作者:武卓、楊亦誠
Llama 2是Meta發佈的最新大型語言模型,是以Transformer為基礎的人工神經網路,以一系列單詞作為輸入,遞迴地預測下一個單詞來生成文本。這是一款開源且免費的人工智慧模型。在此之前,由於開源協議問題,Llama 1雖然功能強大,但不可免費商用,而這一次Meta終於推出了免費商用版本Llama 2,藉著這個機會,我們來分享一下如何用Llama 2和OpenVINO工具套件來打造一款聊天機器人。
這個應用範例的GitHub資源庫網址如下:https://github.com/OpenVINO-dev-contest/llama2.openvino
備註1:由於Llama 2在模型轉換和運作過程中對記憶體的佔用較高,推薦使用支援64GB以上記憶體的的伺服器終端作為測試平台。
備註2:本文僅分享部署Llama 2原始預訓練模型的方法,如需獲得自訂知識的能力,需要對原始模型進行Fine-tune;如需獲得更好的推論性能,可以使用量化後的模型版本。
匯出模型
第一步,我們需要下載Llama 2模型,並將其匯出為OpenVINO所支援的IR格式模型進行部署,這裡我們使用Optimum-Intel所提供的介面,直接從Hugging Face資源庫中下載並生成IR模型。
compile=False,
from_transformers=True)
ov_model.save_pretrained(model_path)
不過在這之前,我們首先需要向Meta申請模型下載的許可,方可開始下載,具體如何發送申請可以參考Hugging Face網站Llama 2資源庫中的說明和引導:meta-llama/Llama-2-7b-hf
執行專案資源庫中的export_ir.py腳本後,會在本地指定路徑中生成openvino_model.bin和openvino_model.xml,前者為模型參數檔,後者為模型結構檔。
由於目前Hugging Face的Transformer以及Optimum資源庫都已經支援Llama 2系列模型的部署,一種比較簡便和快捷的做法是,直接使用Optimum-Intel來運作整個Llama 2 pipeline,由於Optimum中已經預置了完整的問答類模型pipeline: ModelForCausalLM,並進行了深度的整合,所以我們只需要調用少量介面,並且可以輕鬆調用OpenVINO推論後端,實現一個簡單問答任務的部署。
compile=False,
device=args.device)
ov_model.compile()
generate_ids = ov_model.generate(inputs.input_ids,
max_length=args.max_sequence_length)
output_text = tokenizer.batch_decode(generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]
這裡再簡單介紹下什麼是Optimum。Optimum資源庫是Hugging Face為了方便開發者在不同硬體平台部署來自Transformer和Diffuser資源庫的模型,而打造的部署工具,其中的Optimum-Intel資源庫則支援在Intel平台部署模型時,調用OpenVIN工具套件作為模型的推論後端,提升任務性能。
最終效果如下:
“Response: what is openvino ?
OpenVINO is an open-source software framework for deep learning inference that is designed to run on a variety of platforms, including CPUs, GPUs, and FPGAs. It is developed by the OpenVINO Project, which is a collaboration between Intel and the Linux Foundation.
