作者: Elham Harirpoush,Arm資深解決方案工程師
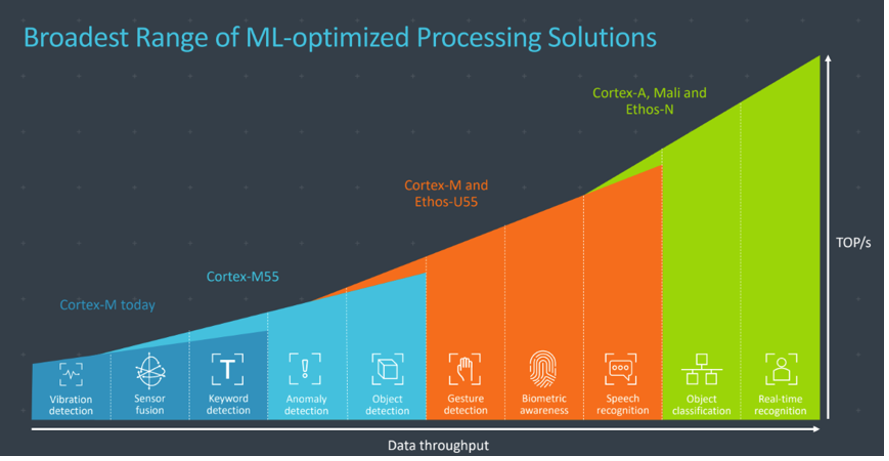
Cortex-M55處理器是Arm Cortex-M處理器中人工智慧功能最強大的,也是第一顆基於Arm Helium技術的CPU。儘管Cortex-M55在微小的微處理器上運作機器學習模型速度已經很快了,不過它與Arm Ethos-U55 microNPU完成整合後,在嵌入式系統中最快可讓機器學習推論速度提升480倍。
Ethos-U55是一款機器學習處理器,經過最佳化後可執行常見的數學機器學習演算法運算,例如卷積或啟動函數。針對音訊處理、語音辨識、影像分類與物件偵測,Ethos-U處理器支援例如卷積神經網路(CNN)與循環神經網路(RNN)等神經網路模型。
在Ethos-U NPU上部署推論
在Ethos-U NPU上執行推論時,將網路運算子量化成8位元(無正負號或帶正負號)或16位元(帶正負號)是必要的,原因是Ethos-U只支援8位元的權重或16位元的啟動。TensorFlow模型最佳化套件(TensorFlow Model Optimization Toolkit)可以讓開發人員在記憶體、功耗與儲存空間受限的裝置上進行部署時最佳化機器學習模型。
目前已有不同的最佳化技術可供使用,包括量化(quantization)、修剪法(pruning,或譯「剪枝」)以及分群法(clustering),這些都是TensorFlow模型最佳化套件的一部份,並與TensorFlow Lite相容。例如,您可以對模型進行訓練後的整數量化(post-training integer quantization),並利用TFLiteConverter把轉化完成的模型載入後,將權重與啟動從浮點數字轉化成整數數字。請留意,模型一旦完成修剪或分群,修剪/分群後通常會進行小量的訓練,以補償準確度的流失。因此,必須在模型的複雜性與大小之間權衡。
使用訓練後量化來最佳化模型:
def representative_dataset():
for _ in range(100):
# Using some random data for testing purposes
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
# Load the model into TensorFlow using TFLite converter
converter = tf.lite.TFLiteConverter.from_saved_model(“model_tf”)
# Set options for full integer post-training quantization
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
# Ensure that if any ops can't be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# Set the input and output tensors to int8
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
# Convert to TFLite
tflite_model_quant = converter.convert()
