作者: 李盛安,慈濟大學醫資系教授/Intel Software Innovator
在人工智慧與電腦視覺領域中,姿態估計技術的發展一直扮演著關鍵角色。隨著深度學習的進步,越來越多高效的姿態估計模型被提出並應用於各種場景中。OpenVINO 2024.2 作為 Intel 最新的 AI 部署工具,為模型部署提供強大的支援。本篇文章將探討幾個姿態估計模型在OpenVINO 2024.2上的效能表現。本文的運作平台是Intel AI PC,透過Intel Core Ultra內的CPU、iGPU 和 NPU 執行並觀察不同模型於OpenVINO 2024.2環境下執行的效能與目前軟體平台支援的狀態,同時也讓有興趣在姿態辨識應用的使用者與開發人員提供參考,了解適合自己應用需求的姿態估計方案。
本文主要於ASRock NUC BOX-155H平台進行,使用Intel Core Ultra運作的NUC (下一代計算單元)。我們將姿態辨識模型OpenPose、3D Pose、MoveNet 與 YOLOv8 模型轉換為OpenVINO IR模型格式,分別在CPU、iGPU及NPU上進行部署。觀察這些模型在CPU、iGPU及NPU的硬體效能差異,透過實際執行影片推論的過程,觀察NPU的性能表現。
本次測試機器ASRock NUC BOX-155H的記憶體大小為32G,使用的作業系統是Ubuntu 22.04.4 LTS。

作業系統與驅動程式
- 作業系統:
- 版本:Ubuntu 22.04.4 LTS
- 核心版本:6.5.0-44
- OpenVINO:
- 版本:2024.2
- 驅動程式:
- iGPU與NPU驅動程式的安裝方式,本文後面會提及安裝步驟。
OpenVINO 2024.2姿態估計套件介紹
如果是剛接觸OpenVINO的使用者,目前有許多方法可以安裝OpenVINO 2024.2的運作環境,在本文中透過Python程式環境來安裝OpenVINO的開發環境,在OpenVINO 2024.2的官方網頁中,可以看到不同作業環境下的安裝方式。
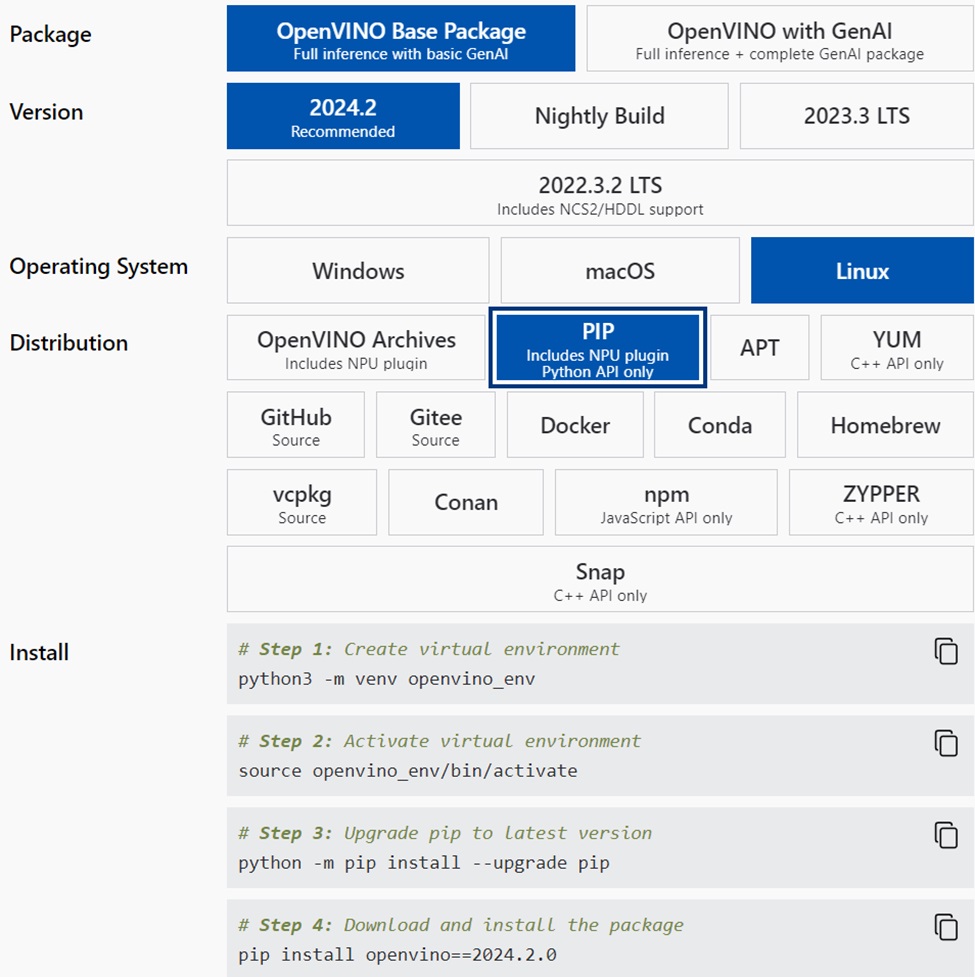
按照底下的指令安裝 OpenVINO 2024.2:
# Step 1: 建立openvino_env虛擬環境(官方文件的建議名稱是openvino_env)
python3 -m venv openvino_env
# Step 2: 啟動openvino_env虛擬環境
source openvino_env/bin/activate
# Step 3: 升級pip到最新的版本,確保套件資料庫的版本是最新的
python -m pip install --upgrade pip
# Step 4: 下載OpenVINO 2024.2.0套件並且安裝
pip install openvino==2024.2.0
OpenVINO 2024.2在官方的文件中主要最大的差異是推出LLM專屬的API,同時相對於OpenVINO 2024.1,許多Openvino Notebooks的專案也持續的更新,以下將介紹OpenVINO 2024.2 Notebooks跟姿態辨識相關的專案。
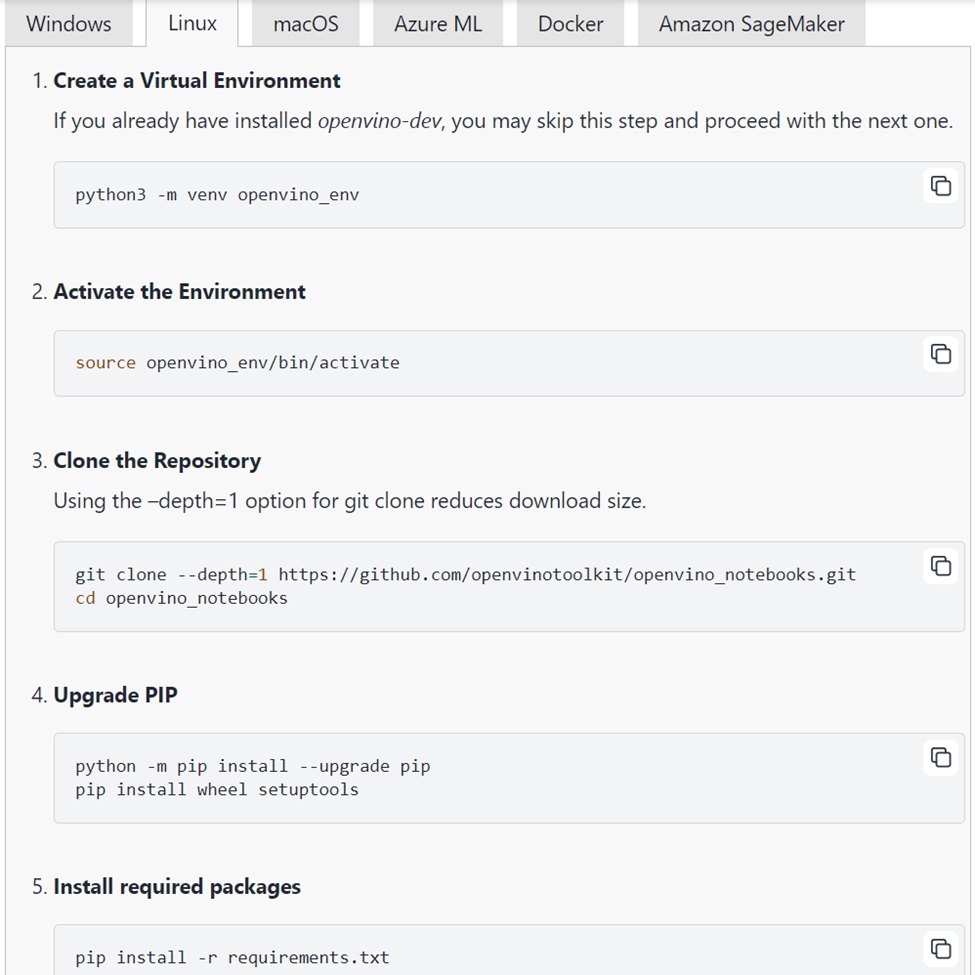
安裝OpenVINO Notebooks
