作者: Jack OmniXRI,Intel Software Innovator
2022年底 OpenAI 引爆大語言模型(Large Lauguage Model,LLM)及生成式人工智慧(Generative Artificial Intelligence,GenAI),從此有各種文字、聲音、影像及多模態的應用,其中「虛擬主播」就是很常的應用例,如像民視的「敏熙」就是很經典的案例。
說到虛擬主播,其演進歷史也有數十年,早年需由美工人員大費周章設計好3D人物模型,再請配音員配上固定對白,最後由動畫人員把肢體動作、對白和嘴形對好,才能完成影片輸出,常見於高階 3D 電玩中較精緻的非玩家角色(Non-Player Character,NPC)。
後來隨著傳統電腦視覺及3D動畫技術演進,慢慢開始有了虛擬代理人(Virtual Agent)、VTuber (Video + Youtuber)出現,只要事先準備好可愛的3D人物模型(公仔),加上高階動作補捉器(Motion Capture),再請真人表演肢體及臉部動作來驅動3D公仔,就可大幅減少美工及動畫人員的工作。早期電腦性能較差,只能採預錄加上後處理合成方式處理,像日本「初音未來」這類「虛擬偶像」及擬真 3D 電影「阿凡達」就是知名代表。
後來隨電腦性能及電腦視覺技術成熟,只需使用一般網路攝影機,就能即時偵測到表演者的動作、表情並驅動3D公仔,一般會稱呼表演者為 VTuber (Video Youtuber),像日本知名「絆愛」、台灣 Yahoo TV 的「虎妮」就屬此類。這樣的技術很適合哪些不露臉的表演者和真實世界的互動,但缺點也是沒有真人就無法操作了,且真人表演不流暢也會影響虛擬人物表現。
十多年前深度學習電腦視覺及自然語言處理(Natual Language Processing,NLP)技術興起,讓電腦有機會能完全控制3D公仔的肢體動作、語音轉文字(Speech To Text,STT)、自然語言理解(Natual Language Understanding,NLU)、對話內容產生、語音轉文字(Text To Speech,TTS),於是開始有了虛擬助理(Vitrual Assistant)和虛擬代理人(Virtual Agent)出現。而隨著大語言模型及生成式技術越來越成熟,像真人一樣互動的數位分身(中國大陸慣稱數字人–即Digital Human、Meta Human)也開始出現在各種場域中,如捷運站的虛擬客服。

圖1:虛擬分身演進,3D人物、人臉建模,動作、表情補捉、真人驅動VTuber,大語言模型及生成式AI客服、主播。(OmniXRI整理製作, 2024/12/12)
為了使大家能更進一步理解如何實作一個簡單離線版(邊緣端)的虛擬主播,可以輸入所需文字,產生對應語音,配合閉嘴人物影片生成新的對嘴影片。接下來就分別從「推論硬體及環境建置介紹」、「MeloTTS 文字轉語音生成」、「Wav2Lip 自動對嘴影片生成」及「建置完整虛擬主播」等四大部份作更進一步說明。
完整範例程式可參考下列網址:https://github.com/OmniXRI/digital_human
(註:本文範例不適用 Google Colab 執行,僅限Intel OpenVINO Notebooks虛擬環境下使用)
1. 推論硬體及環境建置介紹
這裡選用了 Intel AI PC Asus NUC 14 Pro (Core Ultra 5 125H, 內建 Arc GPU, 10TOPS NPU, DDR5 32GB)作為邊緣推論裝置,完整規格請見參考文獻[1]。建議使用前先到官網更新一下NPU驅動程式[2]。(註:如果你仍是使用 Core i3/i5/i7 12/13/14代CPU,在Windows 10運作,原則上以下各範例還是可以執行,只是速度上會慢上許多。)
本文主要使用Windows 11,工作環境是根據 Intel OpenVINO Notebooks 建議的 Python 虛擬環境。如果你未曾安裝過OpenVINO及Notebooks則可參考官方Github 說明[3]進行全新的安裝。
(註:如需中文安裝說明,可參考[4]第2小節說明)
OpenVINO Notebooks目前最新版(latest)為2024.5版,原則大部份的範例都可執行在OpenVINO 2024.x 版。由於w2vlip 範例[5] 只存在 2024.5版中,所以如果電腦中已安裝過較舊版本OpenVINO Notebooks,請先下載最新版openvinotoolkit/openvino_notebooks的ZIP格式檔案,解壓縮後再把 /notebooks/wav2lip 整個檔案夾複製到自己電腦上原先 /openvino_notebooks/notebooks 路徑下,才能進行後面的工作。
不管全新或部份安裝,為避免影響到原先的範例程式,所以請先將 /notebooks/wav2lip 檔案夾複製一份,並更名為 /notebooks/digital_humnan,以便後續將MeloTTS和Wav2Lip整合在一起。接著將 https://github.com/OmniXRI/digital_human 中三個 ipynb 範例下載到 \digitl_human 路徑下,以利後續測試。
