作者:歐敏銓
Edge AI的推論應用已逐漸從工業電腦向下推到嵌入式系統,然而,在MCU/MPU為運算核心的架構中,如何滿足AI/ML的推論運算需求?廠商們提出了各種方案,如客製化AI加速器SOC、採用FPGA,以及整合Arm的Ethos-U 神經處理單元(NPU)等,其中整合NPU的作法似乎得到較高的市場接受度。
以AI晶片新創ALIF開發的4個家族系列(E1、E3、E5、E7)為例,下圖說明了這個家族的運算核心組合,透過整合不同類型及數量的運算核心,即強調即時性的MCU核心(Cortex-M55)、微型NPU AI/ML加速器(Ethos-U55)及應用MPU核心(Cortex-A32),來滿足輕量、中量到大量運算需求的不同應用。
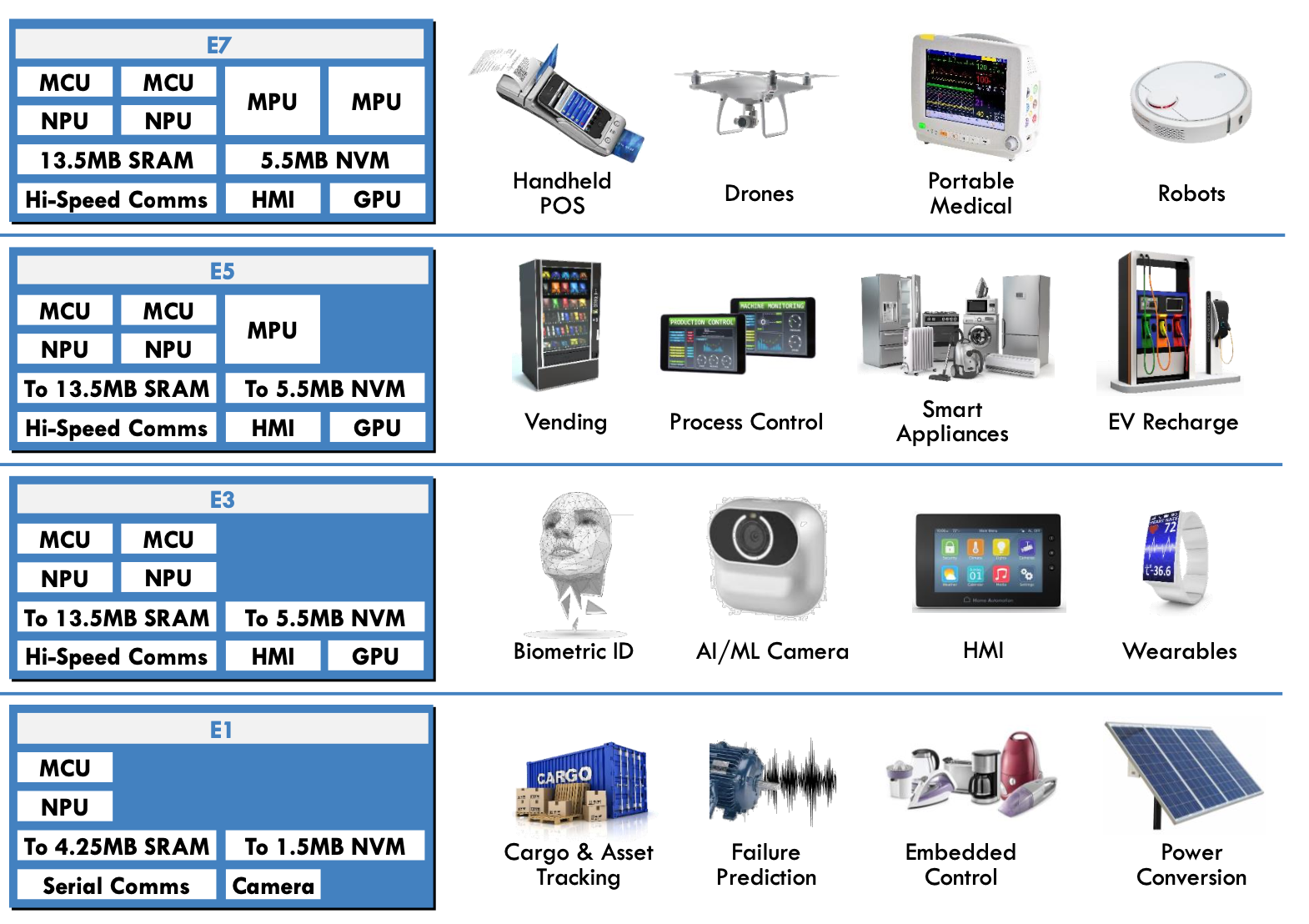
ALIF的AI晶片系列與應用領域;資料來源:ALIF
如果你是嵌入式系統的開發者,下一個要學習的課題,應該就是怎麼善用上圖中的NPU,以滿足Edge AI應用的低功耗、高效率需求。以下摘要Arm幾篇針對Arm micro NPU,即Ethos-U(U55、U65)的技術文,簡介一下Vela Compiler開發環境與流程,希望對大家能有幫助。
NPU模型編譯工具 – Vela Compiler
Ethos -U NPU 是一款小型且節能的AI/ML運算處理核心,用於減少運行機器學習 (ML) 神經網路 (NN) 所需的推理時間和記憶體需求。在硬體配置上,它不會單獨存在,而會與Cortex-M核心、記憶體及周邊整合在一起,配置的方式很多,架構示意圖如下:
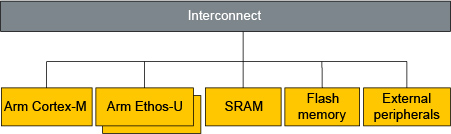
Ethos-U與Cortex-M及記憶體、週邊的互連性示意圖(資料來源)