安裝好OpenVINO 2024.2以後,可從以下網址安裝OpenVINO Notebooks來學習許多的範例與預訓練模型的部署方式:https://docs.openvino.ai/2024/learn-openvino/interactive-tutorials-python/notebooks-installation.html
下方表格顯示OpenVINO Notebooks可以運作的環境,要注意的是Python的版本以及你所執行的Linux環境的版本是不是符合。
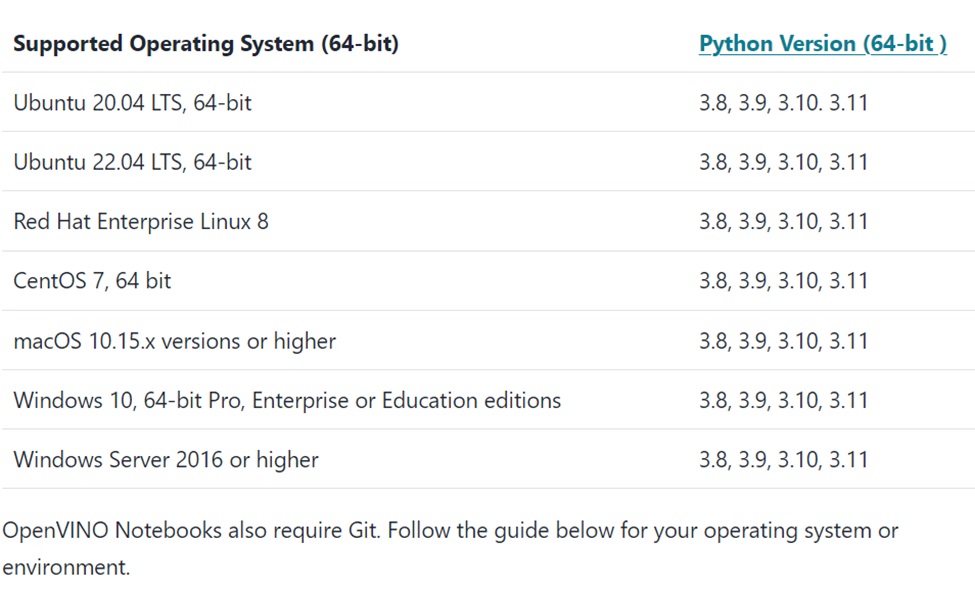
當你已經按照之前的步驟安裝好OpenVINO 2024.2的Python虛擬環境,並且啟動OpenVINO 2024.2的虛擬環境之後(Notebooks的安裝步驟的第一個與第二個步驟,也就是這個目的),按照第三個步驟開始,透過git指令來下載Openvino Notebooks所需要的程式與套件,進入openvino_noteooks的子目錄,就可以開始透過pip指令來安裝Openvino Notebooks (下圖步驟四與步驟五)。
安裝OpenVINO的GPU驅動程式與套件
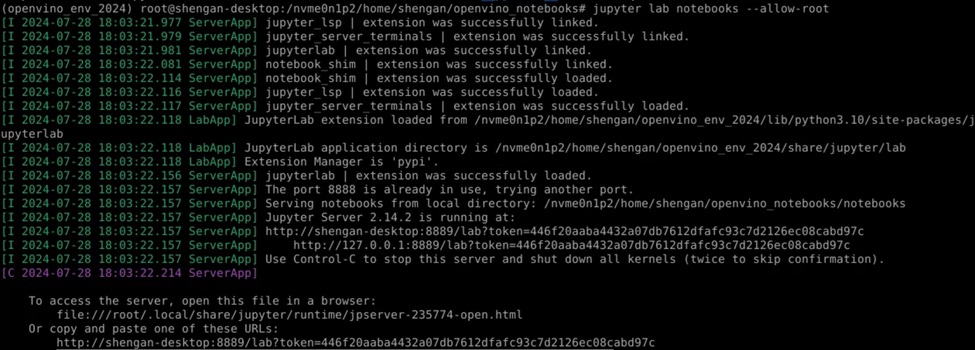
安裝完OpenVINO Notebooks之後,我們可以先測試兩個Jupyter lab notebooks的專案,為了方便後續的實驗,都是使用root的身分權限執行後續的效能測試觀察。下圖為啟動jupyter後的圖示,使用root身分的時候,後面要加上—allow-root。
之後可以用瀏覽器啟動jupyter的專案,可以先看GPU與NPU的執行狀態是否正常,GPU的專案名稱是gpu-device,NPU的專案名稱是hello-npu,底下是gpu-device.ipynb的專案,重點在確定GPU一定要出現在OpenVINO可以搜尋到的硬體,不然就算OpenVINO跑得起來,在很多情況下沒有GPU的驅動程式配合下,效能有可能會降低非常多。
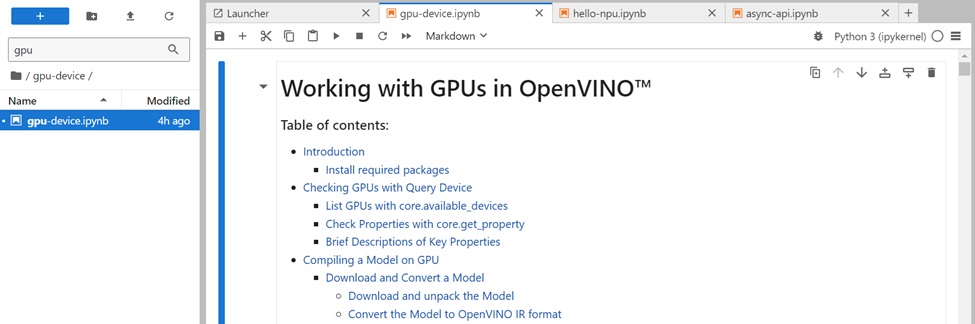
整個專案的第一段有一個說明,OpenVINO Intel iGPU (這些GPU包括在大多數Intel Core桌上型和移動處理器中)或在Intel獨立GPU產品上進行推論,如 Intel Arc A系列顯示卡和Intel資料中心GPU Flex系列。一般如果我們在桌上型PC要安裝OpenVINO的GPU驅動程式,需要連結以下網址來安裝相關的套件:https://dgpu-docs.intel.com/driver/client/overview.html。
主要的觀念是選擇了Client GPUs的驅動程式來安裝,另外對於Ubuntu 24.04 LTS目前可能還有部分運作的問題。建議先用Ubuntu 22.04.4LTS來安裝GPU驅動程式。官網文件中需要安裝的步驟不能跳過,會產生套件下載安裝失敗的情形。

另外官方文件寫了很多種不同運作狀態下的驅動程式安裝方式,本文中只安裝了最左邊的架構,沒有GPU debugging的環境。
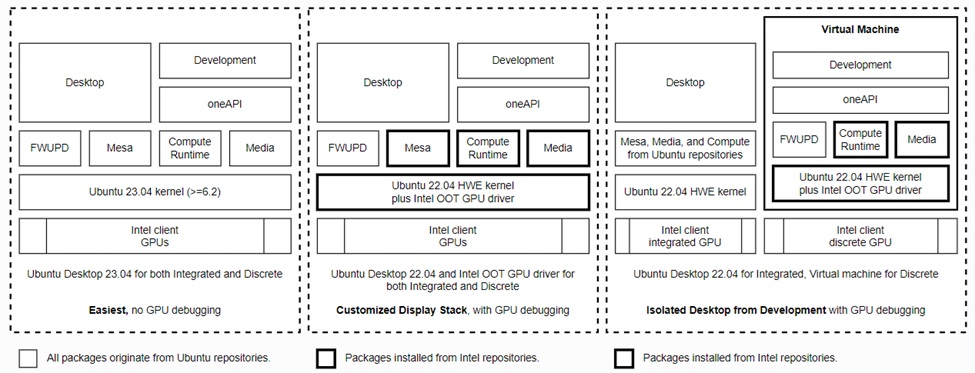
按照官方文件的第一與第二個步驟做完,後面GPU的運作才會比較正常。

安裝完第一跟第二個步驟之後,需要重新開機。
