人形機器人正在成為實體人工智慧(Physical AI)最受矚目的應用場景之一,但要讓機器人在真實世界中穩定行走、避開障礙、理解環境並完成任務,背後往往需要大量模擬、訓練與驗證。過去,機器人強化學習(RL)通常被視為高度仰賴大型GPU叢集、分散式基礎架構與x86開發環境的工作負載,尤其是涉及高擬真實體模擬與人形機器人步態訓練時,更常被歸類為資料中心等級的任務。
不過Arm首席解決方案架構師沈綸銘(Odin Shen)近期分享的一套人形機器人訓練流程,試圖重新定義這項工作負載的運算邊界。該流程以NVIDIA DGX Spark為平台,結合Isaac Sim、Isaac Lab、RSL-RL與近端策略最佳化演算法(Proximal Policy Optimization,PPO),在單一Arm架構工作站上完成從原生建置、模擬、訓練到評估的完整流程,並以Unitree H1人形機器人在粗糙地形上的步行訓練作為實例。透過這套機器人訓練流程展示,Arm試圖證明其平台角色已從邊緣推論,進一步延伸到人形機器人開發全生命週期的重要案例。
從大型叢集到單機工作站 機器人訓練工作流開始分層
在大型AI機器人研發中,GPU叢集仍然具有不可取代的角色。無論是用於產生大量合成資料、訓練機器人基礎模型,或同時執行數千至數萬個平行模擬環境,大規模運算資源仍是加速模型收斂與任務泛化的關鍵。NVIDIA也將Isaac平台定位為開放式機器人開發平台,涵蓋模擬、機器人學習框架、CUDA加速函式庫、AI模型與參考工作流程,支援自主移動機器人、機械手臂、操作型機器人與人形機器人等應用。
然而,並非每一個機器人開發階段都必須直接進入大型叢集。對許多開發團隊而言,早期模型驗證、任務設計、模擬環境調校、獎勵函數設計與策略收斂觀察,往往更需要一套低摩擦、可反覆迭代、能在本地端運作的工作流程。Arm展示的案例,正是將原本被認為偏向資料中心的機器人RL流程,下放到單一工作站級平台,讓開發者能在更接近本地開發的環境中完成機器人學習實驗。
