作者:許哲豪 Jack
這兩年人工智慧當道,無人自動駕駛汽車技術也隨之興起,我想超過四十歲的大叔們心中最完美的自駕車莫過於 1980 年代電視影集「霹靂遊俠」中李麥克開的那台「伙計」了。
「伙計」擁有高度人工智慧,不但可以自動駕駛,遇到狀況也會自動閃避,還可以輕鬆和人對話解決各種問題,李麥克拿起手表還可呼叫「伙計」開到指定地方,簡直就是現代人工智慧自駕車及語音助理的最佳範本!
不過自駕車這項技術聽起來就很難,那 Maker 們有沒有機會自己土砲一台呢?

1980 年代經典電視影集「霹靂遊俠」李麥克和人工智慧自駕車「伙計」(圖片來源)
說起自駕車(Autonomous Car)或是先進駕駛輔助系統(Advanced Driver Assistance Systems, ADAS)主要都是希望車輛在沒有人為操作下即可自動導航(GPS 衛星定位、路線規畫)、避障(閃避車輛、行人或異物)及環境感測(看懂燈號、路標),同時將使用者安全地帶到目的地。目前各國爭相投入研發資源,大到無人公車、卡車、貨櫃車,小到無人計程車、送貨車、電動輪椅甚至無人農業耕耘機、採收機,就是不想錯過新一波的交通革命。
在自駕車眾多技術中最不可缺少的一項就是電腦視覺技術,但要搞懂一大堆數學、人工智慧理論、程式撰寫方式、系統框架和硬體架構,還得懂得如何建立資料集、訓練及優化(加速)模型,這可就難倒大多數人了,難道就不能「快快樂樂學 AI」,站在巨人的肩膀上看世界嗎?
英特爾(Intel)為了讓大家能夠快速入門,因此提出了一項免費、跨硬體(CPU、 GPU、FPGA、ASIC)的開放電腦視覺推論及神經網路(深度學習)優化工具包「OpenVINO」(Open Visual Inference & Neural Network Optimization Toolkit),同時提供很多預先訓諫及優化好的神經網路模型可供大家直接使用。
影像辨識目標
在進入主題之前,首先要先認識一下影像辨識的常見項目及定義,如下圖所示:
A. 影像分類:一張影像原則上只能被分到一個類別,所以影像中最好只有一個主要物件。若影像中出現多個物件,那分類時則可能出現多個分類結果,同時會給出每個分類的不同機率,此時誤分類的可能性就會大大提昇。
