作者:尤濬哲
上一次(ROS系統YOLOv3效能初體驗)我們談到在Intel OpenVINO架構下,當需要進行AI運算時利用Intel GPU加速一樣可獲得不錯的效能,並且使用YOLO v3進行測試。
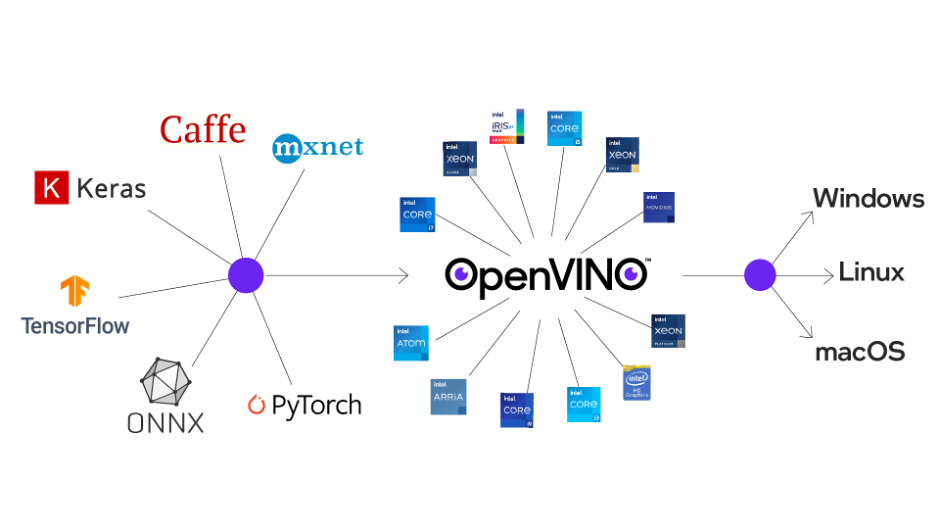
這次我們將會自製一個CNN分類器,並透過OpenVINO的模型轉換程式轉換成IR模型,並進行模型效能與正確率分析。依據Intel官方網站的說明,OpenVINO可以針對不同模型進行最佳化,目前支援包括Tensorflow、Keras、Caffe、ONNX、PyTorch、mxnet等多種模型。
也就是說,當使用者透過其他框架訓練完成的模型檔,例如Keras的model.h5檔,或者TensorFlow的model.pb檔,只要經過轉換就可以在OpenVINO中以最高效能來執行。
(圖片來源: Intel OpenVINO官方網站)
不過讀者可能會比較在意的就是透過OpenVINO加速後,效能是能提昇多少、正確率會不會發生變化?還有就是若我已經有一個訓練好的Model,我要如何轉換為OpenVINO可以讀取的模型呢?
本文將分為兩個部份來說明,第一個部份就是如何進行模型轉換,第二部份則來評測轉換前後的執行效能差異,除了模型比較之外,讀者一定會想了解Intel OpenVINO GPU與NVIDIA CUDA的差異,這部份也在本文中進行比較,我相信會讓讀者大開眼界。
OpenVINO模型轉換
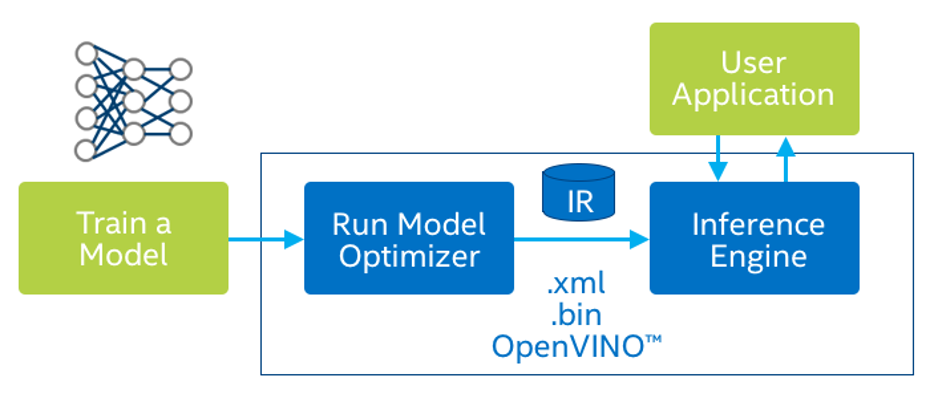
以目前官方文件所述,OpenVINO架構執行效能最佳的為IR(Intermediate Representations) 格式模型,所謂的IR模型是「中間表達層」,IR模型包含一個bin及xml,bin包含實際權重的網路權重weight及誤差bais資料,而xml則是記載網路結構。