若要在Ethos-U上部署NN模型,需要以Vela來編譯訓練好的量化模型,以便為Ethos-U產出最佳化的NN模型。Vela是一種開源Python工具,可將TFLite NN模型編譯成最佳化過的版本,在包含Arm Ethos-U NPU的嵌入式系統上運作。您可執行$pip install ethos-u-vela指令來安裝Vela,然後藉由下列指令行,使用像ethos-u55-128等特定Ethos-U NPU組態對網路進行編譯。點擊此連結可閱讀更多有關Vela的不同指令行選項。
$ vela model.tflite \
--accelerator-config=ethos-u55-128 \
--optimise Performance
--config vela.ini
--system-config=Ethos-U55_High_End_Embedded
–-output-dir ./results_dir /path/to/model.tflite \
accelerator-config指定不同Ethos-U55之間可以使用的microNPU配置:
- ethos-u55-256
- ethos-u55-128
- ethos-u55-64
- ethos-u55-32
- ethos-u65-256
- ethos-u65-512
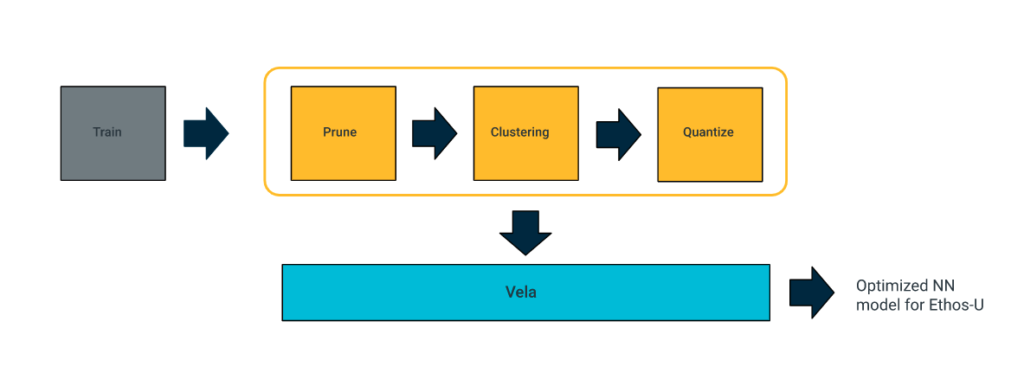
圖1:Vela工作流程。
Vela輸出的是最佳化過的TensorFlow Lite檔案,可以在使用Ethos-U NPU的系統上進行部署;這裡選用配置了Corstone-300 FVP的Arm虛擬硬體來做為相關範例。通常您可以使用TensorFlow Lite Interpreter Python API,從磁碟機載入TFLite模型,以便進行部署。
# Load the TFLite model in TFLite Interpreter
interpreter = tf.lite.Interpreter(model_content=tflite_model)
然而,多數微控制器並不具備檔案系統,因此需要額外的程式碼與空間,才能從磁碟載入模型。有效的解決方法是把模型放在屬於二進制的一個C源檔案中,然後直接把它載入記憶體。因此,必須使用供微控制器C++程式庫用的TensorFlow Lite,以便載入模型並進行預測。
另一個快速且簡便的方式,則是使用開源的Arm機器學習嵌入式評估套件(Arm ML Embedded Evaluation Kit)。它可讓開發人員使用微控制器推論引擎使用的TensorFlow Lite,快速執行神經網路,並鎖定Arm Cortex-M55 與Ethos-U微控制器。
評估套件概述
Arm機器學習評估套件幫助開發人員針對Arm Cortex-M55 與Arm Ethos-U55 NPU,快速打造並部署嵌入式機器學習應用。它包含供Ethos-U55系統使用的、已開發完成的軟體ML應用,其中包括:
- 影像分類(Image classification)
- 關鍵詞萃取(Keyword spotting,KWS)
- 自動語音辨識(Automated Speech Recognition,ASR)
- 異常偵測(Anomaly Detection)
- 人員偵測(Person Detection)
因此,您可以利用這些能立即使用的機器學習實例,快速評估以Cortex-M CPU與Ethos-U NPU運作的網路性能表現。您也可以用評估套件中的同屬推論執行器(generic inference runner),輕鬆打造供Ethos-U使用的客製機器學習軟體應用。您可以把這個同屬推論執行器用在所有的模型上,以便獲取各種性能的度量值(performance matrix),例如NPU的時脈週期以及不同匯流排間的記憶體使用量。