B. 物件定位:一張影像中可同時出現多個相同或不同物件,大小不据,辨識後會對每個物件產生一個邊界框(Bounding Box),如此即可獲得較為準確的物件位置(座標)及尺寸(邊界框長寬)。
C. 語義分割:是一種像素級分類,意思就是每個像素都只會被歸到某一分類,如此就可取得接近物件真實邊界(Edge)。但缺點是多個相同物件類型的像素都會被分到同一類,當物件太靠近或部份重疊時就不易分清楚共有多少物件。
D. 實例分割:這也是一種像素級的分類,和語義分割的差別是相同類型的不同物件所屬像素就會被區分成不同分類(顏色),包括物件有部份重疊時,如此就能更正確判別影像中的內容。
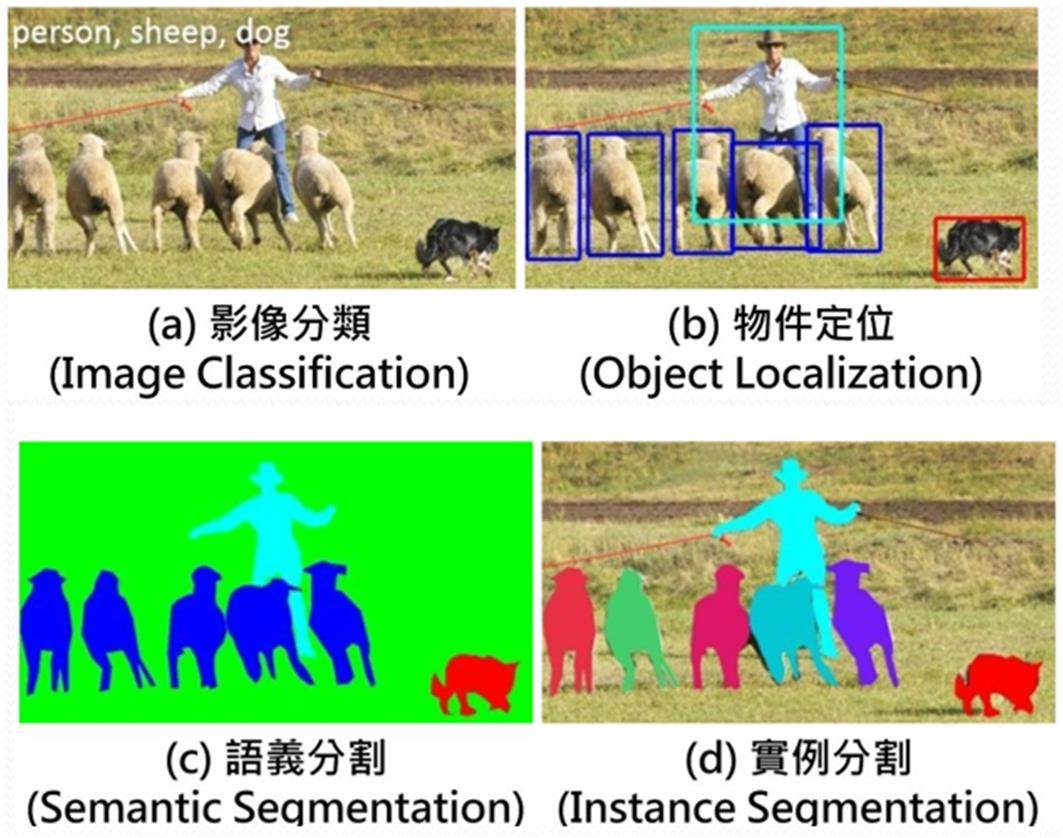
影像辨識的常見項目(圖片來源)
以上視覺辨識難度依序遞增,同時在樣本訓練及推論時間也隨之巨幅成長。在自駕車領域較常用到「物件定位」,比方說找出前方車輛、行人、號誌位置,但當場景較複雜(如市區)時,同一影像中物件數量大增,且邊界框大量、大面積重疊,可能會影響辨識結果,因此更需要像語義分割及實例分割這類像素級分類。
不過由於實例分割的計算量大過語義分割許多,且現實中不需要分的如此仔細,所以大部份僅採用語義分割來偵測場景中的多種物件,比方說道路、人行道、地面標線、背景、天空、植物、建物等等,如下圖所示:

語義分割應用於自駕車,(a)僅道路,(b)道路、車輛、路標等多物件辨識(圖片來源)
Intel OpenVINO簡介
玩過「電腦視覺」的朋友肯定對開源工具「OpenCV」不會陌生,這個強調不要自己造輪子的開源視覺函式庫,是英特爾(Intel)於西元 2000 年釋出的,不管是個人或商業用途皆可任意使用,不必付任何費用。OpenCV 除了原有對 Intel CPU 加速函式庫 IPP (Integrated Performance Primitives)、 TBB (Threading Building Blocks)的支援外,發展至今已陸續整合進許多繪圖晶片(GPU)加速計算的平台,如 OpenVX、OpenCL、CUDA等。
