作者:楊亦誠
隨著生成式AI的興起,和大語言模型對話聊天的應用變得非常熱門,但這類應用往往只能簡單地和你「聊聊家常」,並不能針對某些特定產業提供非常專業和精準的答案,這是大語言模型(以下簡稱LLM)在時效性和專業性上的侷限所導致:現在市面上大部分開源的LLM幾乎都只是使用某一個時間點前的公開資料進行訓練,因此無法學習到這個時間點之後的知識,並且也無法保證在專業領域上知識的準確性。
那有沒有辦法讓你的模型學習到新的知識呢?當然有,這裡一般有2種方案:
- 微調(Fine-tuning):微調是透過對特定領域資料庫進行廣泛的訓練來調整模型,這樣可以內化專業技能和知識。然後,微調也需要大量的資料、大量的運算資源和定期的重新訓練以保持時效性。
- 檢索增強生成(RAG):RAG的全稱是Retrieval-Augmented Generation,它的原理是透過檢索外部知識提供上下文回應,在無需對模型進行重新訓練的情況,保持模型對於特定領域的專業性,同時透過更新資料查詢庫,可以實現快速地知識更新。但RAG在構建以及檢索知識庫時,會佔用更多額外的記憶體資源,其回應延遲也取決於知識庫的大小。
從以上比較可以看出,在沒有足夠GPU運算資源對模型進行重新訓練的情況下,RAG方式對普通使用者來說更為友好。本文就要來探討如何利用OpenVINO以及LangChain工具構建屬於你的RAG問答系統。
RAG流程
RAG可以幫助LLM「學習」到新的知識並提供更可靠的答案,它的實現流程其實並不複雜,主要可以分為以下兩個部分:
- 構建知識庫檢索
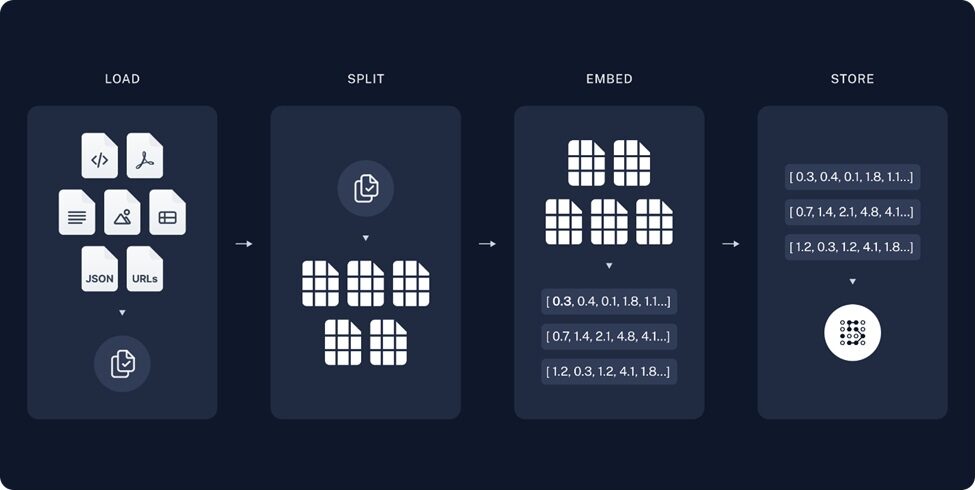
構建知識庫流程
- 載入(Load):讀取並解析使用者提供的非結構化資訊,這裡的非結構化資訊可以是例如PDF或者Markdown這樣的檔案形式。
- 分割(Split):將檔案中段落按標點符號或是特殊格式進行拆分,輸出若干片語或句子,如果拆分後的單句太長,會不便於後期LLM理解以及抽取答案;如果太短又無法保證語義的連貫性。因此我們需要限制拆分長度(chunk size);此外為了保證chunk之間文字語義的連貫性,相鄰chunk會有一定的重疊,在LangChain中我可以透過定義Chunk overlap來控制這個重疊區域的大小。
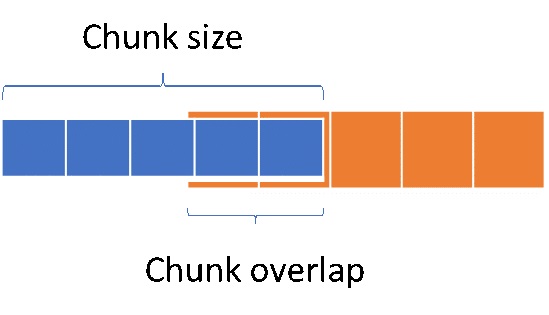
Chunk size和Chunk overlap範例。
- 向量化(Embedding):使用深度學習模型將拆分後的句子向量化,把一段文字根據語義在一個多維空間的座標系裡面表示出來,以便知識庫儲存以及檢索;語義相近的兩句話所對應的向量相似度會相對較大,反之則較小,以此方式我們可以在檢索時,判斷知識庫裡句子是否可能為問題的答案。
- 儲存(Store):構建知識庫,將文字以向量的形式儲存,用於後期檢索。
- 檢索和答案生成
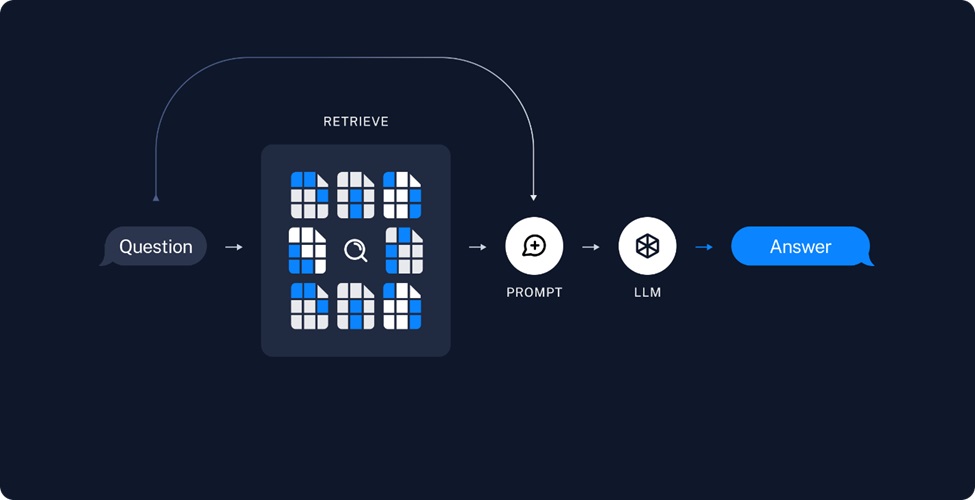
