作者: Jason Zhu,Arm資深首席工程師
互動式影像分割已成為全球最受歡迎應用程式中的代表性行動體驗。簡單來說,你只需要在圖片上點一下(或畫出一個大致的提示),應用程式就能立即透過產生像素遮罩(pixel mask)將物件「裁切」出來。這使得一些常見功能得以實現,例如建立個人化貼圖、將主體從背景中分離以替換背景,或對影像的特定區域套用選擇性強化效果。如果你曾使用過 Instagram 的 cutout 工具,就會發現物件遮罩能直接在裝置上快速生成。這些成果是由透過ExecuTorch(PyTorch的開源裝置端推論執行環境)與Arm SME2(Scalable Matrix Extension 2)運作的精簡分割模型所驅動。
本文將探討這些軟硬體技術升級如何讓影像裁切功能背後的裝置端互動式分割模型 SqueezeSAM在影像分割任務中實現最高可達3.9倍的加速,並闡述這一突破對行動裝置端應用開發者的廣泛影響。SqueezeSAM已部署在Meta旗下應用中。
行動裝置端AI的興起
隨著行動裝置端人工智慧 (AI) 不斷發展,一個核心問題擺在眼前:當更強大的模型在嚴格的行動裝置端功耗與延遲限制下能夠運作得更快時,會出現哪些新的可能性?實際上,許多互動式行動裝置端AI功能和工作負載已在CPU上運作,因為 CPU 始終可用、與應用無縫及整合,且在各類場景中具備高靈活性、低延遲與出色效能。對於這類部署方案,效能優劣往往取決於CPU執行矩陣密集型核心的效率,以及當算力不再是瓶頸後,還存在哪些限制因素。
SME2是Armv9 架構中的一組先進的 CPU 指令,專為在裝置端直接加速針對矩陣運算工作負載而設計。我們量化了在 ExecuTorch 與 XNNPACK 部署方案中,SME2 對端對端推論的加速效果,並透過運算子(operator)級效能分析展示具體哪些方面獲得改善。啟用SME2的全新Arm CPU已整合在Arm Lumex 運算子系統 (CSS)中,用於旗艦智慧手機與次世代PC裝置。
案例研究:利用SME2加速互動式影像分割
我們測試了在以ExecuTorch和XNNPACK為後端運作時,SME2對SqueezeSAM推論延遲的影響。該方案利用Arm KleidiAI最佳化的核心,以發揮SME2的加速能力。
啟用SME2後, INT8和FP16推論均獲得顯著效能提升(圖1)。在採用預設功耗配置的單個CPU核心上,INT8延遲改善1.83倍(從556毫秒降至304毫秒),FP16延遲改善3.9倍(從1163毫秒降至298毫秒)。若無SME2,延遲會過高,無法滿足互動式場景的流暢使用需求;啟用SME2後,單核心端對端推論延遲可達到300毫秒左右,使裝置端部署切實可行,同時也為應用的其他部分留出了效能冗餘量。