要注意的是第四跟第五個步驟筆者後來並沒有使用,因為安裝之後可能會與系統原來的一些套件產生衝突,後面就維持在第一跟第二步驟之後,可以正常的使用iGPU來進行後續實驗。中間碰過一些問題,偶爾系統更新、換了kernel也有可能產生部分其他相容性的問題,所以就沒有使用,這個狀態應該後面可以等OpenVINO穩定的支援Ubuntu 24.04 LTS的時候,直接安裝新的OpenVINO版本就可以解決需要運作在Ubuntu 24.04 LTS的需求。
官方文件中Installing out-of-tree drivers for GPU以及一些後續的測試安裝環境的成功與否的流程,經驗上我最後用了一個乾淨的Ubuntu 22.04.4 LTS直接裝完第一與第二步驟就可以正常使用了,之前安裝了太多東西反而後續怎麼樣都無法正常運作(看得到GPU,但是無法正常推論)。
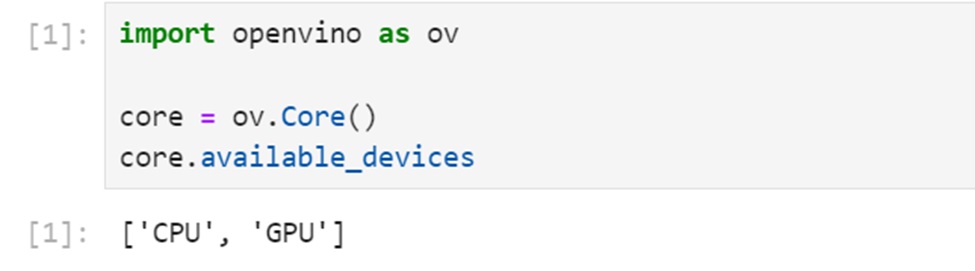
重開機之後重新執行OpenVINO Notebooks,一切正常的狀態下,將會看到OpenVINO能夠正確識別目前有哪些推論裝置。如下圖,執行第一個與第二個專案的區塊之後,應該會看到 [‘CPU’,’GPU’] 的裝置名稱,此時是第一個階段的完成。最後要能夠正常的執行到專案的最後的區塊都正常完成,才能夠確定OpenVINO的GPU運作正常。

為了簡化設備和管道配置,OpenVINO 提供了高階性能提示(high-level performance hints),這些提示會自動設置用於推論的批次大小和平行執行緒的數量。”LATENCY”嘗試將推論時間最佳化,而 “THROUGHPUT”則最佳化整體的流量或 FPS。

要使用 “LATENCY” 性能提示,在編譯模型時添加 {“PERFORMANCE_HINT”: “LATENCY”},如上圖所示。對於 GPUs,這將自動最小化批次大小和平行流數量,以便所有運算資源都可以集中在盡快完成單次推論。
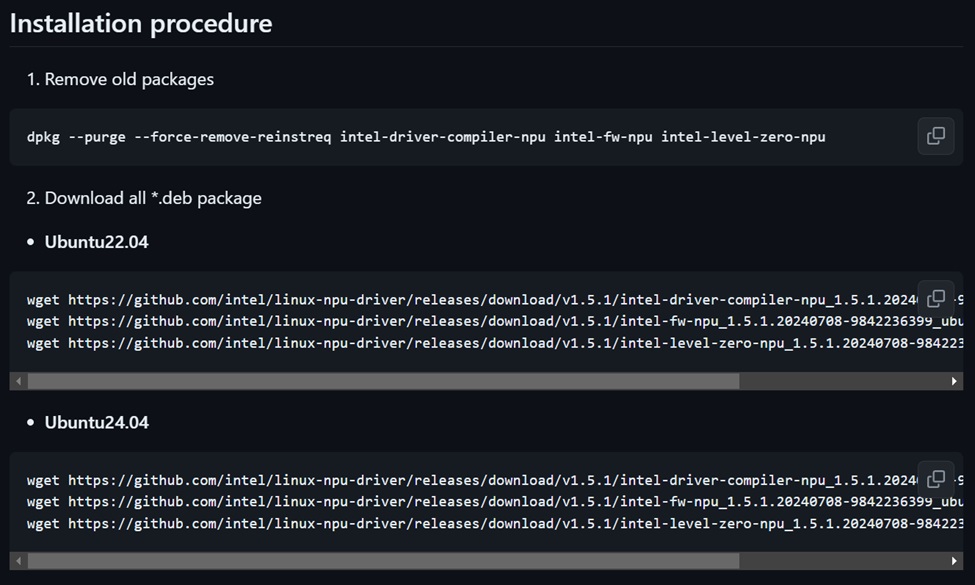
安裝OpenVINO的NPU驅動程式與套件
在OpenVINO中要使用NPU的執行環境,建議可以先開啟hello-npu.ipynb專案,可以看到一些NPU使用環境安裝方式的說明,目前最新版的NPU 驅動程式已經到了1.5.1的版本,這個版本相對的對於Ubuntu 22.04.4 LTS,以及Ubuntu 24.04LTS等已經有比較多的支援。
要安裝驅動程式可以依據說明進入以下網址:https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html
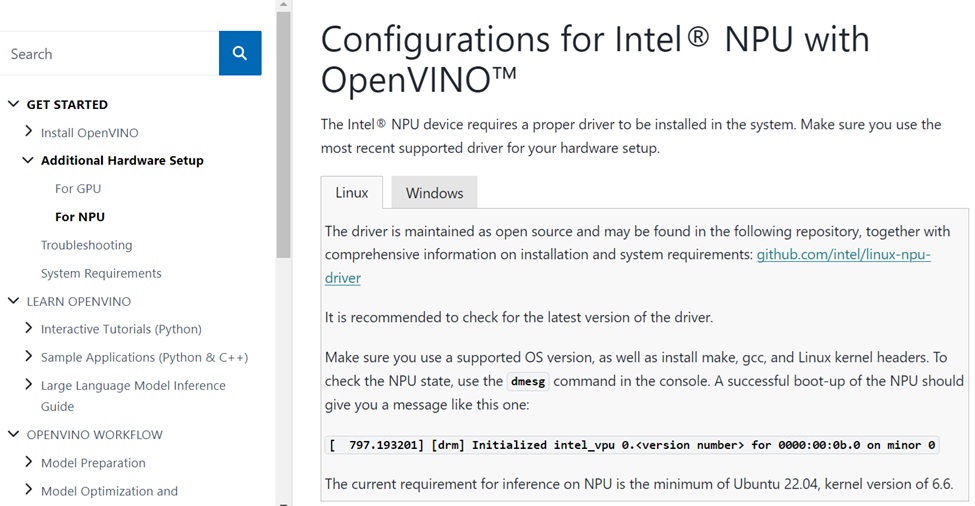
網頁中有一個github的專案網址,可以下載最新版的NPU驅動程式來安裝:https://github.com/intel/linux-npu-driver/releases
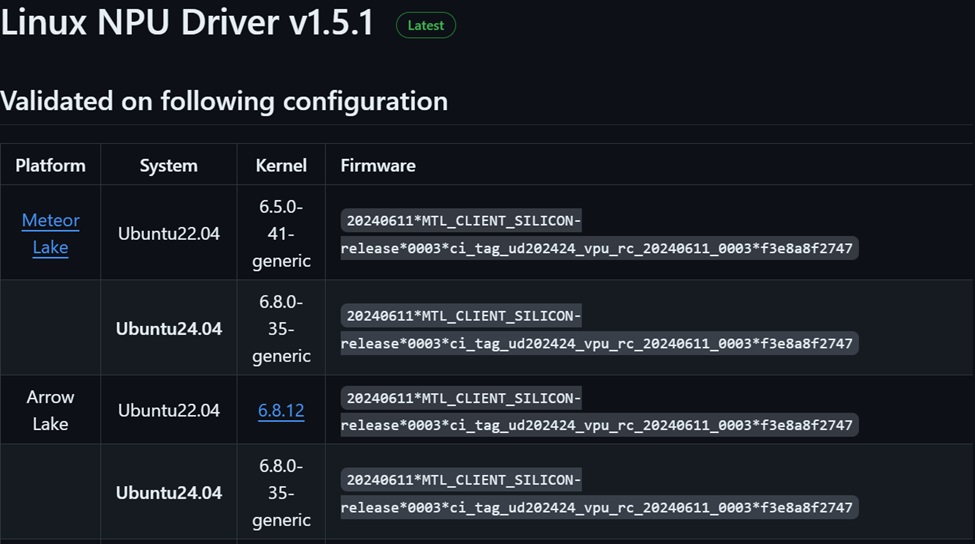
其中可以看到已經有針對Ubuntu 22.04以及Ubuntu 24.04的支援(2024年5月);不過在此之前筆者曾經做過一些測試,當時針對Ubuntu 24.04一直沒有很穩定,因此目前針對Ubuntu 22.04進行安裝NPU驅動程式,來觀察在Intel Core Ultra的執行效能。
於OpenVINO Notebooks觀察OpenPose預訓練模型的執行效能