後續當OpenVINO要載入模型時,只要讀取這兩個檔案即可,雖然這樣轉換須多經過一道手續,但是卻可大幅提高執行效能,在此我們介紹如何轉換模型。
(資料來源:openvino官網)
本次就以筆者在教學上最常用的個案「玩猜拳」為例,利用卷積類神經CNN模型製作一個圖形分類器,可以對「剪、石、布」以及「無」(代表使用者還沒有出拳)的四種圖形進行判斷。模型採用[224x224x3]的圖片格式,本文以Tensorflow為例演練轉換過程,其他模型轉換方式類似,讀者可以參考本例作法進行轉換測試。

無(N)
布(P)

石(P)

剪(S)
1. TensorFlow模型轉換
一般來說以TensorFlow訓練模型的話,那麼我們可能會得到兩種格式的檔案,一種為使用Keras的h5檔,另外一種則是TensorFlow的pb檔,h5檔案可以透過python轉換成pb檔,因此本文僅介紹pb檔的模型轉換。
另外為了後續測試能有一致的標準,本文的模型使用Google的Teachable Machine(簡稱TM)進行訓練,這樣可以讓讀者在與自己的電腦進行效能比較時,能有較公平的比較基準,若讀者有自行訓練的類神經模型,一樣可以參考下面的方式進行轉換。
關於TM的訓練過程,請自行參考其他教程,本文僅針對最後的模型下載過程進行說明。也就是說,當TM已經訓練好模型之後,就可以點選右上角的「Export Model」匯出模型。
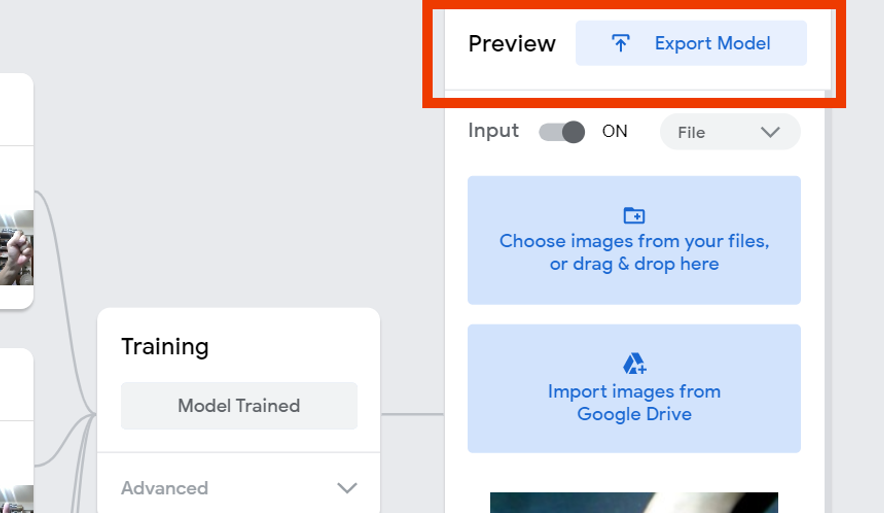
開啟匯出模型視窗後,點選:1.Tensorflow,然後點選儲存格式為2.Savemodel,最後選3.Download my model。