另外由於程式會使用到影音相關處理函式,但這些未包括在 OpenVINO & Notebooks 範例中,所以需手動安裝 ffmpeg 函式庫。請確認已進入 OpenVINO Notebooks Python 虛擬環境中後再安裝,如以下指令所示:
pip install ffmpeg
2. MeloTTS 文字轉語音生成
目前 OpenVINO 在文字轉語音(TTS)方面雖有提供 OuteTTS 和 Parler-TTS 範例,但本文使用另一個更輕量的模型 MeloTTS [6]。它提供了多國語言,如英文、法文、日文、韓文、西班牙文等,其中當然也有包含中文(可中英文混合)。使用上非常簡單,只需提供待發音之文字內容、語速即可。
由於 MeloTTS 尚未正式加入 OpenVINO Notebooks 中,所以這裡我們需要手動安裝相關套件。安裝前,首先啟動 OpenVINO Notebooks Python 虛擬環境,但先不要啟動 Jupyter Notebooks 環境,進到 /openvino_notebooks/notebooks/ 路徑中準備安裝。
接著到 https://github.com/zhaohb/MeloTTS-OV/tree/speech-enhancement-and-npu ,按下綠色「<> Code」,選擇「Download ZIP」,解壓縮後把 \MeloTTS-OV-speech-enhancement-and-npu 檔案夾內所有內容複製到 \openvino_notebooks\notebooks\digital_human 下。
(註:請不要直接複製網頁上git clone命令,這樣會誤下載到標準版本,導致 OpenVINO 無法正確執行。)
再來進到指定路徑,開始安裝必要套件。
cd digital_human
pip install -r requirements.txt
pip install openvino nncf
python setup.py develop # or pip install -e .
python -m unidic download
python -m nltk.downloader averaged_perceptron_tagger_eng
pip install deepfilternet # optional for enhancing speech
pip install ffmpeg # 一定要裝,不然影音內容無法顯示
完成後執行下列命令進行文字轉語音測試。這裡 language 設為 ZH (中英混合)即可, tts_device 可設為CPU、GPU,而bert_device則可設為 CPU、GPU、NPU。
python test_tts.py --language ZH --tts_device CPU --bert_device CPU
第一次執行會花比較多的時間下載模型及轉換成OpenVINO用的IR格式(bin+xml),完成的模型會存放在 \tts_ov_ZH 路徑下。執行完成後會得到 ov_en_int8_ZH.wav ,語音內容為「我們探討如何在Intel平台上轉換和優化atificial intelligence 模型」,可開啟聲音播放軟體進行檢查。
完成上述步驟後才能運作下列簡易版帶介面程式 MeloTTS_run.ipynb 。這個範例有提供 Gradio 介面,方便大家以網頁方式重覆輸入測試字串及檢查生成聲音檔案內容。
下次想要測試時,由於已有轉換好的模型,所以直接開啟並執行這個範例即可執行文字轉語音工作。
# MeloTTS for OpenVINO 單獨執行含Gradio介面範例
#
# by Jack OmniXRI, 2024/12/12
from melo.api import TTS
from pathlib import Path
import time
# MeloTTS 文字轉語音基本參數設定
speed = 1.0 # 調整語速
use_ov = True # True 使用 OpenVINO, False 使用 PyTorch
use_int8 = True # True 啟用 INT8 格式
speech_enhance = True # True 啟用語音增強模式
tts_device = "CPU" # 指定 TTS 推論裝置 , "CPU" 或 "GPU"(這裡指 Intel GPU)
bert_device = "CPU" # 指定 Bert 推論裝置, "CPU" 或 "GPU" 或 "NPU"
lang = "ZH" # 設定語系, EN 英文, ZH 中文(含混合英文、簡繁中文皆可)
# 指定測試文字轉語音字串
if lang == "ZH":
text = "我們討如何在 Intel 平台上轉換和優化 artificial intelligence 模型"
elif lang == "EN":
text = "For Intel platforms, we explore the methods for converting and optimizing models."