答案生成流程。
- 檢索(Retrieve):當使用者問題輸入後,首先會利用embedding模型將其向量化,然後在知識庫中檢索與之相似度較高的若干段落,並對這些段落的相關性進行排序。
- 生成(Generate):將這個可能包含答案,且相關性最高的Top K個檢索結果,包裝為Prompt輸入,導入LLM中,據此來生成問題所對應的答案。
關鍵步驟
在利用OpenVINO構建RAG系統過程中,有以下一些關鍵步驟:
1. 封裝Embedding模型類
由於在LangChain的chain pipeline會呼叫embedding模型類中的embed_documents和embed_query來分別對知識庫檔案和問題進行向量化,而他們最終都會呼叫encode函數來實現每個chunk具體的向量化實現,因此在自訂的embedding模型類中也需要實現這樣幾個關鍵方法,並透過OpenVINO進行推論任務的加速。
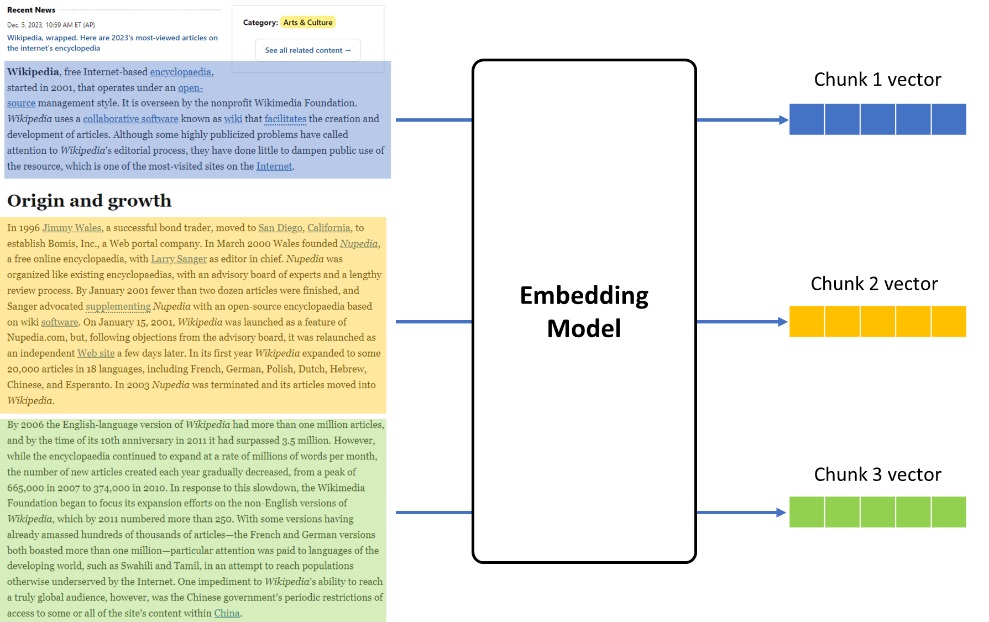
embedding模型推論示意。
由於在RAG系統中的各個chunk之間的向量化任務往往沒有依賴關係,因此我們可以透過OpenVINO的AsyncInferQueue介面將這部分任務平行化,以提升整個embedding任務的輸送量。
for i, sentence in enumerate(sentences_sorted):
inputs = {}
features = self.tokenizer(
sentence, padding=True, truncation=True, return_tensors='np')
for key in features:
inputs[key] = features[key]
infer_queue.start_async(inputs, i)
infer_queue.wait_all()
all_embeddings = np.asarray(all_embeddings)
此外,從HuggingFace Transfomers資源庫匯出的embedding模型是不包含mean_pooling和正規化操作的,因此我們需要在取得模型推論結果後,再實現這部分的後處理任務,並將其作為callback function與AsyncInferQueue進行綁定。
def postprocess(request, userdata):
embeddings = request.get_output_tensor(0).data
embeddings = np.mean(embeddings, axis=1)
if self.do_norm:
embeddings = normalize(embeddings, 'l2')
all_embeddings.extend(embeddings)
infer_queue.set_callback(postprocess)
2. 封裝LLM模型類