OpenPose是由卡內基梅隆大學(Carnegie Mellon University)開發的一個開源姿態估計框架,專門用來偵測人體的多個關鍵點;OpenPose在OpenVINO的預訓練模型IR格式中名稱為human-pose-estimation-0001。OpenPose模型被轉換為IR格式,使其能夠在多種硬體平台上運作,包括 CPU、iGPU 和 NPU 等。OpenPose模型能夠充分利用OpenVINO的最佳化技術和硬體加速能力,顯著提升其在各種應用場景中的推論速度和資源使用效率。
在過去Open Model Zoo的預訓練環境中,包含幾類的姿態辨識模型,其中OpenPose的編號為human-pose-estimation-0001,使用者可以依據這個概念,以human-pose-estimation-0005、0006、0007以及higherhrnet模型觀察其效能在CPU、iGPU、NPU環境狀態下的執行效能。
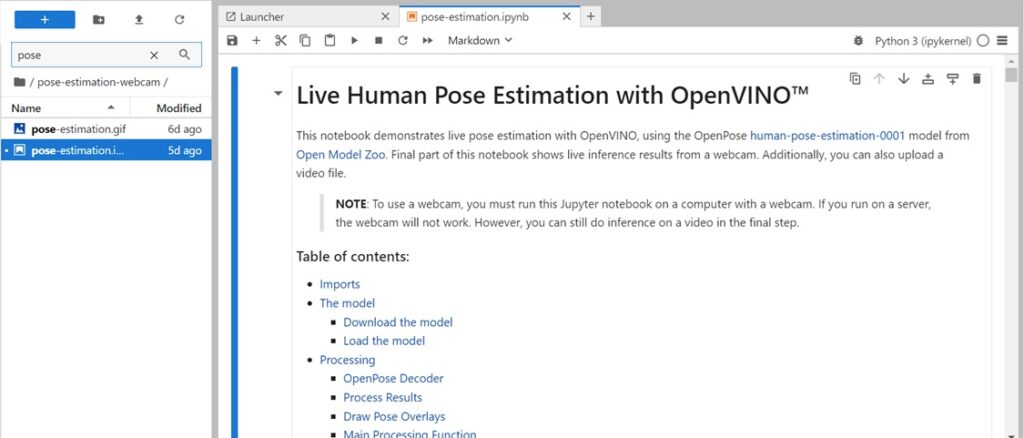
以下將說明由Openvino Notebooks執行Live Human Pose Estimation with OpenVINO專案。
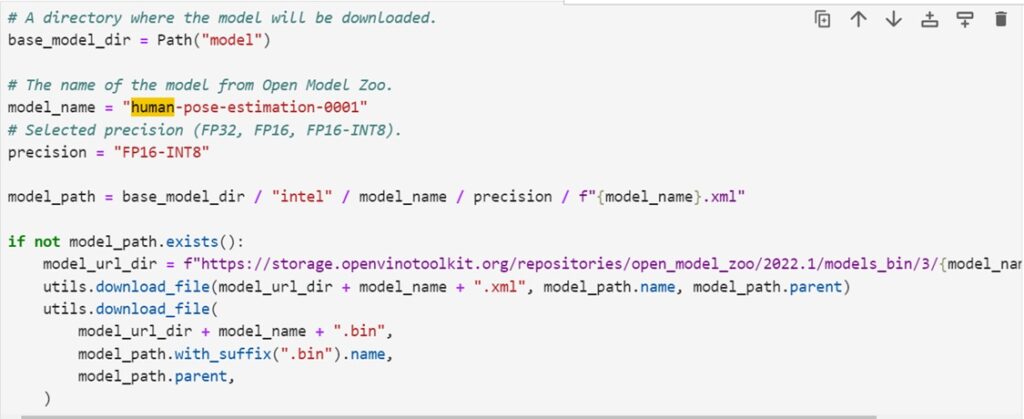
專案中可以看到所使用的預訓練模型是 human-pose-estimation-0001,可以選擇的精度為FP32、FP16與FP16-INT8,因此可以很方便的進行模型的使用,特別是在CPU、iGPU、NPU不同的運算單元的環境下,可以很方便的觀察不同運算單元所對應的執行效能。
透過專案內部所提供的程式區塊,可以將human-pose-estimation-0001中FP32、FP16、FP16-INT8的不同精度的模型分別下載下來。
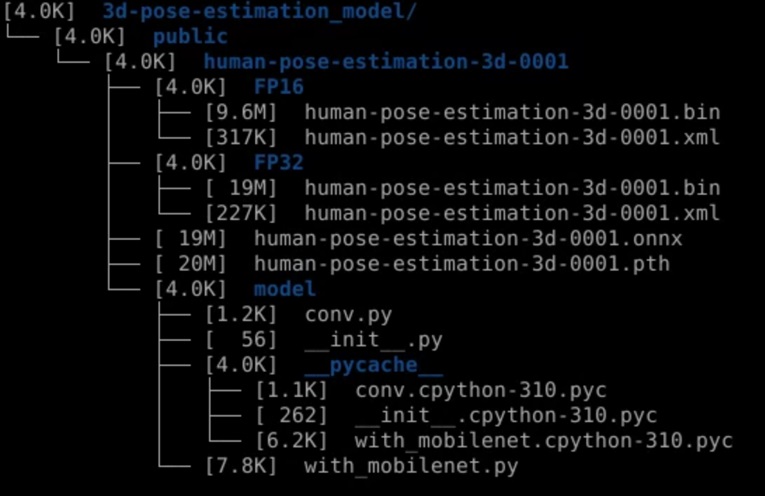
透過tree model/intel/human-pose-estimation-0001 -sh 指令,觀察下載的模型的子目錄架構,以及相關模型檔案的大小。
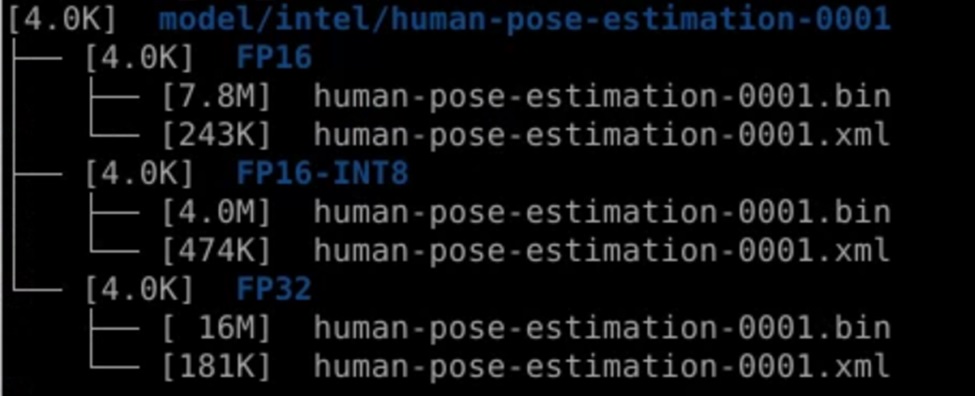
在專案的最底端有一個測試用的範例影片,影片中對應著不同時間點的人數出現以及遮蔽的狀態,這個狀態下可以觀察不同的模型相對的執行的效能與應用的狀態。

接下來的各小節將會依序的顯示各個模型於不同運算單元的效能與執行的FPS結果,本文透過實際執行同一個測試影片的狀態下,分別觀察不同姿態辨識模型於Intel Core Ultra的執行效能,不同於過去單純使用benchmark_app的測試環境觀察各個模型對應的執行效能,本次將直接透過ASRock NUC BOX-155H的執行不同姿態辨識的效能,來觀察實際的運算情形。
可以觀察到範例中的影片共有3,920個Frame,將這3,920個Frame分別由CPU、iGPU、NPU,並且由human-pose-estimation-0001的FP32、FP16、FP16-INT8三種模型的架構去執行姿態辨識的過程,觀察最後至3,920個Frame辨識完成後,平均的FPS的情形。
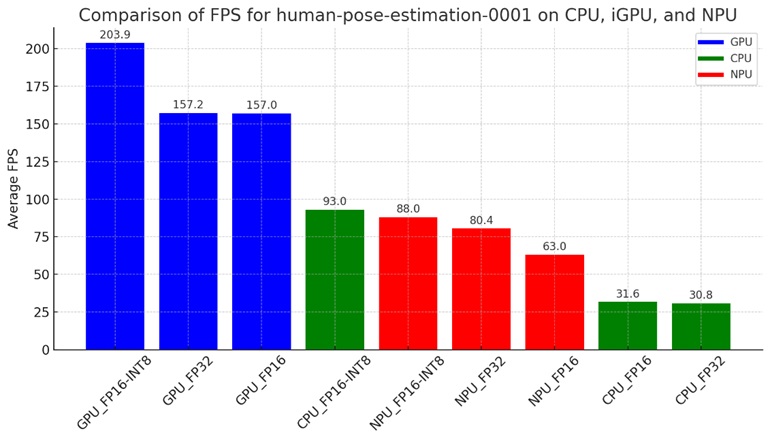
由上圖可以觀察到,iGPU的執行效能在FP32、FP16、FP16-INT8是最快的,在精度不同的條件下,同樣都表現出最快的效能,這一點與過去在沒有NPU的時代,GPU執行的效能可以大幅度的快過CPU是相符的,而CPU無論執行FP32或FP16的效能,相對於NPU都只有不到一半的效能,這個結果可以做為日後執行模型效能的參考,而CPU在執行FP16-INT8的時候,效能較NPU執行FP16-INT8的效能好一些,也可以作為一個初步的參考結果。