此時下載的檔案內容包含一個文字檔案「labels.txt」及資料夾「model.savedmodel」,而在資料夾內則包含「saved_model.pb」及資料夾「assets」及「variables」,接下來我們就可以將此檔案轉換為IR格式。
下載的tensorflow pb檔案。
下一步我們則可以利用OpenVINO內建的「model_optimizer」模組進行優化及模型轉換,一般是在「/opt/intel/openvino_安裝版本/deployment_tools/model_optimizer/」資料夾內,我們將會選用的轉換程式為mo_tf.py,而語法如下
python3 mo_tf.py --saved_model_dir <<模型檔案存放資料夾路徑>> --output_dir <<IR模型檔輸出路徑>> --input_shape <<輸入層結構>> --data_type <<選用的資料格式>>
舉例來說,假設我的pb模型檔存放在「Tensorflow/SaveModel」資料夾內,而要輸出到「IR」資料夾,而第一層架構為[1,224,224,3](此代表輸入1張圖,長寬為224×224,有RGB三色),選用FP32(預設值)為資料格式,此時語法為
python3 mo_tf.py --saved_model_dir Tensorflow/SaveModel --output_dir IR --input_shape [1,224,224,3] --data_type FP32
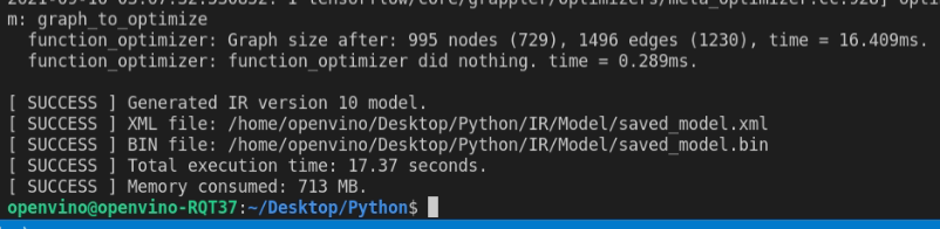
轉換完成會出現的訊息。
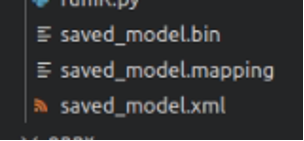
轉換完成的IR模型檔案。
當轉換完成的訊息出現後,就可以在IR資料夾中看到三個檔案「saved_model.bin」、「saved_model.mapping」、「saved_model.xml」,這樣就代表轉換完成了。