上述結果表示,SME2可在CPU上顯著加速量化後的INT8模型。同時,在本案例中,SME2讓FP16延遲接近INT8水準,這一成果意義重大,因為它並非替代INT8,而是擴展了實際可部署的方案範圍。這讓開發者擁有更高的靈活性,可選擇最符合精度與工作流程需求的資料格式,尤其適用於對精度敏感的工作負載,如影像超解析度、影像裁切、低光源去噪與高動態範圍 (HDR) 強化。倘若沒有如此等級的FP16加速,行動裝置端部署通常只能選用INT8以滿足延遲目標,而這意味著需要導入量化工作流程並承擔精度下降的風險。
除了基準測試數據之外,這些速度提升也直接轉化為釋放更多CPU運算資源的冗餘量。這些冗餘量可用於打造更豐富的體驗,例如在保持相機預覽與使用者介面順暢回應的同時,並行執行影像分割與影像增強(例如降噪或HDR);或是將cutout功能從單張影像延伸到即時影片中的主體分割與跨影格追蹤;同時也有助於降低功耗。
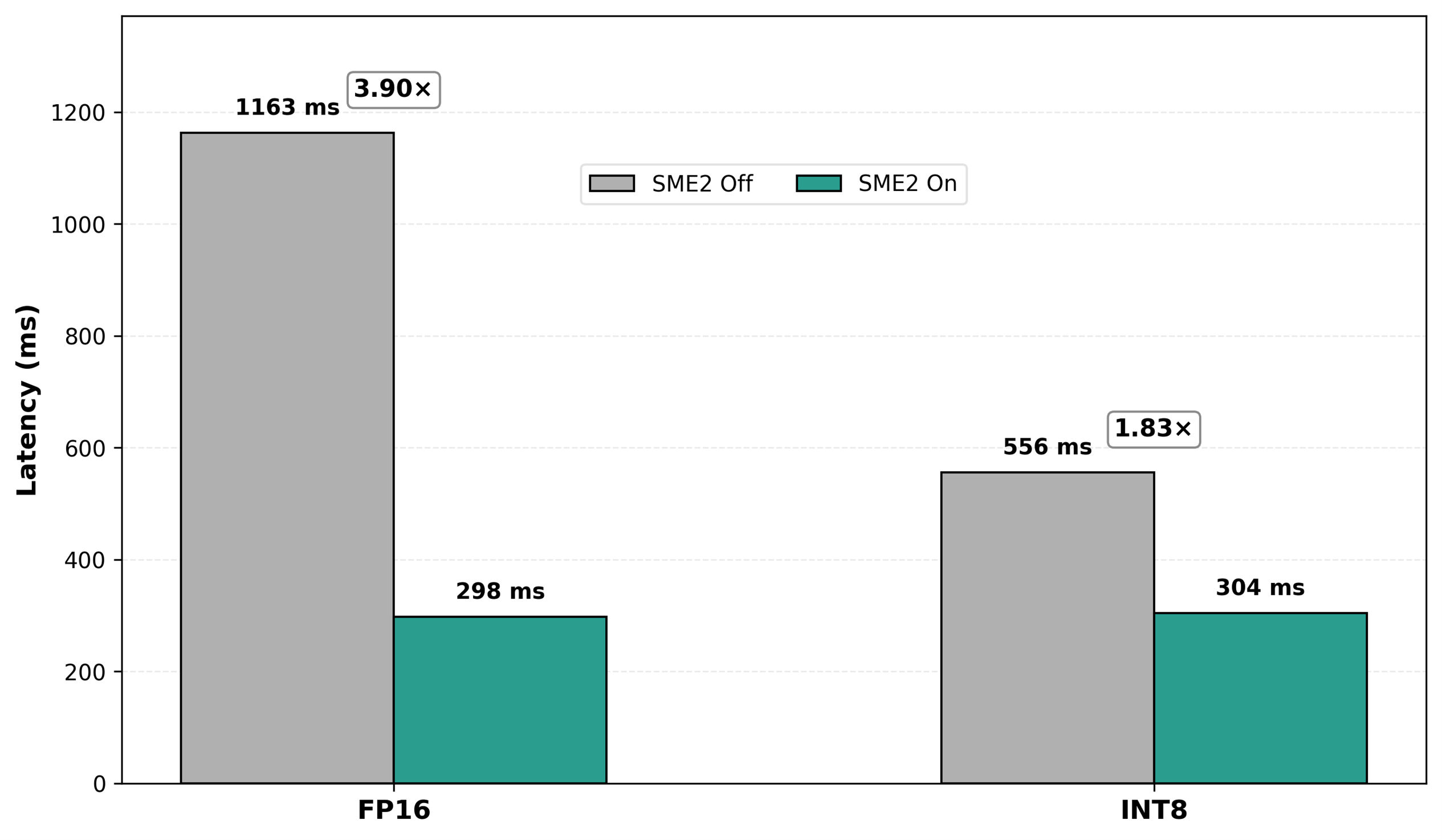
圖 1:普通模式下(預設行動裝置端功耗設置),一個CPU核心在啟用與不用SME2時SqueezeSAM的端對端延遲。INT8從556毫秒改善至304毫秒(提升1.83倍)。FP16從1,163毫秒改善至298毫秒(提升3.90 倍),在本案例中FP16延遲已接近INT8水準。
本文所有結果均為在搭載啟用SME2的Arm CPU之旗艦級Android智慧手機上進行受控測試所得。效能會因模型、硬體及實際裝置的設置而異。
技術堆疊:PyTorch、ExecuTorch、XNNPACK、Arm KleidiAI 和 SME2
框架間的連接關係

上圖總結了本案例研究中使用的CPU執行技術堆疊。模型在PyTorch中定義,由ExecuTorch匯出並運作,CPU運算則委派給做為後端的XNNPACK執行。XNNPACK使用Arm KleidiAI,這是針對 Arm CPU、為加速機器學習工作負載而最佳化的羽量級CPU核心函式庫。這些核心可在受支援的裝置上自動運用SME2加速,同時也能為不支援SME2的系統提供針對其他的CPU特性進行最佳化。
當ExecuTorch在啟用XNNPACK委託的情況下運作模型時,XNNPACK會在運作時根據底層硬體能力選擇合適的核心實現。在啟用SME2的裝置上,這些運算中的矩陣乘法運算可直接受惠於SME2加速,無需對模型結構或應用程式碼進行任何修改。在這類運算得到加速後,推論流水線中的其他環節(如資料移動、佈局轉換、未委託的運算子等)往往會成為新的效能瓶頸。這也是運算子級效能分析對於理解端對端效能如此重要的原因。
案例研究模型
在本次評估中,我們使用了SqueezeSAM模型,該模型採用羽量級、以conv2d為主的UNet 架構,是典型的行動裝置端視覺模型。
模型結構自然可被映射為兩大類工作,這兩類工作對端到端推論時間有著顯著影響:
