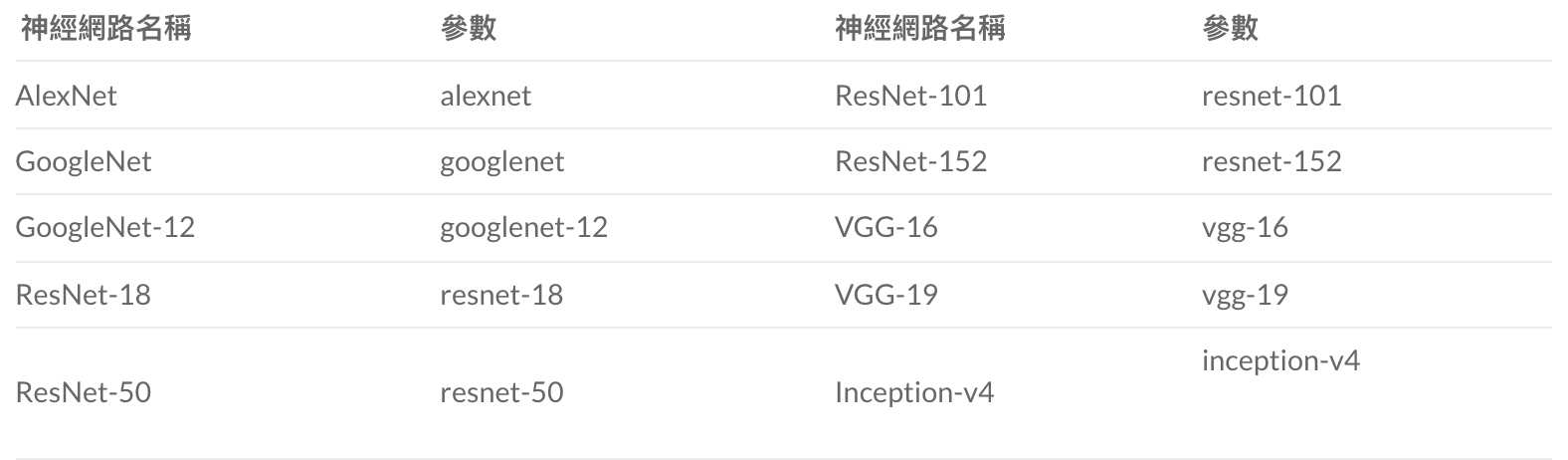
該如何使用其他神經網路模型?
三種電腦視覺任務都可以使用 –network來使其他模型:
$ ./imagenet.py --network=resnet-18 ./images/black_bear.jpg ./images/test/black_bear_resnet18.jpg

可以注意到準確度為94%與googlenet的98%有些許差距,可以嘗試變換不同的模型,觀察哪一個模型適合便是哪一種物件。
結語
基本的Jetson Inference已經介紹得差不多了,也帶大家認識了第一個電腦視覺任務 – 圖片分類,接下來也會帶大家體驗其他的電腦視覺任務。
*本文由RS components 贊助發表,轉載自DesignSpark部落格原文連結

- 【CAVEDU講堂】micro:bit V2使用TCS34725顏色感測器模組方法 - 2025/06/27
- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


