Google 於 2015 年所提出的人臉辨識系統 Facenet,由於演算原理容易理解且應用方便,成為目前最流行的臉部識別技術。本篇文章介紹 Facenet 的辨識模型和架構,並在 Keras 環境下實際測試。近年來透過深度學習以及 CNN,不但開啟了人臉辨識領域的新紀元,也讓傳統的 LBP、HOG 搭配支援向量機 SVM 的辨識方法顯得落伍。這些複雜的深度學習模型不但辨識率極高,而且能識別的人數級別與相片總量也都以萬級來計算,若侷限於學術的實驗情境下與人眼來比較,這成績已經遠遠抛開我們肉眼的能力了。
輸出量化特徵值,而非輸出分類結果
下圖是標準的臉部辨識作業流程,首先 1.針對輸入的影片或相片進行臉孔偵測 Face Detection,接著 2.進行臉部校正對齊 Face Alignment,然後開始 3.依據不同的算法來取得臉部的特徵 Feature Extraction,有了特徵,傳統的作法是 4.據此來計算與匹配不同的臉孔圖片,最後 5.透過 softmax 輸出至各分類結果,但 Facenet 則不然,模型所輸出的是該臉孔特徵的歐式距離總和。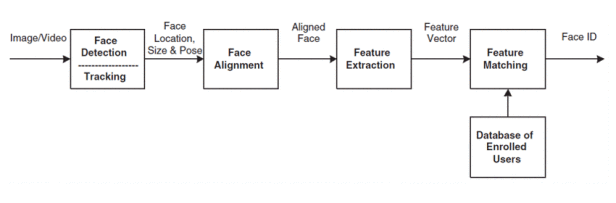
臉部辨識作業流程
- Face Verification 驗証是否為同一人
- Face Identification 辨識身份或姓名
- Face Cluster 相似的人分類在一起
- Face Search 搜索相似的人
- Face Tracking 跟蹤特定的人臉
Triplet Loss:模型的核心
模型需要取得圖片不同的特徵並映射到歐幾里德的空間中(即計算特徵間的歐氏距離),所採用的作法是 Triplet loss,如下圖原論文中的圖示說明。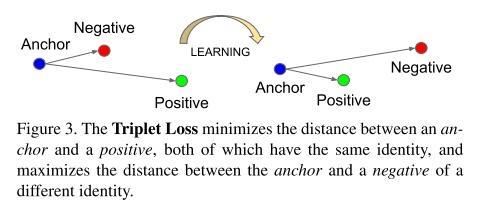
Triplet loss 的運作模式
Facenet 架構
Facenet 主要由以下步驟所組成: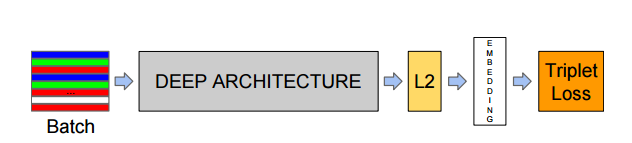
Facenet 的組成步驟
- Batch → Batch input layer 將臉孔圖片輸入模型,這些圖片需已經 Facial alignment及resize處理。原開發者使用 MTCNN 來進行臉孔偵測及校準
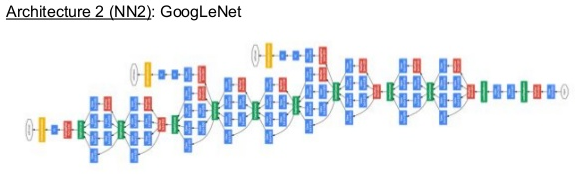
- Deep Architecture → 即用於特徵學習的 CNN 架構,具彈性可以採用不同的網路。剛推出時使用 Zeiler&Fergus 架構和 Google的Inception v1,今年最新版改為 Inception ResNet-v2。不同架構對於辨識結果有顯著的影響,如下圖為使用不同的 network model 的辨識成績差異。
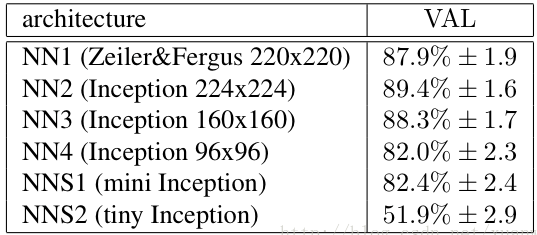
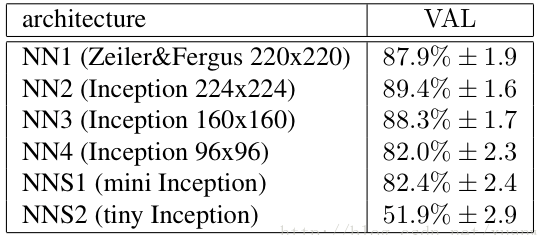
使用不同的 network model 的辨識成績差異
- L2 → L2 normalization 歸一化,讓資料能對應到一個超平面。
- Embedding → 經過 CNN 模型以及 L2 歸一化後生成的特徵向量
- Triplet Loss → 從向量中取得一個 embedding 函數 f(x),讓相同孔之間的特徵距離要盡可能的小,而不同孔之間的特徵距離要盡可能的大。
在 Keras 環境使用 Facenet
Facenet 使用 Tensorflow 開發,不過已有很多有心人士另外撰寫為 Cafffe 或 Keras 等版本,如果我們想要在 Keras 環境中使用,推薦可以採用 keras-facenet。作者提供了一個預訓練好的 Keras model 可直接下載使用。當然也可以下載其它的預訓練 models,再透過作者提供的轉檔程式 tf_to_keras.ipynb 轉為 .h5 model 來使用。下載預訓練模型