若您原本是使用Keras的h5 model檔案的話那該怎麼辦,先轉成pb檔結構,再轉換成IR即可,以下為h5轉換pb的python語法。
import tensorflow as tf
model = tf.keras.models.load_model('saved_model.h5') #h5的檔案路徑
tf.saved_model.save(model,'modelSavePath') #'modelSavePath'為pb模型檔案輸出路徑
將h5轉換成pb檔案後,就可以依照前述方式將再將pb轉換成IR檔案。除了TensorFlow之外,其他模型的轉換方式,可以參考OpenVINO官方網頁說明。
模型轉換效率比較
當使用OpenVINO進行模型轉換時,並非單純轉換而已,事實上OpenVINO在轉換過程會對模型進行最佳化(算是偷吃步嗎?哈哈),最佳化部份包括以下兩種:
- 修剪:剪除訓練過程中的網路架構,保留推理過程需要的網路,例如說剪除DropOut網路層就是這種一個例子。
- 融合:有些時候多步操作可以融合成一步,模型優化器檢測到這種就會進行必要的融合。
如果要比較最佳化後的類神經網路差異,我們可以透過線上模型視覺化工具,開啟兩個不同模型檔案來查看前後的變化。下圖為利用netron分別開啟原始pb模型及轉換後的IR模型的網路架構圖,讀者可以發現經過轉換後的模型與原始TensorFlow模型有很大的差別,IR模型會將多個網路進行剪除及融合,減少網路層數提昇運算效能。
以下圖為例,左側為IR模型,右側為TF模型,兩者比較後可以發現,原先使用的Dropout層已經在IR中被刪除。
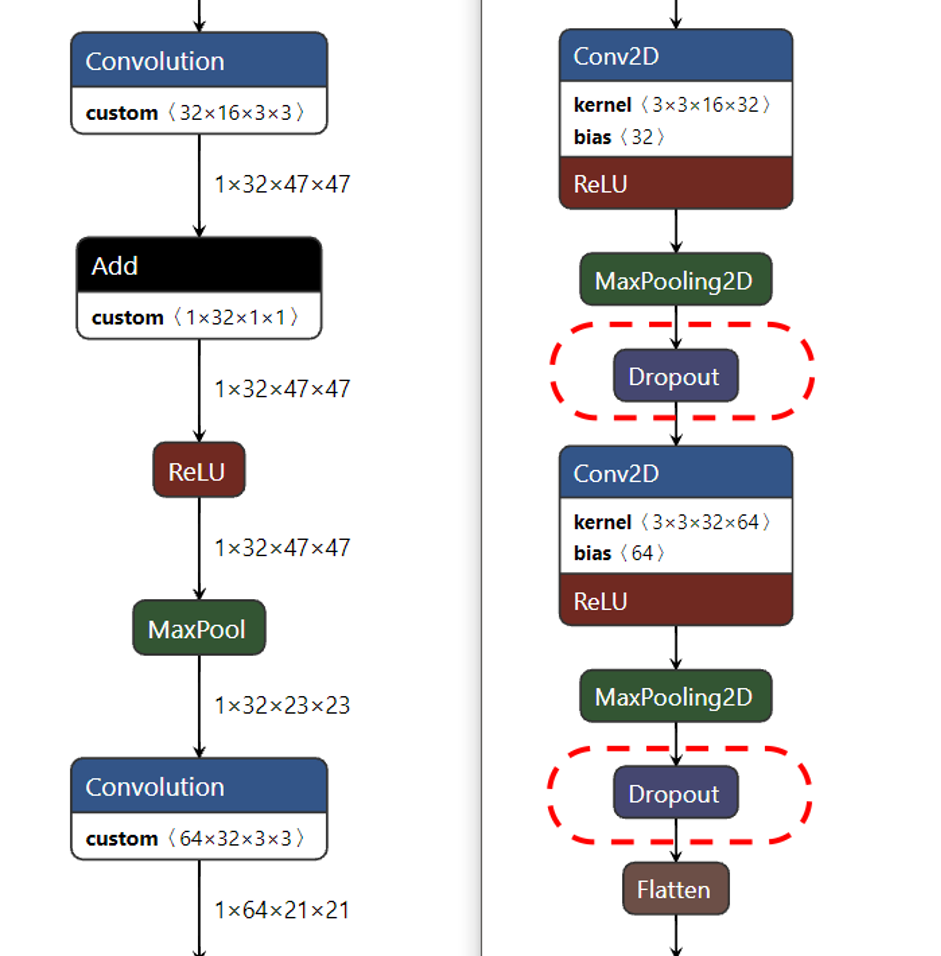
模型轉後前後比較圖左圖為IR模型,右圖為原始TensorFlow模型(由於模型都相當大,此處僅呈現差異的一小部份)