OpenVINO provides a set of tools and libraries for developers to build, optimize, and deploy deep learning models for inference. It supports popular deep learning frameworks such as TensorFlow, PyTorch, and Caffe, and provides a number of features to improve the performance“
模型部署(方案二)
由於Optimum仍屬於「黑箱」模式,開發者無法充分自訂內在的運作邏輯,所以這裡使用的第二種方式,則是在脫離Optimum資源庫的情況下,僅用OpenVINO的原生介面部署Llama 2模型,並重構pipeline。
整個重構後的pipeline如下圖所示,Prompt提示會送入Tokenizer進行分詞和詞向量編碼,然後有OpenVINO推論獲得結果(藍色部分),來到後處理部分,我們會把推論結果進行進一步的採樣和解碼,最後生成常規的文本資訊。這裡為了簡化流程,僅使用了Top-K作為篩選方法。

Llama 2問答任務流程
整個pipeline的大部分程式碼都可以套用文本生成任務的常規流程,其中比較複雜一些的是OpenVIN推論部分的工作,由於Llama 2文本生成任務需要完成多次遞迴反覆運算,並且每次反覆運算會存在cache快取,因此我們需要為不同的反覆運算輪次分別準備合適的輸入資料。接下來我們詳細解構一下模型的運作邏輯。
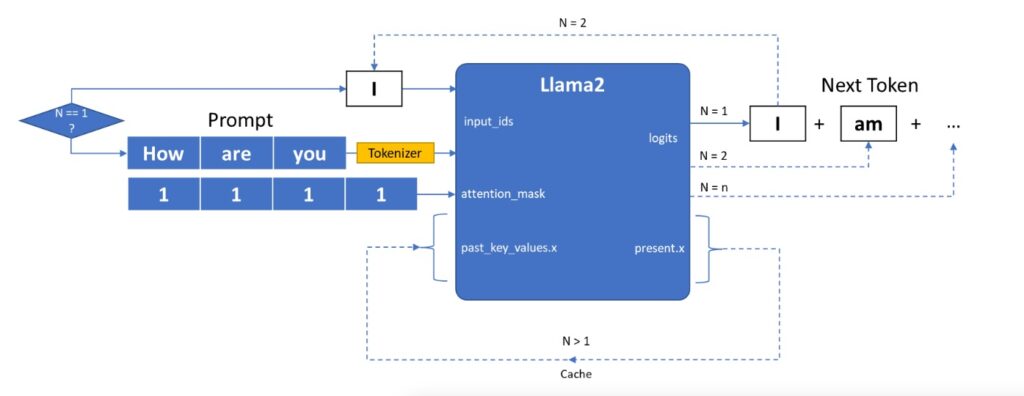
Llama 2模型輸入輸出原理
Llama 2模型的輸入主要由三部分組成:
- input_ids是向量化後的提示輸入。
- attention_mask用來描述輸入資料的長度,input_ids需要被計算的資料所在對應位置的attention_mask值用1表示,需要在計算時被丟棄資料用0表示。
- past_key_values.x是由一連串資料構成的集合,用來保存每次迭代過程中可以被共用的cache。
Llama 2模型的輸出則由兩部分組成:
- Logits為模型對於下一個詞的預測,或者叫next token。
- present.x則可以被看作cache,直接作為下一次迭代的past_key_values.x值。
整個pipeline在運作時會對Llama 2模型進行多次迭代,每次迭代會遞迴生成對答案中下一個詞的預測,直到最終答案長度超過預設值max_sequence_length,或者預測的下一個詞為結束字元eos_token_id。
- 第一次迭代
如圖所示,在一次迭代時(N=1) input_ids為提示語句,此時我們還需要利用Tokenizer分詞器將原始文本轉化為輸入向量,而由於此時無法利用cache進行加速,past_key_values.x系列向量均為空值。
- 第N次迭代
當第一次迭代完成後,會輸出對於答案中第一個詞的預測Logits,以及cache資料,我們可以將這個Logits作為下一次迭代的input_ids再輸入到模型中進行下一次推論(N=2),此時我們可以利用到上次迭代中的cache資料、也就是present.x,無需將完整的「提示+預測詞」一併送入模型,從而減少一些部分重複的運算量。這樣周而復始,將當前的預測詞所謂一次迭代的輸入,就可以逐步生成所有的答案。
聊天機器人
除了Llama 2基礎版本,Meta還發佈了LLaMA-2-chat,使用來自人類回饋的強化學習來確保安全性和幫助性,專門用於構建聊天機器人。相較於問答模型模式中一問一答的形式,聊天模式則需要構建更為完整的對話,此時模型在生成答案的過程中還需要考慮到之前對話中的資訊,並將其作為cache資料往返於每次迭代過程中,因此這裡我們需要額外設計一個範本,用於構建每一次的輸入資料,讓模型能夠給更充分理解哪些是歷史對話,哪些是新的對話問題。
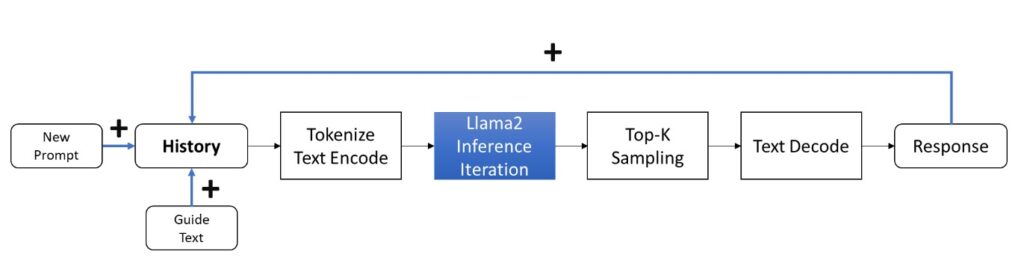
Llama 2聊天任務流程
這裡的text範本是由「引導詞+歷史記錄+當前問題(提示)」三部分構成:
- 引導詞:描述當前的任務,引導模型做出合適的回饋。