近年來,由於深度學習大量應用於電腦視覺,自 OpenCV 3.0 版後就加入 DNN (Deep Neural Network)模組,3.2 版更是加入深度學習常用的 Caffe 框架及 YOLO 物件定位模組。今(2018)年 Intel更是推出開放(免費)電腦視覺推論及神經網路(深度學習)優化工具包「OpenVINO」(Open Visual Inference & Neural Network Optimization Toolkit)。
OpenVINO整合了OpenCV、 OpenVX、OpenCL 等開源軟體工具並支援自家 CPU、 GPU、FPGA、ASIC (IPU、VPU)等硬體加速晶片,更可支援 Windows、Liunx (Ubuntu、CentOS)等作業系統,更可支援常見 Caffe、TensorFlow、Mxnet、ONNX 等深度學習框架所訓練好的模型及參數。同時,兼顧傳統電腦視覺和深度學習計算,從此不用再糾結到底要選那一種組合來完成電腦視覺系統了。
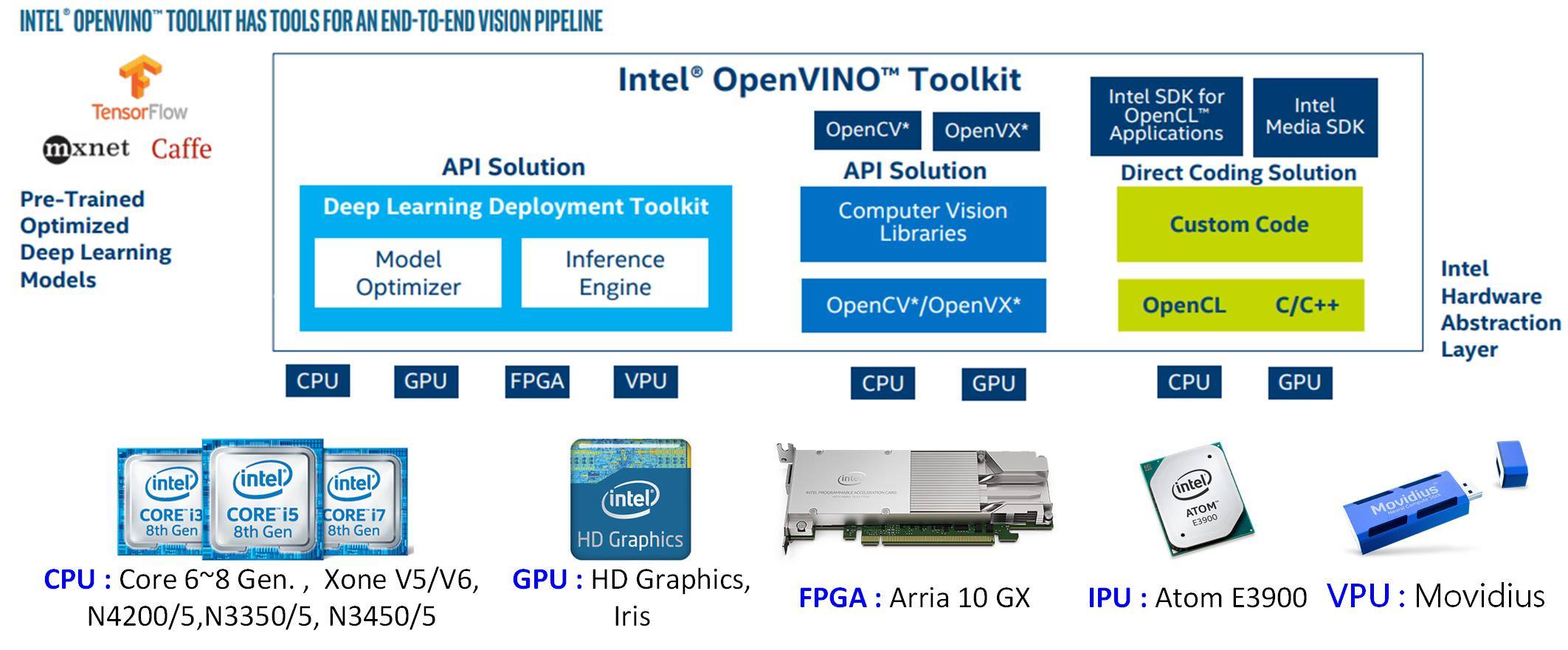
INTEL OpenVINO 架構及支援硬體加速裝置(圖片來源)
OpenVINO 主要是用來推論用的,特定模型的參數必須在其它框架(TensorFlow、Cafee、Mxnet)下訓練好才可使用。OpenVINO 除了可提供硬體加速外,更提供模型優化器(Model Optimizer)功能,可協助去除已訓練好的模型中的冗餘參數,並可將 32bits 浮點數的參數降階,以犧牲數個百分點正確率來換取推論速度提升數十倍到百倍。
優化後,產出二個中間表示(Intermediate Representation、IR)檔案(*.bin, *.xml),再交給推論引擎(Inference Engine)依指定的加速硬體(CPU、GPU、FPGA、ASIC)進行推論,如下圖所示:
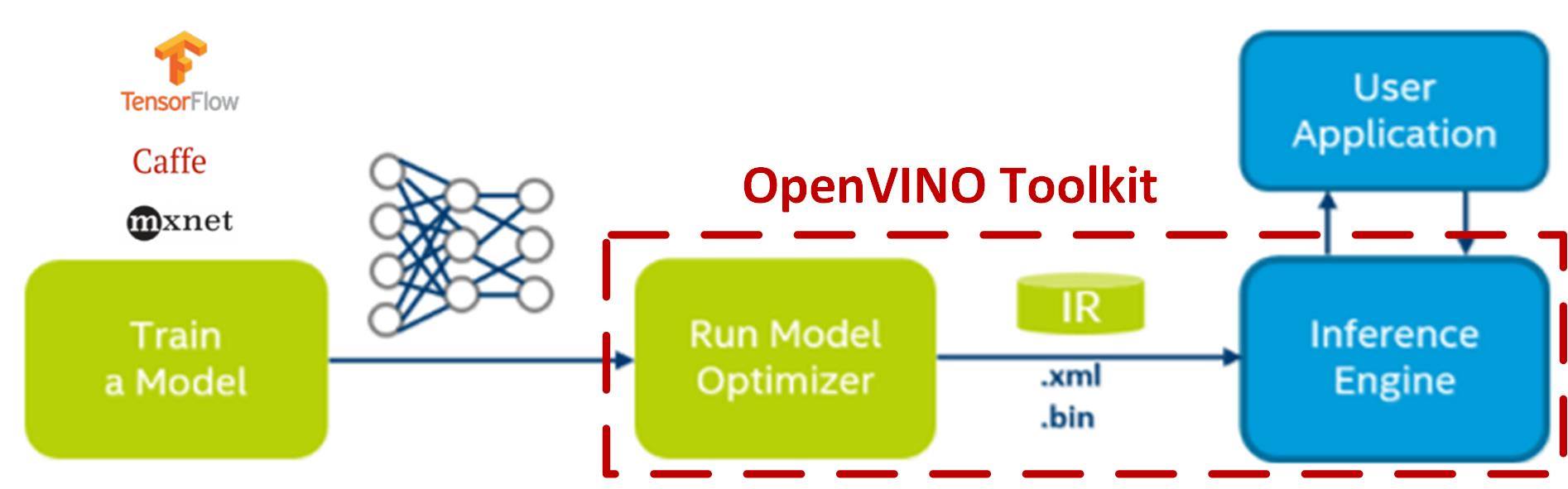
OpenVINO 模型優化及推論引擎架構(圖片來源)