DGX Spark的核心是Grace–Blackwell GB10 Superchip,整合Arm架構Grace CPU與Blackwell GPU。這套系統採桌上型尺寸設計,具備128GB 一致性統一系統記憶體,並可提供最高1 PFLOP的FP4 AI效能,用於本地端AI模型開發、測試、微調與推論。相較於大型資料中心叢集,這類平台的意義並不在於取代雲端或高效能運算基礎設施,而是讓開發者能更快進入實驗、調校與驗證階段。

Arm原生建置降低環境切換成本
這套流程的第一個關鍵,在於Isaac Sim與Isaac Lab並非透過x86主機進行交叉編譯,而是直接在Grace CPU的 aarch64 環境中原生建置。整個軟體堆疊包含GCC 11、CUDA 13、Git LFS 與Omniverse 模擬元件,最後產出原生aarch64執行檔,並保留完整CUDA加速能力。
這對機器人開發者的意義在於,模擬、訓練與後續部署之間的架構斷點有機會被縮小。過去若開發端、訓練端與邊緣部署端分屬不同硬體與作業環境,團隊往往需要處理交叉編譯、相依套件差異、驅動版本與效能落差等問題。當Isaac Sim與Isaac Lab能在Arm原生環境中建置與執行,代表Arm不再只是終端推論或低功耗邊緣控制器的選項,而是能向上承接模擬與訓練流程,形成從雲端到邊緣更一致的開發模型。
在實作案例中,Arm 選擇Isaac-Velocity-Rough-H1-v0 任務,訓練具備19個致動關節的Unitree H1 人形機器人,使其能追蹤前進速度指令、維持平衡,並在程序生成的粗糙地形上行走。訓練流程採用RSL-RL這類針對機器人移動任務設計的輕量級強化學習函式庫,並以近端策略最佳化演算法作為主要訓練方法。
模擬與學習迴圈的整合