於OpenVINO Notebooks觀察Yolov8-keypoint模型的執行效能
在OpenVINO Notebooks裡面,提供Yolov8非常棒的專案範例,可以從yolov8-keypoint-detection.ipynb這個專案範例裡面學會許多的Yolov8開發的程式碼,對於OpenVINO而言,Yolov8本身提供了export的功能項目,可以方便地將Yolov8的預訓練模型轉換為其他格式,其中也包含了OpenVINO使用的IR格式。
在yolov8-keypoint-detection.ipynb專案中,按照OpenVINO本身提供的方式,可以快速地轉換成FP32以及FP16的精度,透過half=True跟half=False可以將Yolov8的姿態辨識模型輸出為FP32跟FP16的精度格式的模型。

進一步要將更多的格式轉換出來,例如FP16-INT8。查了一下Yolov8的官方網頁說明文件,系統本身的export指令提供許多的輸出格式,官方網站的文件網址如下:https://docs.ultralytics.com/modes/export/#arguments
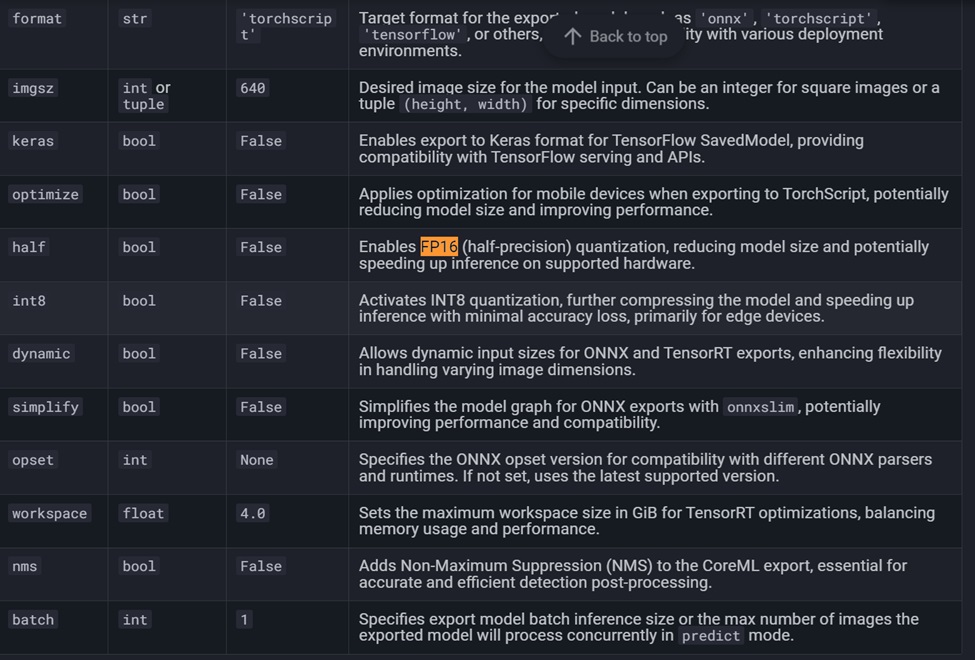
可以看到export裡面有許多的參數可以設定,並且可以設定不同格式的模型輸出。
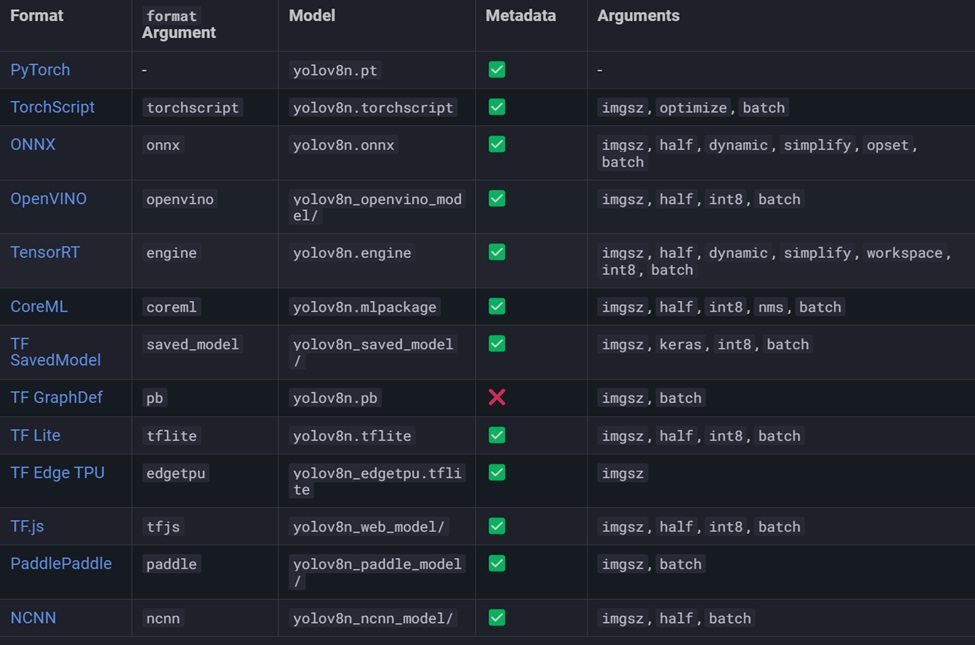
可以透過這個方法取得能運作於OpenVINO的INT8格式Yolov8姿態辨識模型,並以下方指令得到相關的INT8模型輸出:
yolo export model=yolov8n-pose.pt format=openvino int8=True

同時也可以透過其他的參數格式,獲得FP32與FP16的Yolov8 export轉換出來的OpenVINO於不同精確度的模型。
yolo export model=yolov8n-pose.pt format=openvino half=False
其中包含選項optimize的True與False選項,兩個分別設定,觀察看看Yolov8的optimize轉換出來的模型是否效能上有差異。最後將產生完成的模型,透過tree命令顯示Yolov8的模型的大小,以及各精度的情形。
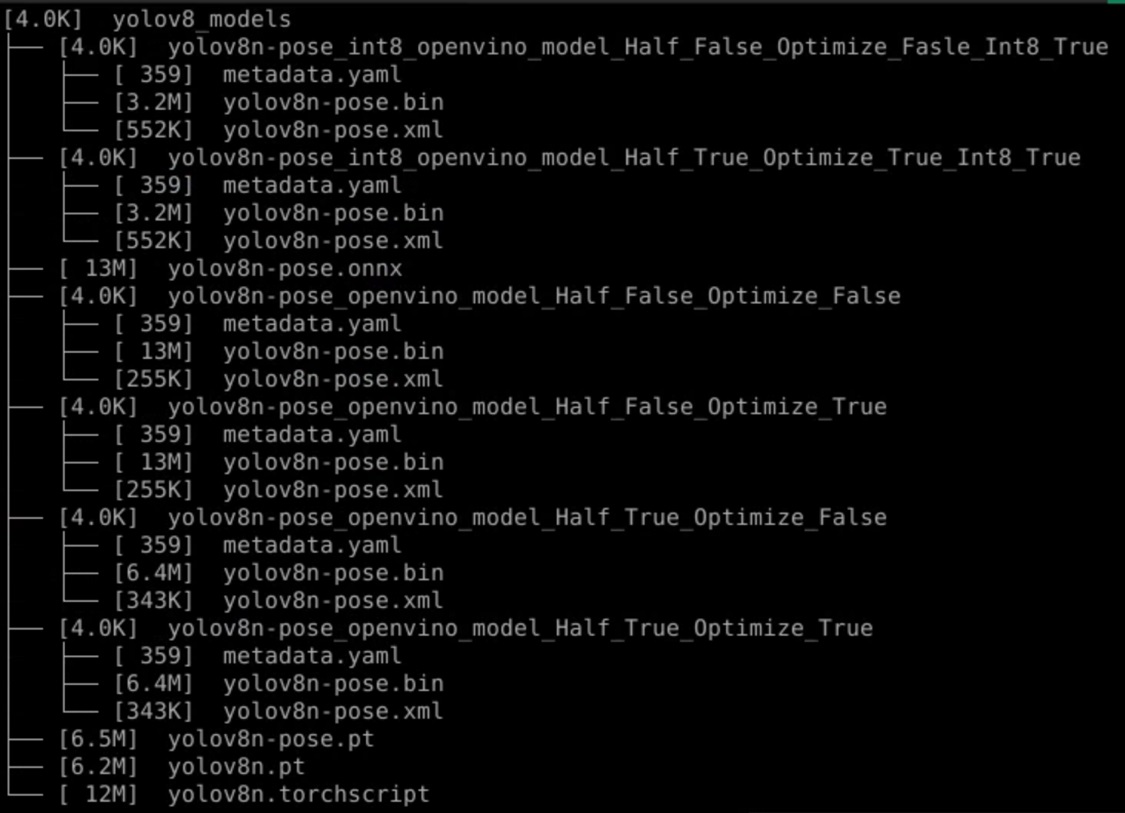
將這個網址的影片一樣透過Yolov8各種轉換出來的姿態辨識模型,分別執行一次,觀察在CPU、iGPU、NPU,以及各種條件下的模型與精度執行的FPS效能差異,最後得到了下方的圖表:
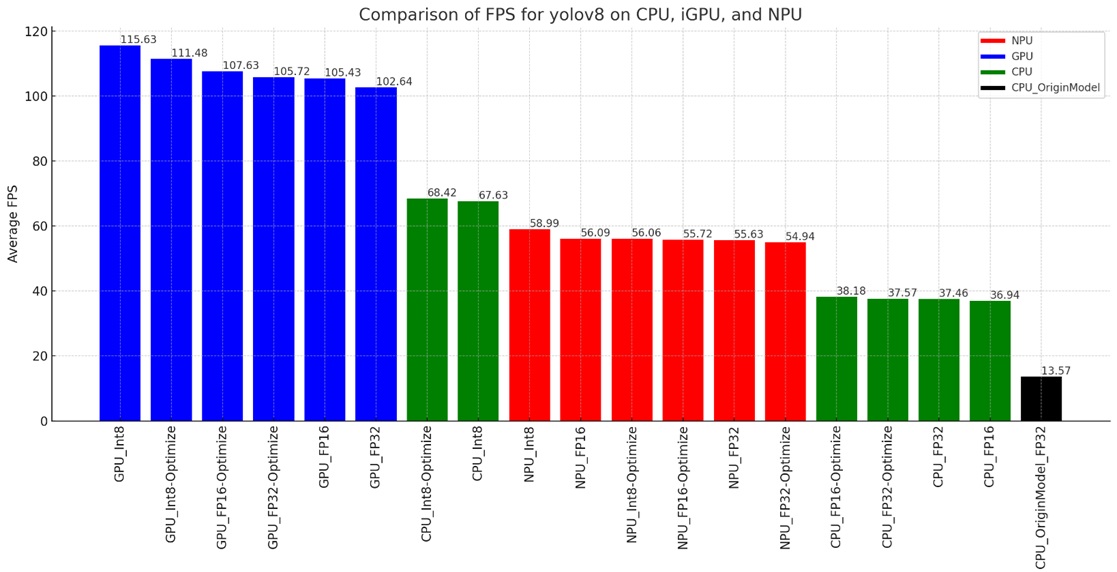
上圖顯示了與human-pose-estimation-0001類似的趨勢,GPU的執行效能在各種精度的狀態下(FP32、FP16、INT8),表現了非常棒的執行效能,接近8倍以上相對於最原始的yolov8n-pose.pt下載模型的FPS執行效能。過去有一些文章描述yolov8n-pose.pt的執行效能不太理想,透過OpenVINO的架構來執行,在單純使用CPU在FP32與FP16的精度下,也有接近3倍的FPS效能提升。
最後可以觀察到單純的使用NPU來執行,效能雖然沒有GPU這麼驚人,不過在FP32、FP16的精度下,執行效能也比原本的yolov8n-pose.pt好接近4倍以上。綜觀來說,NPU在各種精度模式下的執行效能呈現穩定的狀態,後續可以再花一些觀察與CPU協作時的效能變化。
