作者:曾成訓(CH.Tseng)
傳統的手勢辨識主要採用影像處理手法,針對手部圖片進行影像分析,著重在於形狀及特徵點的取得,缺點是需要控制嚴格的外在環境因子(如燈光、背景、顏色等),才能避免造成影像分析時的干擾,而近年來得利於 AI 技術,透過深度學習自動萃取特徵並進行影像分類及物件偵測,可讓手勢辨識變得更加精確,也不易受外在環境所干擾。
不過,如果您打算自行訓練一個手勢辨識模型,首先要面對的第一項工作便是圖片的搜集及標記,這是一項相當繁雜且花時間的人力密集工作,因此如果有個方便好用的工具能自動將影片或攝影機中的手勢,自動裁切並依手勢類型分類好,甚至還能將手勢自動標記好,是不是非常方便呢?
這是可能的,只要先訓練好一個偵測手部的模型,便可以利用它來製作一個手勢自動分類及標記的工具,產生兩種類型的 dataset:
- Classified image dataset
- VOC labeled dataset
本文目的是希望透過該工具,節省圖片資料搜集、圖片分類、圖片標記這三項工作的時間,而我們唯一的工作僅是準備影片、在鏡頭前比出需要的各種手勢,讓該工具直接替我們產生出可直接用來訓練影像分類或物件偵測使用的 dataset。
製作手部偵測模型
在設計這套工具前,我們需要訓練一個手部偵測模型,這個模型的目的是「無論任何姿勢,只要是人的手掌都要能偵測到」,至於如何訓練該模型,您可使用任何常用的開源物件偵測 framework,下方我們分別以 YOLOV3-Tiny 以及 SSD-Mobilenet 2 作為訓練示範,dataset 則是使用兩種開源 hand dataset 以及一個自製的 hand dataset 來訓練。
- 訓練的 dataset
下方介紹兩個開源的 dataset 以及一個自己製作的 dataset:
A)EgoHands:A Dataset for Hands in Complex Egocentric Interactions,該 dataset 來源為 48 個影片(二個人在進行互動遊戲,以第一人稱視角拍攝);圖片尺寸為 720×1280 px,每個影片匯出 100 frames並已 labeled,總計 4800 張;Label 的格式為 matlab 的 mat 檔,poly 多邊形(每個手部約 200~300 points)。

(圖片來源:Indiana University)
B)VGG hand dataset:VGG(Visual Geometry Group)為牛津大學工程科學系的社群。內容分為train/test/validation 三個 dataset,圖片來源為其它開源影像資料庫(如 PASCAL VOC)及電影片段;
Label 為依物體長寬而變化傾斜的矩形,不是常用的左右垂直上下水平的 label,格式為使用 Matlab 的 mat 檔;圖片尺寸不定,長寬一般介於 300~600 px 之間。

(圖片來源:University of Oxford)
C)自拍的 hand dataset
使用 webcam 拍攝,尺寸為 640×480 px,數量 1723 張;原先是作為數字 0~5 的手勢 dataset,使用 VOC 格式的 label;拍攝地點為 office。