由於LangChain已經可以支援HuggingFace的pipeline作為其LLM物件,因此這裡我們只要將OpenVINO的LLM推論任務封裝成一個HF的text generation pipeline即可。此外為了串流輸出答案(逐字列印),需要透過TextIteratorStreamer物件定義一個串流生成器。
streamer = TextIteratorStreamer(
tok, timeout=30.0, skip_prompt=True, skip_special_tokens=True
)
generate_kwargs = dict(
model=ov_model,
tokenizer=tok,
max_new_tokens=256,
streamer=streamer,
# temperature=1,
# do_sample=True,
# top_p=0.8,
# top_k=20,
# repetition_penalty=1.1,
)
if stop_tokens is not None:
generate_kwargs["stopping_criteria"] = StoppingCriteriaList(stop_tokens)
pipe = pipeline("text-generation", **generate_kwargs)
llm = HuggingFacePipeline(pipeline=pipe)
3. 設計RAG prompt template
當完成檢索後,RAG會將相似度最高的檢索結果包裝為Prompt,讓LLM進行篩選與重構,因此我們需要為每個LLM設計一個RAG prompt template,用於在Prompt中區分這些檢索結果,而這部分的提示資訊我們又可以稱之為context上下文,以供LLM在生成答案時進行參考。以ChatGLM3為例,它的RAG prompt template可以是這樣的:
"prompt_template": f"""<|system|>
{DEFAULT_RAG_PROMPT_CHINESE }"""
+ """
<|user|>
問題: {question}
已知內容: {context}
回答:
<|assistant|>""",
其中:
- {DEFAULT_RAG_PROMPT_CHINESE}為我們事先根據任務要求定義的系統提示詞。
- {question}為使用者的問題。
- {context}為Retriever檢索到的、可能包含問題答案的段落。
例如,假設我們的問題是「飛槳的四大優勢是什麼?」,對應從飛槳檔案中取得的Prompt輸入就是:
<|system|>
基於以下已知資訊,請簡潔並專業地回答用戶的問題。如果無法從中得到答案,請說 「根據已知資訊無法回答該問題」 或「沒有提供足夠的相關資訊」。不允許在答案中添加編造成分。另外,答案請使用中文。
<|user|>
問題: 飛槳的四大領先技術是什麼?
