作者:陳紀翰
一場 AI 盛宴的軟硬體碰撞
目前迷你主機(mini PC)的規格大致可分為有風扇與無風扇兩種,無風扇迷你主機常用於控制機器、資料收集以及執行SCADA系統(監控與資料採集系統)等工業環境;而有風扇迷你主機目前的應用主要集中在需要高效能運算和可靠散熱的場景,包含遊戲與多媒體創作、資料處理與科學運算、企業應用與邊緣運算以及其他戶外應用。
有風扇的迷你主機可以在極端環境下保持穩定運行,尤其是在高溫條件下;這使得迷你主機能夠在小型化的同時,支援高效能的持續運作,適合各種需要穩定性能和散熱的應用場景。本文要介紹的就是ASRock Industrial NUCS Ultra 100 BOX系列NUC BOX-155H有風扇mini PC。
這款mini PC是準系統,使用者購買首先要注意的是原始規格不含固態硬碟以及記憶體,需要自行選購安裝,如圖1。

圖 1 : NUC BOX-155H 內裝照,使用者需自行添購SSD與RAM。
關於處理器:
NUC BOX-155H採用 Intel® Core™ Ultra 155H處理器,擁有6個 P-Cores、8個E-Cores以及2個LP (Low Power) E-Cores,共22執行緒,並具有8個Xe -cores的Intel® Arc™ graphics繪圖核心以及NPU核心,可執行OpenVINO™、WindowsML、DirectML、ONNX RT等,其主要特色包括:
- 混合架構:Meteor Lake採用了混合架構,結合高效能核心(P-cores)和高效率核心(E-cores),類似於之前的 Alder Lake 和 Raptor Lake 系列。
- 整合AI加速器(NPU):這一代的Meteor Lake新增了 神經處理單元(NPU),提升了人工智慧推論、機器學習等 AI 相關工作負載的處理能力。
- Intel Arc繪圖處理:155H內建8個Xe繪圖核心的Intel Arc Graphics,支持包括DirectML和OpenVINO在內的現代API,適合用於遊戲、視訊編輯、AI 影像處理等應用。
- 強化的能源效率:155H採用了Intel 7nm製程技術和Foveros 3D封裝技術,這使其在提供強大性能的同時保持較低的功耗,特別適合輕便設備。
- 先進的I/O支援:這款處理器支援Thunderbolt 4和PCIe Gen 4,實現更快的資料傳輸速率,並能兼容最新的高速周邊設備和儲存方案。
- DDR5和LPDDR5支援:155H支援最新的DDR5和LPDDR5記憶體技術,提供更高的頻寬和更低的延遲,適合高記憶體需求的應用場景。
