作者:曾成訓
最初版本的 YOLO 論文公佈於 2015 年,刊登於 arXiv 公開論文網站上,掛名的作者分別是 Joseph Redmon、Santosh Divvala、Ross Girshick 以及 Ali Farhadi,但主要開發者應該是 Joseph Redmon,這是他的個人網站 https://pjreddie.com/。除了電腦,他還喜愛滑雪、徒步旅行、攀岩以及和他的阿拉斯加雪撬犬 Kelp 玩,所以他的 YOLO 論文(https://arxiv.org/abs/1506.02640)寫得相當的平實有趣,V2 版還被選為 2017 年最佳論文。
Joseph Redmon 曾經上 TED 演講介紹 YOLO,可上此網址觀看:https://www.ted.com/talks/joseph_redmon_how_a_computer_learns_to_recognize_objects_instantly?language=zh-tw#t-434921
他在影片中介紹了影像分類及物件偵測的不同,推廣 Object detection 的應用並展示了 YOLO 在實時偵測上的威力。

有興趣可看Joseph Redmon的演講或是到他官網了解更多(圖片來源:作者提供)
如何訓練自己的 YOLO model
1. dataset 準備與架構
從 V2 開始,可以自行在 cfg 檔中設定輸入圖片的尺寸(預設 416×416 或最高 608×608,或任何大於 32 的 2 次方倍數尺寸)。所以若在拍攝相片時能用愈高像素來拍愈好,可 label 出的物件愈多,且在後續使用的彈性更大。
在相片的準備上,建議需注意多樣及差異性,假設我們要準備柑橘圖片供辨識使用,那麼拍攝時需注意到:
- 不同環境:比如溫室或戶外的場地,高架或平地種植的草莓。
- 不同季節:蔬果外觀顏色的變化。
- 不同時間:光影的變化帶來的差異,直射斜射或散射光。
- 不同氣候:雨天與乾季對於蔬果外形的影響。
- 不同生長周期:蔬果從發芽抽高長葉到開花結果成熟…等,不同時期的外觀變化。
2. 相片或攝影的選擇
使用影片匯出影格 frames 作為訓練用圖片,目前也是主流方法之一,與相片拍攝比較,個人覺得最大差異有二,其一 ,事前篩選(相片)或事後篩選(攝影);其二,像素尺寸大小。
|
相片 |
影片 |
|
| 優點 | 1. 尺寸及解析度較高
2. 篩選相片時間少, 可直接進行 label 3. 成本較低 |
1. 直接針對目的物進行錄影,不需一張張拍攝,搜集 data 較方便省時。
2. 短時間內便可搜集到各種不同角度不同視野的大量相片。 3. 訓練時可針對欠缺的某一角度或形態的相片,再從影片檔中去取得再加入訓練。 |
| 缺點 | 1. 拍攝時需考慮角度對焦及距離,搜集 data 會發費較多時間。
2. 若缺少某一類相片,必須重回現場拍攝取得。 |
1. 解析度較低,物體太小時無法利用裁圖方式來放大。
2. 需花費時間針對影片中的 frames 進行篩選匯出,才能開始 label。 3. 1080P 或 4K 錄影,硬體成本較相機高。 |
我個人偏好的模式是以相片為主攝影為輔,在準備 dataset 階段可先用相片拍攝大量相片後,再花點時間用攝影模式拍幾段影片,之後在訓練的過程中,若發現效果不理想或有某一類型的圖片缺乏,可從影片中尋找符合該類型的 frame 加入訓練。
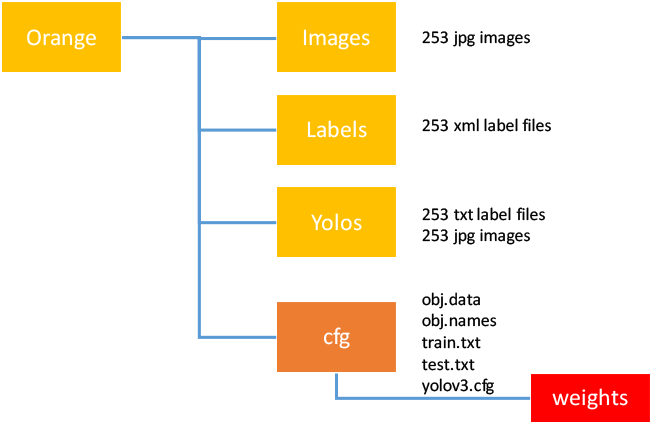
3. 建立相關資料夾
首先,先建立如下三個資料夾,然後將上一步欲用來訓練的相片放置於 images 資料夾中。
建立資料夾並把相片放入images資料夾(圖片來源:作者提供)
4. 開始label相片
這裡使用的 Label 軟體是 LabelImg,請從 https://github.com/tzutalin/labelImg 下載並執行該軟體。剛執行時畫面是空的,請按「Open Dir」、「Change Save Dir」選擇剛剛建立的 images 以及 labels 資料夾,接下來便可從下窗格中選擇要 label 的相片,「按下 Create RectBox」便可開始 label。