機器學習嵌入式評估套件的軟硬體堆疊
評估套件的軟體堆疊包含不同的層,最上面的是應用層,下面則是各種相依層。Ethos-U NPU完成組建系統的配置後,搭載Ethos-U NPU驅動程式的整合微控制器的TensorFlow Lite,會執行可被Ethos-U NPU加速的特定運算子。
對於在NPU上運作、且未獲支援的神經網路模型運算子,CPU上運行的推論會使用CMSIS-NN。CMSIS-NN最佳化CPU工作負載的執行,或使用推論引擎提供的參考核心(kernels)。硬體抽象層(HAL)來源則提供一個不偏好任何平台的API,以取用特定平台的硬體功能。
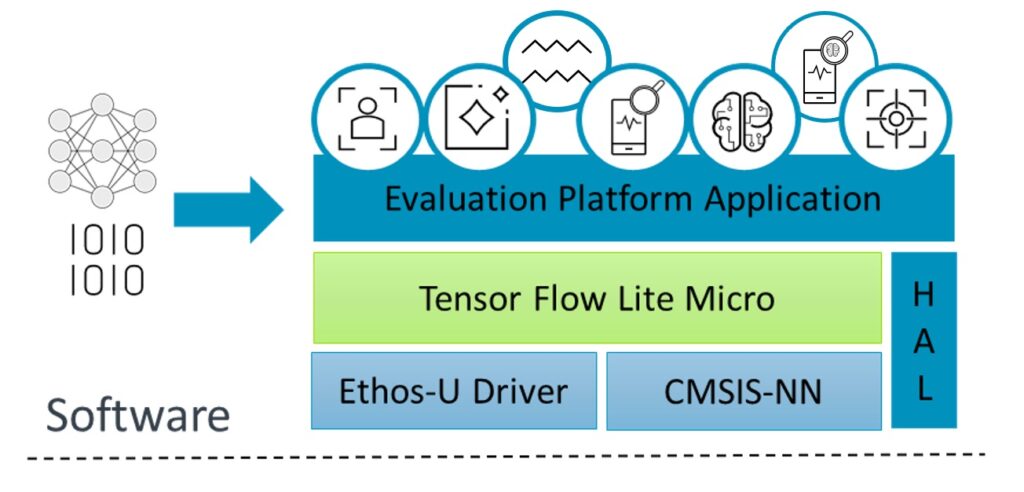
圖2:機器學習評估套件的軟體堆疊。
此一機器學習評估套件是架構在Arm Corstone-300參考設計之上,可協助系統單晶片(SoC)的設計人員以更快的速度打造安全的系統。它充份發揮Arm Cortex-M55處理器的優點,極大化物聯網與嵌入式裝置的效能。Corstone-300可以和Ethos-U55輕鬆進行整合,可使用的平台格式為生態系FPGA (MPS3)與固定虛擬平台(FVP),讓開發作業在硬體可用之前就能展開(內含Ethos-U55的晶片硬體已陸續問世)。
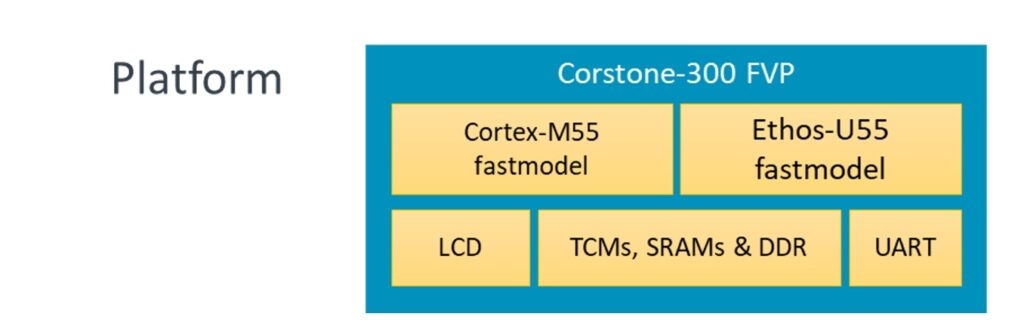
圖3:機器學習評估套件的硬體堆疊。
Corstone-300 FVP搭配Ethos-U55及Arm虛擬硬體
FVP是MPS3 FPGA影像檔的數位對映(digital twin)。它讓開發人員可以針對使用Arm Cortex-M55 與Arm Ethos-U55設計的虛擬平台,快速打造與評估真實世界的嵌入式機器學習應用。
搭載Ethos-U55 與Ethos-U65的Corstone-300 FVP已經發表可用,是Arm虛擬硬體的一部份。Arm虛擬硬體針對Arm架構的SoC提供功能準確的模型,讓應用開發人員在晶片與硬體上市可用之前與之後,都能打造與測試軟體,從而協助加速物聯網及終端AI應用的開發作業。
Corstone-300 FVP在雲端上以簡單的應用程式方式運行,以便模擬記憶體與週邊設備,同時免除打造與配置開發板農場的複雜性。
機器學習評估套件工作流程
針對打造與運行立即可用的機器學習評估套件的ML實例,如利用機器學習評估套件在搭載Cortex-M 與Ethos-U的系統上進行關鍵詞萃取,常見的工作流程如下:
- 確定下列不可或缺的元件已安裝完畢,並已放在正確的路徑上可供使用。
GNU Arm embedded toolchain version 10.2.1 or higher or the Arm Compiler version 6.15 or higher
CMake version 3.15 or above
Python 3.6 or above
Python virtual environment module
Make
An Arm Corstone-300 based FV
- 複製Ethos-U評估套件儲存庫。
$ git clone https://review.mlplatform.org/ml/ethos-u/ml-embedded-evaluation-kit