- 運算密集型運算:卷積層(iGEMM,隱式通用矩陣乘法)和注意力/MLP層(GEMM,通用矩陣乘法)
- 資料移動類運算:轉置、重塑和佈局轉換
平台說明:在許多基於Armv9架構的裝置上,SME2做為CPU核心間的共用執行資源實現,其伸縮特性會隨系統級晶片(SoC)與CPU微架構不同而存在差異。我們在評估中已明確考慮這一點,並在解讀單核與多核結果時討論其產生的影響。
結果:INT8和 FP16(1個CPU核心對比4個CPU核心)
我們在啟用與不使用SME2的條件下,對同一模型的兩種精度(INT8和FP16)進行基準測試。我們特別關注單核執行場景(SME2在此場景下相對增益最大),同時也給出四核心結果,以說明當 SME2做為共用硬體資源時的絕對延遲與擴展表現。所有測試均僅統計模型本身的推論延遲。
模型透過ExecuTorch在Android智慧型手機上運作,在相同軟體與系統環境下分別測試啟用與不使用SME2的情況。除非另有說明,所有結果均為在無溫控降頻情況下的穩態效能。
所有結果均以「普通模式 | 無限制模式(毫秒)」的形式提供。普通模式對應預設的行動裝置電源設置,即系統電源策略啟用狀態,反映典型使用者使用場景。無限制模式對應持續供電、保持喚醒狀態的配置,CPU頻率限制有效解除;單核測試中,無限制模式結果固定在最高效能(Ultra/Prime,本例中為 4.2 GHz)CPU核心上運作。
在兩種模式下,SME2均呈現一致的相對加速趨勢,表明儘管絕對延遲存在差異,但其加速效果受系統功耗策略影響較小。除非另有明確說明,本文後續均以普通模式結果為主,因其更能反映典型手機使用環境下的使用者的感知延遲。無限制模式結果用於展示效能冗餘量與硬體上限,應視為最佳表現,而非日常用戶體驗。
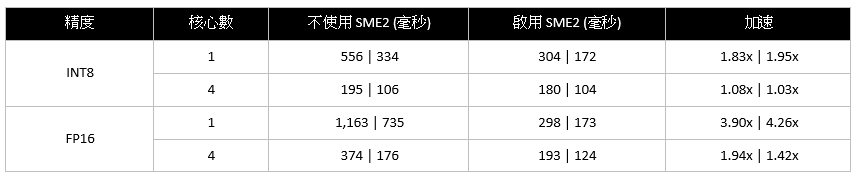
表1:在Android手機上啟用與不使用SME2時,SqueezeSAM的端對端延遲結果,分別在一個CPU核心與四個CPU核心上測試(僅模型延遲)。數值以「普通模式 | 無限制模式(毫秒)」的形式提供。
關於四核心擴展說明:四核心的加速比例較小(例如,普通模式下INT8為1.08倍,而單核心為1.83倍),這與SME2做為共用資源的特性一致,同時也受記憶體頻寬、快取行為等其他系統共用因素影響。伸縮特性會因SoC與CPU實現方式不同而存在差異。在生產部署中,若能滿足延遲目標,優先使用一到兩個核心可獲得更好的能效;當需要更低的絕對延遲且功耗預算允許時,可使用更多核心。
運算子級效能分析的重要性
端對端延遲只能告訴我們效能提升了多少,無法說明原因及後續的最佳化物件。為了理解SME2的效能增益來源及下一階段的效能瓶頸,我們使用運算子級效能分析。
