作者:洪銘恩
DeepStream最大優勢是能讓使用者方便處理多個來源,並將處理的結果同步顯示在畫面上,也能將主模型推論後的結果放入一個或多個副模型執行進一步的推論。
在一般使用者執行影像辨識的過程中,往往都是使用OpenCV讀取影像,再經由模型特性轉換適合的格式後,放入已訓練好的模型得到推論結果。以筆者的使用方式為例,若是要針對不同的攝影機畫面進行推論,往往得自行設定不同的輸入源,像是多個視訊串流或是安裝了一個以上的攝影機,以OpenCV讀取不同USB攝影機為例:
cap1 = cv2.VideoCapture(0)
cap2 = cv2.VideoCapture(1)
乍看之下好像沒什麼問題,執行邏輯也不會太難,只要將推論過程設定好,輪流迭代各攝影機讀取的影像即可。
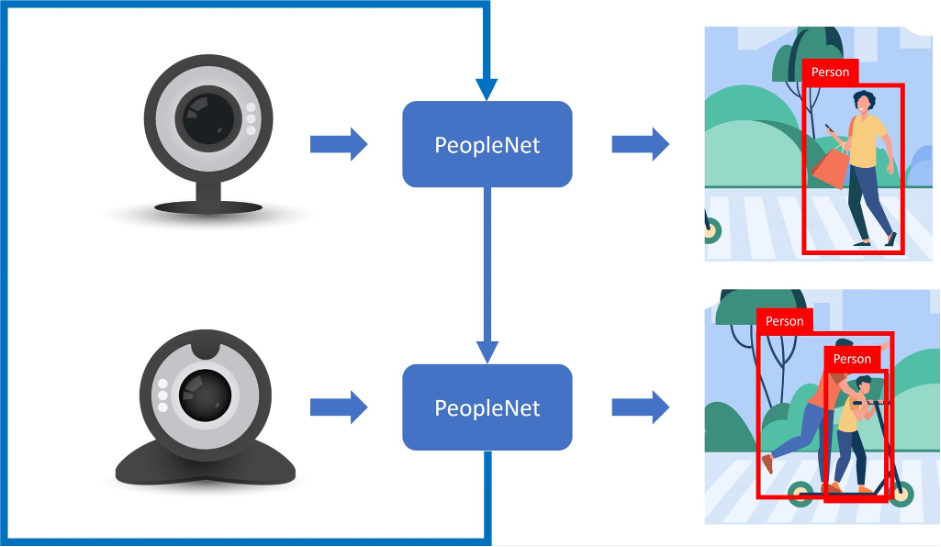
實際執行後就如設定的一樣,畢竟執行了兩次推論(處理兩個攝影機的來源),效能就會隨著推論的次數下降,原先處理單個來源的FPS可以來到30左右,隨著增加讀取的攝影機數量,速度就會直接砍半給你看,原先接近實時的效果就變成類似當機的慘狀。
雖說可以輪流跳著推論,而不是每次推論都要將每個攝影機的影像全部用上,來改善這個情況,但問題還是存在呀!只是從降低速度改為有時候辨識到有時候沒有而已。
DeepStream針對多影像輸入這方面的問題進行了改善與加速,本篇文章將著重在如何設定DeepStream讀取多個影像進行推論的部份,也提供在不同來源下如何設定的問題進行說明。
一、事前準備
首先要決定好推論用的模型,筆者這邊使用NVIDIA線上課程提到的jetson-inference,來訓練一個Object Detection模型,預訓練模型採用的是SSD-MobileNet,針對手上的幾個物件進行資料蒐集並訓練。在DeepStream運行模型時,會轉換成TensorRT的engine檔案進行加速,所以在這邊也將模型轉換為ONNX以便能將模型輸入給TensorRT。
執行平台採用Jetson Nano 4GB,影像輸入的部份將針對影片、USB Camera與RTSP進行說明。
二、設定DeepStream
首先要讓DeepStream能正常讀取ONNX檔案進行推論,設定的部份與步驟可以參考筆者的另一篇文章:在DeepStream上使用自己的Pytorch模型,這篇文章有提及如何在DeepStream使用jetson-inference訓練的Object Detection模型,請確認是否能正常運作。
1. 多USB Camera來源:
將USB Camera接上Jetson Nano後,透過指令查看是否有讀取到裝置,請輸入:
ls /dev/video*
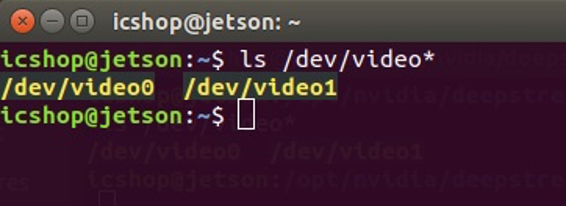
以上圖為例,筆者這邊連接兩支USB Camera,所以能讀取到兩個裝置,編號0為第一支USB Camera,編號1為第二支USB Camera,待會設定DeepStream配置檔案時會需要填入對應的編號,以便連接正確的裝置。
接下來開啟配置檔案設定輸入來源,[source編號]可以讓使用者設定來源數量,首先設定第一個來源[source0],因為使用的是USB Camera所以於來源類型的部份選擇CameraV4L2,接著設定影像大小camera-width=640/camera-height=480。還能設定最大與最小FPS,camera-fps-n是設定最大FPS,camera-fps-d則是設定最小FPS,最後就是USB Camera的編號了,camera-v4l2-dev-node=0表示連接編號0的USB Camera。
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=640
camera-height=480
camera-fps-n=30
camera-fps-d=1
camera-v4l2-dev-node=0
方才只是設定第一支USB Camera,因為我們有兩個來源,所以請再新增一個[source1],用來設定第二個來源。設定上與[source0]相同,您可以直接複製[source0]並更改為[source1],主要不同在於camera-v4l2-dev-node=1的部份,設定來源將連接第二支USB Camera。
[source1]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=640
camera-height=480
camera-fps-n=30
camera-fps-d=1
camera-v4l2-dev-node=1
設定完兩個輸入源後,DeepStream將會依照您的設定,從這兩支USB Camera取得影像並進行推論。接下來是設定顯示畫面的部份,經由設定[tiled-display],能讓兩個推論結果同步顯示在螢幕上,您可以透過參數設定畫面大小與分割樣式。
首先enable=1啟用我們的顯示器,您可透過rows與columns設定畫面輸出欄位數量,筆者希望從兩個USB Camera取得的兩個影像能左右顯示在畫面上,所以設定上rows=1/columns=2,若您想分成上下顯示,則可將參數調整為rows=2/columns=1。width=1280/height=480是設定畫面輸出的大小,請依照自己的需求設定。
[tiled-display]
enable=1
rows=1
columns=2
width=1280
height=480
gpu-id=0
nvbuf-memory-type=0
完成上述設定後即可儲存並執行,設定無誤的話應該能順利看到畫面,就如配置檔案設定的一樣左右顯示,細節的部份請用滑鼠左鍵點擊想要查看的畫面,畫面將會放大並顯示細節,想退回總顯示畫面的話只要點選滑鼠右鍵即可。