影像語義分割原理
在 OpenVINO 中提供了多種預訓練及優化好的深度學習模型,包括影像分類(AlexNet、GooLeNet、VGG、SqueezeNet、RestNet)、物件定位(SSD、Tiny YOLO)及一種類似全卷積神經網路(Fully Convolutional Networks、FCN)的語義分割模型(like FCN-8s),接下來就簡單說明 FCN 的運作原理。
一般傳統用於影像分類的卷積神經網路(Convolution Neural Network, CNN)是經過多次卷積層(Convolution Layer)取出特徵圖(Feature Map)加上池化層(Pooling Layer)令影像縮小一半後,再經過全連結層(Fully Connection Layer)產生不同分類的機率,最後再找出機率最高的分類當作輸出結果(如下圖上半部)。

影像分類(CNN)與語義分割(FCN)深度學習模型概念(圖片來源)
因為全連結層把所有的空間資訊全部壓縮掉,因此無法了解到每個像素被分到那個類別。為了,能得到每個像素的分類(語義分割),Jonathan Long 在 2015 年提出 FCN論文解決了這個問題。主要方式是把全連結層也改用卷積層,產出和原影像尺寸相同的熱力圖(Heatmap),用以表示每個像素屬於某一類的機率有多高。
如同上圖所顯示,最後會產出 1000 千張熱力圖,接著再對 1000 張圖相同位置像素計算出最大機率的分類,最後將所有分類結果組成一張新的圖即為語義分割結果圖。
原始影像(image)經多次卷積(conv)及池化(pool),到了 pool5 時影像尺寸已到了原尺寸的 1/32,此時再經二次卷積(conv6, conv7)後,最後將影像上採樣(Upsample)放大 32 倍,即可得語義分割結果圖 FCN-32s(如下圖所示)。這樣的結果非常粗糙,為了得到更精細結果,可把 conv7 結果放大 2 倍加上 pool4 後再放大 16 倍,就可得到更精細的結果圖 FCN-16s。
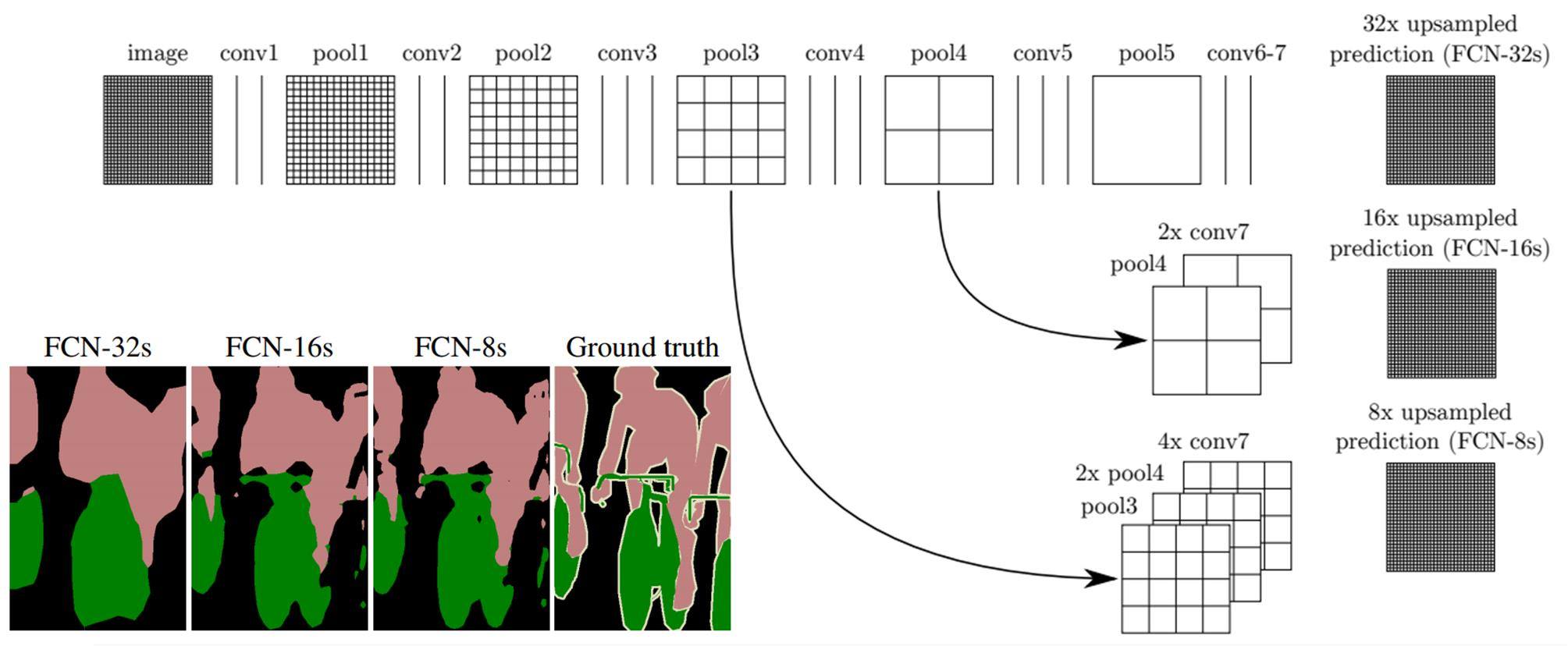