若要更清楚地對一般使用者說明其主要功能性,那我們可以說,這款mini PC是Intel®近幾年推動的典型AI PC產品,主打AI加速器(搭載NPU)、邊緣運算能力(尤其強調可在邊緣設備執行生成式AI)、低功耗高性能(P-cores及E-cores混合架構)及多模態生成應用(多媒體處理能力,涵蓋文字、影像、音訊),總而言之,我們可以將它視為智慧型個人多媒體處理助手產品。
以mini PC作為多媒體AI個人助理
隨著人工智慧(AI)技術的迅速發展,AI的應用範疇已經逐漸從大型資料中心和雲端運算延伸到日常生活中的個人設備,其中mini PC作為多媒體 AI 個人助理的角色正在崛起。這些小型電腦因其強大的處理能力和低功耗特性,成為個人化AI應用的理想平台。
目前的AI發展趨勢強調即時性和個性化的體驗,mini PC可以執行高效能的AI模型,為使用者提供多種多媒體服務,例如語音識別、影像處理、智慧家庭控制等。透過整合AI演算法,這些設備可以學習和適應使用者的行為習慣,實現更加智慧化和個性化的互動體驗。
此外,隨著本地化運算技術的進步,mini PC能夠在不依賴雲端的情況下完成多數AI任務,這不僅提升了資料隱私的保護,也減少了對網絡連接的依賴。這種趨勢符合目前AI技術發展中的一個關鍵方向——邊緣運算的應用。
整體來說,以mini PC作為多媒體AI個人助理的應用,展現了AI技術日益貼近日常生活的趨勢,未來這類設備將在提升個人生活品質和工作效率方面扮演越來越重要的角色,而本文將分析NUC BOX-155H這台 mini PC 在多媒體處理上的效能,並且分享一個未來十分看好、能成為個人多媒體助理的AI模型:Stable Diffusion及其多個版本的發展與應用選擇。
評測跑分
測試之前已將繪圖驅動更新至最新 (32.0.101.5768) 以及最新的 BIOS。
首先,我們呈現PCMark 10的評估結果,如圖2,該測試用來評估整體系統的多方面性能,特別是日常應用場景下的表現。系統的總得分為5,779,這表明該系統在多方面日常任務中具有不錯的表現能力,其中在各個子項測試中:
- Web Score (9,222):代表瀏覽器和網頁應用的性能,非常優秀。
- Apps Score (11,041):應用程式得分,能夠流暢執行多種辦公和生產力程式。
- Rendering and Visualization Score (5,868):渲染和可視化能力,一般,但尚能應對。
- Photo Score (12,723):處理影像編輯等工作,表現非常出色。
- Video Score (6,257):視訊處理得分表現,中等。
- Chat Score (7,490) 和 Writing Score (6,680):文字處理,流暢。
