Google推出網頁版 LLM 推論API,使在瀏覽器中運行小型大型語言模型(LLMs)成為可能。此一Web API技術的特色通過 WebAssembly 和 WebGPU 效率地利用設備端的 GPU 來加速運算,克服了記憶體限制,甚至可以在瀏覽器中運行更大的模型,例如Gemma 1.1 7B。這個 8.6GB 檔案包含 70 億個(7B+)參數,比之前在瀏覽器中運行的任何模型大幾倍,其回應的品質改進也相應顯著,同時也保障了用戶的隱私。

大型語言模型 (LLM) 為人類與電腦和設備互動提供了新的方式,這些模型大多運行在資料中心的強大伺服器上,使用者得透過網路連線傳送請求(如ChatGPT)和等待回應。為了節省雲端服務的開銷,並提升企業或個人的用戶穩私,LLM的應用正走向設備端運作的Edge AI架構發展,甚至要求能做到離線使用。然而,這樣做是對機器學習基礎設施的真正壓力測試:即使是「小型」LLM通常也有數十億個參數和以GB為單位的容量,這很容易使本地端的記憶體和運算能力過載。
針對此需求與挑戰,今年5月Google AI Edge 的 MediaPipe 推出了新的實驗性跨平台 LLM 推論(Inference)API – MediaPipe LLM Inference API ,可利用本地端裝置的 GPU 跨 Android、iOS 和 Web 運行小型 LLM,並獲得極佳的效能。在發佈時,它能夠完全在裝置上運行四個公開可用的 LLM: Gemma、Phi 2、Falcon和 Stable LM。這些模型的大小範圍為 1 到 30 億個參數。
此一LLM推論API,一開始以Android及iOS等運算資源較強大的行動裝置為目標,接著才鎖定一般性的瀏覽器運算,此階段面臨的挑戰,除了設備端的運算能力外,很大的挑戰來自於本地端不同類型記憶體的限制,以及可以適應多種模型的單一Library,和能夠在Google多個產品中對.tflite格式的支援。
目前該研究團隊已有不錯的成果,並推出網頁版 LLM 推論API,使在瀏覽器中運行小型大型語言模型(LLMs)成為可能。在Google Research的這篇Blog文章中指出,通過 WebAssembly 和 WebGPU 技術,可有效率地利用設備端的 GPU 來加速運算,克服了記憶體限制,甚至可以在瀏覽器中運行更大的模型,例如Gemma 1.1 7B。這個 8.6GB 檔案包含 70 億個(7B+)參數,比之前在瀏覽器中運行的任何模型大幾倍,其回應的品質改進也相應顯著,同時也保障了用戶的隱私。
此一Web API的特色包括:
- WebAssembly 和 WebGPU: 利用這些技術來提升運算性能,實現在瀏覽器中加速LLM的運行。
- 小型LLM: 能夠在設備上運行高達 7 億參數的模型,顯示出良好的性能和資源管理。
- 用戶隱私: 在本地運行模型可以減少數據傳輸,增強用戶隱私。
- MediaPipe 的整合: 結合多媒體處理功能,為開發者提供了豐富的工具和API支持。
以下為在瀏覽器中執行的 Gemma 1.1 7B,使用者與瀏覽器之間的對話影片:用戶詢問生日賀卡訊息創意,進而得到多個模板作為回應,並提供後續詳細信息,然後模型將其合併。
在Web上運行LLM
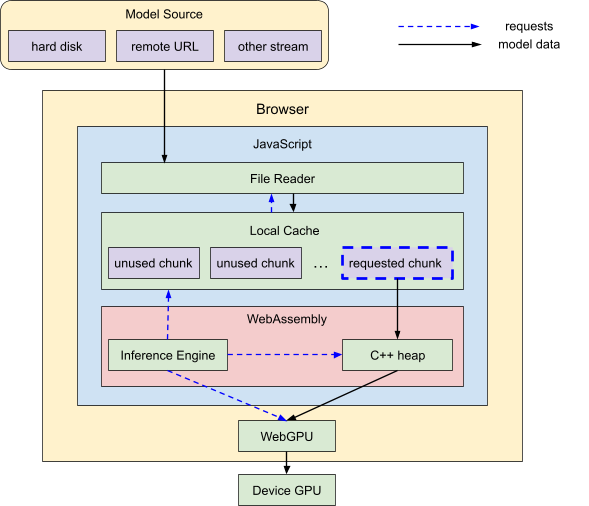
Google AI Edge 的MediaPipe本質上是跨平台的,因為大部分程式碼都是用C++編寫的,可以很好地針對許多目標平台和架構進行編譯。為了在瀏覽器中運行MediaPipe LLM Inference API,Google研究團隊將整個程式碼庫(所有非 Web 特定的內容)編譯為WebAssembly,這是一種可以在所有主要瀏覽器中高效運行的特殊組合程式碼,能提供出色的效能和可擴展性,但也帶來了一些額外的限制,例如會影響 C++ 程式碼和 CPU 記憶體限制。
值得一提的是,此架構使用WebGPU API 來執行所有與 GPU 相關的任務,使得WebAssembly不會限制裝置的 GPU 功能。該 API 旨在在瀏覽器中本機運行,使模型運算能夠比以往更直接地存取 GPU 及其運算功能。為了獲得最佳效能,此一機器學習推論引擎會上傳模型權重並完全在 GPU 上執行模型操作。
克服記憶體限制
相較之下,當從硬碟或網路載入 LLM 時,原始資料必須經過多個層才能到達 GPU:
- 檔案讀取記憶體
- JavaScript記憶體
- Web彙編記憶體
- WebGPU 裝置記憶體
具體來說,新的Web API架構使用基於瀏覽器的文件讀取 API 將原始資料帶入 JavaScript,將其傳遞到 C++ WebAssembly 記憶體,最後將其上傳到 WebGPU,一切都將在其中運行。每一層都有需要考慮的記憶體限制(參考原文),Google 也一一提出了因應的系統架構來適應。
小結
隨著Google AI Edge的MediaPipe推出MediaPipe LLM Inference API,使用者未來有機會在各種裝置上運行小型LLM,並體驗到流暢的性能和用戶隱私保護。此一Web API利用WebAssembly和WebGPU來突破記憶體限制,使得瀏覽器能運行更大規模的LLM模型,而隨著這些技術的持續改善,未來我們可能會看到更多基於LLM的應用在各種平台上無縫運行,進一步推動人機互動的革新。
(責任編輯:歐敏銓)
延伸閱讀

- 【技術導讀】Google推出Web API技術,用瀏覽器運行LLM沒問題! - 2024/10/11
- ADI新推嵌入式軟體開發環境以簡化並加速實現智慧邊緣應用 - 2024/10/08
- 【AI下一步】Human-In-The-Loop(人類參與循環)的重要性 - 2024/10/06



















.jpg)
.jpg)