- Hand dataset 格式轉換
EgoHands 和 VGG hand dataset 的標記格式皆是 Matlab 的 mat,我習慣先將它們轉為 PASCAL VOC 格式,以方便後續 YOLO 或是 SSD models 的訓練。
A)EgoHands dataset
1. 下載 EgoHands dataset:進入 http://vision.soic.indiana.edu/projects/egohands/ 後,點選下圖中紅框的 link,不需申請即可直接下載。

(圖片來源:曾成訓提供)
2. 解壓後,第一層的 metadata.mat 即為存放標記資訊的地方,圖片則放置於 _LABELLED_SAMPLES folder。
(圖片來源:曾成訓提供)
3. 轉為 VOC 格式檔。
4. 轉檔結果:會於指定的 palm_egohands/ 目錄下,產生 labels 及 images 兩個資料夾,接著你可用 labelImg 開啟,檢驗格式轉換是否正確。
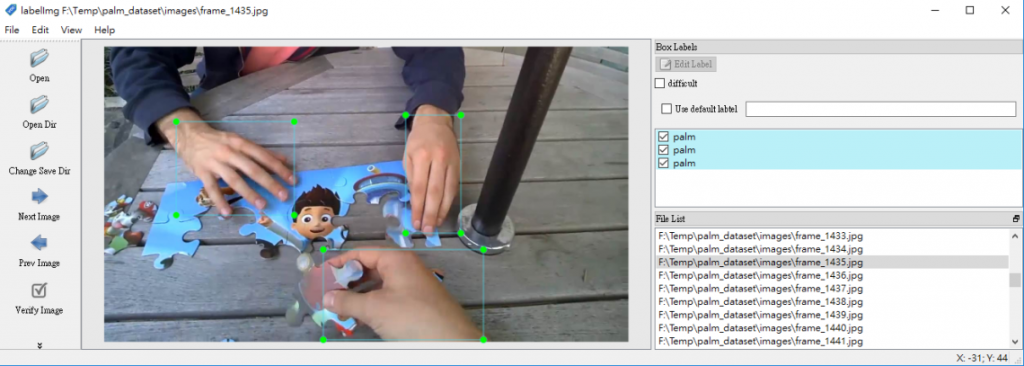
轉換結果正確(圖片來源:曾成訓提供)
B)VGG hand dataset
1. 下載:進入 http://www.robots.ox.ac.uk/~vgg/data/hands/,點選下方的 link,不需申請即可直接下載。

(圖片來源:曾成訓提供)
2. 下載解壓後,內有 training、test、validation 等三個資料夾,每個資料夾下分為 images 及 annotations 兩個目錄,每個圖檔搭配一個與圖檔同名的 matlab 標記檔。
3. 新增 images 及 annotations 目錄,接著將各目錄下的 images 圖檔及 annotations 標記檔集中放置於新建的 images 及 annotations 資料夾中。
4. 轉為 VOC 格式檔。
5. 轉檔結果:會於指定的 palm_oxford_hands/train/ 目錄下,產生 labels 及 images 兩個資料夾,接著你可用 labelImg 開啟,檢驗格式轉換是否正確。
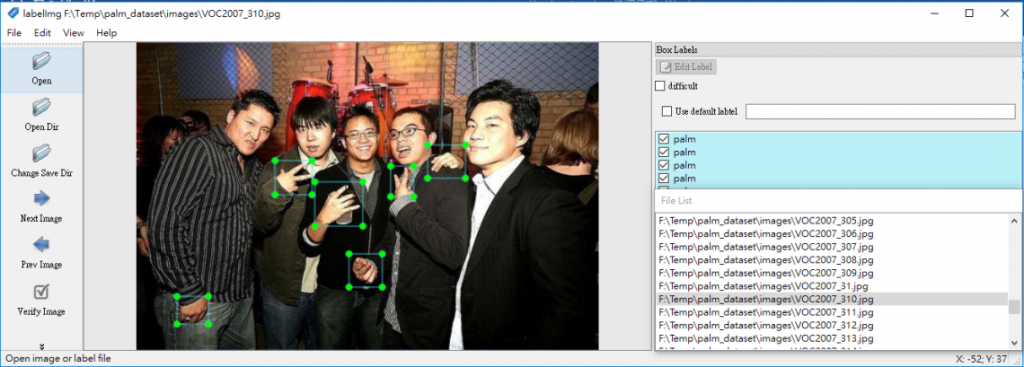
轉換結果正確(圖片來源:曾成訓提供)
Palm detection 訓練
下面我們分別使用 YOLOV3-Tiny 以及 SSD-Mobilenet 來訓練此手部偵測模型:
- YOLOV3-Tiny 訓練
可利用我之前所撰寫的 makeYOLOV3 程式,只需要在安裝好 Darknet 環境的 PC 上,輸入 VOC 格式 dataset 的路徑,便可自動轉換為 YOLO dataset,接著產生 YOLO 的 data、cfg、names 等設定檔案,執行結束後會顯示您所要執行的訓練 command,只需要 copy/paste 執行該行指令便可開始訓練。
另外,訓練之前,建議先執行先驗框程式,取得六組先驗框(YOLOV3 為九組)放在 yolov3-tiny.cfg 的 anchors 參數中。訓練過程如下:
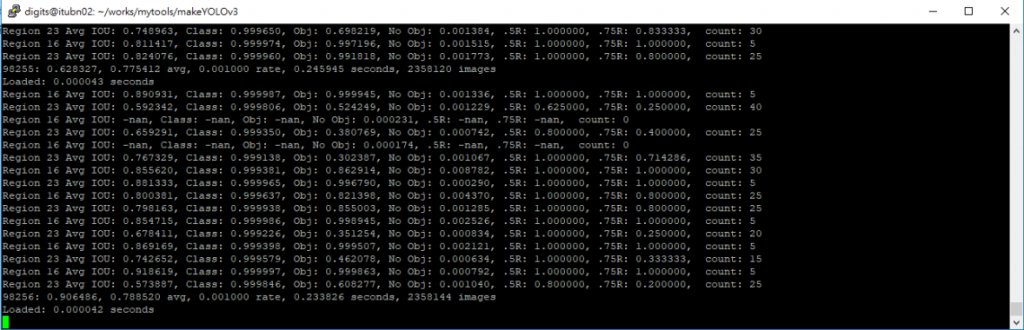
(圖片來源:曾成訓提供)
- SSD-Mobilenet V2 訓練
1. 轉換為 Tensorflow TF-Record dataset。
2. Download pre-trained model 及 config file。
3. 修改 ssd_mobilenet_v2_coco.config 灰色字的部份。
num_classes:1
batch_size:24
fine_tune_checkpoint: “ssd_mobilenet_v2_coco/model.ckpt"
train_input_reader: {
tf_record_input_reader {
input_path: “ssd_dataset/train.record"
}
label_map_path: “ssd_dataset/object-detection.pbtxt"
}
eval_input_reader: {
tf_record_input_reader {
input_path: “ssd_dataset/test.record"
}
label_map_path: “ssd_dataset/object-detection.pbtxt"
shuffle: false
num_readers: 1}
4. 開始訓練。
python train.py –logtostderr –train_dir=/home/chtseng/works/train_palm_model/training/ –pipeline_config_path=/home/chtseng/works/train_palm_model/palm_ssd_mobilenet_v2.config
在 Jetson Nano 上測試手部偵測模型的效果
將圖片 size 縮小至 VGA 尺寸後,Jetson Nano 開發板上透過 GPU 加速,YOLOV3-Tiny 與 SSD-MobileNetV2 的 FPS 皆可到七以上。
- YOLOV3-Tiny
- SSD-MobileNetV2
這個手部偵測模型可協助我們取得影像中的手部區域,接著我們便可設計程式針對該區域進行標記或分類,以便產生手部的 classification dataset 以及 VOC labeled dataset。舉例來說,我們透過鍵盤輸入手勢的名稱,接著在鏡頭前比出各種需要的手勢,該工具便可自動將手部區域 crop,另外儲存為依類別分類的手勢圖片庫,或者自動 label 成 VOC dataset。
製作手勢自動分類及標記工具
在上文中,我們已經利用數個開源的手勢 dataset 訓練好了一個可偵測手部的 YOLOV3-Tiny 模型,其效果如下:
接下來將介紹如何利用此 model 來設計一個工具,協助我們產生 1)已 label 好的手勢 VOC dataset、2)依手勢類別分類好的 classified dataset。
參數說明
程式請參考附錄,所使用的參數如下:
參數說明
#想要要偵測的物件名稱。