# 若指定語音增強模式則新增 process_audio() 函式
if speech_enhance:
from df.enhance import enhance, init_df, load_audio, save_audio
import torchaudio
# 將輸入聲音檔案處理後轉存到新檔案中
def process_audio(input_file: str, output_file: str, new_sample_rate: int = 48000):
"""
Load an audio file, enhance it using a DeepFilterNet, and save the result.
Parameters:
input_file (str): Path to the input audio file.
output_file (str): Path to save the enhanced audio file.
new_sample_rate (int): Desired sample rate for the output audio file (default is 48000 Hz).
"""
model, df_state, _ = init_df()
audio, sr = torchaudio.load(input_file)
# Resample the WAV file to meet the requirements of DeepFilterNet
resampler = torchaudio.transforms.Resample(orig_freq=sr, new_freq=new_sample_rate)
resampled_audio = resampler(audio)
enhanced = enhance(model, df_state, resampled_audio)
# Save the enhanced audio
save_audio(output_file, enhanced, df_state.sr())
# 初始化 TTS
model = TTS(language=lang, tts_device=tts_device, bert_device=bert_device, use_int8=use_int8)
# 取得語者資訊
speaker_ids = model.hps.data.spk2id
speakers = list(speaker_ids.keys())
# 若指定使用 OpenVINO, 檢查該語系是否已處理過,若無則進行轉換,結果會存在 \tts_ov_語系 路徑下
if use_ov:
ov_path = f"tts_ov_{lang}"
if not Path(ov_path).exists():
# 將原始模型轉換成 OpenVINO IR (bin+xml) 格式
model.tts_convert_to_ov(ov_path, language= lang)
# 進行模型初始化
model.ov_model_init(ov_path, language = lang)
if not use_ov: # 若未使用 OpenVINO
for speaker in speakers:
output_path = 'en_pth_{}.wav'.format(str(speaker))
start = time.perf_counter()
model.tts_to_file(text, speaker_ids[speaker], output_path, speed=speed*0.75, use_ov = use_ov)
end = time.perf_counter()
else: # 若使用 OpenVINO
for speaker in speakers:
output_path = 'ov_en_int8_{}.wav'.format(speaker) if use_int8 else 'en_ov_{}.wav'.format(speaker)