已知內容: ## 安裝
PaddlePaddle最新版本: v2.5
跟進PaddlePaddle最新特性請參考我們的版本說明
四大領先技術
開發便捷的產業級深度學習框架
飛槳深度學習框架採用基於程式設計邏輯的組網範式,對於普通開發者而言更容易上手,符合他們的開發習慣。同時支持聲明式和命令式程式設計,兼具開發的靈活性和高性能。網路結構自動設計,模型效果超越人類專家。
支援超大規模深度學習模型的訓練
飛槳突破了超大規模深度學習模型訓練技術,實現了支援千億特徵、萬億參數、數百節點的開源大規模訓練平臺,攻克了超大規模深度學習模型的線上學習難題,實現了萬億規模參數模型的即時更新。
查看詳情
支援多端多平台的高性能推論部署工具
…
<|assistant|>
4.創建RetrievalQA檢索
在文字分割這個任務中,LangChain支援了多種分割方式,例如按字元數的CharacterTextSplitter,針對Markdown檔案的MarkdownTextSplitter,以及利用遞迴方法的RecursiveCharacterTextSplitter,當然你也可以透過繼承TextSplitter父類來實現自訂的split_text方法,例如在中文檔案中,我們可以採用按每句話中的標點符號進行分割。
class ChineseTextSplitter(CharacterTextSplitter):
def __init__(self, pdf: bool = False, **kwargs):
super().__init__(**kwargs)
self.pdf = pdf
def split_text(self, text: str) -> List[str]:
if self.pdf:
text = re.sub(r"\n{3,}", "\n", text)
text = text.replace("\n\n", "")
sent_sep_pattern = re.compile(
'([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;
sent_list = []
for ele in sent_sep_pattern.split(text):
if sent_sep_pattern.match(ele) and sent_list:
sent_list[-1] += ele
elif ele:
sent_list.append(ele)
return sent_list
接下來我們需要載入預先設定的好的prompt template,創建rag_chain。
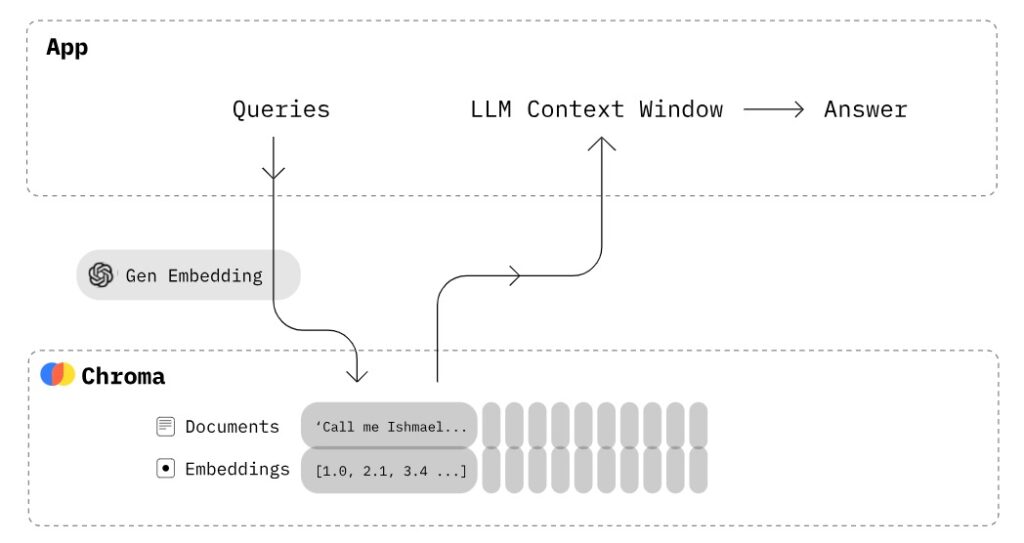
Chroma引擎檢索流程。
這裡我們使用Chroma作為搜尋引擎,在LangChain中,Chroma預設使用cosine distance作為向量相似度的評估方法, 同時可以透過調整db.as_retriever(search_type= “similarity_score_threshold”),或是db.as_retriever(search_type= “mmr”)來更改預設檢索策略,前者為帶閾值的相似度搜尋,後者為max_marginal_relevance演算法。當然Chroma也可以被替換為FAISS檢索引擎,使用方式也是相似的。
此外透過定義as_retriever 函數中的{“k”: vector_search_top_k},我們還可以改變檢索結果的回覆數量,有助於LLM取得更多有效資訊,但也會因此增加Prompt的長度,提高推論延遲,因此不建議將該數值設定太高。創建rag_chain的完整程式碼如下:
documents = load_single_document(doc.name)