#本例的 model 只有一個物件,也是我們所打算偵測的
objects = (“palm”)
#每隔多少 frame 才偵測一次?以避免相似的圖片太多。
frame_interval = 3
#物件偵測分數需高於多少?此值設高則 precision 高,但 recall 及 accuracy 低,反之亦然。
#如果您希望自動偵測出的結果一定都要對的,那就把它設高。
#如果希望不要有物件未被偵測到,那麼就把它設低。
score = 0.9
#所有自動 label 及自動 classify 完成的 dataset,會放在此路徑下。
datasetPath = “hand_gestures/”
# classified dataset 的目錄名稱
#本程式會產生兩種 classified dataset,即 crop 和 original 兩種。
classify_path = “classify/”
#自動 label 好的 VOC dataset,圖片及標記檔的目錄。
imgPath = “images/” #voc images path
labelPath = “labels/” #voc labels path
#dataset的圖片格式
imgType = “jpg” # jpg, png
#輸入來源,可為video影片檔,或 web camera。
inputType = “webcam” # webcam, video
#輸入來源若為 video,指定影片檔的 path
media = “/home/chtseng/works/alpr/videos/4K/IMG_2241.MOV”
#是否將物件偵測過程錄製成影片?可掌握影片中那些物件被偵測並轉為 dataset 使用
write_video = True
#影片的路徑名稱
video_out = “labeled.avi”
#輸出的 image 是否要先旋轉?
output_rotate = False
#指定旋轉角度
rotate = 0
#設定手掌模型的參數,程式將用此模型來偵測及製作 auto labeling。
yolo = opencvYOLO(modeltype=”yolov3-tiny”, \
objnames=”models/1_palm_hand_gesture/obj.names”, \
weights=”models/1_palm_hand_gesture/yolov3-tiny_500000.weights”,\
cfg=”models/1_palm_hand_gesture/yolov3-tiny.cfg”, score=score)
使用說明
使用上相當簡單,只用到兩個快捷鍵:
- 按下「l」錄(小寫的 L),可切換 class 名稱,表示接下來的影像畫面,若有偵測到手掌,其 class皆為指定的名稱。
- 按下「q」錄,將結束此 auto labeling 程式。
執行:python3 auto_labeling_hand_gestures.py
操作示範
下面將示範如何透過本 auto labeling 程式製作一個手勢 dataset:
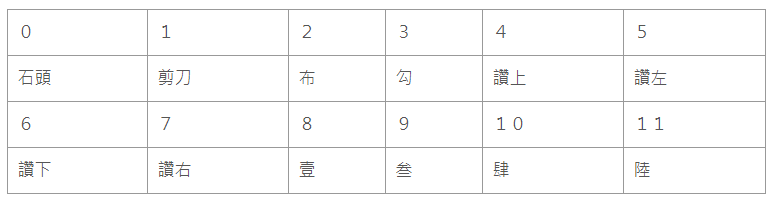
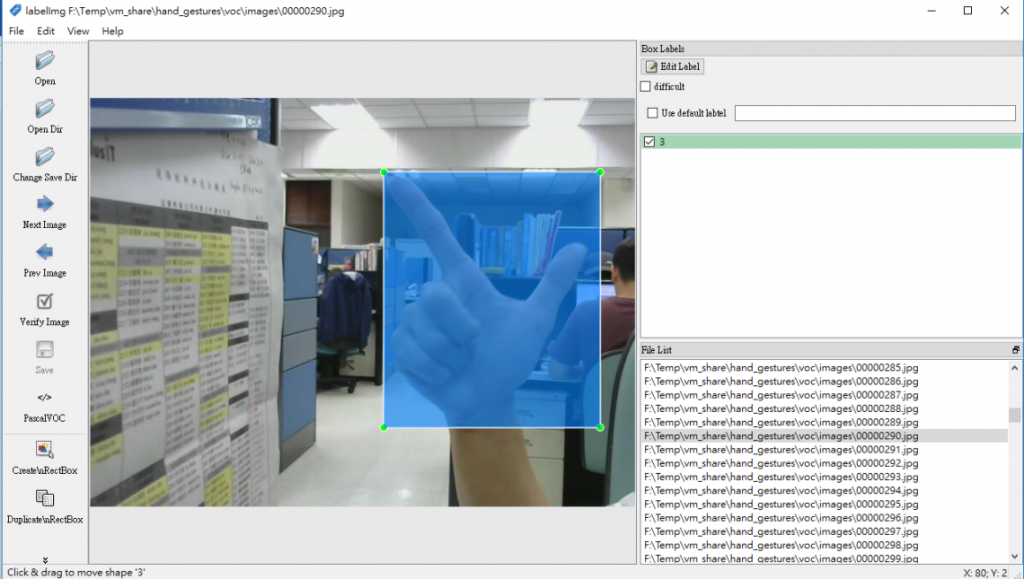
該 dataset 的 classes 及其對應名稱(圖片來源:曾成訓提供)
1. 執行 auto_labeling_hand_gestures.py。
2. 按「l」鍵,輸入「0」,接著在鏡頭前方比出石頭的手勢。
視 Frame rate 速度、設定的 frame interval 以及是否有偵測到手掌而定,每分鐘所搜集到的 image 數量會有所差異;以我自己在 Intel i5-3470 CPU 透過 Virtual Box 執行為例,每分鐘可搜集到 80 張左右的圖片。
3. 依次按「l」鍵,分別輸入各 class 的代碼(0~11),分別比出相對應的手勢。
4. 可回頭輸入不同 class 的手勢,本程式會自動將圖片補在對應的 class 資料夾中。
5. 錄製結束後,按「q」鍵結束。
我將整個 Auto labeling 的操作過程錄成影片如下,總共 12 種手勢,在六分鐘內便可錄製完成。
自動產生的 Dataset
操作完成後,會在指定目錄下產生出下列三種 dataset:
1. VOC 標記格式的 dataset,總共 1370 張。
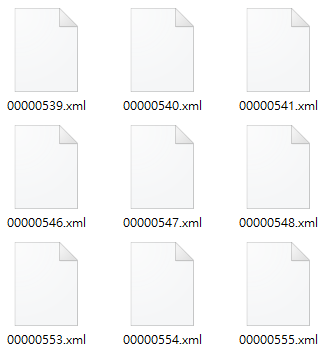
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
(圖片來源:曾成訓提供)
2. 分類好的手勢圖片,共有 12 個資料夾,每個資料夾約 100~200 張圖片。
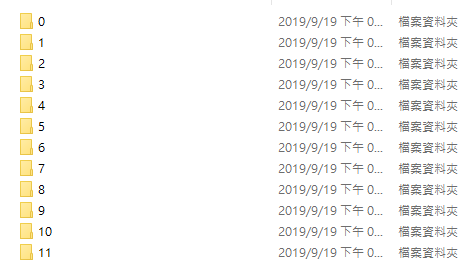
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
3. 分類好的手勢圖片原圖,共有 12 個資料夾,每個資料夾約 100~200 張圖片。
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
小結
本次所示範自動產生的 dataset,其圖片數目還不夠,我們尚需不同的人物、場景及環境,來產生更多的圖片才行。Auto labeling 並非萬能,後續還是需要人工的 review、增修、標記框及篩選錯誤,若我們用於自動標記的模型訓練得相當優異,那麼後續的 review 時間肯定可以減少許多。
(本文經作者同意轉載自 CH.TSENG 部落格、原文連結;責任編輯:賴佩萱)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2021/06/06
請問 “程式請參考附錄”, 沒有看到附錄,方便傳送嗎? 謝謝
2021/06/07
本文為轉載文章,作者不太會來回覆,可以到他的部落格試試~
2020/06/09
你好,最近在學習yolo,看到了這篇文章想要學習,但是將mat檔案轉為voc格式這邊我一直想不到怎麼做,請問可以再說明的詳細一點嗎?
2021/06/06
請問auto_labeling_hand_gestures.py可以分享或傳送嗎?