2025年首發的最新版本OpenVINO來了!生成式AI (GenAI)的品質和應用範圍不斷呈現爆炸性成長,每天都有全新的最先進模型湧現,受到廣泛關注的DeepSeek也是其中之一;預期這樣的發展動能將持續下去。
OpenVINO的最新版本2025.0,除了性能的再次提升,也擴大了GenAI模型的支援範圍,並針對英特爾(Intel)的神經處理單元(NPU)導入了關鍵最佳化功能。在接下來的文章中,讓我們一起來探索這些令人興奮的更新!
支援全新影像生成案例與模型
OpenVINO 2025.0版本在運作於Intel CPU和GPU的OpenVINO GenAI流水線,導入了對 FLUX.1影像生成模型的支援,包括Dev和Schnell版本變體;開發者現在可以透過Optimum-Intel匯出這些Flux模型,並將它們與Text2ImagePipeline一起使用來產生影像。由於Flux對精度變化非常敏感,我們一直相當努力提高生成性能並維持模型準確性。
值得一提的是,我們也透過LoRA支援客製化模型。先前版本的Safetensor檔案中導入了對模型微調技術LoRA (Low-Rank Adaptation)的支持,該技術能支援將多個轉接器連結到現有模型,並在生成過程中開啟和關閉它們,無需重新編譯模型。如今我們在增加對Flux模型的支援之同時,也為該系列模型導入了對LoRA轉接器的支援;可以從Hugging Face Hub下載轉接器,並透過我們的GenAI Text2Image Pipeline輕鬆使用它們。
範例:以LoRA強化的FLUX.1-Dev影像生成
下面的圖片展示了應用和未應用紗線藝術風格LoRA的INT8量化FLUX.1-dev模型的輸出,以愛因斯坦為(Albert Einstein)主角的圖片是從我們的LoRA text2image樣本取得的,使用的提示詞為「albert einstein,yarn art style」(初始種子值=420, 迭代次數=20)。

應用和未應用LoRA轉接器的INT8量化FLUX.1-dev模型的輸出比較。
為了支援更多使用影像生成模型的創意場景,我們為兩條新流水線──Image2Image和Inpainting──導入預覽支援。
顧名思義, Image2Image流水線是輸入圖片和文字,並根據兩者生成新圖片,這能以更具可預測的方式產生新圖。在Inpainting流水線,則是以生成的內容替換輸入圖片的一部分(使用遮罩圖片來指定)。此外若有需要,這兩條流水線都支援模型的LoRA客製化。
文字生成場景的改善
新版OpenVINO還在LLMPipeline API導入了對提示查找解碼(prompt lookup decoding)的預覽支援,這是推測解碼(speculative decoding)的簡化,它用輸入提示本身內的直接查找機制取代了傳統的草稿模型,這有助於在請求高度相似的情況下顯著減少產生延遲。例如,以一組文件為基礎進行的問答可以取得性能優勢,因為答案是根據作為提示本身一部分的那些文件所產生。