$cd ml-embedded-evaluation-kit
- 抽出所有的外部相依。
$ git submodule update --init
- 執行build_default.py檔案,並使用如MPS3 FVP目標及Ethos-U55 timing-adapter等預設值,配置組建系統。
a. 倘若使用Arm GNU嵌入式工具鏈:
b. 倘若使用Arm編譯器:$ python build_default.py
$ python build_default.py –toolchain arm
- 以make指令編譯專案。
- 組建的結果置於build/bin目錄下,如:
bin
├── ethos-u-.axf
├── ethos-u-.htm
├── ethos-u-.map
└── sectors
├── audio.txt
└──
├── ddr.bin
└── itcm.bin
- 倘若使用FVP,用Arm虛擬硬體在FVP上開啟想要使用的應用。例如,您可以使用下列指令,在Ethos-U55上展開關鍵詞使用的使用場景:
$ FVP_Corstone_SSE-300_Ethos-U55 -a ./build/bin/ethos-u-kws.axf
點擊這裡可以瞭解更多FVP支援的不同的指令行參數。
利用機器學習嵌入式評估套件配置與執行客製化模型
針對客製化的工作流程與神經網路模型,機器學習評估套件在使用上也非常簡易。比方說影像分類,您可以不讓MobileNet通過,而讓新的模型與輸入大小一起通過。不過,如果您要在Ethos-U NPU上執行特定的機器學習模型,請確認您的客製化模型已經成功通過Vela編譯器,並產出最佳化過的神經網路模型。
接下來請建立一個組建目錄,並為Vela產出的TFLite檔案設定路徑,以便利用Cmake來配置組建系統。最後,以make對專案進行編譯。
您可以使用同屬推論執行器建立機器學習評估套件的組建選項,為您在Cortex-M55與Ethos-U55上執行的特定機器學習應用,設定推論的速度。您可以執行下列指令,完成上述作業:
$ mkdir build && cd build
$ cmake .. \
-Dinference_runner_MODEL_TFLITE_PATH=TFLITE_PATH
-DUSE_CASE_BUILD=inference_runner
更多有關於cmake可供使用的不同參數選項的資訊,請詳見打造預設配置。
$ make
然後利用Arm虛擬硬體,以選用的Ethos-U55在FVP上執行相對應應用的二進制檔案。
注意:Arm虛擬硬體FVP執行的MAC數量,應該與Vela編譯器上的–accelerator-config配置的一樣:
FVP_Corstone_SSE-300_Ethos-U55 -C ethosu.num_macs=128 -a ./build/bin/ethos-u-inference_runner.axf
現在就試試!
您現在就可開始使用機器學習評估套件、在Arm虛擬硬體中可用的Corstone-300 FVP、Arm Vela 編譯器以及現有的ML實例,針對Arm Ethos-U NPU進行機器學習軟體開發。
現在就來試試看Arm虛擬硬體吧!
(本文中文版校閱者為Arm主任應用工程師林宜均;責編:Judith Cheng)

- 【Arm的AI世界】利用Arm機器學習嵌入式評估套件快速部署Edge AI應用 - 2024/01/15
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