在效能表現上,Odin的文章指出,該系統以無圖形介面模式(headless mode)執行,並設定512個平行環境,單機可達約 65,000 simulation steps/s 的模擬吞吐量。這對人形機器人訓練相當關鍵,因為強化學習的效率高度仰賴大量互動樣本;平行模擬環境越多,策略能接觸到的狀態與動作組合越豐富,也越有機會加速收斂。
其架構價值不只來自GPU算力,也來自CPU與GPU之間的資料流整合。Blackwell GPU負責實體模擬與神經網路加速,Grace CPU 則負責任務調度(orchestration)、編譯與資料準備;NVLink-C2C 提供CPU與GPU之間的統一記憶體空間,減少傳統PCIe架構下反覆搬移張量資料所造成的延遲與吞吐量瓶頸。
對比大型 GPU 叢集,單一DGX Spark不會取代大規模模型訓練或超大規模合成資料生成,但它可能補上另一個更貼近開發現場的缺口:讓工程師能在本地快速測試任務、調整環境、觀察策略行為,再將成熟流程推向更大規模的運算平台。Isaac Lab本身即是建立在Isaac Sim之上的開源模組化機器人學習框架,目標是簡化機器人在模擬中學習與適應新技能的流程;這也說明機器人開發正走向更高度平台化與工作流導向。
不只讓人形機器人學走路 訓練過程也更可觀察
強化學習最具吸引力之處,在於開發者能直接觀察策略如何從隨機探索逐步形成可用行為。Arm在訓練過程中比較不同檢查點(checkpoint):在第50次迭代時,多數機器人幾乎立即跌倒,關節動作雜亂且不穩定,尚未形成明確步態;到了第1,350次迭代,機器人已能穩定向前行走,在不平坦地形上維持平衡,並能從小幅干擾中恢復。
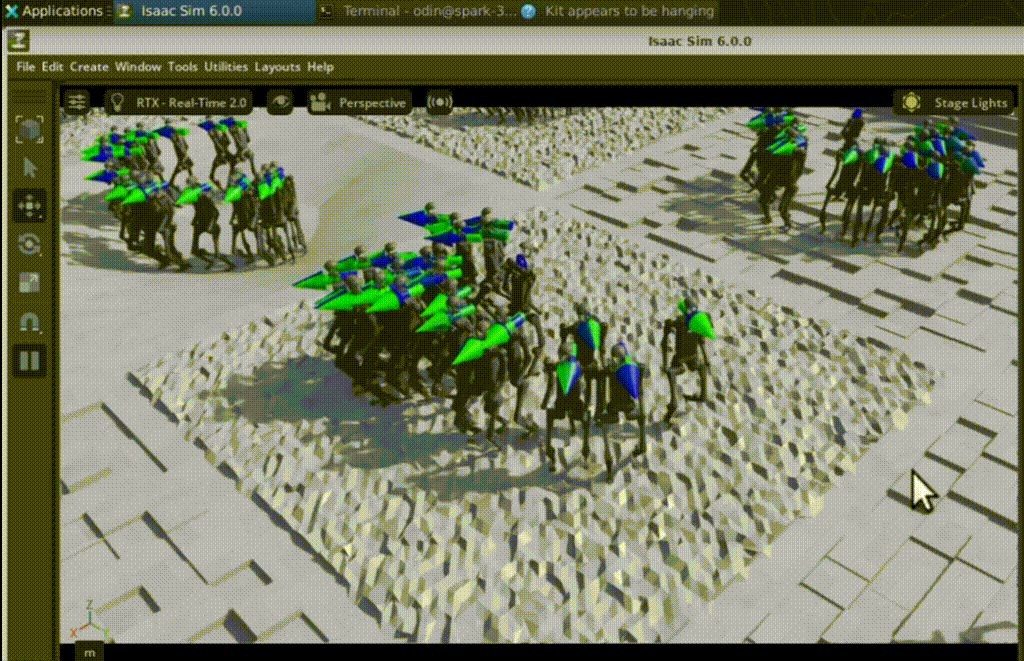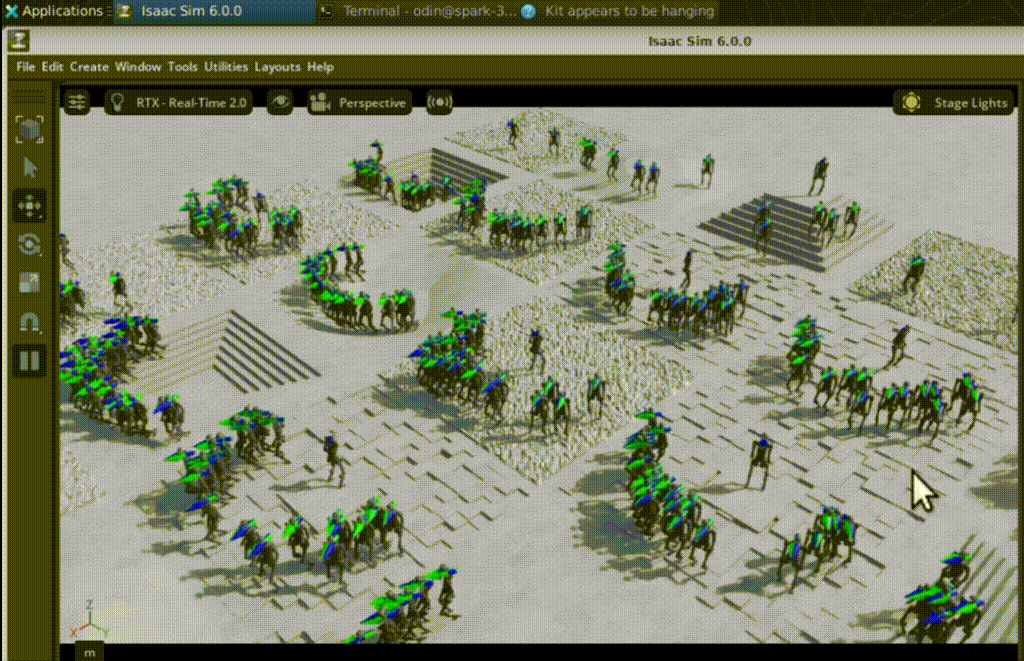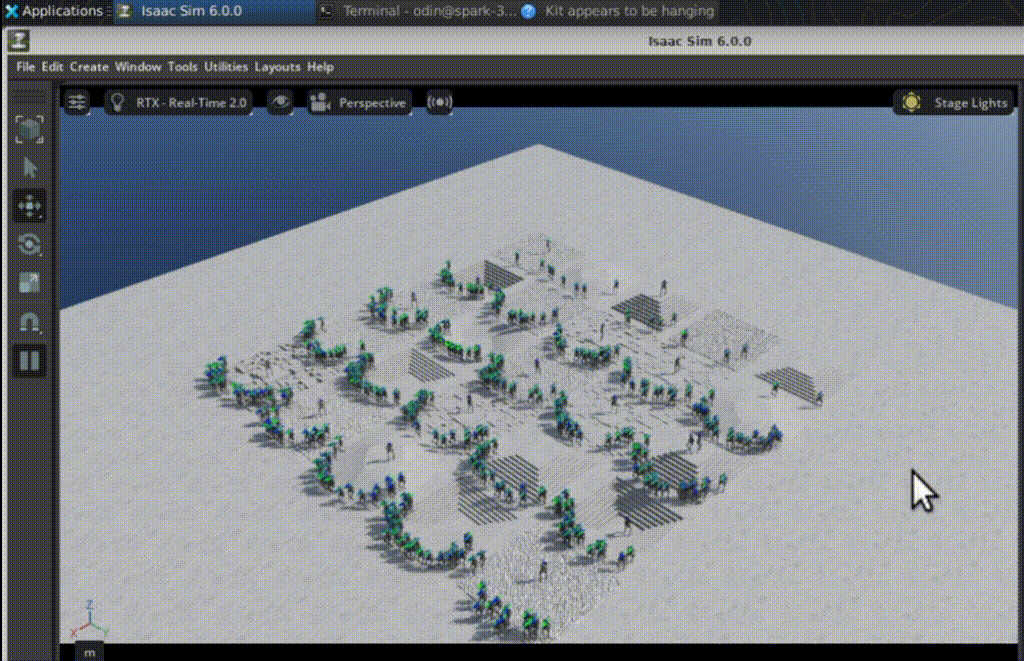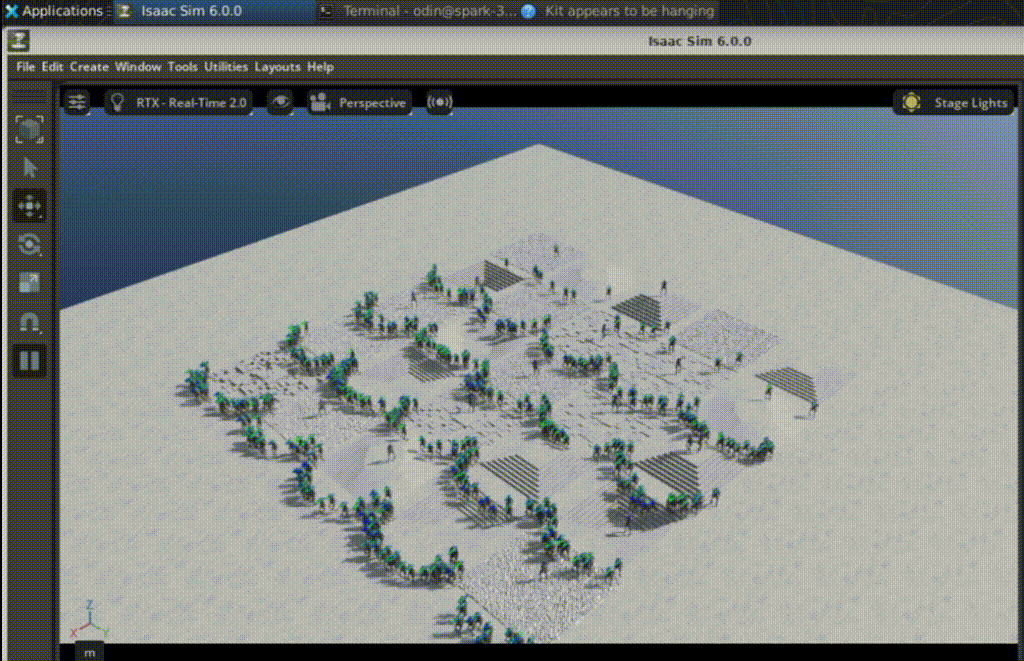