作者提供的預訓練模型是使用 MS-Celeb-1M dataset 訓練,用於一般環境的辨識來說效果已相當不錯,並不一定要自行搜集臉孔資料來訓練。MS-Celeb-1M 是微軟於 2016 年 6 月所公開發佈的人臉資料庫,包含 100 萬個名人總共約 800 多萬張人臉影像。 下面說明如何在使用 Keras 版本的 Facenet:程式說明
我改編了作者用於示範的 .pynb 程式,可方便驗證 compares 列表中相片的人與 valid 相片中的人,其差異度為多少。程式碼
| import numpy as np import os, time import cv2 from skimage.transform import resize from scipy.spatial import distance from keras.models import load_model #驗證 compares 列表中相片的人與 valid 相片中的人 valid = “200127/200127_1.jpg” compares = [“200002/200002_1.jpg”, “200127/200127_1″, “200127/o.jpg” ] #用 OpenCV 的 Cascade classifier 來偵測臉部,不一定跟 Facenet 一樣要用 MTCNN。 cascade_path = ‘haarcascade_frontalface_default.xml’ #我們的人像相片都放置於 validPicPath validPicPath = ‘members/’ #此版 Facenet model 需要的相片尺寸為 160×160 image_size = 160 #使用 MS-Celeb-1M dataset pretrained 好的 Keras model model_path = ‘model/facenet_keras.h5’ model = load_model(model_path) #———————————————————— #圖像白化(whitening)可用於對過度曝光或低曝光的圖片進行處理,處理的方式就是改變圖像的平均像素值為 0 ,改變圖像的方差為單位方差 1。 def prewhiten(x): if x.ndim == 4: axis = (1, 2, 3) size = x[0].size elif x.ndim == 3: axis = (0, 1, 2) size = x.size else: raise ValueError(‘Dimension should be 3 or 4’) mean = np.mean(x, axis=axis, keepdims=True) std = np.std(x, axis=axis, keepdims=True) std_adj = np.maximum(std, 1.0/np.sqrt(size)) y = (x – mean) / std_adj return y #使用 L1 或 L2 標準化圖像,可強化其特徵。 def l2_normalize(x, axis=-1, epsilon=1e-10): output = x / np.sqrt(np.maximum(np.sum(np.square(x), axis=axis, keepdims=True), epsilon)) return output #偵測並取得臉孔 area,接著再 resize 為模型要求的尺寸(下方例子並未作alignment) def align_image(img, margin): cascade = cv2.CascadeClassifier(cascade_path) faces = cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=3) if(len(faces)>0): (x, y, w, h) = faces[0] face = img[y:y+h, x:x+w] faceMargin = np.zeros((h+margin*2, w+margin*2, 3), dtype = “uint8″) faceMargin[margin:margin+h, margin:margin+w] = face