要在 Ethos-U 上部署神經網路 (NN) 模型,您需要做的第一步是使用Vela Compiler來編譯準備好的模型。Vela 是一個開源 Python 工具,可在 Linux、Mac OS 和 Microsoft Windows 10 作業系統上運作。它可以將訓練好的神經網路模型優化為可以在包含 Ethos-U NPU 的嵌入式系統上運行的模型版本,其開發流程如下:
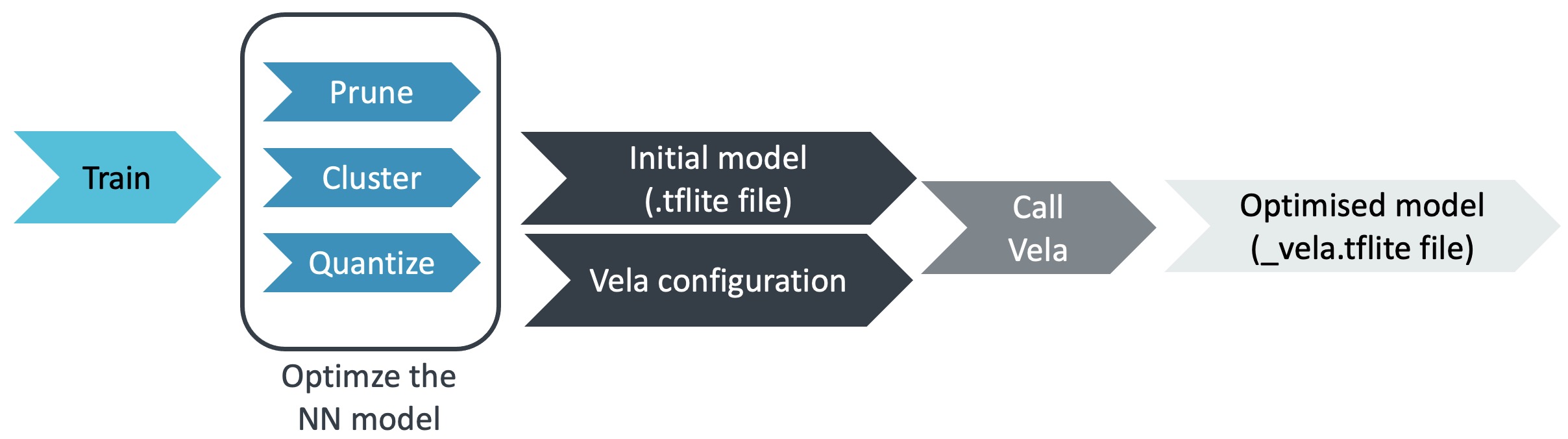
Ethos-U運用Vela Compiler的開發流程圖(資料來源)
以下是開發流程中的3個重要步驟:
1. 準備您的神經網路模型
要透過Ethos-U microNPU 加速,採用的模型必須先量化為 8 位元或 16 位元格式。如果您手邊已經有自己的預訓練模型,目前有許多現成工具可用來轉換及量化模型,例如TensorFlow Model Optimization toolkit,此工具包提供了與TensorFlow Lite相容的量化(quantization)、剪枝(pruning)和聚類(clustering)等最佳化技術。基於最佳化技術,可以降低模型的複雜性和大小,從而減少記憶體使用、儲存大小和下載大小。
如果您手邊沒有模型,則可在Arm ML Zoo和TensorFlow Hub找到各種 .tflite 格式的 ML 模型。您可以直接下載並使用它們作為您自己的模型。
註:TensorFlow Lite 是一個開源深度學習框架,支援設備上機器學習。它允許您將預先訓練的 TensorFlow 模型轉換為 TensorFlow Lite 平面緩衝檔案 (.tflite),該檔案針對速度和儲存進行了最佳化。
2. 準備 Vela 配置檔案(Configuration file)