我們透過ExecuTorch開發工具中的效能分析工具ETDump採集每個運算子的耗時資訊,該工具會記錄推論過程中各個運算子的執行時間。這使我們能夠將端對端加速效果歸因到模型的具體部分,如圖2和表2所示。
為了讓分析更具可行性,我們將運算子歸納為少數幾個與常見模型結構精準對應的類別:
- Convolution卷積:Conv2d層(通常基於iGEMM實現)
- GEMM通用矩陣乘法:矩陣乘法和線性層(注意力和MLP投影)
- Elementwise 各向量/矩陣/張量间,對應位置的元素計算 :ReLU、GELU、Add、Mul 及其他逐點運算
- Data Movemen 資料移動:轉置、拷貝、格式轉換、重塑和填充
- Other 其他:未委派的運算子和框架開銷
透過上述分類拆解,我們可以解釋SME2在哪些方面作用最為顯著,以及在矩陣運算被加速後依然存在的效能瓶頸。
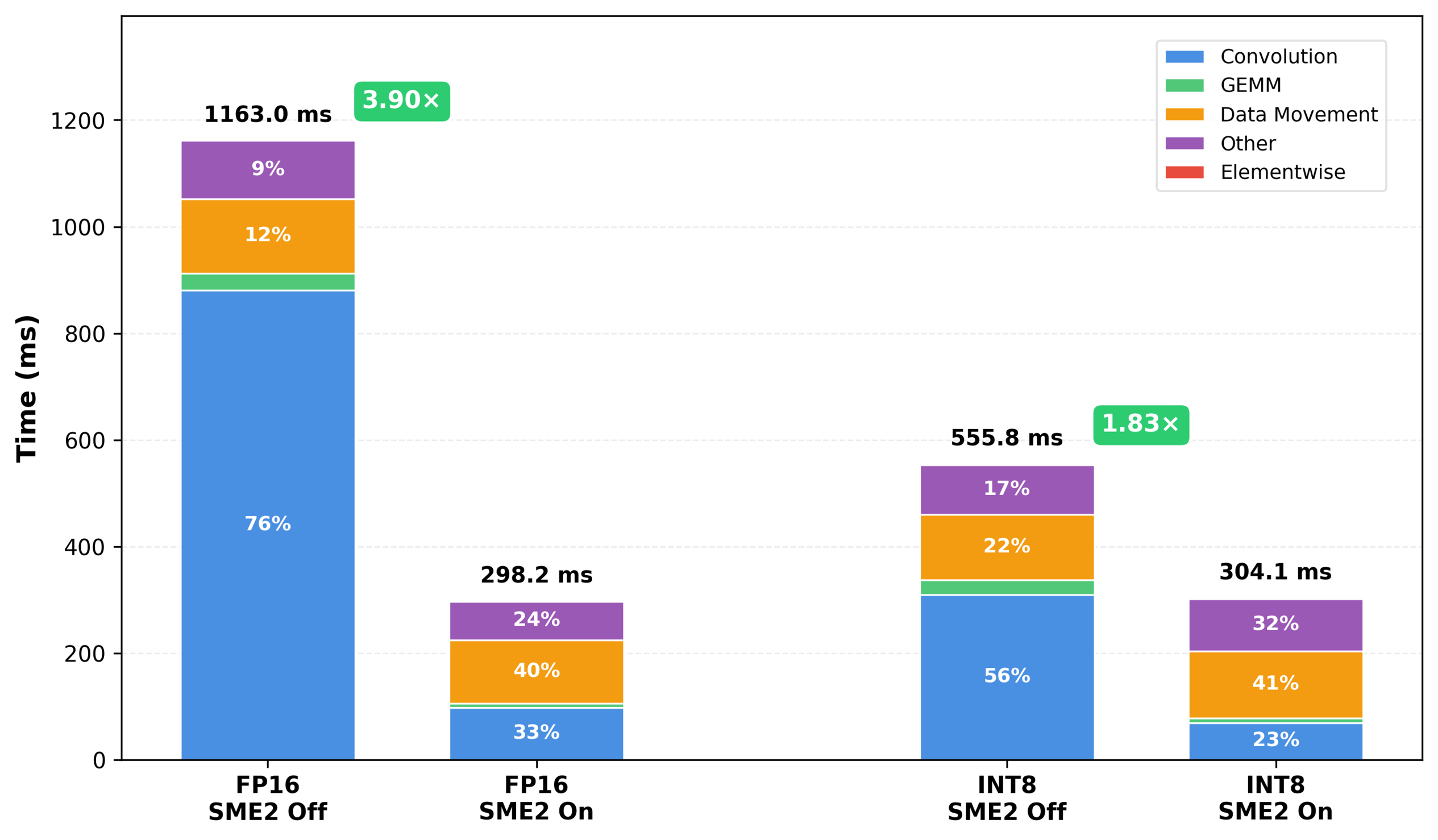
圖2:在Android手機上(一個Arm CPU核心,預設行動裝置功耗設置),啟用與不使用SME2時,FP16與INT8的運算子類別耗時細節(絕對時間)。SME2大幅降低卷積與GEMM耗時,資料移動在執行時間中的佔比顯著提升。
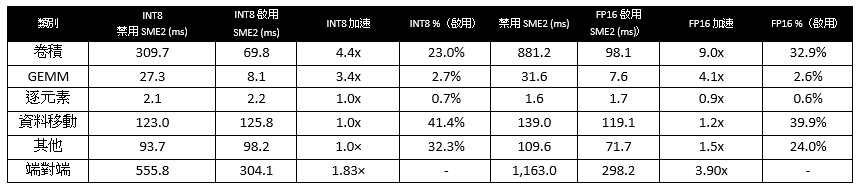
表2:在Android 智慧手機上(一個Arm CPU核心,預設行動裝置功耗設置),不使用與啟用SME2情況下INT8與FP16的運算子級耗時細節對比。非矩陣乘法運算子主要受運作時波動的影響。
從端對端與運算子級結果得出的三大洞察
洞察1:SME2能夠加速矩陣運算,將瓶頸轉移至資料移動
SME2顯著降低INT8與FP16精度下的端到端延遲。在單個Arm CPU核心上,INT8效能改善1.83倍(從556毫秒降至304毫秒),FP16改善3.90 倍(從1,163毫秒降至298毫秒)。即使在四核心場景下,SME2仍可大幅降低FP16延遲(從374毫秒降至193毫秒)。這些最佳化效果使單核執行延遲進入約300毫秒區間,在為應用其他部分保留CPU冗餘量的同時,讓行動裝置端的即時互動成為可能。
運算子級效能分析說明,SME2能夠大幅加速矩陣密集型運算子。用SME2時,卷積與GEMM佔據推論的主要耗時,分別佔INT8執行時間的55.7%、FP16 的75.8%。啟用SME2後,GEMM運算子加速約3–4倍,卷積/iGEMM 加速約4–9倍,這是端到端效能提升的主要驅動因素。
矩陣運算加速後,資料移動與框架開銷的相對佔比上升,後續最佳化的重心也隨之轉移。
洞察2:由轉置驅動的資料移動約佔總運作時的40%
在SME2加速後,資料移動成為主要運作耗時因素之一。在啟用SME2的INT8運作中,資料移動佔總運作時的41.4%(FP16為39.9%)。ETDump追蹤結果顯示,約85% 的資料移動時間來自轉置運算子,僅兩類轉置節點就佔用該類別超過80%的耗時。