2. 多影片來源
有了設定多個USB Camera的經驗後,設定其他來源就難不倒你了,與設定USB Camera差不多,只要設定相對應的來源即可,請先準備要用來作為輸入源的影片,筆者這邊同樣準備兩個不同的影片,作為模型推論的資料輸入來源。
一樣先來設定[source0],影片輸入的部份選擇類型是URI,使DeepStream經由這個路徑找到我們要進行推論的影片,uri=file://01.mp4的意思是讀取名稱為01的mp4影片檔案,請根據您影片存放的位置填入,num-sources=1則是作為一個來源輸入,若是想將一個影片當作多個來源可參考範例程式,這邊就不贅述了。
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
type=2
uri=file://01.mp4
num-sources=1
gpu-id=0
接著設定第二個來源[source1],與[source0]一樣,差別在影片路徑而已,同樣請根據您影片存放的位置填入,其餘參數設定一樣。
[source1]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
type=2
uri=file://02.mp4
num-sources=1
gpu-id=0
顯示畫面設定的部份,因為與上一個USB Camera一樣是兩個來源,所以筆者對於[tiled-display]的設定保持不變。
[tiled-display]
enable=1
rows=1
columns=2
width=1280
height=480
gpu-id=0
nvbuf-memory-type=0
完成上述設定後即可儲存並執行,筆者作為輸入源的兩個影片分別是總物件拍攝與單物件逐一拍攝,顯示畫面參考如下。

3. RTSP來源
若您沒有RTSP來源可以測試,筆者這邊提供一個方法讓您取得RTSP來源,那就是使用您的Android手機充當網路攝影機,Google Play上有一些App可以讓您的手機作為RTSP網路攝影機,可以透過RTSP Server關鍵字找到,筆者使用的是下圖所示的App。
只要將Jetson Nano與手機連上同一個網路來源,啟動App後按下執行,就能在畫面上看到連結路徑,如下圖所示:

筆者這邊透過該方式使用兩台Android手機充當RTSP來源,若您是使用iphone的同學請自行搜尋是否有類似的App。來源[source0]的設定與影片路徑相同,同為URI,路徑填上在App畫面上看到的路徑。請務必確認是否所有裝置都在相同的網路中。
[source0]
Enable=1
#Type - 1=camerav4l2 2=URI 3=multiuri 4=RTSP
Type=2
Uri=rtsp://192.168.3.59:5540/ch0
Num-sources=1
Gpu-id=0
來源[source1]的設定同樣與[source0]相同,路徑填上在另一支手機畫面上看到的路徑,其餘參數設定皆與讀取影片的設定相同。
[source1]
Enable=1
#Type - 1=camerav4l2 2=URI 3=multiuri 4=RTSP
Type=2
Uri=rtsp://192.168.3.75:5540/ch0
Num-sources=1
Gpu-id=0
顯示畫面設定的部份一樣與讀取影片的設定相同,您可參考設定多影片的[tiled-display]設定,完成上述設定後即可儲存並執行,即可從畫面當中查看到兩台手機傳送過來的影像。

三、補充說明與結論
上述示範了三種不同來源經由DeepStream執行模型推論的方法,筆者都只各示範了兩個來源,若是想要增加更多輸入來源只要自行增加[source編號]的部份即可,例如:
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
...
[source1]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
...
[source2]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP
...
當然也可以混用不同的來源,例如[source0]使用USB Camera、[source1]使用影片來源、[source2]採用RTSP…等,記得當來源增加時要調整[tiled-display]。除了能讓使用者更方便執行多輸入源作推論之外,DeepStream還能讓使用者執行不同模型對一個畫面作推論,有興趣的話可以參考官方說明文件。
(責任編輯:謝涵如)

- 運用NVIDIA DeepStream讀取多個影像進行推論 - 2021/10/27
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