Vela是Ethos-U系列的高度可自訂的離線編譯工具。您可以使用預設(default)配置的檔案,也可以透過重寫Vela設定檔自訂 Ethos-U 嵌入式系統的各種屬性,例如記憶體延遲和頻寬,這對實際部署是很重要的。
3. 配置並運行
Vela為使用者提供了大量的命令列介面(CLI)來配置每個特定的呼叫過程。在眾多的參數中,除了必須的「網路」之外,正確設定以下關鍵參數選項以反映真實的硬體平台配置是必不可少且重要的。如果您沒有另外指定這些參數,它將在特定於版本的內部預設值下運行。

關鍵配置參數列表(資料來源)
從下圖可以更清楚了解Vela的開發流程:
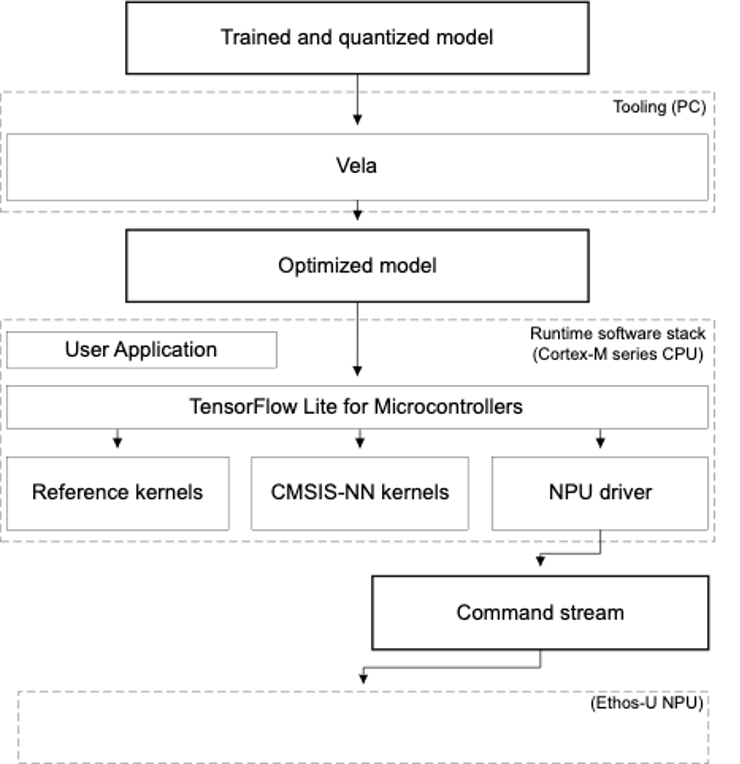 若要存取 Ethos-U NPU 開源軟體、工具、文件和其他說明,請造訪https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u。
若要存取 Ethos-U NPU 開源軟體、工具、文件和其他說明,請造訪https://review.mlplatform.org/plugins/gitiles/ml/ethos-u/ethos-u。
參考資料:
Arm Ethos-U NPU Application development overview Version 5.0
Vela Compiler: The first step to deploy your NN model on the Arm Ethos-U microNPU
Optimize a ML model for fast inference on Ethos-U microNPU

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