start = time.perf_counter()
model.tts_to_file(text, speaker_ids[speaker], output_path, speed=speed, use_ov=use_ov)
if speech_enhance:
print("Use speech enhance")
process_audio(output_path,output_path)
end = time.perf_counter()
dur_time = (end - start) * 1000
print(f"MeloTTS 文字轉語音共花費: {dur_time:.2f} ms")
# 使用 Gradio 產生互動介面
import gradio as gr
# 定義文字轉語音處理函式 tts()
# 輸入: content(字串)、 use_ov(布林值)、 speed(數值)
# 輸出: "MeloTTS 文字轉語音共花費: xx.xx ms"(字串)、 語音檔案名稱(字串)
def tts(content, use_ov, speed):
start = time.perf_counter()
model.tts_to_file(content, speaker_ids[speaker], output_path, speed=speed/100, use_ov=use_ov)
if speech_enhance:
print("Use speech enhance")
process_audio(output_path,output_path)
end = time.perf_counter()
dur_time = (end - start) * 1000
audio = "ov_en_int8_ZH.wav"
result = f"MeloTTS 文字轉語音共花費: {dur_time:.2f} ms"
return result, audio
# 建立輸人及輸出簡單應用介面
# fn: 介面函數名稱
# inputs: 輸人格式, 文字(標籤:名字, 值: “請輸入文字內容")、使用 OpenVINO(複選盒)、滑動桿(標籤:語速(%),最小值50,最大值200,預設值100)
# outputs: 輸出格式,結果字串(標籤:輸出)、輸出音檔(標籤:輸出結果, 檔格式式: filetype)
demo = gr.Interface(
fn=tts,
inputs=[gr.Textbox(label="文字", value = "請輸入文字內容"),
gr.Checkbox(value=True, label="Use_OpenCV"),
gr.Slider(50, 200, value=100, label="語速(%)") ],
outputs=[gr.Textbox(label="轉換時間"),
gr.Audio(label="輸出結果", type="filepath")],
)
# 執行顯示介面
demo.launch()
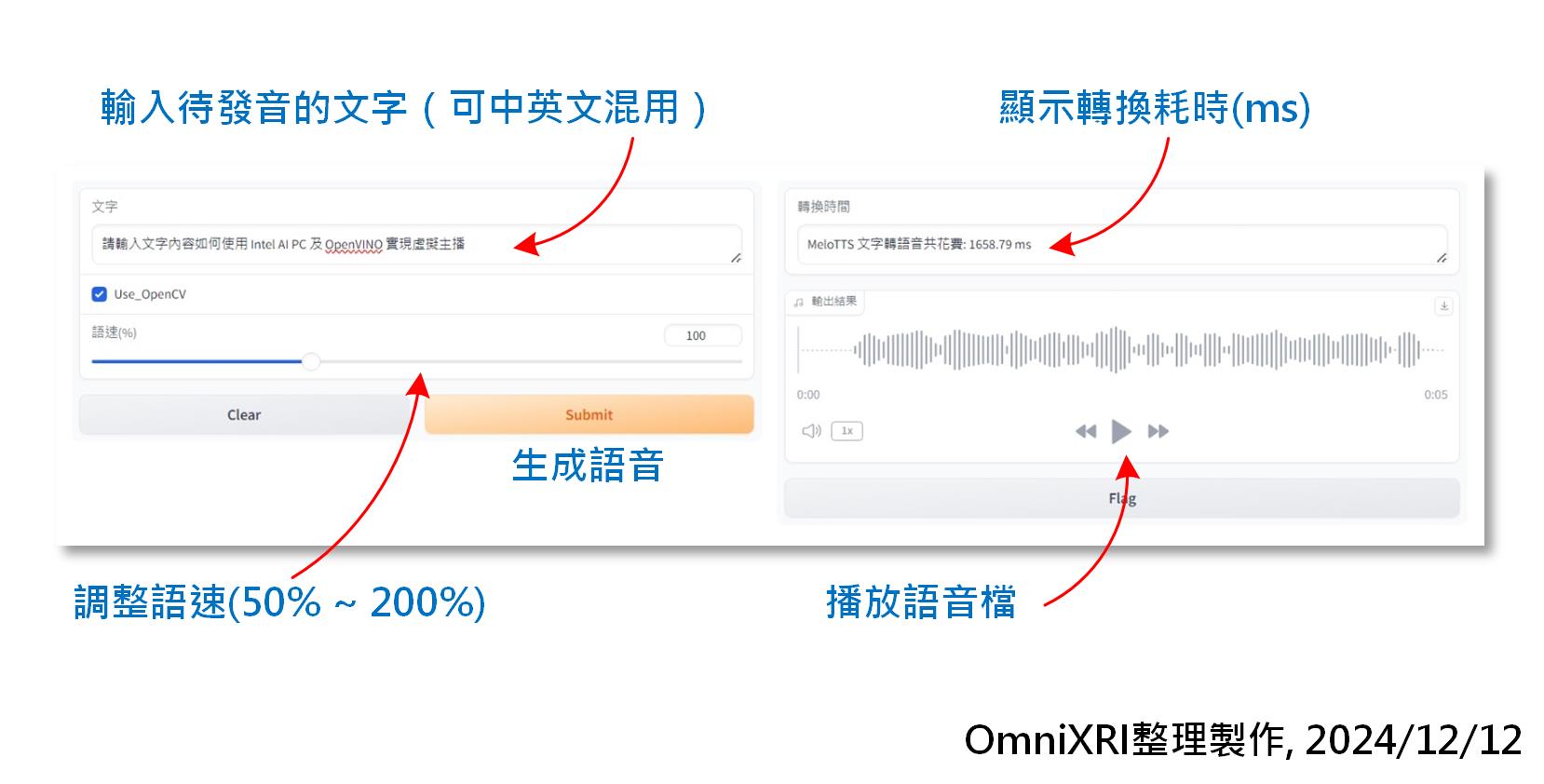
圖2:執行 MeloTTS_run.ipynb 生成語音結果。(OmniXRI整理製作, 2024/12/12)
3. Wav2Lip 自動對嘴影片生成
由於前面已於 \digital_human 路徑下備妥wav2lip相關範例,此時啟動OpenVINO Notebooks Python 虛擬環境後,即可進入Jupyter Notebooks 環境,進到 /openvino_notebooks/notebooks/digital_human ,開啟 wav2lip.ipynb 全部執行即可。
在這個範例中,共需使用到兩個模型,一個負責臉部偵測(Face Detection),另一個則負責將產生對應聲音的嘴形影像(Wave to Lip)。