下載並執行 LabelImg 軟體(圖片來源:作者提供)
在作 label 框選時,請考慮是否有足夠的紋理特徵?此外,若人眼都無法確定的物件,就放棄框選。

人眼都無法判斷就放棄框選(圖片來源:作者提供)
框選完所有的相片之後,您的資料夾下應會分別有相同數目的 image 檔及 xml 的 label 檔。
請注意,目前新版 for windows 的 LabelImg 新增 YOLO 格式,因此可以直接輸出 YOLO 需要的檔案格式,您可以直接使用該格式,但我的習慣還是用較為流行的 Pascal VOC 格式,另外再寫一支程式將 VOC 轉為 YOLO 格式,好處是 VOC 較多人使用,而我們的 dataset 除了 YOLO 之外,還可以支援其它的 object detection 模型。

格式取決個人習慣(圖片來源:作者提供)
5. 轉換 VOC labels 為 YOLO 格式

YOLO格式是text文字檔(圖片來源:CAVEDU提供)
YOLO 所需要的 label 格式不同於我們所熟知、ImageNet 使用的 PASCAL VOC xml,而是採用 text 文字檔,第一欄為 class 的 ID,其它皆以物件框相對於整張圖片的比例來呈現:
| 類別代碼 | 物件中心x位在整張圖片x的比例 | 物件中心y位在整張圖片y的比例 | 物件寬度w佔整張圖片寬度的比例 | 物件長度h佔整張圖片長度的比例 |
| Categorynumber | Object centerin X | Object centerin Y | Object widthin X | Object heightin Y |
例如下圖定義了三個名稱為「Orange」的 label,右側為 PASCAL VOC 的格式,下方為 YOLO 的格式,可用如下計算方式來轉換 VOC→YOLO。
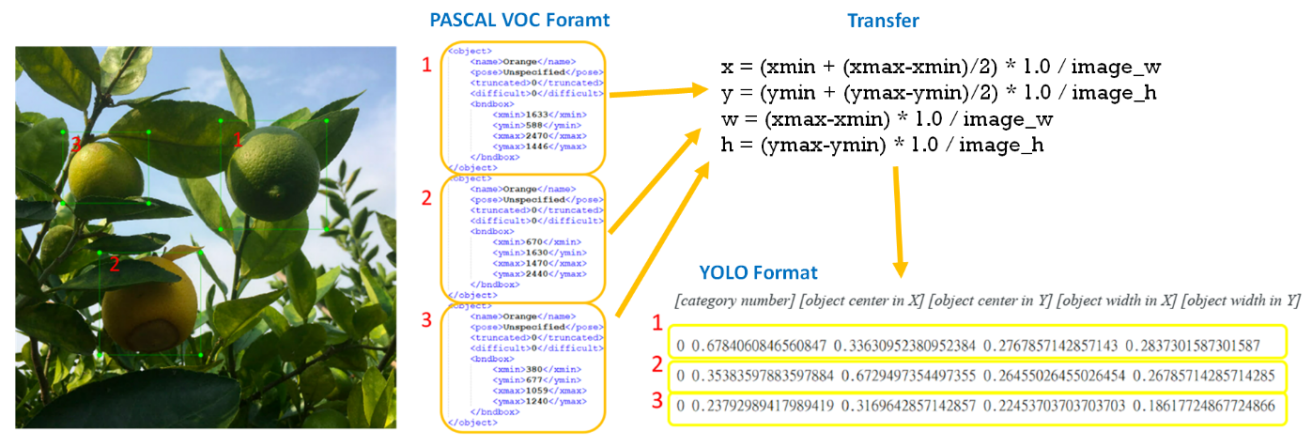
轉換VOC→YOLO(圖片來源:作者提供)
轉換公式:
x = (xmin + (xmax-xmin)/2) * 1.0 / image_w
y = (ymin + (ymax-ymin)/2) * 1.0 / image_h
w = (xmax-xmin) * 1.0 / image_w
h = (ymax-ymin) * 1.0 / image_h
6. 建立YOLO資料夾,放置Label檔及圖片檔
YOLO 的 label 檔是 text 格式的 .txt,每張圖片對應一個 txt 檔,且兩者較要放置於同一資料夾中,因此,我建了一個資料夾名稱為 YOLO,將所有 images 及 txt 檔全部放置於其下。稍後在訓練時,YOLO 只會 access 該 Yolos 資料夾,Images 和 Labels 這兩個已經不需要了。