text_splitter = TEXT_SPLITERS[spliter_name](
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
texts = text_splitter.split_documents(documents)
db = Chroma.from_documents(texts, embedding)
retriever = db.as_retriever(search_kwargs={"k": vector_search_top_k})
global rag_chain
prompt = PromptTemplate.from_template(
llm_model_configuration["prompt_template"])
chain_type_kwargs = {"prompt": prompt}
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
)
5. 答案生成
創建以後的rag_chain物件可以透過rag_chain.run(question)來回應使用者的問題。將它和執行緒函數綁定後,就可以從LLM物件的streamer中獲取串流的文字輸出。
def infer(question):
rag_chain.run(question)
stream_complete.set()
t1 = Thread(target=infer, args=(history[-1][0],))
t1.start()
partial_text = ""
for new_text in streamer:
partial_text = text_processor(partial_text, new_text)
history[-1][1] = partial_text
yield history
本範例的完整程式碼網址如下:https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/254-llm-chatbot/254-rag-chatbot.ipyn
最終效果
最終效果如下圖所示,當使用者上傳了自己的檔案後,點擊Build Retriever便可以創建知識檢索資料庫,同時也可以根據自己檔案的特性,透過調整檢索資料庫的配置參數來實現更高效率的搜尋。當完成檢索資料庫創建後,就可以在對話方塊中與LLM進行問答互動了。
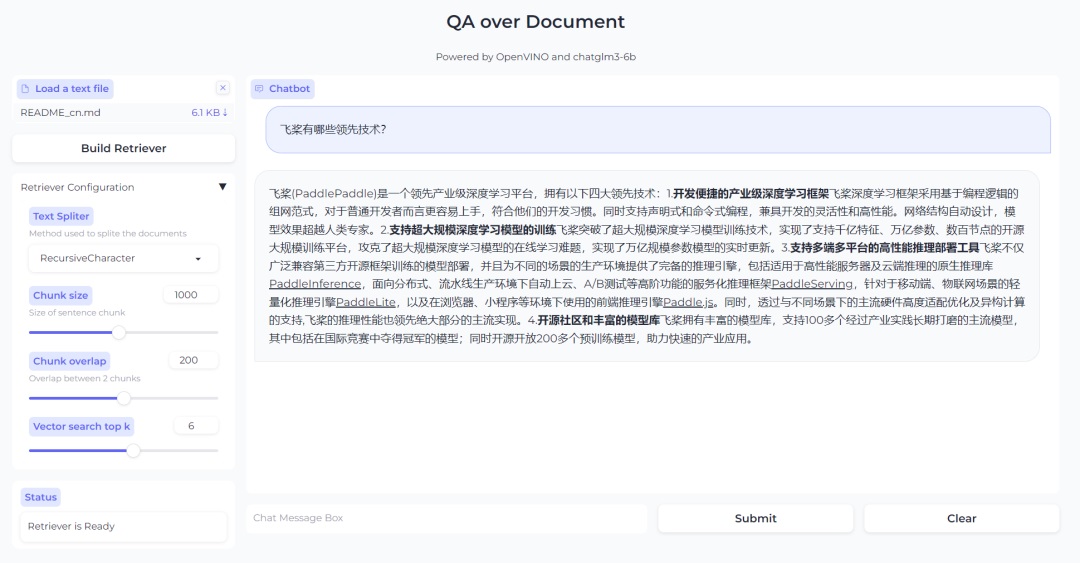
以RAG為基礎的問答系統效果。
總結
在醫療、工業等領域,產業知識庫的構建已經成為了一個普遍需求,透過LLM與OpenVINO的加持,我們可以讓使用者對於知識庫的查詢變得更精準、高效率,帶來更友善的互動體驗。
參考資料
- LangChian RAG:https://python.langchain.com/docs/use_cases/question_answering/
- OpenVINO非同步API:https://docs.openvino.ai/2023.2/openvino_docs_OV_UG_Python_API_exclusives.html#asyncinferqueue

- 輕薄型筆電OK!利用OpenVINO部署Phi-3.5「全家餐」 - 2024/09/20
- LangChain框架已正式支援OpenVINO! - 2024/06/12
- 如何在Windows平台呼叫NPU部署深度學習模型 - 2024/03/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!