第一次執行會花費很多時間,因為程式會下載相關模型並轉換好OpenVINO 所需IR格式(bin+xml),預設會存放在 \models 路徑下。 Gradio介面啟動後,點擊最下方的 Example ,就會自動將實驗用影音檔載入輸入端,接著按下「Submit」等待一段時間後就能得到輸出影片,預設會存放在 \Results 路徑下,名為 result_voice.mp4 。
這裡也支援直接從網路攝影機錄影、錄音,再進行影像生成。錄製時建議影片長度要大於聲音長度,否則會發生自動重播造成的不連續跳動感。
完成上述步驟後才能運作下列簡易版帶介面程式 wav2lip_run.ipynb 。這個範例有提供 Gradio 介面,方便大家以網頁方式重覆輸入影音檔案及檢查生成影像檔案內容。
由於 wav2lip.ipynb 並不會自動偵測模型是否已下載和轉換,所以當重新執行時非常耗時,建議第二次執行時,直接開啟 wav2lip_run.ipynb 運作,由於已有轉換好的模型,可直接執行影音對嘴轉換,節省許多時間。
# wav2lip 單獨行含Gradio介面範例
#
# by Jack_OmniXRI, 2024/12/12
from notebook_utils import device_widget
# 設定下拉式選單,以選擇推論裝置 (CPU, GPU, NPU, AUTO) (這裡的GPU是指Intel內顯)
device = device_widget()
device
import os
import sys
from pathlib import Path
#print(os.path.abspath('.'))
sys.path.append('./wav2lip') # 為了讓系統找得到 wav2lip 相關函式,所以手動加入相關路徑
OV_FACE_DETECTION_MODEL_PATH = Path("models/face_detection.xml") # 指定人臉偵測模型路徑
OV_WAV2LIP_MODEL_PATH = Path("models/wav2lip.xml") # 指定 wav2lip 模型路徑
from ov_inference import ov_inference
# 確認存放輸出結果路徑是否存在,若否則建立 \results 路徑
if not os.path.exists("results"):
os.mkdir("results")
# 使用 OpenVINO 進行推論
ov_inference(
"data_video_sun_5s.mp4", # 指定原始影片檔案
"data_audio_sun_5s.wav", # 指定聲音檔案
face_detection_path=OV_FACE_DETECTION_MODEL_PATH, # 指定人臉偵測模型路徑
wav2lip_path=OV_WAV2LIP_MODEL_PATH, # 指定 wav2lip 模型路徑
inference_device=device.value, # 指定推論裝置
outfile="results/result_voice.mp4", # 輸出結果檔案名稱
)
# 使用 Gradio 產生互動介面
from gradio_helper import make_demo
demo = make_demo(fn=ov_inference)
try:
demo.queue().launch(debug=True)
except Exception:
demo.queue().launch(debug=True, share=True)

圖3:執行 wav2lip_run.ipynb 生成對嘴影像結果。(OmniXRI整理製作, 2024/12/12)
4. 建置完整虛擬主播
當已可成功執行上述二個範例( melotts_run.ipynb、wav2lip_run.ipynb )後,代表相關環境都已準備好,此時才能運作 digital_human.ipynb 這個「虛擬主播」完整範例。
使用時可依下列步驟在Gradio介面上進行操作。
- 在文字欄位輸入一段文字。