這類開銷源於模型不同部分與運作時之間的資料佈局不匹配,而非運算強度問題。實際場景中,當具有不同佈局偏好的運算子按序組合時,會觸發頻繁的NCHW、NHWC格式轉換。在本模型中可以看到:歸一化運算子做為可移植的NCHW運算子執行,且無法與相鄰卷積融合(例如當非線性啟動函數位於Conv2d與BatchNorm之間時),而XNNPACK卷積核心更偏好NHWC佈局。這會在UNet編碼器–解碼器模組中引發重複的佈局轉換:
BatchNorm/GroupNorm (NCHW) → 轉置 (NCHW→NHWC) → 卷積 (NHWC) → 轉置 (NHWC→NCHW) → BatchNorm/GroupNorm (NCHW)
由於這類開銷由模型與運作時的佈局選擇決定,而非運算強度,因此必須透過效能分析才能將其顯露出來,進而將其轉化為可執行的最佳化目標。
重要的是,這一效能分析洞察已被證實具備實際最佳化價值。做為初步措施,Meta ExecuTorch團隊在框架中實現了針對性的影像最佳化,以減少歸一化層周圍不必要的資料佈局轉換。在我們的實驗中,除SME2帶來的加速增益外,還可使INT8延遲額外減少約70毫秒 (23%),FP16延遲額外減少約30毫秒 (10%)。
由上述結果可以確認,高轉置的資料移動是極具價值的最佳化方向。隨著我們持續分析整張運算圖的佈局行為,仍有進一步最佳化的潛力。
洞察3:在本案例研究中,啟用SME2後FP16延遲接近INT8水準
儘管INT8每個張量元素僅佔用一半的記憶體頻寬,但這並不直接帶來成比例的端對端加速。啟用SME2後,本案例中FP16延遲已接近INT8(單個核心上分別為298毫秒與304毫秒)。
運算子耗時明細揭示了背後原因。FP16的卷積加速效果尤為顯著(加速9.0倍,INT8為4.4倍),彌補了INT8在記憶體上的效率優勢。同時,INT8矩陣運算路徑會帶來額外開銷,包括量化、伸縮及更複雜的核心調度邏輯,削弱了INT8的有效頻寬優勢。
最終效果是,SME2拓寬了可選用的精度範圍。INT8依然是有效的方案,而對於不希望承擔量化複雜度或精度損耗的精度敏感型工作負載,FP16也變得更加實用。儘管本案例中FP16效能已接近INT8,但該效果與任務負載強相關,會隨運算子組合、張量形狀與記憶體壓力發生變化。
實際操作範例:重現工作流程
如想自行嘗試上述工作流持,我們提供了基於開源SAM模型的實際操作課程,內容涵蓋模型匯出、使用SME2執行推論、透過ETDump進行運算子級效能分析等。完整的設置說明與程式碼範例可在程式碼儲存庫及Learning Paths中取得。
你將能學到:
- 如何將分割模型匯出至ExecuTorch,並啟用XNNPAC 委派