在OpenVINO轉換工作結束後,就會告知最佳化前後所造成的差異,以本例而言,原本995個節點、1496個路徑的類神經網路就被最佳化為729個節點、1230個路徑,因此能提昇運算效率。

解模型轉換過程之後,接下來就是測試OpenVINO在執行上是否有效能上的優勢。以下會有二個測試,測試項目包括效能及正確率,以了解OpenVINO是否能具有實用性,也就是說在獲得效能的同時,是否能保有相同的正確性,讓讀者對於後續是否採購支援OpenVINO機器有比較的依據:
- 在RQP-T37上測試IR模型及TensorFlow Keras h5模型效能比較
- OpenVINO iGPU及Colab的 GPU效能比較
1.在RQP-T37上測試IR模型及Tensorflow上的差異
本測試是同一台機器(RQP-T37)及環境(Ubuntu 20.04.2 LTS)之下進行,模型則採用Google TeachableMachine所製作的手勢分類器(猜拳遊戲:剪刀石頭布),辨識對象為800張224x224x3的手勢照片,模型採用FP32進行分析辨識總時間及正確率。
為了避免單次測試可能造成的誤差,測試取100次的平均及標準差,並繪製盒型圖(Box plot),本測試並不使用其他測試常採用的fps(Frame per second),而僅計算的是辨識(inference)總時間,不計算檔案讀取、資料轉換過程所耗費的時間。因為本測試主要要了解模型轉換後的差異,避免受到其他因素的影響因此不使用fps。
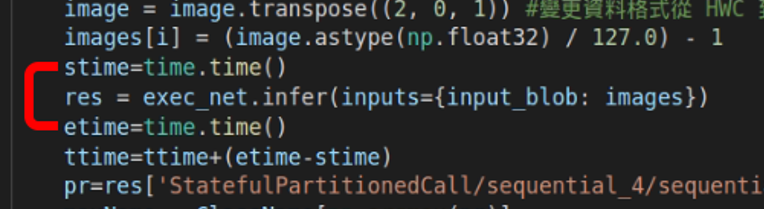
(a) IR模型程式碼片段,顯示僅計算推論時間。(評估標準為Inference總時間)
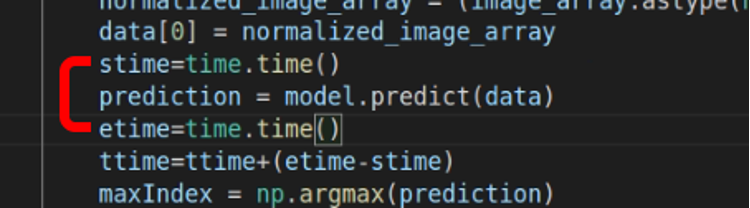