FCN 不同上採樣語義分割結果(圖片來源)
同理,將高(pool3)、中(2 倍 pool4)、低(4 倍 conv7)解析度的內容加在一起,再放大就可得到 FCN-8s 更高精度的語義分割圖。雖然 FCN 得到的結果和真實內容(Ground truth)分割正確度還有滿大的差距,但此方法卻是開創以卷積神經網路達成語義分割最具代表性的算法,同時也是電腦視覺最頂級研討會 CVPR 2015 最佳論文。這幾年陸續有多種算法被推出,但大部份仍是仿效此種多重解析度整合方式改良而得。
OpenVINO 安裝執行
接下就開始說明如何以 Intel 電腦視覺推論及神經網路(深度學習)優化工具包「OpenVINO」土砲自駕車的視覺系統。首先到 OpenVINO 官網,如下圖所示,按下左上角黃色按鈕,依所需的作業系統(Windows, Liunx)下載工作包並依指示將開發環境(Visual Studio 2015/2017, GCC)安裝完成。
雖然官方指定要 Windows 10 64bit, Intel Core 6 ~ 8 代 CPU 才能執行,經實測在 Windows 7 64bit/Intel Core i5 480M (i5 第一代筆電用 CPU)、Visual Studio 2017 (含 MSBuild)環境下還是可以順利編譯及執行。
以 Windows + Visual Studio2017 組合安裝為例:
可參考官網提供的網址,預設軟體開發工具包(SDK)會安裝在 C:\Intel 路徑下,而主要開發工具會安裝在\computer_vision_sdk_XXXX.X.XXX\deployment_tools\ (XXXX 表示版本),其中較重要的內容包括以下四點:
- \computer_vision_algorithms 傳統視覺算法
- \inference_engine 推論引擎及相關範例程式
- \intel_models 預先訓練模型
- \ model_optimizer 模型優化器