建立YOLO資料夾,放置Label檔及圖片檔(圖片來源:作者提供)
7. 建立設定檔 cfg 資料夾
在 Orange 目錄下,新增 cfg 資料夾,我們將在此資料夾下放置 YOLO 設定檔。
建立設定檔 cfg 資料夾(圖片來源:作者提供)
有五個設定檔,分別為:
obj.names、obj.data、train.txt、test.txt、yolov3.cfg or yolov3-tiny.cfg
1. obj.names:此檔內容為 label 的列表,例如 mature 與 flower,YOLO 在訓練與預測時皆需要讀取此檔。

2. obj.data:定義 label 數目以及各個設定檔及 weights 目錄的 path,YOLO 訓練及預測時皆會讀取。
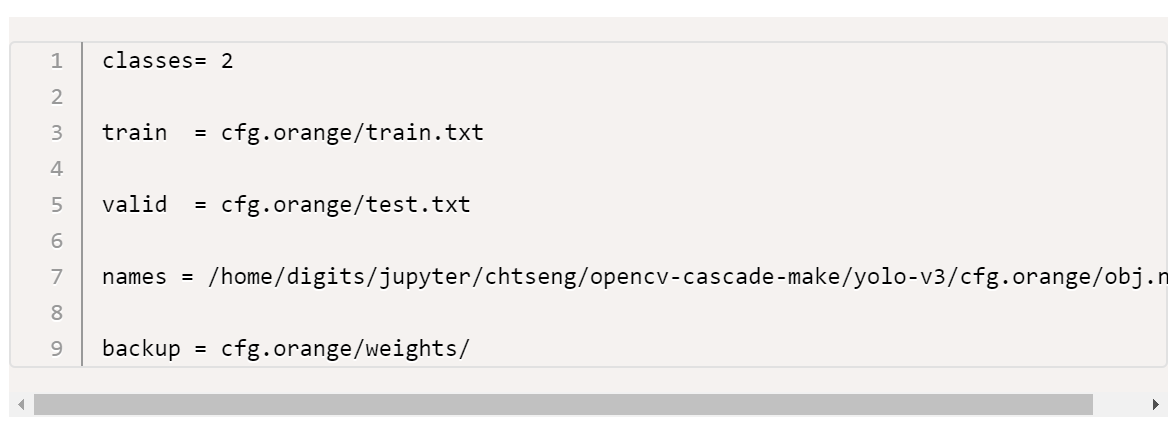
3. train.txt:所有 images 檔案名稱列表中的 80%(或其它比例,可視需求變更),訓練時 YOLO 會依次讀取該檔內容取出相片進行訓練.。您可以手動或寫程式取出固定比例的列表放置於此檔案內容中。
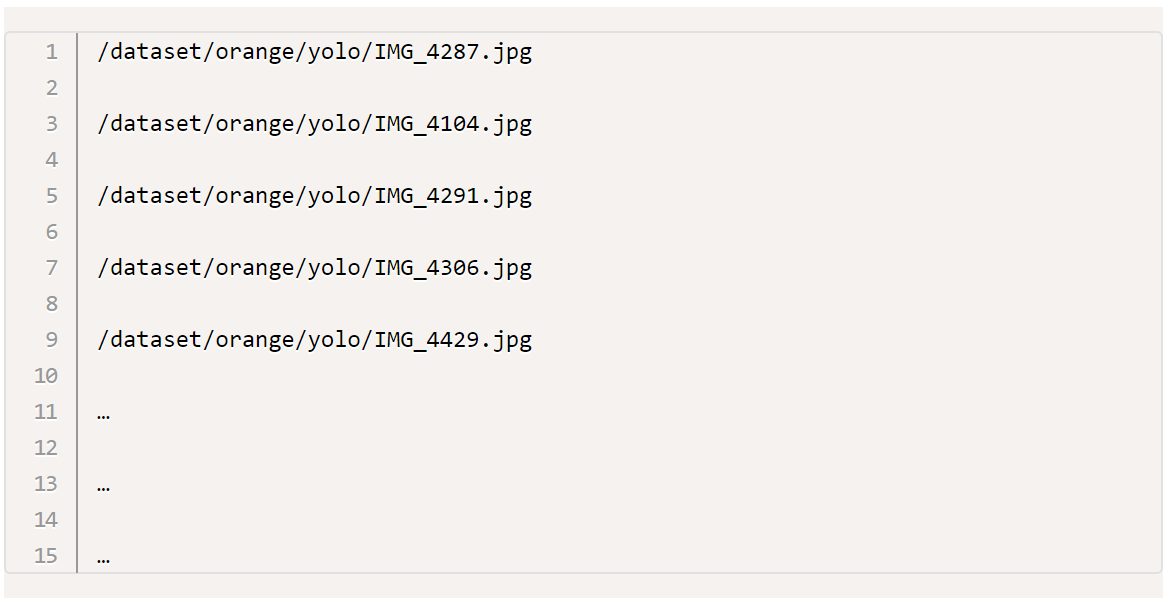
4. test.txt:所有 images 檔案名稱列表中的 20%(或其它比例,可視需求變更),訓練時 YOLO 會依次讀取該檔內容取出相片進行 validation.。您可以手動或寫程式取出固定比例的列表放置於此檔案內容中。