(b) TensorFlow模型程式片段,顯示僅計算推論時間。(評估標準為Inference總時間)
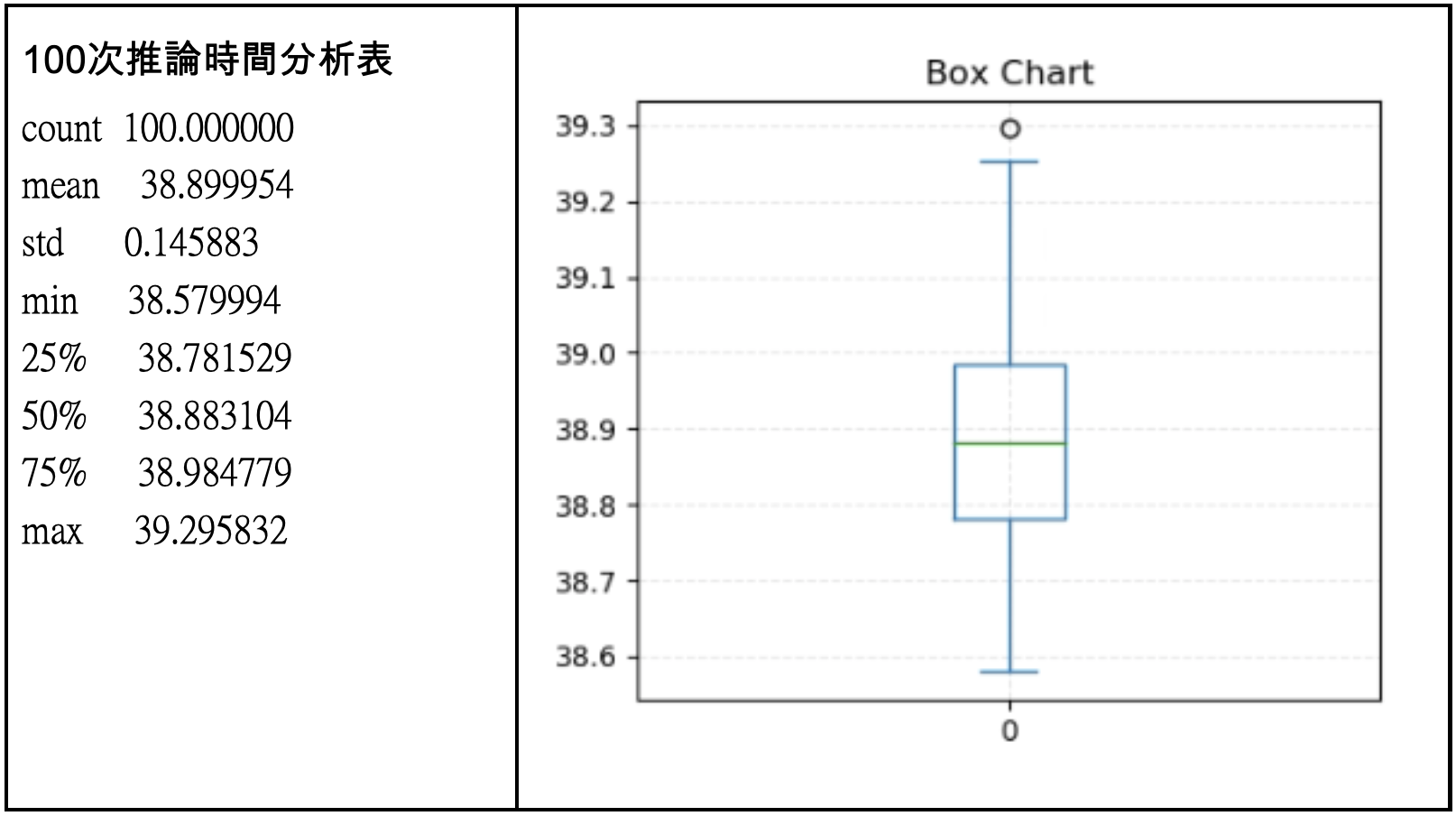
在完成100次執行之後,我們先看原始TensorFlow模型的執行狀況如下表,做完800張照片的手勢推論,平均時間為38.941,換算辨識一張的時間約0.04秒,而標準差0.103,大致換算fps的上限約25,這樣的結果算是中規中矩。
另一方面IR模型進行推論結果則呈現在下圖,可以發現效能非常高,分析800張照片平均只要1.332秒,也就是一張224×224的照片僅需要0.00166秒,非常不可思議,換算fps上限約為602,若看標準差也只有0.008,代表耗費時間也相當穩定,並無太大起伏。
相對於原始的Tensorflow pb模型來說,效能大約提昇了30倍,相當令人驚豔。
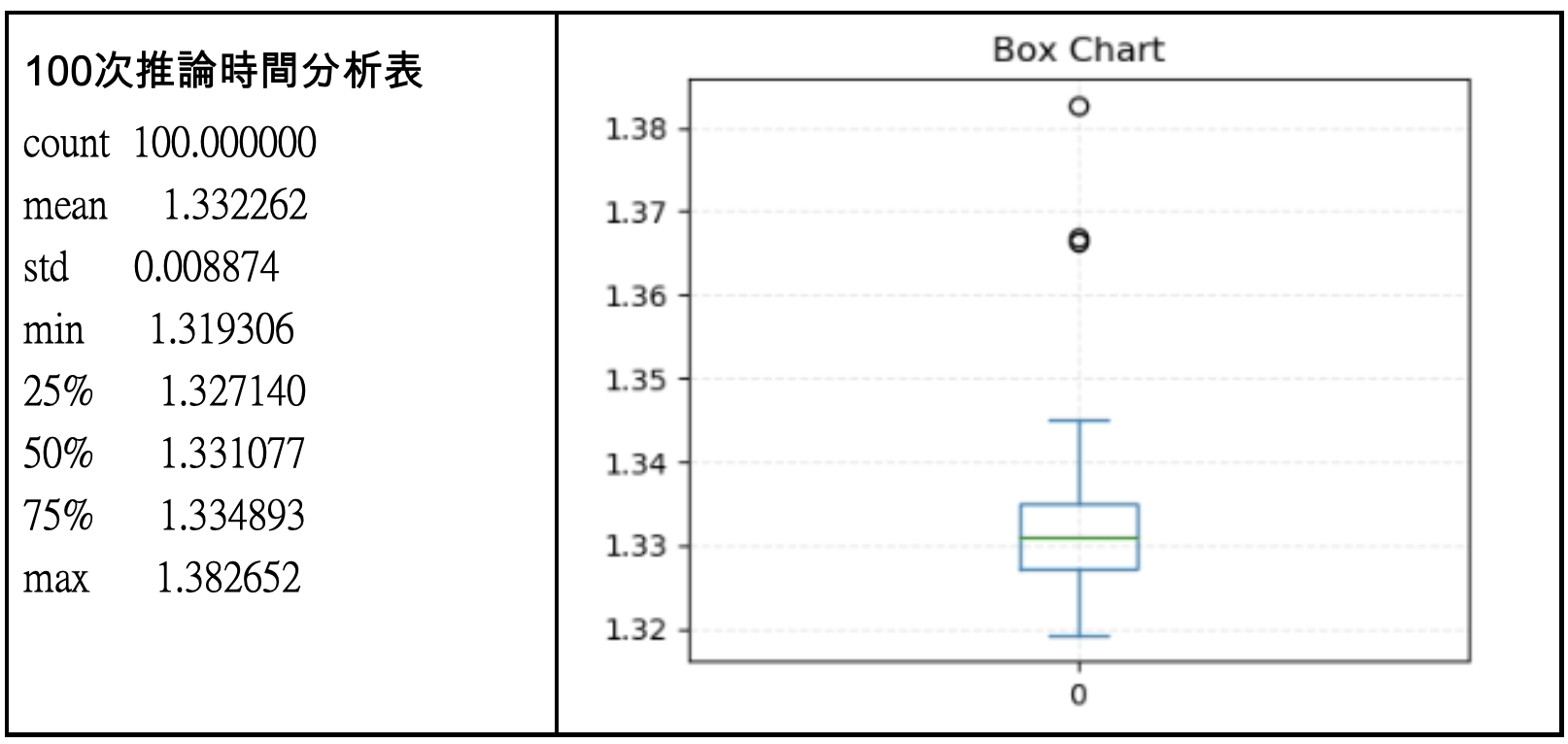
雖然效能提昇如此之多,讀者應該會覺得OpenVINO的Inference引擎可能會在「效能」與「正確性」之間進行trade off,是否在大幅提昇效能後,卻喪失了最重要的推論正確性?此時觀察兩次測試時的混淆矩陣可以發現,在TensorFlow模型時800次只有3次將布看成剪刀,正確率為797/800大約0.996。
而在IR模型時,800次辨識有9次將石頭看成剪刀,所以其正確率為793/800=0.991,事實上兩者相差無幾,不過有趣的是兩個模型所辨識錯誤的項目不太一樣,值得後續再深入討論。
筆者在此必須強調,OpenVINO架構的效能提昇如此之多,個人認為主要在於模型最佳化(model_optimizer)的過程,雖然Intel CPU及GPU雖然有所幫助,但不可能把效能提升到30倍之多。
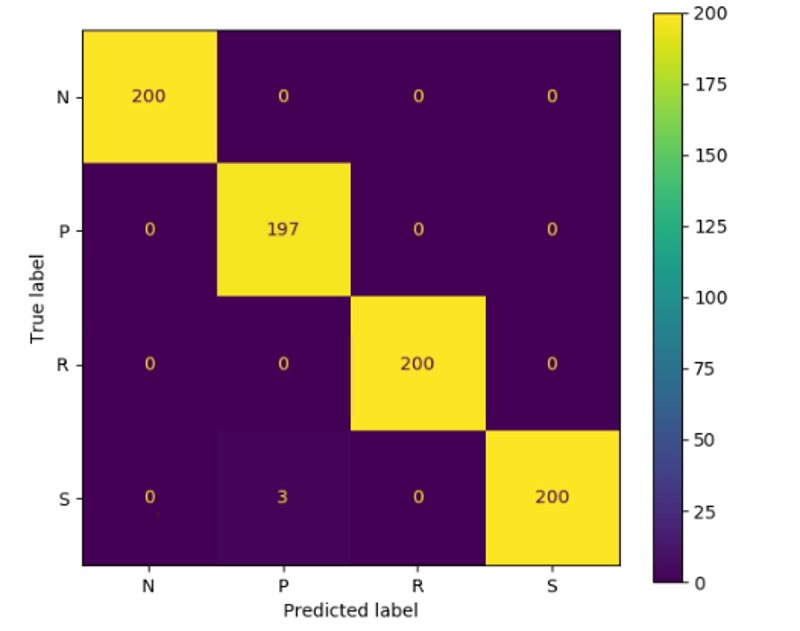