於OpenVINO Notebooks觀察human-pose-estimation-3d-0001模型的執行效能
進一步觀察human-pose-estimation-3d-0001預模型的執行效能, 啟動OpenVINO Notebooks中的3D-pose-estimation.ipynb專案,可看到以下畫面:
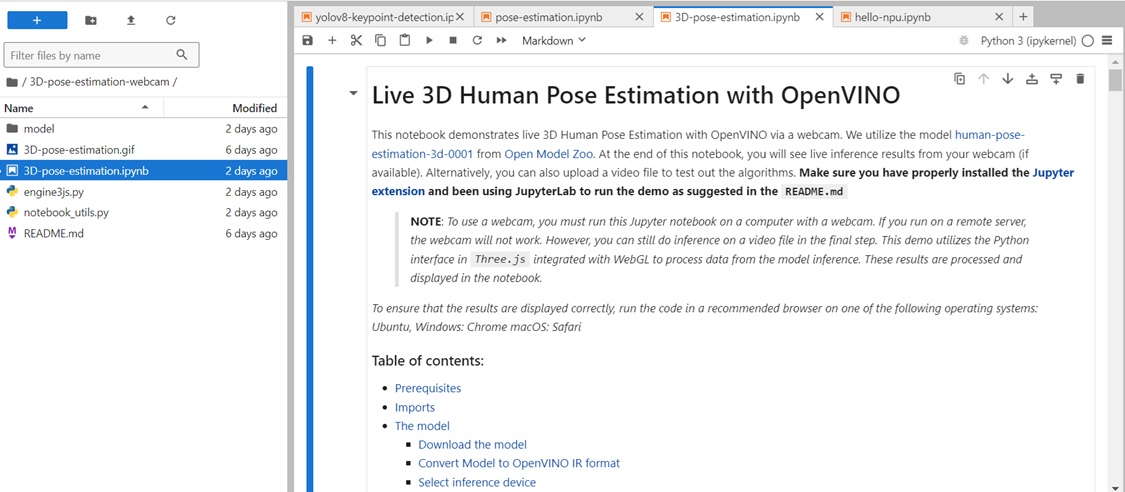
在Download the model的區塊,可以看到如何下載與轉換human-pose-estimation-3d-0001的預訓練模型,並且將其轉換為IR的FP32與FP16的格式,這個部分是重要的範例,之後如果有拿到onnx格式的模型不會轉換,可以用這一個方式轉換。

下載與轉換好模型以後,可以看到會呈現以下的路徑格式,將模型的輸出路徑設定在3d-pose-estimation_model的路徑下。

可以看到路徑的架構如下,其中原始下載的路徑模型是onnx的格式,透過OpenVINO的模型轉換,將FP32與FP16轉換好的模型分別儲存於目錄之下。(FP16會是FP32一半的模型檔案大小)
接著就可以執行效能量測的過程了,可以看到human-pose-estimation-3d-0001在GPU的運作模式下,辨識的正確度與效能非常不錯。

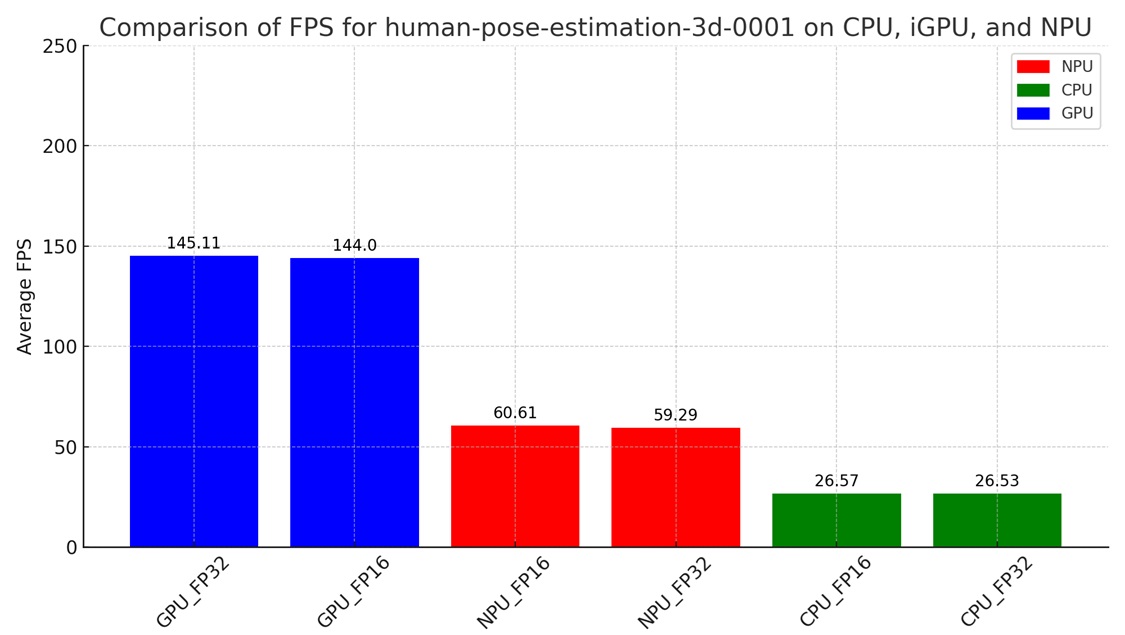
最後分別將CPU、GPU、NPU執行的FP32與FP16的FPS整理如下圖,可以看到因為沒有關於FP16-INT8的模型可供測試,此次GPU、NPU、CPU的模型效能呈現一個有趣的現象,NPU執行的效能較CPU有2倍以上的效能,同時GPU較CPU有5.6倍的效能,很明顯的在human-pose-estimation-3d-0001預訓練模型上,NPU與GPU展現非常棒的辨識效率與正確性。
於OpenVINO Notebooks觀察MoveNet模型的執行效能
MoveNet是Google發表的一款高效能姿勢估計模型,專為即時應用而設計。此模型分為兩個版本:MoveNet Lightning和MoveNet Thunder。Lightning是輕量級版本,適用於行動裝置和低算力環境;而Thunder則是高準確率版本,適用於對精度要求較高的應用場景。MoveNet 能夠在多種姿勢下快速準確地檢測人體關節,廣泛應用於健身應用、姿勢矯正、舞蹈指導等領域。
要下載MoveNet的模型,會發現已經轉移到Kaggle的網站了,MoveNet目前在Kaggle的網址如下:https://www.kaggle.com/code/kerneler/movenet-ultra-fast-and-accurate-pose-detection

Kaggle提供內的程式範例提供了模型下載的網址,可以看到movenet_lightning與movenet_thunder的下載網址:
本文中需要利用的是多人辨識模型來進行效能的觀察,網址如下:https://www.kaggle.com/models/google/movenet/tensorFlow2/multipose-lightning
可以看到提供不同種類的模型下載,觀察Kaggle提供的範例程式碼,可以看到Download the model from TF Hub描述如何得到模型的下載網址:
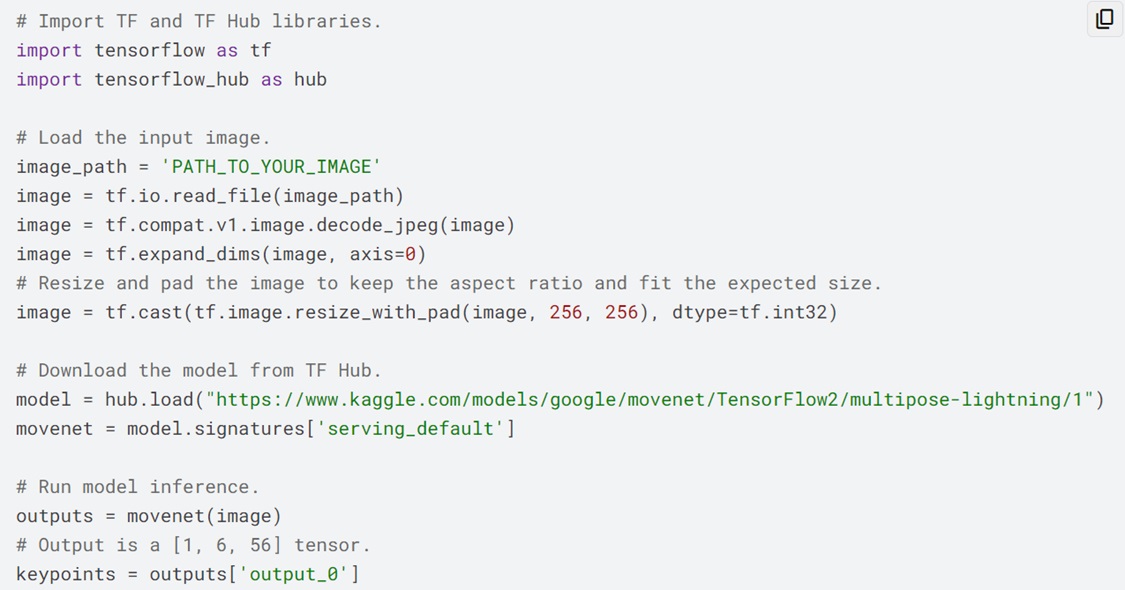
透過以下網址至Kaggle下載MoveNet模型,可以得到多人辨識的MoveNet模型:https://www.kaggle.com/models/google/movenet/TensorFlow2/multipose-lightning/1
獲得MoveNet模型之後,要能夠在OpenVINO裡面使用模型,重點回到如何轉換跟輸出模型。可以透過OpenVINO的save_model函式,將記憶體中運作的模型匯出成FP32與FP16的IR格式。透過下面的範例程式,可以將MoveNet的模型匯出成OpenVINO使用的FP32與 FP16格式。
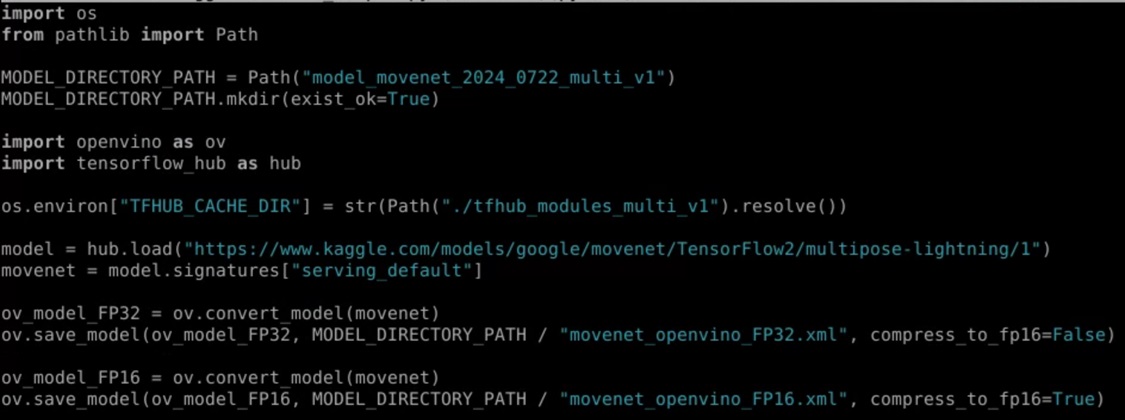
另外還有一些重要的模型轉換範例,可以透過以下的網址練習:https://colab.research.google.com/github/openvinotoolkit/openvino_notebooks/blob/main/notebooks/121-convert-to-openvino/121-convert-to-openvino.ipynb
上面的Colab環境提供模型轉換所需要的觀念。
有了MoveNet的FP32與FP16的模型之後,可以開始進行MoveNet模型測試,我們使用與前面相同的影片進行辨識;要注意的是,此次轉換出來的模型可以使用不同的input shape大小來推論,因此我們嘗試使用不同的input shape大小來觀察,在CPU與iGPU的情況下執行效能的變化。同時,此次的實驗在NPU的運作下,會顯示模型載入錯誤的狀態,因此沒有進行測試。
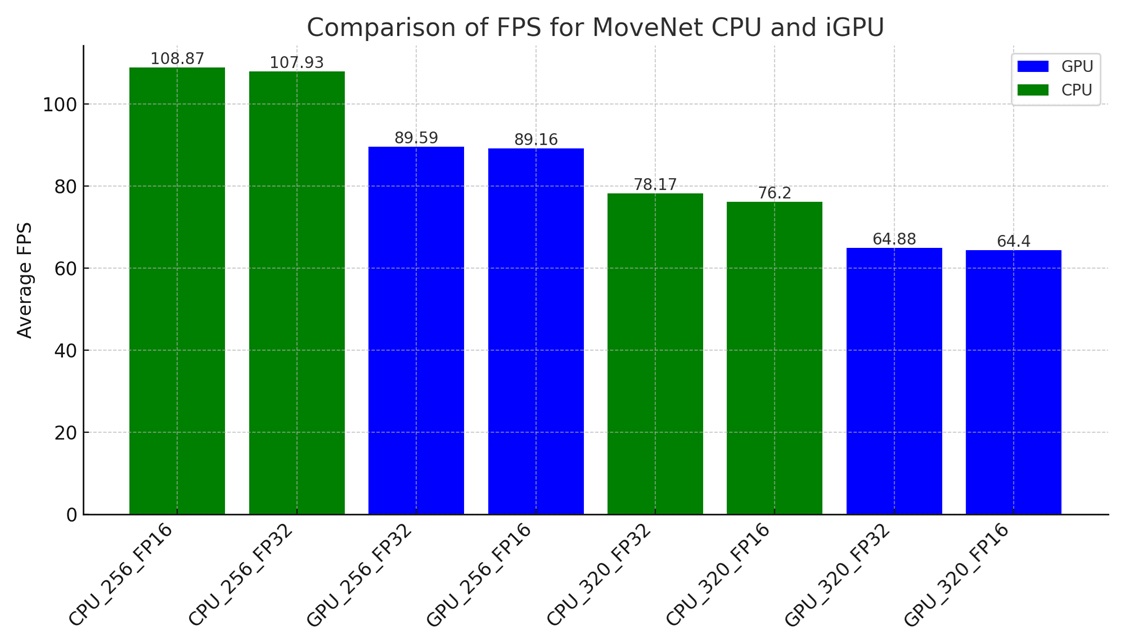
從上圖會發現一個奇妙的現象:轉換出來的模型使用CPU執行的狀態下,不論在FP32或FP16的精確度模型下,都較GPU的執行效率為好,這個情形與之前觀察到的現象是相反的,進一步的可以觀察到CPU與GPU的FPS執行效率大約差1.2倍。官方建議以32的倍數作為input shape,在本次的實驗中,將input shape設定為256以及320。
後記
在這次測試中,我們首先將OpenPose、YOLOv8 、3D Pose與MoveNet的模型轉換為OpenVINO IR格式,並分別在CPU、iGPU及NPU上進行部署。測試的重點在於觀察這些模型在不同運算單元上的效能差異。整體上觀察到的現象是NPU在FP32與FP16的模型精確度環境運作時,確實可以得到比CPU好的執行效能。
本文主要針對OpenVINO提供的姿態辨識預訓練模型,來觀察在Intel Core Ultra具有NPU執行單元的實際FPS效能,未來在進行姿態辨識相關的應用與部署時,希望能夠提供一個在OpenVINO環境運作的基本概念。使用OpenVINO來提升模型的運作效率,在邊緣運算是簡單有效的策略,可以在不更改軟體環境的架構下,大幅度提升模型推論的速度。值得注意的是,在MoveNet的測試中,暫時無法達到預期的效果,iGPU的效能在某些情況下竟然比CPU還慢。這些結果為後續OpenVINO的部署與調教方式提供了參考,並指出了可能的調整方向,為未來的開發和部署提供了一些可行的思考途徑。