安裝完成後,開啟\inference_engine\samples\build_2017\ALL_BUILD.vcxproj,經編譯後即可在\inference_engine\bin\intel64\Release 路徑下找到所有編譯好的範例執行檔。
Intel OpenVINO 官網畫面(圖片來源)
接著可在 \inference_engine\samples\segmentation_sample 路徑下找到本次土砲自駕車的視覺系統所需用到的範例程式,而程式主要工作內容包括下面步驟:
- 載入推論引擎插件(Plugin)
- 讀取由模型優化產出的中間檔(*.xml, *.bin)
- 配置輸入和輸出內容
- 載入模型給插件
- 產生推論需求
- 準備輸入
- 進行推論
- 處理輸出
若不想了解程式碼及工作細節的人亦可直接拿來用,只要準備好輸入的影像即可得到已做好語義分割的結果影像。目前 OpenVINO 提供二種預先訓練及優化好的語義分割模型,分別為 \deployment_tools \intel_models\ 路徑下的 semantic-segmentation-adas-0001 (20 類)和road-segmentation-adas-0001 (4 類)。
前者提供較多的分類包括道路、人行道、建物、牆壁、籬笆、電線桿、紅綠燈、交通號誌、植物、地面、天空、行人、騎士、汽車、卡車、公車、列車、機車、自行車、自己的車頭等 20 類;後者僅分道路、人行道、標線和背景共 4 類;單純使用 CPU 時,前者推論時間約為後者十倍左右。
使用時主要有兩個參數,-i 輸入影像名稱,-m 模型名稱,指定時須包含完整路徑。另外預設是使用 CPU 計算,所以只接受 32bit 浮點數(FP32)而不接受 16bit 浮點數(FP16)。輸入影像尺寸不据,而在 20 類語義分割時輸出影像尺寸為 2048×1024 像素,而 4 分類時為 896×512 像素。輸出檔名固定為 out_0.bmp(如下圖所示)。
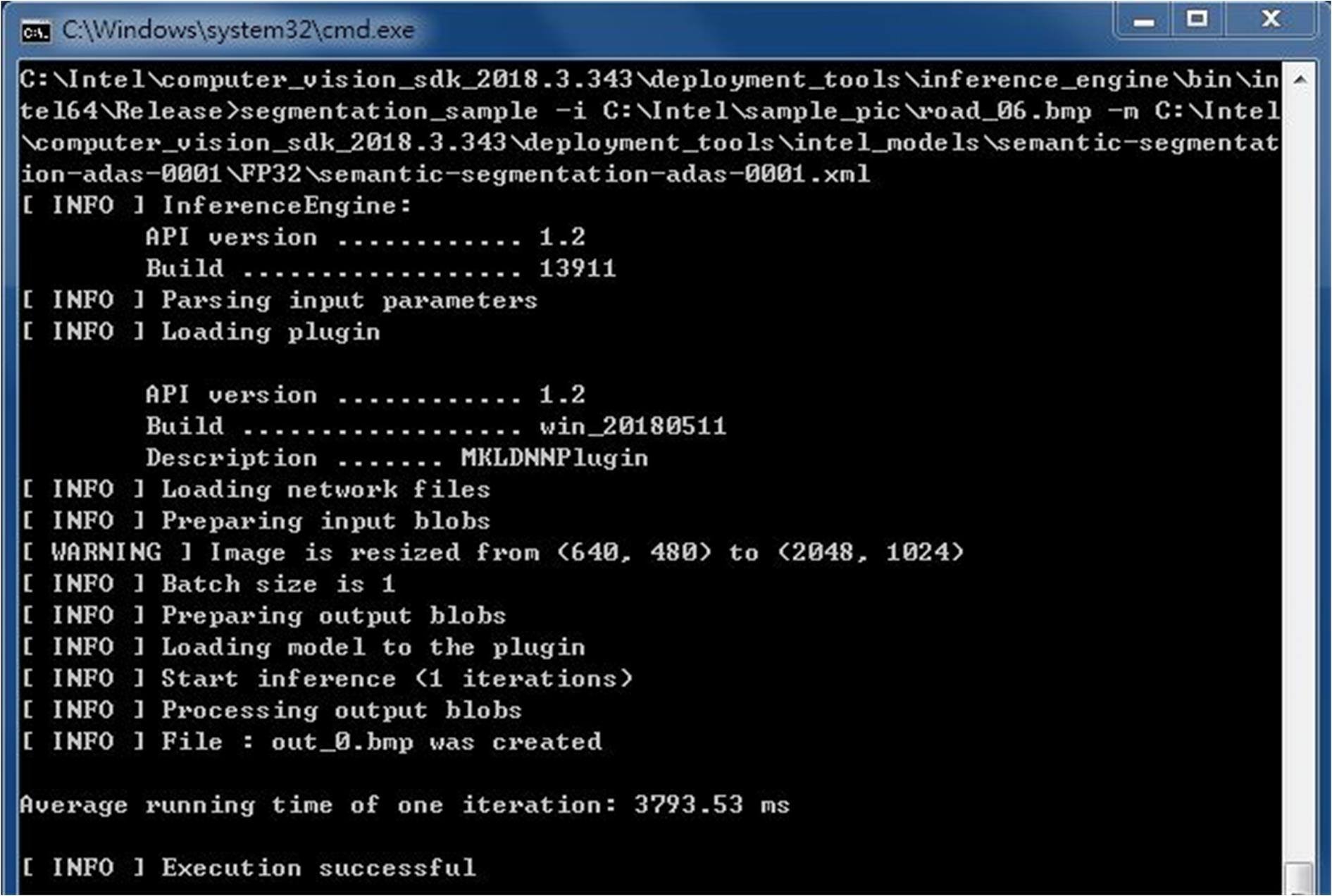
自駕車影像語義分割範例執行結果(圖片來源:Jack 提供)