TensorFlow模型辨識混淆矩陣
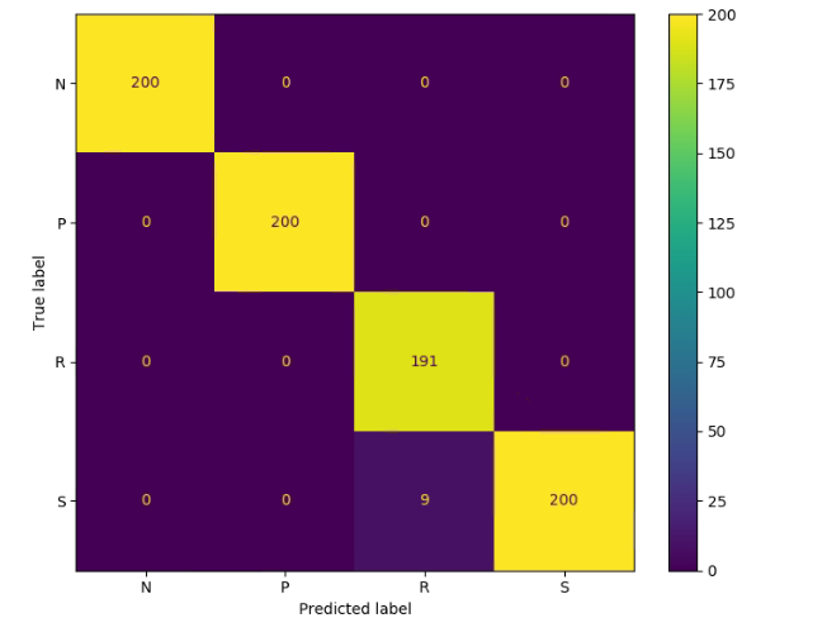
IR模型辨識混淆矩陣
測試小結:
- 經過最佳化的IR比TensorFlow模型效能上大幅提昇,差異約30倍
- 經過最佳化的IR與TensorFlow模型正確率幾乎相當
2.比較OpenVINO iGPU及Colab的 GPU
本測試則是使用Colab上的GPU進行加速運算,Google Colab可以說是近幾年來最受歡迎的程式開發平台了,尤其是提供免費的GPU加速,可以讓使用者在AI運算上獲得相當好的效能。因此本次也針對Colab平台進行測試,測試之前查詢Colab所提供的GPU規格為Tesla T4。
而根據NVIDIA的規格表,T4具有2,560個CUDA核心,FP32的算力為8.1 TFLOPS。

NVIDIA T4規格(資料來源:NVIDIA)
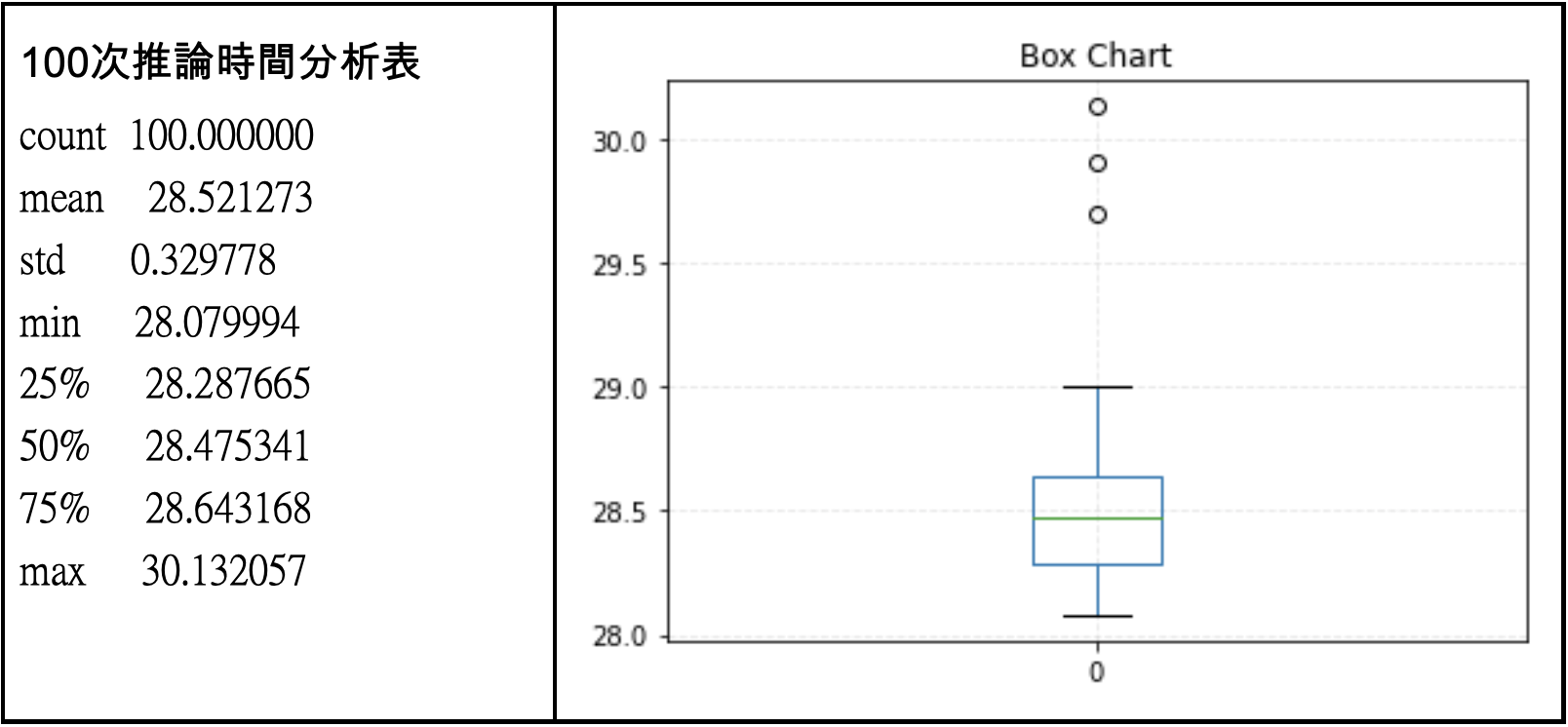
與前次測試相同,推論對象為800張224x224x3的圖片,採用原始的TensorFlow pb模型,且確認有開啟GPU加速。
經過100次分析後,獲得上表可以得知,Colab的運算速度比本次測試用的電腦採用的Intel CPU時效能高,平均一次約28.52秒,相當於分類1張照片只花0.035秒,換算fps上限28.05,這個效能符合Colab 所提供的GPU規格。
讀者可能會想到在Colab上的照片讀取效能比Local端差多了,這樣評估不公平,這裡要注意的是,我們測試都僅加總推論時間,並沒有計算檔案讀取的時間。此次測試比較後,OpenVINO效能還是明顯較好。不過一樣的,筆者認為效能提昇是來自於OpenVINO的模型最佳化。
測試小結:
- 同樣在pb模型下,Colab採用的GPU加速後,效能大於Intel CPU