本文尚有許多未提及的內容,未來有機會將進行後續實驗,例如異質單元架構的並行處理效能與功耗變化、Async-API的效能測試,以及NNCF模型調教剪枝等。此外,針對整理好的訓練資料集或公開資料集,應用NNCF技術來提升模型的最佳化,不僅能提高原有模型的效率,還能在邊緣運算部署中實現更高效的運作方式。這些研究將為模型的實際應用提供更多支援與最佳化。
參考資料
- (2024). OpenVINO Toolkit Documentation. Retrieved from https://docs.openvino.ai/2024/get-started/install-openvino.html
- (2024). Intel AI PC Overview. Retrieved from https://www.asrockind.com/zh-tw/NUC%20BOX-155H
- (2024). YOLOv8 Pose Estimation Model Documentation. Retrieved from https://docs.ultralytics.com
- Carnegie Mellon University. (2023). OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. Retrieved from https://github.com/CMU-Perceptual-Computing-Lab/openpose
- (2023). MoveNet: Ultra Fast and Accurate Pose Detection. Retrieved from https://www.kaggle.com/models/google/movenet
- (2024). Intel Neural Compute Stick 2 Documentation. Retrieved from https://docs.openvino.ai/2024/get-started/configurations/configurations-intel-npu.html
- 李盛安. (2021). 優化OpenVINO模型效能:參數設定影響實測. Medium. Retrieved from https://makerpro.medium.com/%E5%84%AA%E5%8C%96openvino%E6%A8%A1%E5%9E%8B%E6%95%88%E8%83%BD-%E5%8F%83%E6%95%B8%E8%A8%AD%E5%AE%9A%E5%BD%B1%E9%9F%BF%E5%AF%A6%E6%B8%AC-46fa353f108c
- 李盛安. (2021). AI提升教學效能. MakerPro. Retrieved from https://makerpro.cc/2021/09/ai-improves-teaching-effectiveness/

專長:醫療資訊系統、生物資訊、雲端運算、大數據、人工智慧、分散式系統、行動裝置程式設計、軟體工程、行動資訊系統、數位圖像處理
- 以3D感知開啟智慧機器人新時代:從深度相機到OpenVINO的邊緣智慧革命 - 2025/12/12
- OpenVINO 2024.2姿態模型效能評估:以OpenPose、YOLOv8與3D-Pose為例 - 2024/08/05
- 優化OpenVINO模型效能:參數設定影響實測 - 2021/08/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