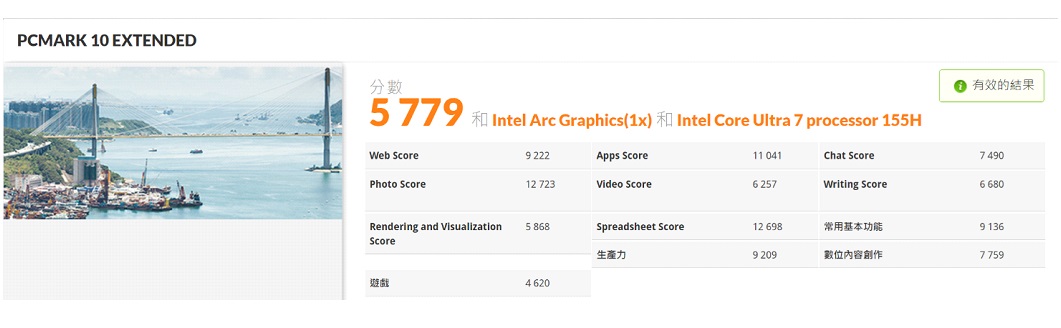
圖2 : PCMARK 10 EXTENDED測試
綜合來看,這個測試結果顯示該系統在日常應用、文書處理、圖像編輯和基本的數位內容創作中有很強的性能,呼應了前段智慧型個人多媒體處理助手之路。
這個測試也顯示了系統在高負載情況下有不錯的表現,尤其CPU的溫度控制不錯,影格率穩定性方面接近高規標準(逼近高規97%,高於良好標準95%) ,如圖3。
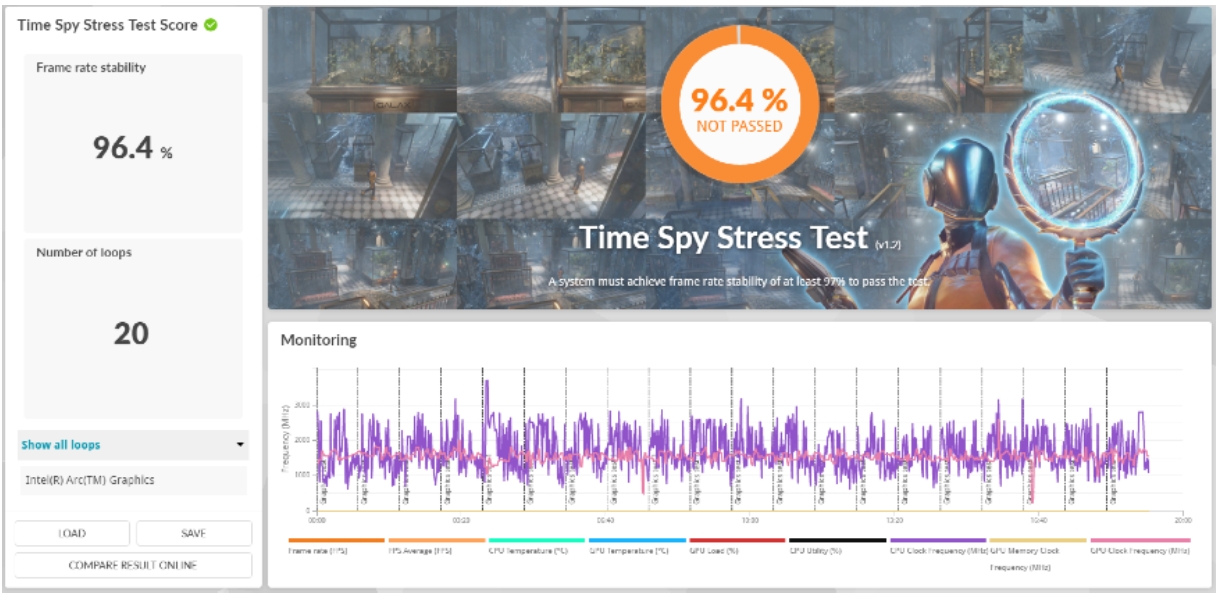
圖3 : Time Spy Stress Test
再來我們看一下CPU跑多執行緒測試的結果,如圖4。
多執行緒與單執行緒得分:
Max threads (多執行緒最大性能)、16 threads、8 threads、2 threads與1-thread (單執行緒)得分均低於一般同規格平均,但是比較1、2執行緒的評估結果相對較優。
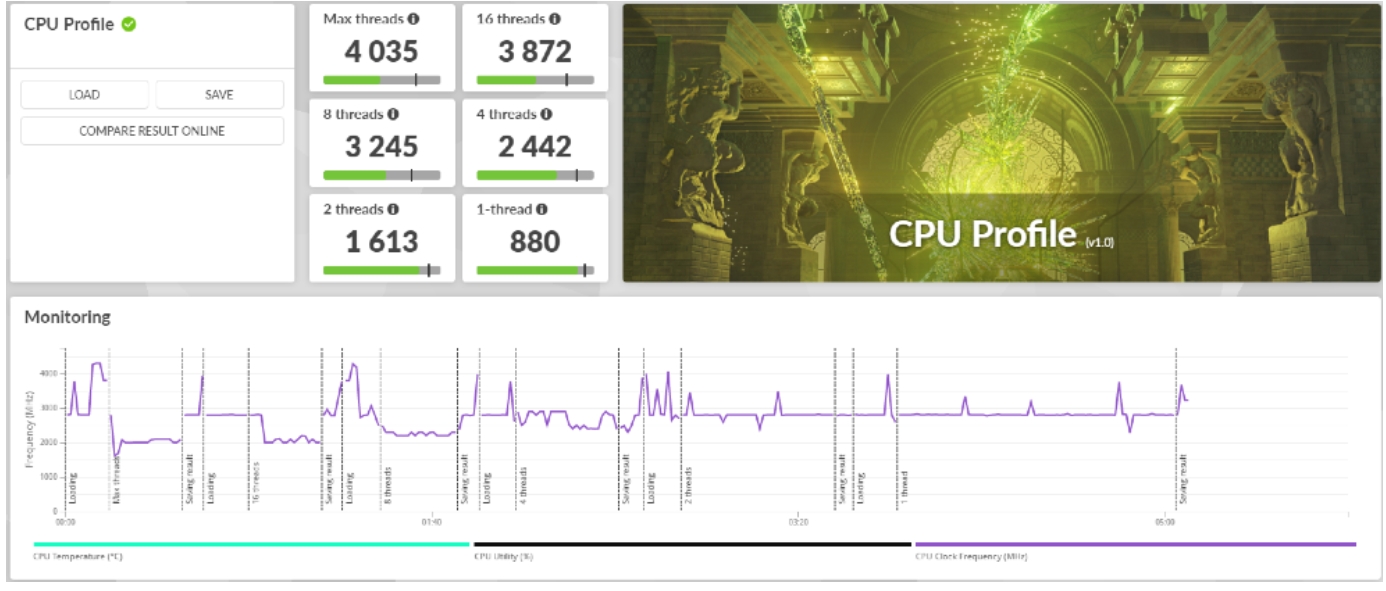
圖4 : PC Profile
在測試過程中,發現該機器在運作時的噪音相當低,運作環境相對安靜。這顯示其風扇調控策略較為保守,仍有優化空間;如果採取更積極的風扇調度,可以在接受略高的噪音情況下換取更穩定的效能輸出。
個人多媒體助理:Stable Diffusion
Stable Diffusion是一種基於Latent Diffusion Model (LDM)的生成式AI技術,自2022年由CompVis團隊發布以來迅速演變並推出了多個版本,彙整如表1:
- 起源與初期版本:Stable Diffusion最早由CompVis發布,最初的1版本其實是從Latent Diffusion演變而來,隨後的1.2到1.5版本進一步改善了模型的訓練步數與資料集,逐步提升生成效果。
- 進階版本:2022年底至2023年初,Stability AI推出了2.0和2.1版本,然而這些版本並不如預期受歡迎。相對而言,2023年的SDXL系列(包括SDXL 0.9和SDXL 1.0)則取得了更大的突破,特別是在圖片生成品質和自然語言理解方面有顯著提升。
- 近期版本與未來趨勢:2024年,Stable Diffusion發展到3.0版本,並且開始加入更快的Turbo模式與新的3D生成技術,展現了AI影像生成技術的前瞻性和多樣性。
總結來說,Stable Diffusion在短短兩年內經歷了快速的發展,從最初的Latent Diffusion到如今的多個版本,每次迭代都在性能和應用範圍上取得了顯著的進步,特別是在「控制細節」和「生成細節」兩大方面表現出顯著的進步;要將Stable Diffusion發展成個人多媒體編修助手,我們針對這兩個方向進行分析:
Stable Diffusion v1.x
這是初期版本,雖能生成具有相當水準的影像,但在生成細節上仍有許多侷限,尤其是在細節處理和複雜場景的生成上,模型往往會產生模糊或不精確的結果。控制細節的能力有限,使用者只能透過文字提示來影響結果,無法避免某些不希望出現的元素(無法有效利用負向提示),對生成內容的精準控制相對困難。
這個問題在Stable Diffusion v1.5版本上有得到改善-- 「Image Generation with Stable Diffusion and IP-Adapter」這個模型採用Stable Diffusion v1.5為基礎模型,但加入了IP-Adapter控制機制,維持輕量但提升了控制品質與細節。
Stable Diffusion v2.x
v2.x 系列在生成細節上有了明顯的提升,特別是導入了深度估計模型,使得生成的影像在3D感和場景深度方面表現更好。在「控制細節」上也有突破,透過加入 負向提示(Negative Prompting) 功能,使用者可以更有效控制影像內容,指定不想要的元素,讓最終結果更符合預期。此外,對解析度和細節的處理也更精細,使得生成的影像更生動、真實。
Stable Diffusion XL
最新的 SDXL 在「生成細節」上達到了新的高度,不僅提升了解析度,還在色彩、光影、紋理等方面進行了強化,讓影像更加逼真和細膩。模型的生成能力顯著增強,能夠處理複雜的場景和高細節的物件。此外,該版本在「控制細節」上進一步提升,提供了更精確的文字提示控制,讓用戶能夠創建更加具體且個性化的圖像,並能有效控制圖像中的各種細節,避免過度複雜或多餘的元素出現。
總而言之,隨著Stable Diffusion的版本演進,生成的影像在細節處理上越來越精緻,控制的精度也不斷增強,從最初的簡單提示控制,到負向提示,再到最新版本中的精確生成,這些改善讓使用者在創建過程中擁有更多的自由度和精確度。
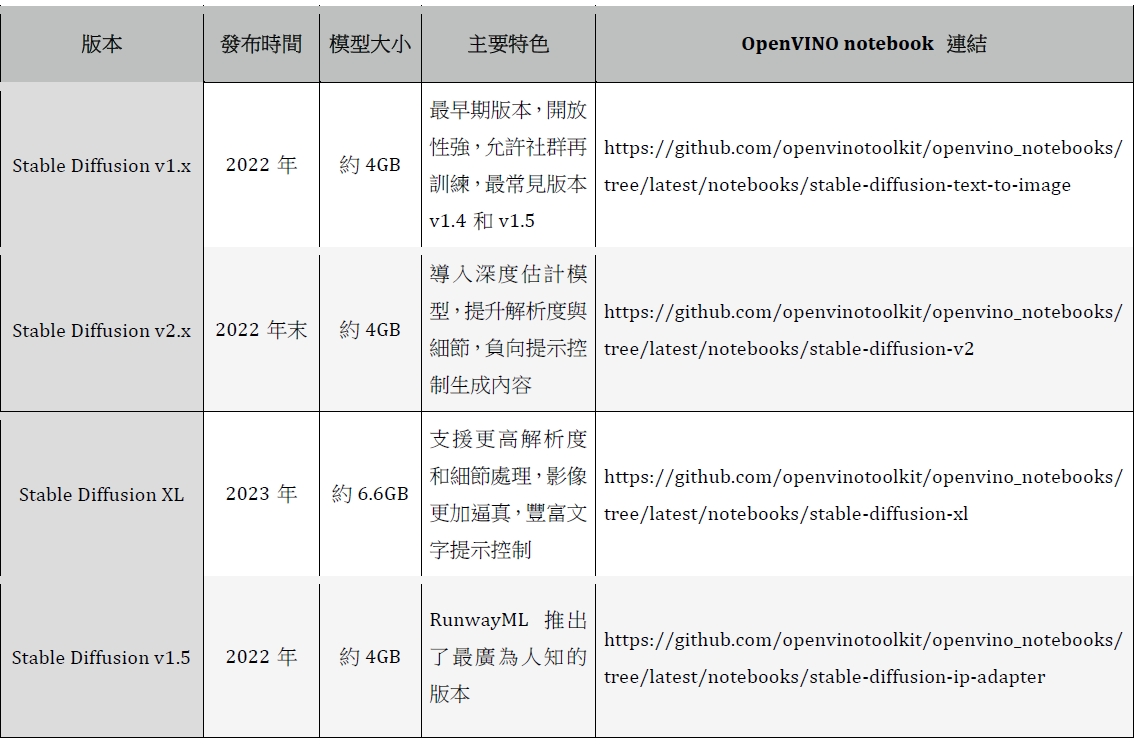
表1 : Stable Diffusion版本比較
介紹完上述幾個版本,使用者應該針對自己的應用有所抉擇,因為Stable Diffusion的版本開發似乎是相互平行地在進行,並不是單純的v3都勝過v2、v2都勝過 v3 ,尚須進一步考慮預訓練權重採用的資料及大小,以及轉換OpenVINO後量化造成的精度衰減(某些詞彙可能不引起反應)。