- IR模型在OpenVINO模型最佳化及加速後,效能超過NVIDIA CUDA
結論
本次文章主要讓讀者了解OpenVINO架構的效能與正確性的比較,另外也說明自製模型的轉換過程。測試時雖硬體上有明顯差距,以及並未使用TensorRT做模型最佳化,但本測試還是有一定的代表性,也就是說當讀者擁有一台Intel電腦時,透過安裝OpenVINO ToolKit來進行模型最佳化,一樣可以獲得性能相當好的AI辨識引擎,不一定要購買超高等級的顯示卡才能進行AI專案開發。
畢竟一般讀者購買電腦一定有CPU,卻不一定會購買獨立GPU顯示卡,或者像是無法加裝顯示卡的筆記型電腦,以往沒有獨立顯卡的電腦以CPU進行AI推論時都會花費大量時間,系統無法即時反應,因此缺乏實用性。而本次測試則是證明在OpenVINO架構下,就可以透過模型最佳化程式及Intel GPU加速,進而在幾乎不影響正確率的結果下得到非常好的效能,這個效能甚至超越 NVIDIA架構。
不過筆者必須提醒讀者,目前OpenVINO只有提供Inferencing,尚不提供Training的功能,所以讀者必須先透過其他方式進行訓練獲得模型後,才可以在OpenVINO中進行實地推論。雖然如此,無論是採用Intel的電腦,還是標榜低價的文書電腦,都可以快速進行AI運算,可以說是實做AI系統非常好的工具。
(責任編輯:謝涵如)

學歷:中山大學資訊管理研究所 博士
- 舊瓶裝新酒還是新瓶裝舊酒?Jetson Orin Super效能實測 - 2025/03/12
- 低成本空氣品質感測器 – 夏普 GP2Y10開箱實驗 - 2023/03/16
- 【ESP32專欄】ESP32 MQTT與深度睡眠 - 2022/06/20
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


