
邁向通用:ACT如何讓機器人「預見未來」動作?
ACT (Action Chunking with Transformers) 改變了機器人的決策方式。它讓機器人從一個只能看到當前的「短視者」,變成了能夠預見未來行動、動作連貫、且極具穩健性的「短程規劃大師」。

讓機器人開始「思考下一步」的三個關鍵模型:ACT、RDT-1B和π₀
剖析 ACT、RDT-1B和π₀的發展,一個共同的核心事實逐漸清晰:機器人的智能正在從「控制」升級到「理解」與「生成」。

為何Google、NVIDIA和Intel都支持LeRobot開源專案?
LeRobot 的快速崛起,除了提供了一套優雅的軟體架構來處理 VLA 模型的核心挑戰,更透過與 Google、NVIDIA、Intel 和 Hugging Face 自身的深度協作,構築了一個從雲端訓練到邊緣部署的完整生態閉環。

WorldVLA:視覺、語言與動作的融合之路
WorldVLA 是一個自回歸動作世界模型,它將動作和圖像的理解與生成統一起來。 WorldVLA 將視覺-語言-動作 (VLA) 模型(動作模型)和世界模型整合在一個框架中。
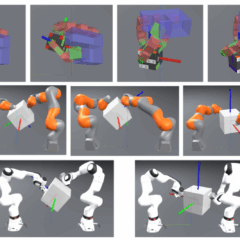
為生成機器人訓練用資料而生的MIT PhysicsGen
近期麻省理工學院(MIT)與機器人與人工智慧研究所(RAI)合作推動名為PhysicsGen的計畫,運用Gen AI來生成實體性、物理性資料,再將資料供AI模型訓練用。

【Podcast】進入世界模型時代:AI 的新智慧引擎
在這集精彩的 Podcast 節目中,我們帶領你進入「世界模型」(World Model)的核心概念,探索這項技術如何讓 AI 不只是辨識環境,而能模擬世界演進、進行推理與計劃。