目前值得推薦的是Stable Diffusion v1.x最輕量,而Stable Diffusion v2.x加入了負向提示詞,使得可控制的約束條件變得比較多。另外,如果要額外加入文字以外的約束條件,可以採用「Image Generation with Stable Diffusion and IP-Adapter」這個模型,在維持輕量化的前提下,加強文字與非文字(如邊緣或影像)的控制效果,其多模態輸入示意圖如圖 5 所示。
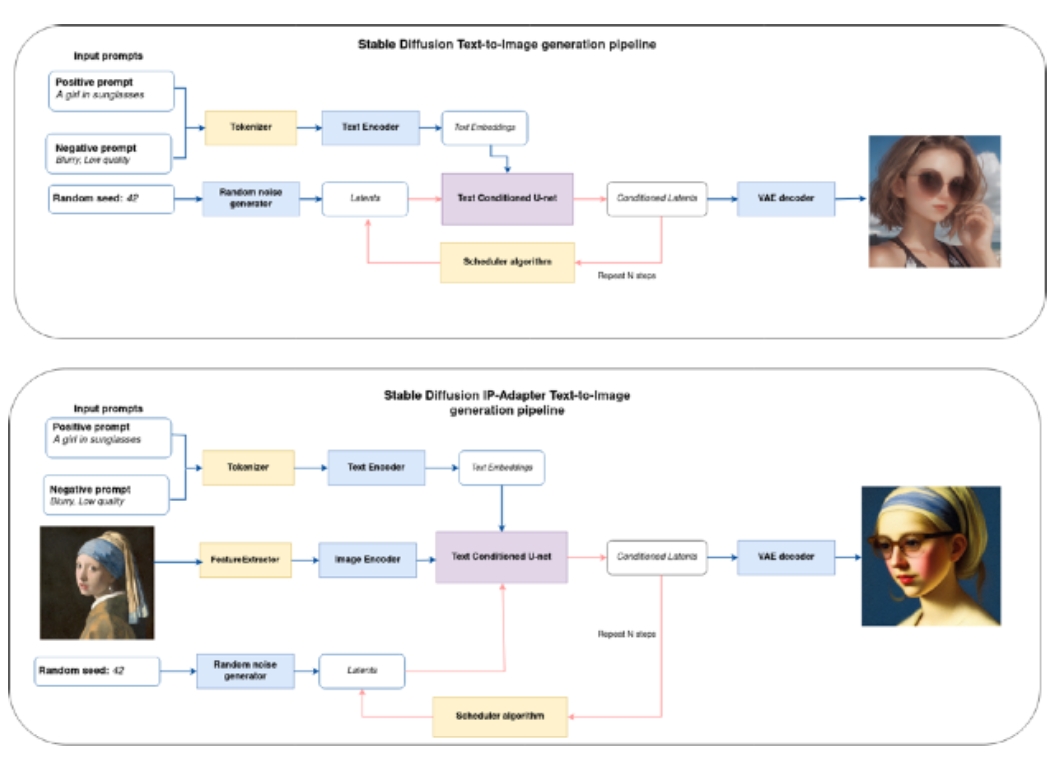
圖5 : IP-Adapter使得Stable Diffusion有多模態輸入的特性,⽀援影像與⽂字(正、負向提⽰詞)輸入,以⽤於更精確控制輸出結果
Stable Diffusion and IP-Adapter
此專案位於OpenVINO notebook的此連結,notebook 開頭即是模型架構,如圖6所示。
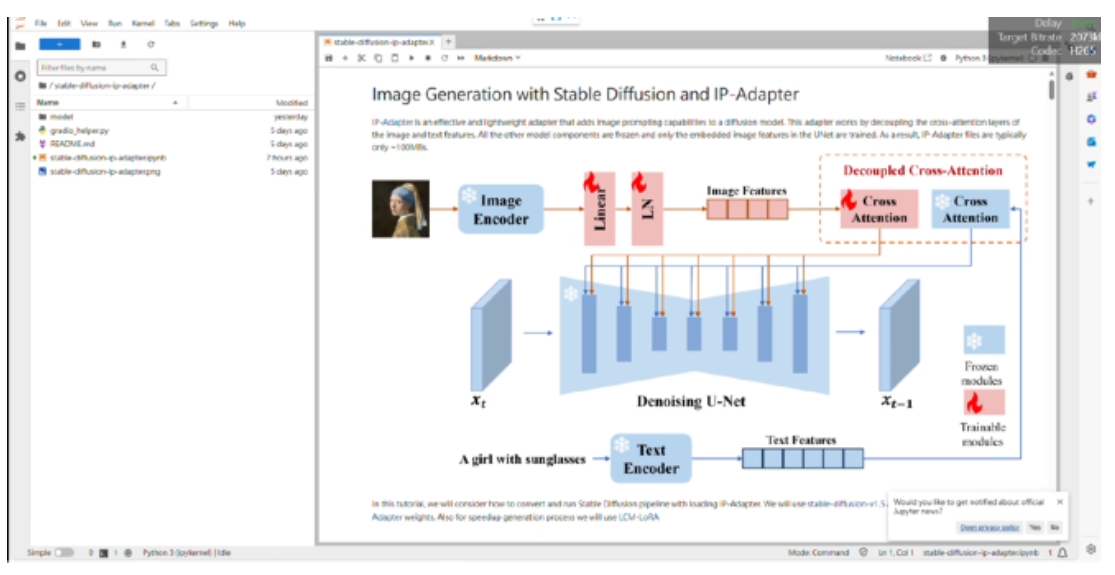
圖 6 : Stable Diffusion with IP Adapter OpenVINO notebook
一路執行到底,程式會用Gradio開啟互動頁面,此時就可以用如圖7顯示的網頁互動頁面來丟圖片及提示詞。
圖7 : Stable Diffusion with IP Adapter OpenVINO notebook 以Gradio開出的互動式網⾴
我們首先來測試,給一張貓咪的圖片,在這張圖片中,貓躺在一張小床上,我們希望把他改成躺在桌上,因此我們給予一個正向提示詞:「A cat is lying on the desk, facing forward, clearly visible, big eyes cat」 (提示詞是請 ChatGPT 生出來的),模型生出圖8右畫面,從畫面中我們可以看到貓的顏色與花紋一定程度地參照了原圖的貓(仍有某些不相同,例如後腳顏色),此外桌子的木紋理、椅子布套顏色也都一定程度地參照了原圖。

圖8:左⽅為輸入圖,右⽅為配合提⽰詞後的輸出圖
看到了姿態與場景轉換的成功之後,我們再試試另一張圖,這次換走在戶外的貓咪,我們改變他的姿態為坐下,於是我們給了一個很簡單的提示詞:「A cat sit.」結果得到如圖9所示的結果,貓並沒有坐下,於是我們增加一下詞彙:「A relaxed cat sit.」結果就成功坐下了。

圖 9 : 分別為輸入圖、配合提⽰「A cat sit.」輸出圖以及配合提⽰「A relaxed cat sit.」輸出圖