- 歷史記錄:記錄聊天的歷史資料,包含每一組問題和答案。
- 當前問題:類似問答模式中的問題。
query: str,
system_prompt=DEFAULT_SYSTEM_PROMPT) -> str:
texts = [f'[INST] <>\n{system_prompt}\n<>\n\n']
for user_input, response in history:
texts.append(
f'{user_input.strip()} [/INST] {response.strip()} <s> [INST] ')</s>
texts.append(f'{query.strip()} [/INST]')
return ''.join(texts)
我們採用streamlit框架構建構建聊天機器人的web UI和幕後處理邏輯,同時希望該聊天機器人可以做到即時互動;即時互動意味著我們不希望聊天機器人在生成完整的文本後,再將其輸出在視覺化介面中,因為這個需要使用者等待比較長的時間來取得結果,我們希望在使用者在過程中可以逐步看到模型所預測的每一個詞,並依次呈現。因此需要利用Hugging Face的TextIteratorStreamer元件,基於其構建一個流式的資料處理pipeline,此處的streamer為一個可以被迭代的物件,可以依次取得模型迭代過程中每一次的預測結果,將其依次添加到最終答案中,並逐步呈現。
skip_prompt=True,
skip_special_tokens=True)
generate_kwargs = dict(model_inputs,
streamer=streamer,
max_new_tokens=max_generated_tokens,
do_sample=True,
top_p=top_p,
temperature=float(temperature),
top_k=top_k,
eos_token_id=self.tokenizer.eos_token_id)
t = Thread(target=self.ov_model.generate, kwargs=generate_kwargs)
t.start()
# Pull the generated text from the streamer, and update the model output.
model_output = ""
for new_text in streamer:
model_output += new_text
yield model_output
return model_output
當完成任務構建後,我們可以透過streamlit run chat_streamlit.py指令啟動聊天機器,並存取本地位址進行測試。這裡選擇了幾個常用配置參數,方便開發者根據機器人的回答準確性進行調整:
- max_tokens:生成句子的最大長度。
- top-k:從可信度對最高的k個答案中隨機進行挑選,值越高生成答案的隨機性也越高。
- top-p:從概率加起來為p的答案中隨機進行挑選, 值越高生成答案的隨機性也越高,一般情況下,top-p會在top-k之後使用。
- Temperature:從生成模型中抽樣包含隨機性, 高溫意味著更多的隨機性,這可以説明模型給出更有創意的輸出。如果模型開始偏離主題或給出無意義的輸出,則表明溫度過高。
備註3:由於Llama 2模型較大,首次硬體載入和編譯的時間相對會比較久
總結
作為當前最火紅的開源大語言模型,Llama 2憑藉在各大基準測試中出色的成績,以及支持微調等特性被越來越多開發者所認可和使用。利用Optimum-Intel和OpenVINO構建Llama 2系列任務可以進一步提升其模型在英特爾平台上的性能,並降低部署門檻。

- OpenVINO 2025.3: 更多生成式AI,釋放無限可能 - 2025/09/26
- 用OpenVINO GenAI解鎖LoRA微調模型推論 - 2025/08/29
- 用OpenVINO GenAI解鎖LLM極速推論:推測式解碼讓AI爆發潛能 - 2025/04/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