由於 CPU 計算時會受作業系統是否忙碌影響,所以同一張影像計算每次推論時間都會有所不同。當在 Windows 7 64bit/Intel Core i5 480M 2.6GHz CPU/2GB RAM 環境下測試時,20 分類推論時間大約在 3.7~4.3 秒,4 分類則在 0.3~0.4 秒左右,推論時間和影像內容複雜度無關。後續若改成高階 CPU 或 GPU 後相信推論時間肯定能大幅縮短。完整執行範例指令如下所示。
20 類語義分割指令:
segmentation_sample -i C:\Intel\sample_pic\input_image.bmp -m C:\Intel\computer_vision_sdk_XXXX.X.XXX\deployment_tools\intel_models\semantic-segmentation-adas-0001\FP32\semantic-segmentation-adas-0001.xml
4 類語義分割指令:
segmentation_sample -i C:\Intel\sample_pic\input_image.bmp -m C:\Intel\computer_vision_sdk_ XXXX.X.XXX\deployment_tools\intel_models\road-segmentation-adas-0001\FP32\road-segmentation-adas-0001.xml
OpenVINO 實例應用
接著,在網路上隨機收集一些道路影像,包括白天、晚上、郊區、市區、遠近鏡頭等,並用二種模型進行測試影像語義分割,其結果如下圖所示,左為原始影像,中為 20 分類,右為 4 分類。從結果來看,大致還分得還不錯,像(b)中圖汽車和卡車重疊及自身車頭,(c)的道路和人行道雖然顏色及紋理很像,都能分得很好。不過晚上的影像就有些小誤判,可能和影像過暗及物件過小影響。

自駕車影像語義分割測試結果。左為原始影像,中為 20 分類,右為 4 分類(圖片來源:Jack 提供)