- 調整語速(50% ~ 200%,預計100%)。
- 按下「生成語音」鍵即可透過 MeloTTS 產生一個聲音檔案,預設為 “ov_en_int8_ZH.wav”。
- 接著按下「載入樣本」鍵即可載入一個預設的影片(data_video_sun_5s.mp4)和剛才生成的聲音檔案。這裡亦可直接上傳影片和聲音檔案或開啟網路攝影機直接錄影、錄音再進行合成。
按下「生成影片」鍵即可開始使用 Wav2Lip 進行影片生成。 - 完成生成後,點擊影片左下方播放鍵可檢視生成結果。
- 如果有需要,點擊影片右上方下載鍵可將檔案下載到電腦上。
- 如想自行調整 Gradio 介面可參考【vMaker Edge AI專欄 #24】 如何使用 Gradio 快速搭建人工智慧應用圖形化人機介面
# Digital Human 虛擬主播
#
# by Jack_OmniXRI, 2024/12/12
import os
import sys
from pathlib import Path
from melo.api import TTS
import time
import gradio as gr
#print(os.path.abspath('.'))
sys.path.append('./wav2lip') # 為了讓系統找得到 wav2lip 相關函式,所以手動加入相關路徑
from notebook_utils import device_widget
from ov_inference import ov_inference
# MeloTTS 文字轉語音設定及處理函式
speed = 1.0 # 調整語速
use_ov = True # True 使用 OpenVINO, False 使用 PyTorch
use_int8 = True # True 啟用 INT8 格式
speech_enhance = True # True 啟用語音增強模式
tts_device = "CPU" # 指定 TTS 推論裝置 , "CPU" 或 "GPU"(這裡指 Intel GPU)
bert_device = "CPU" # 指定 Bert 推論裝置, "CPU" 或 "GPU" 或 "NPU"
lang = "ZH" # 設定語系, EN 英文, ZH 中文(含混合英文、簡繁中文皆可)
# 指定測試文字轉語音字串
if lang == "ZH":
text = "我們討如何在 Intel 平台上轉換和優化 artificial intelligence 模型"
elif lang == "EN":
text = "For Intel platforms, we explore the methods for converting and optimizing models."
# 若指定語音增強模式則新增 process_audio() 函式
if speech_enhance:
from df.enhance import enhance, init_df, load_audio, save_audio
import torchaudio
# 將輸入聲音檔案處理後轉存到新檔案中
def process_audio(input_file: str, output_file: str, new_sample_rate: int = 48000):
"""
Load an audio file, enhance it using a DeepFilterNet, and save the result.
Parameters:
input_file (str): Path to the input audio file.
output_file (str): Path to save the enhanced audio file.
new_sample_rate (int): Desired sample rate for the output audio file (default is 48000 Hz).