- 如何在已啟用SME2的Android、iOS和macOS裝置上建構與部署模型
- 如何運作ETDump效能分析,採集各運算子的耗時資訊
- 如何在自有模型中識別並量化資料移動及其他非運算類效能瓶頸
結論:SME2 帶來的實際改變
在本SqueezeSAM案例研究中,SME2為INT8與FP16提供了顯著的裝置端CPU加速效果,從本質上提升了互動式行動裝置端工作負載的可行性。
這對開發者和產品團隊來說意味著:
- 裝置端機器學習在CPU上更具可行性:SME2可實現最高3.9倍的端對端推論加速。在Android默認功耗設置下,真實互動式行動裝置端模型的單核延遲可從1秒以上降至約300毫秒。對於互動式工作負載,這使得基於CPU的裝置端機器學習從勉強可用變為穩定實用,同時為應用其他功能保留效能空間。
- FP16在部分場景中成為更可行的部署選擇:SME2大幅加速FP16運算,並縮小其與INT8之間的延遲差距,讓開發者能更靈活地選擇最符合精度、工作流程與延遲要求的數值精度,尤其適用於對精度敏感的工作負載。
- 節省的算力冗餘量可帶來更豐富的使用體驗:釋放的CPU預算可用於強化裝置端功能,例如在影像分割的同時運作畫質強化(如降噪、HDR),或將影像裁切從單張圖片擴展至支援跨幀目標追蹤的即時視訊。
- 效能分析給出下一階段最佳化目標:當SME2加速了矩陣密集型運算子(卷積/iGEMM、GEMM)後,效能瓶頸通常會轉向資料移動與未委派運算子。基於ETDump的運算子級效能分析可清晰展示這類開銷,並提供可落地的最佳化方向。
根據起點不同,有兩點明確的啟示:
- 若您目前尚未部署裝置端機器學習,那麼基於SME2的CPU加速可以讓行動裝置端CPU成為部署這類「高度運用數學」模型的可行起點,而效能分析能夠為驗證表現和持續反覆運算提供清晰路徑。
- 若你已經部署裝置端模型,SME2可釋放算力冗餘量,用於拓展功能、提升使用者體驗;同時效能分析可指出增益最高的後續最佳化方向(在SqueezeSAM中,由轉置驅動的佈局轉換約佔總執行時間的 40%)。
綜合以上,SME2加速與運算子級效能分析相結合,可形成一套實用工作流程:既能快速獲得立竿見影的效能提升,亦可精準定位裝置端AI後續的最佳化方向。
(責編:Judith Cheng;參考原文:Accelerating on-device ML inference with ExecuTorch and Arm SME2;本文中文版校閱者為Arm首席應用工程師林宜均)
- 【Arm的AI世界】按步驟學習在Arm Ethos-U85上部署PaddlePaddle模型 - 2026/07/08
- 【Arm的AI世界】打造車用裝置端多模態助理 - 2026/06/16
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