cv2.imwrite(str(time.time())+”.jpgceMargin) aligned = resize(faceMargin, (image_size, image_size), mode=’reflect’) cv2.imwrite(str(time.time())+”_aligned.jpgigned) return aligned else: return None #圖像的預處理(即前述的幾項步驟) def preProcess(img): whitenImg = prewhiten(img) whitenImg = whitenImg[np.newaxis, :] return whitenImg #————————————————- imgValid = validPicPath + valid aligned = align_image(cv2.imread(imgValid), 6) if(aligned is None): print(“Cannot find any face in image: {}”.format(imgValid)) else: faceImg = preProcess(aligned) #–> model 會輸出 128 維度的臉孔特徵向量,接著我們將它們合併並進行 L2 正規化。Z embs_valid = l2_normalize(np.concatenate(model.predict(faceImg))) #同上方的 valid 圖片,依序取得各圖片人臉的臉孔特徵向量,再與 valid 進行歐氏距離計算。 for member in compares: img_file = validPicPath + member aligned = align_image(cv2.imread(img_file), 6) if(aligned is not None): faceImg = preProcess(aligned) embs = l2_normalize(np.concatenate(model.predict(faceImg))) distanceNum = distance.euclidean(embs_valid, embs) print(“Diff with {} is {}”.format(member, distanceNum)) |
程式測試
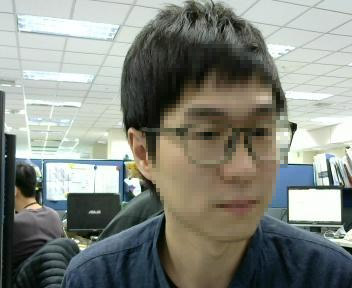
我們將一些不同人的相片放置於 members 目錄下,目錄名稱為其人名或代表工號,接著來測試看看。 正面臉孔: |
 |
1.082138 |
 |
0.493925 |
 |
||
| 1.0013418 | 1.0399750 | 0.7001376 |
 |
 |
 |
 |
|
| 0.36971601843833923 | 0.9557983875274658 |
 |
 |
| 0.7647050619125366 | 0.6167847514152527 |
|
|
使用一張側面的臉孔來預測其它角度的臉孔,果然差異值最小的那兩張與上方的確是同一人沒錯。
小結
本文簡單的介紹了 Facenet,並且示範如何於 Keras framework 使用。dataset 並非自行訓練而是使用微軟 MS-Celeb-1M dataset,雖然如此,單張相片的 verify 能力已相當令人驚豔,如果希望應用在公司內部並提昇到更高的辨識率,建議應考慮加入自行搜集的相片重新訓練以製作更符合公司人員的 model。 另外,如果在一般的 PC 上執行,您會發現 Facenet 速度不是很快速,此時可以考慮改為在 GPU 上執行,在迅速的辨識速度下,可作出各種有趣且實用的人臉辨識專案。 (本文經作者同意轉載自CH.TSENG部落格、原文連結;責任編輯:葉于甄)
人到中年就像沒對準的描圖紙,一點一點的錯開,我只能當個Maker來使它復位。
Latest posts by 曾 成訓 (see all)
- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