"""
model, df_state, _ = init_df()
audio, sr = torchaudio.load(input_file)
# Resample the WAV file to meet the requirements of DeepFilterNet
resampler = torchaudio.transforms.Resample(orig_freq=sr, new_freq=new_sample_rate)
resampled_audio = resampler(audio)
enhanced = enhance(model, df_state, resampled_audio)
# Save the enhanced audio
save_audio(output_file, enhanced, df_state.sr())
# 初始化 TTS
model = TTS(language=lang, tts_device=tts_device, bert_device=bert_device, use_int8=use_int8)
# 取得語者資訊
speaker_ids = model.hps.data.spk2id
speakers = list(speaker_ids.keys())
# 若指定使用 OpenVINO, 檢查該語系是否已處理過,若無則進行轉換,結果會存在 \tts_ov_語系 路徑下
if use_ov:
ov_path = f"tts_ov_{lang}"
if not Path(ov_path).exists():
# 將原始模型轉換成 OpenVINO IR (bin+xml) 格式
model.tts_convert_to_ov(ov_path, language= lang)
# 進行模型初始化
model.ov_model_init(ov_path, language = lang)
if not use_ov: # 若未使用 OpenVINO
for speaker in speakers:
output_path = 'en_pth_{}.wav'.format(str(speaker))
start = time.perf_counter()
model.tts_to_file(text, speaker_ids[speaker], output_path, speed=speed*0.75, use_ov = use_ov)
end = time.perf_counter()
else: # 若使用 OpenVINO
for speaker in speakers:
output_path = 'ov_en_int8_{}.wav'.format(speaker) if use_int8 else 'en_ov_{}.wav'.format(speaker)
start = time.perf_counter()
model.tts_to_file(text, speaker_ids[speaker], output_path, speed=speed, use_ov=use_ov)
if speech_enhance:
print("Use speech enhance")
process_audio(output_path,output_path)
end = time.perf_counter()
dur_time = (end - start) * 1000
print(f"MeloTTS 文字轉語音共花費: {dur_time:.2f} ms")
# 聲音自動對嘴生成設定及處理函式
from notebook_utils import device_widget
# 設定下拉式選單,以選擇推論裝置 (CPU, GPU, NPU, AUTO) (這裡的GPU是指Intel內顯)
device = device_widget()
device
import os
import sys
from pathlib import Path
#print(os.path.abspath('.'))
sys.path.append('./wav2lip') # 為了讓系統找得到 wav2lip 相關函式,所以手動加入相關路徑
OV_FACE_DETECTION_MODEL_PATH = Path("models/face_detection.xml") # 指定人臉偵測模型路徑
OV_WAV2LIP_MODEL_PATH = Path("models/wav2lip.xml") # 指定 wav2lip 模型路徑
from ov_inference import ov_inference
# 確認存放輸出結果路徑是否存在,若否則建立 \results 路徑
if not os.path.exists("results"):
os.mkdir("results")
# 使用 OpenVINO 進行推論(至少跑一次)
ov_inference(
"data_video_sun_5s.mp4", # 指定原始影片檔案
"data_audio_sun_5s.wav", # 指定聲音檔案
face_detection_path=OV_FACE_DETECTION_MODEL_PATH, # 指定人臉偵測模型路徑
wav2lip_path=OV_WAV2LIP_MODEL_PATH, # 指定 wav2lip 模型路徑
inference_device=device.value, # 指定推論裝置
outfile="results/result_voice.mp4", # 輸出結果檔案名稱
)
# 使用 Gradio 產生互動介面
# import gradio as gr
# 定義文字轉語音處理函式 tts()
# 輸入: content(字串)、 use_ov(布林值)、 speed(數值)
# 輸出: "MeloTTS 文字轉語音共花費: xx.xx ms"(字串)、 語音檔案名稱(字串)
def tts(content, use_ov, speed):
start = time.perf_counter()
model.tts_to_file(content, speaker_ids[speaker], output_path, speed=speed/100, use_ov=use_ov)
if speech_enhance:
print("Use speech enhance")
process_audio(output_path,output_path)
end = time.perf_counter()
dur_time = (end - start) * 1000
audio = "ov_en_int8_ZH.wav"
result = f"MeloTTS 文字轉語音共花費: {dur_time:.2f} ms"
return result, audio
def load_example():
video = "data_video_sun_5s.mp4"
audio = "ov_en_int8_ZH.wav"
return video, audio
# 設定客製化 Gradio 人機介面
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