為了進一步了解這兩種模型對類似道路場景是否能適用,另外收集了公園步道(g)、賣場彎道(h)、客廳走道(i)、百貨公司走道(j)、候機室走道(k)進行測試(結果如下圖所示)。由測試結果來看,在 20 分類時(g)的天空、地面、植物、建物算是正確分辨,而紅黑磚路則被當成人行道(淺紫色),(h)、(k)勉強能分出道路(深紫色), (i)、(j)則把道路當成人行道(淺紫色)也勉強可以算對,(j)、(k)中的行人(暗紅色)都有正確被辨別出,但(i)的沙發則被誤判為行人和汽車(藍色)。
在 4 分類時(g)、(h)、(k)比較能分辨出道路(淺紫色),(h)甚至還能正確認出地面標線(暗藍色),而(i)、(j)則是完全無法辨識,全部都被當成背景(深紫色)。所以當測試影像是室內或非正常道路時,誤判率明顯提高,歸究其原因應該是訓練的資料集中並沒有這些類型的影像,加上室內光滑地面有大量反光及擺放大量物件造成影響。若想應用這些模型在室內場景,則需要另外大量收集相關影像重新標註後再重新訓練,才能讓正確率有所提升。

非標準道路影像語義分割測試結果。左為原始影像,中為 20 分類,右為 4 分類(圖片來源:Jack 提供)
小結
Intel 所提供的開放(免費)電腦視覺推論及神經網路(深度學習)優化工具包「OpenVINO」讓不懂電腦視覺和深度學習原理的小白可以在很短的時間上手,不必擔心如何建置開發平台、選擇深度學習框架、訓練及優化模型和硬體加速等問題,只需利用預先訓練及優化過的語義分割模型,瞬間就可土砲出一組看起來很專業的自駕車視覺分析系統。
若覺得執行效能不佳,未來還可輕鬆從 CPU 移植到 GPU、FPGA 甚至 Maker 最愛的 Movidius 神經計算棒(VPU),實在讓使用者方便許多,而其它更多更方便的功能就有賴大家親自體驗一下囉!
Click here to learn more
(責任編輯:賴佩萱)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄06】關鍵字偵測 - 2026/07/17
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