5. yolov3.cfg or yolov3-tiny.cfg :YOLO 模型設定檔,請從 Darknet 安裝目錄下的 cfg 資料夾找到需要的 YOLO cfg 檔(標準或 tiny YOLO),複製到本 cfg 資料夾。
6. 修改 yolo 模型的 cfg 檔:
如果您想訓練 Tiny YOLO,請複製並修改 yolov3-tiny.cfg 如下:
Line 3: set batch=24 → using 24 images for every training step
Line 4: set subdivisions=8 → the batch will be divided by 8
Line 127: set filters=(classes + 5)*3 → in our case filters=21
Line 135: set classes=2 → the number of categories we want to detect
Line 171: set filters=(classes + 5)*3 → in our case filters=21
Line 177: set classes=2 → the number of categories we want to detect
如果您想訓練 YOLO,請複製並修改 yolov3.cfg 如下:
Line 3: set batch=24 → using 24 images for every training step
Line 4: set subdivisions=8 → the batch will be divided by 8
Line 603: set filters=(classes + 5)*3 → in our case filters=21
Line 610: set classes=2 → the number of categories we want to detect
Line 689: set filters=(classes + 5)*3 → in our case filters=21
Line 696: set classes=2, the number of categories we want to detect
Line 776: set filters=(classes + 5)*3 → in our case filters=21
Line 783: set classes=2 → the number of categories we want to detect
batch 參數是指每批次取幾張圖片進行訓練,subdivisions 參數是指要將每批次拆成幾組,以避免 GPU memory 不夠。如果您是使用 12G 的 1080 Ti GPU,建議使用其預設的 batch=24、subdivisions=8 即可。
另外,由於標準 YOLO V3 有三個 detector 針對三種 scale 的 feature map,因此要修改三組的 filters 及 classes。Tiny YOLO 只有兩個 detector,因此要修改兩組。
修改完 yolov3.cfg or yolov3-tiny.cfg 之後,便可開始進行訓練了。
8. 開始訓練
新建一目錄給儲存訓練過程的 weights 權重檔,該目錄的路徑名稱定義於 obj.data 中的 backup 參數。
(圖片來源:作者提供)
2. 下載預訓練檔
請從 https://pjreddie.com/media/files/darknet53.conv.74,下載 darknet53.conv.74 weights pre-trained on Imagent,該檔大小約 155MB,可同時用於訓練 YOLO 及 Tiny YOLO。另外,也可以考慮使用 Imagent+COCO datasets 所訓練的 yolov3.weights (https://pjreddie.com/media/files/yolov3.weights)或 yolov3-tiny.weights(https://pjreddie.com/media/files/yolov3-tiny.weights)。
下載後的訓練檔請置於可讀取到的位置,下一步將用到。
3. 執行 darknet command 開始訓練
../../darknet/darknet detector train cfg.orange/obj.data cfg.orange/yolov3-tiny.cfg darknet53.conv.74
4. 訓練過程會持續的秀出各種數值,並且每隔 100batches 會寫出一個 weights 檔。其 log 說明如下:

(圖片來源:作者提供)
5. 一般來說,我們最需要注意的是紅框的 average loss error,如果您訓練的圖片數目有數千個以上,那麼 average loss error 約 0.06 左右便可手動停止了,如果僅有數百張,那麼大約 0.6 左右便可先試著載入其 weights 檔測試看看辨識效果是否滿意。YOLO 在訓練過程中每訓練 100 batches 便會寫入一個新的 weights 檔到目錄中,我們可以隨時取用以檢視目前的訓練成果。
9. 檢視訓練成果
我們找一張圖片,然後使用下列的 Darknet command 來測試。
../../darknet/darknet detector test cfg.orange/obj.data cfg.orange/yolov3-tiny.cfg cfg.orange/weights/yolo_18200.weights {要測試的相片路徑}
執行後,會將指定的測試相片進行檢測後,將結果輸出為 predictions.jpg。

(圖片來源:作者提供)
(本文經作者同意轉載自CH.TSENG部落格、原文連結;責任編輯:楊子嫻)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