# MeloTTS 相關介面
txb_content = gr.Textbox(label="文字", value = "請輸入文字內容")
ckb_use_ov = gr.Checkbox(value=True, label="Use_OpenCV")
sld_speed = gr.Slider(50, 200, value=100, label="語速(%)")
txb_cvt_time = gr.Textbox(label="轉換時間")
file_audio = gr.Audio(label="輸出結果", type="filepath")
# 設定「生成語音」鍵對應動作
btn_tts = gr.Button("生成語音")
btn_tts.click(tts,
inputs=[txb_content, ckb_use_ov, sld_speed],
outputs=[txb_cvt_time, file_audio])
with gr.Column():
# Wav2Lip 相關介面
face_video = gr.Video(label="人臉影片")
text_audio = gr.Audio(label="聲音檔案", type="filepath")
# 設定「載入樣本」鍵對應動作
btn_tts = gr.Button("載入樣本")
btn_tts.click(load_example,
outputs=[face_video, text_audio])
with gr.Column():
output_video = gr.Video(label="結果影片")
# 設定「生成影片」鍵對應動作
btn_wav2lip = gr.Button("生成影片")
btn_wav2lip.click(ov_inference,
inputs=[face_video, text_audio],
outputs=output_video)
demo.launch()

圖4:執行 digital_human.ipynb 完整虛擬主播結果。(OmniXRI整理製作, 2024/12/12)
小結
目前測試結果, MeloTTS 語音生成部份中文只有女聲,還略帶大陸口音,未來可搭配進階訓練個人語音功能,來讓發音更接近所需年齡、性別、語調等。 Wav2Lip自動生成對嘴的影片效果略遜於官方公布的影片品質,包括影像清晰度、嘴形位置及形狀精度,其主要原因是要加快生成速度,相關參數未加調整造成。經此範例程式實驗後,已得到初步「虛擬主播」的效果,未來再加上語音轉文字(STT)及大語言模型(LLM)來生成自然對話,相信很快就能創作出屬於個人的虛擬助理了。
參考文獻
[1] 華碩(ASUS), NUC 14 Pro
https://www.asus.com/displays-desktops/nucs/nuc-mini-pcs/asus-nuc-14-pro/
[2] Intel, 如何安裝或更新 Intel NPU 驅動程式
https://www.intel.com.tw/content/www/tw/zh/support/articles/000099083/processors/intel-core-ultra-processors.html
[3] Intel, Github OpenVINO Notebooks Windows Installtion Guide
https://github.com/openvinotoolkit/openvino_notebooks/wiki/Windows
[4] 許哲豪,【vMaker Edge AI專欄 #16】AIPC開箱實測 ─ Yolov8斜物件偵測
https://omnixri.blogspot.com/2024/04/vmaker-edge-ai-16aipc-yolov8.html
[5] Intel, Github OpenVINO Notebooks – wav2lip
https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/wav2lip
[6] Zhaohb, Github – MeloTTS-OV (speech-enhancement-and-npu)
https://github.com/zhaohb/MeloTTS-OV/tree/speech-enhancement-and-npu
延伸閱讀
[A] Tong Qiu, Optimizing MeloTTS for AIPC Deployment with OpenVINO: A Lightweight Text-to-Speech Solution
https://blog.openvino.ai/blog-posts/optimizing-melotts-for-aipc-deployment-with-openvino-a-lightweight-tts-solution
[B] Xiake Sun, Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime
https://blog.openvino.ai/blog-posts/enable-2d-lip-sync-wav2lip-pipeline-with-openvino-runtime
[C] MakerPRO, Digital Human如何走入你我的數位世界?
https://makerpro.cc/2024/11/how-can-digital-humans-enter-our-digital-lives/
[D] 陳紀翰, 【開箱評測】探索未來:結合迷你PC與生成式AI的個人多媒體助理
https://makerpro.cc/2024/09/test-for-mini-pc-nuc-box-155h
[E] 林士允(Felix Lin), 【開箱實測】OpenVINO榨出單板極限,實作離線LLM AI助理!
https://makerpro.cc/2024/07/unboxing-openvino-llm-ai/
[F] 許哲豪,【AI_Column】影像式AI虛擬助理真的要來了嗎?
https://omnixri.blogspot.com/2018/09/aicolumnai.html
[G] 許哲豪,AI智能虛擬助理介紹Gatebox/HoloBox/MxR Tube
https://omnixri.blogspot.com/2018/03/aigateboxholoboxmxr-tube.html
[H] 許哲豪,虛擬助理再進化真人尺寸虛擬警衛大變身
https://omnixri.blogspot.com/2019/05/blog-post.html

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- Arduino UNO Q教學案例整理 - 2026/03/09
- 有了Intel AI Playground 不寫程式也能輕鬆玩生成式AI - 2025/09/02
- 【開發資源】TinyML MCU 等級開源推論引擎 - 2025/06/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