接下來我們使用ChatGPT給的詞彙進行提示,圖10左的提示詞是:「A relaxed cat lying down on a soft surface, its body stretched out comfortably with paws tucked in and tail curled slightly. The cat’s fur looks soft and smooth, reflecting gentle light. Its eyes are half-closed, giving off a calm and peaceful expression. The background is warm and cozy, complementing the cat’s serene posture as it rests quietly.」中間則是進一步加入負向提示詞:「blurry, distorted, low quality, oversaturated, dark shadows, unnatural lighting, strange anatomy, extra limbs, unrealistic fur, overly bright, overly sharp, noise, artifacts, low resolution.」

圖 10 : 分別為圖9左的輸入圖配合ChatGPT⽣成提⽰詞後的輸出圖,左⼀配合豐富的正向提⽰,畫⾯精美但未完成「躺下」動作,中間圖配合負向提⽰詞後完成「躺 下」動作,右圖配合更換場景,輸出圖仿照了原圖的淺景深效果。
在這兩個測試案例中,我們發現似乎提示詞豐富度有助於貓本身的型態生成,但是提示詞中我們定義「lying」,結果似乎跟我們想的不太一樣,左一圖應該還是坐著的姿態,而中圖則有成功躺下(我們 Google搜尋cat lying看到許多這樣的姿態,因此我們認為生成此圖算符合定義),由此可見負向提示詞的使用也有助於圖片生成。
第三圖則是嘗試變換場景為花園,我們請 ChatGPT 給予正負向提示詞,分別為:
Positive Prompt: “A cat walking gracefully through a vibrant garden filled with blooming flowers and lush greenery. The cat’s fur glistens in the soft sunlight as it moves gently across the garden path. The flowers around it sway slightly in the breeze, adding a sense of motion and life to the scene. The background features colorful plants, butterflies fluttering, and a serene atmosphere, highlighting the beauty of nature.”