這樣的結果也反映在訓練指標上,包括平均獎勵提高、片段長度(episode length)拉長、價值函數損失(value function loss)趨於穩定、動作雜訊(action noise)下降,以及跌倒造成的終止懲罰(termination penalties)減少。對開發者而言,這些視覺行為與數據指標的對應關係,是理解 RL 是否真正收斂的重要依據,也有助於後續進行模擬到真實轉移(sim-to-real)前的策略篩選與安全驗證。
從產業角度來看,這套流程最大的意義不在於證明單一工作站能完成所有機器人AI任務,而是凸顯機器人訓練基礎架構正在分層:大型GPU叢集負責基礎模型、巨量資料與大規模平行訓練;工作站級平台則承接快速原型、任務驗證與本地迭代;最終再延伸到邊緣端部署與實體機器人控制。當Arm 原生環境能支援 Isaac Sim、Isaac Lab 與完整 RL 工作流,代表實體 AI 的開發鏈條有機會變得更連續,也讓更多機器人團隊能在進入昂貴的大規模訓練之前,先建立可重現、可調校、可觀察的本地訓練流程。
無論你是正在評估機器人AI訓練平台,或希望加快從模擬到實作的節奏,MakerPRO在4月29日(週三)晚上8點,特別邀請到目前駐Arm英國總部的Odin現身說法,詳細分享他在Arm架構工作站進行人形機器人訓練的心得,開發者夥伴們千萬別錯過這場能啟發靈感、相互交流經驗的Meetup,快點來報名吧!

- RISC-V躍居AI推論時代運算主流 台灣供應鏈迎接「開放」新契機 - 2026/06/18
- 量子運算加速邁進可用階段 英飛凌分享技術布局策略 - 2026/06/17
- 【COMPUTEX 2026】Edge AI走向現實生活 Alif展示多元低功耗應用 - 2026/06/11
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