如我們的範例所示,這個功能可透過在LLMPipeline中進行最小程度的更動來實現,基本上只需要在流水線中啟用提示查找作為參數,並修改生成配置以添加兩個重要參數:要在提示範圍中查找的詞元(token)數量,以及匹配後要取得的詞元數量。
而由於LLM權重相當佔用記憶體,因此生成過程中的記憶體使用會是應用上的一個重要考量。 KV Cache代表額外的記憶體消耗,並且可能會變得非常大;為此我們導入了KV Cache壓縮作為減少記憶體消耗的方法,在新版本OpenVINO中,我們在CPU的預設是啟用該功能。為了確保壓縮的精準度,我們導入了非對稱INT8壓縮,事實證明這種壓縮通常最精準。如果需要,也可以選擇INT4壓縮來進一步減少記憶體消耗。我們也計劃在未來的版本中啟用其他壓縮技術,敬請期待。
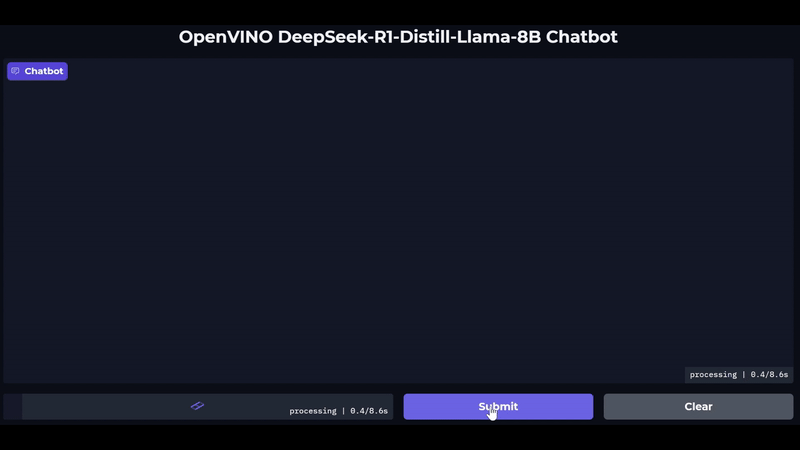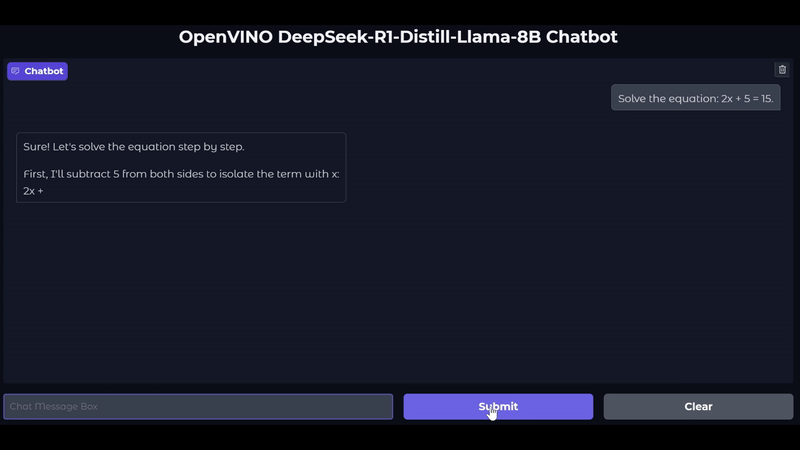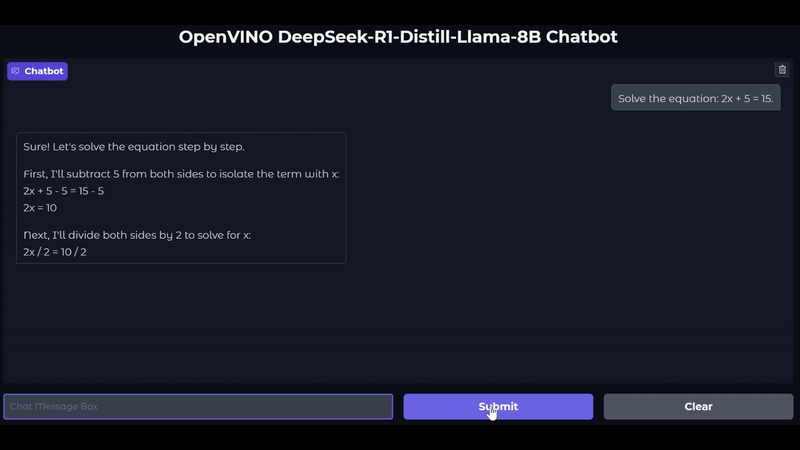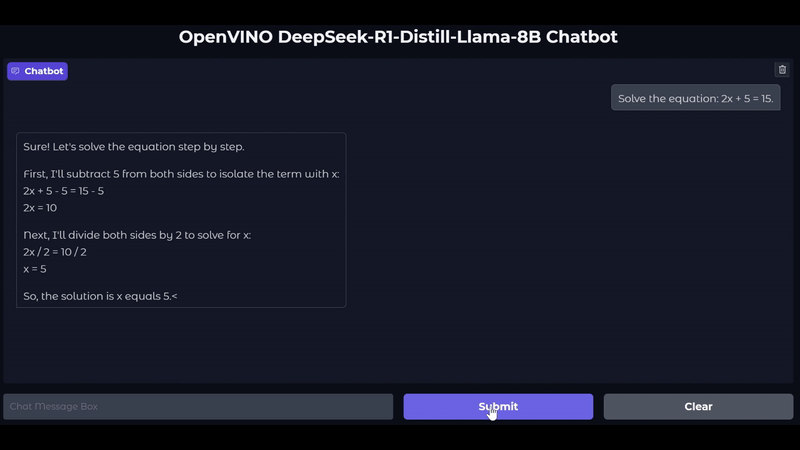
此外,我們也一直致力於支援和驗證最新的模型,包括Mistral-7B-Instruct-v0.2、Qwen2.5,當然我們也支援以LLama和Qwen架構為基礎的DeepSeek蒸餾模型。您可以在我們的最新Notebook中,探索使用DeepSeek-R1蒸餾模型進行LLM推論。下圖顯示與在Intel Core Ultra 200V GPU上運作的DeepSeek-R1-Llama-8b模型的對話。
透過torch.compile路徑支援Intel NPU
OpenVINO已經在torch.compile生態系作為編譯器亮相一段時間了;它已經在CPU和GPU上得到支持,並且在性能方面產生的結果非常接近原生OpenVINO推論。在2025.0版本中,我們導入了選擇Intel NPU裝置時的預覽支援。這包括對來自TorchVision、Timm和TorchBench資源庫300多個模型的支援。
啟用它很容易,如以下指令:
opts = {"device" : "NPU"}
model = torch.compile(model, backend="openvino", options=opts)
不同模型會有不同的結果,因此建議以你自己的模型來嘗試,看看有那些改善;我們建議在Intel Core Ultra Series 2平台或更新版本上使用它。
結語
隨著我們迎接令人興奮的新年,生成性AI的無窮潛力將繼續重塑我們的創作、工作和創新的方式。透過OpenVINO 2025.0,我們強化了對模型覆蓋範圍的支援,提供更快的推論性能以及擴展對Intel NPU的支援。這只是一個開始——我們計劃今年還會發佈更多版本,敬請隨時關注接下來的更新!
(參考原文:Introducing OpenVINO 2025.0)

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