Negative Prompt: “blurry, distorted, low quality, oversaturated, dark shadows, unnatural lighting, strange anatomy, extra limbs, unrealistic fur, overly bright, overly sharp, noise, artifacts, low resolution, cluttered background, monochrome, abstract, excessive detail.”
生成圖片的結果顯示如圖10右,場景有成功轉換,也維持了原圖淺景深的效果。從這幾個案例我們可以看出目前Stable Diffusion with IP-Adapter生出來的圖片擬真程度相當不錯(偶爾會出現不合理的狀況),為解決這些問題,我們可以用更豐富的提示詞進行控制,雖然筆者經過幾次嘗試才得到想要的結果,但其顯示目前已經有一定程度的控制效果。
結論
NUC BOX-155H以其強大的性能和穩定的表現,成為了個人多媒體處理和 AI 應用的理想平台。該設備在日常應用、多媒體創作和高負載運算中的優異表現,展示了其在小型化設計下實現高效能的能力。在目前生成式 AI 聲浪逐漸高漲的趨勢中,Stable Diffusion 作為基於Latent Diffusion Model的先進技術,自 2022年發布以來,已經經歷了多個版本的發展,每次迭代都顯著提升了圖像生成的精度和控制能力,對於AI軟體開發者而言,Stable Diffusion無疑會是未來生成式 AI 的開發基礎模型。
本文測試NUC BOX-155H的處理器和圖形處理能力已經可在合理反應時間內執行Stable Diffusion,進而有效地進行多媒體處理,如圖像生成和編輯,並支持複雜的自然語言理解,這使其成為個人化AI助手的理想選擇,未來我們期待這類mini PC可以在生成式AI開發發揮關鍵作用。

本身是個熱愛藝術的資訊工程研究員,熱衷於探索在『研究、應用與啟發教學』之間平衡而產生的美感。
- 【實作案例】以OpenVINO實現VLM、MLLM導入產業應用 - 2025/08/07
- 【開箱評測】探索未來:結合迷你PC與生成式AI的個人多媒體助理 - 2024/09/24
- 以AI進行無人機巡檢河川地貌分析 - 2023/09/15
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


