根據市場研究機構TrendForce的最新AI server研究,在大型雲端服務供應商(CSP)加大自研晶片力道的情況下,NVIDIA於GTC 2026大會改為著重各領域的AI推論應用落地,有別於以往專注雲端AI訓練市場。其推動GPU、CPU以及LPU等多元產品軸線分攻AI訓練、AI推論需求,並藉由Rack整合方案帶動供應鏈成長。
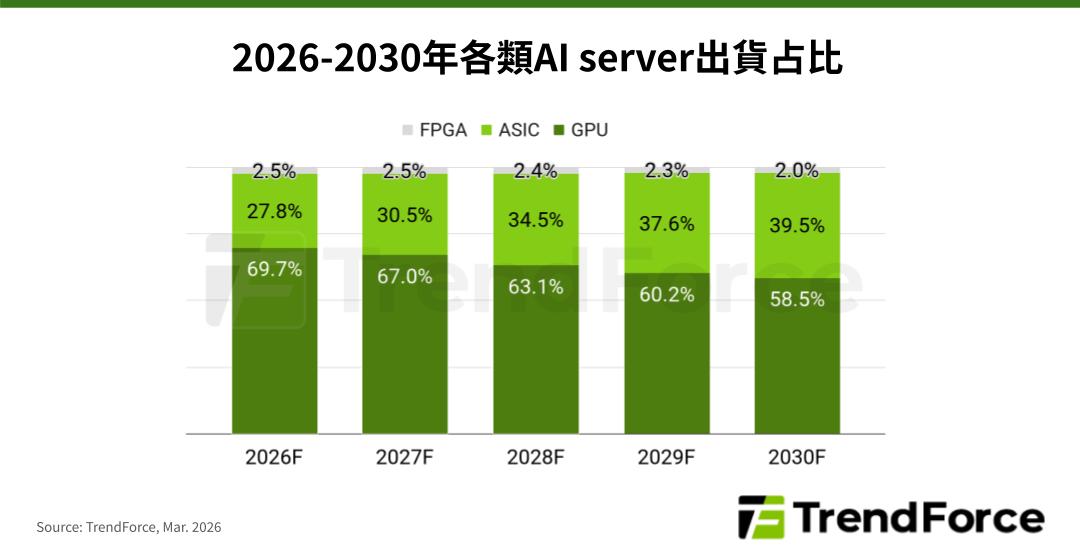
TrendForce表示,隨著以Google、Amazon等CSP為首的自研晶片態勢擴大,預估ASIC AI server占整體AI server的出貨比例將從2026年的27.8%,上升至2030年的近40%。
為鞏固在AI市場的領導地位,NVIDIA採取的其中一項策略為積極推動GB300、VR200等整合CPU、GPU的整櫃式方案,強調可擴展至AI推論應用。本次在GTC發表的Vera Rubin被定義為高度垂直整合的完整系統,涵蓋七款晶片和五款機櫃。
觀察Rubin供應鏈進度,預計2026年第二季記憶體原廠可提供HBM4給Rubin GPU搭載使用,助NVIDIA於第三季前後陸續出貨Rubin晶片。至於NVIDIA GB300、VR200 Rack系統出貨進程,前者已於2025年第四季取代GB200成為主力,預估至2026年出貨占比將達近80%,而VR200 Rack約於2026年第三季底可望逐步展開出貨量能,後續發展仍須視ODM實際進度而定。
另外,AI從生成跨入代理模型時代,在生成Token的解碼(Decode)階段面臨嚴重的延遲與記憶體頻寬瓶頸。為此,NVIDIA整合Groq團隊技術,推出專為低延遲推理設計的Groq 3 LPU,單顆內建500MB SRAM、整機櫃可達128GB。
然而,LPU本身的記憶體容量無法容納Vera Rubin等級的龐大參數與KV Cache。NVIDIA因此於本次GTC提出「解耦合推理(Disaggregated Inference)」架構,透過名為Dynamo的AI工廠作業系統,將推理流水線一分為二:處理代理型AI時,須進行大量數學運算並儲存龐大KV Cache的Pre-fill、Attention運算階段,交由具備極高吞吐量與巨量記憶體的Vera Rubin執行。而受限於頻寬且對延遲極度敏感的解碼與Token生成階段,則直接卸載至擴充了巨量記憶體的LPU機櫃上。
在供應鏈進度上,第三代Groq LP30由Samsung代工,已進入全面量產階段,預計於2026年下半年正式出貨,未來更規畫於下一代Feynman架構中推出效能更高的LP40晶片。

- 電腦視覺結合AI、數位孿生 2026年世足賽號稱史上最「高科技」 - 2026/07/10
- Agentic PC來了?NVIDIA RTX Spark重塑邊緣、桌機算力版圖 - 2026/07/09
- 聚焦機器人與智慧應用 ASRock新推高效能邊緣AI控制器 - 2026/07/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


