作者:歐敏銓
「我們正處於機器人發展的『牛頓時刻』。過去,機器人只是被編程的自動機;現在,它們正學著像人類一樣思考、觀察,並在腦海中模擬整個世界的運行。」
想像一下,你回到家對著家裡的機器人說:「中午同事聚餐,吃太多、口味也太重了,晚上想吃清淡些。」機器人用攝像頭掃視了一遍廚房食材,並連結冷箱系統,挑出雞胸肉做舒肥料理、用氣炸鍋烤了一盤大蒜南瓜,再燙了一顆青花菜,一桌健康餐盤上菜了!

source: figure.ai
這聽起來像是科幻電影中的情節,但在 2026 年的今天,即將成為現實!因為,要實現這一幕機器人須跨越的三座技術門檻,已可望跨越:透過VLA聽懂你的話、透過世界模型(World Model)理解物理規律,並透過Sim2Real技術在「電腦」中磨練出完成現實任務的各種「功夫」。
跨越第一座門檻:透過VLA「聽懂人話」
過去的機器人很「死板」。如果你想讓它拿杯子,工程師得寫幾千行程式碼告訴它座標、角度與力道。一旦杯子換個顏色或形狀,機器人就錯亂了。
VLA(Vision-Language-Action,視覺-語言-動作模型) 的出現,徹底打破了僵局。
什麼是 VLA?
VLA 就像是把 GPT-4 的聰明才智,接上了攝像頭(視覺)與機械臂(動作)。它不再是被動接收座標,而是具備了生活「常識」或工作「知識」。
-
視覺(Vision): 讓它看懂這是一個蘋果,還是那個長得像蘋果的壓力球。
-
語言(Language): 讓它理解「清淡」、「危險」或「幫我拿那個亮亮的東西」這種模糊的指令。
-
動作(Action): 直接輸出控制指令(如:機械臂的座標、關節角度),讓手臂精準抓取目標。
當 Google 的 RT-2 或其他VLA模型問世後,我們驚覺機器人進入了新的世代:開始具備了推理能力。你跟它說「把買回來的蔬菜水果放好」,即便它從未見過其中的栗子南瓜,它也能憑藉在網路上海量數據學到的知識,完成這項任務。VLA 就是那個讓機器人「聽得懂話、看得懂路」的通用型大腦。
》延伸閱讀:本刊VLA技術系列文章
跨越第二座門檻:透過World Model掌握預測物理規律的能力
如果說 VLA 是大腦,那麼 World Model(世界模型) 就是機器人的「小腦」與「直覺」。
你有沒有想過,為什麼你走路時不需要思考重力參數?因為你腦袋裡有一個「物理引擎」。當你看到一個杯子放在桌子邊緣,你本能地知道它可能會掉下去。這就是世界模型:對物理規律的預測能力。
機器人的「腦內演練」
早期的機器人必須在現實中不斷摔倒、撞牆才能學習。但這太慢了,而且機械手臂很貴,禁不起再三的損耗。
World Model 讓機器人具備了「物理規律的想像力」。它會在後台不斷進行模擬:
1.觀察: 現在桌上有一碗湯。
2.想像: 如果我用 50% 的力道推它,它會滑行;如果我用 100% 的力道,它會翻倒。
3.決策: 為了不讓湯灑出來,我應該輕輕端起。
這種「腦袋裡先過一遍」的能力,讓機器人不必真的去闖禍,就能學會避開危險。世界模型是機器人邁向「通用人工智慧」最關鍵的一環,因為它賦予了 AI 對於時間、空間與因果關係的深一層理解。
》延伸閱讀:讓機器也懂「趨吉避凶」:打造AI內在的世界模型 (World Model)
跨越第三座門檻:透過Sim2Real在虛擬中學會現實技能
現在,我們有了一個聰明的大腦(VLA)和一個懂物理規律的模型(World Model),但還需解決一個問題:「將演習與實戰的差距降到最低」。
現在常見的狀況是,機器人在「理想」的環境中訓練了幾萬小時,結果一送到工廠,因為現場地面多了些雜亂的線材,或是地毯有些濕滑,它就當場「當機」或「失控」——這就是機器人圈著名的 Reality Gap。
跨越虛實鴻溝的橋樑:Sim2Real
Sim2Real(Simulation to Real) 技術就是那座橋樑。工程師們在模擬器中用盡各種招式來訓練它,例如:
-
領域隨機化(Domain Randomization): 故意把桌子換成一萬種顏色、讓光源隨意變幻,甚至模擬各種坡度的地面。如果機器人能在這種「瘋狂環境」下成功,那現實世界對它來說就是小菜一碟。
-
迭代學習: 機器人在現實中碰壁後的數據,會被傳回模擬器進行針對性補強。
Sim2Real 是具身智能真正落地的臨門一腳。沒有它,再聰明的算法也只能活在電路板裡。
》延伸閱讀:想了解機器人當紅VLA模型,你不能不懂Sim2Real!
現代機器人的進化路徑
這三個名詞並非各玩各的,它們正在進行一場深度的「三位一體」整合,各有所本:
1.VLA 負責「下令」: 它處理人類的意圖,決定「要做什麼」。
2.World Model 負責「逼真」: 它在虛擬腦海中確保「要做什麼」在物理上的可行性。
3.Sim2Real 負責「落地」: 它確保在「腦海」中學會的精細操作,機器人能分毫不差地做出這些動作。
兩兩來看又互不可缺,共同構成了一個「感知—思考—執行」的閉環:
1.World Model 是 Sim2Real 的「強化版模擬器」
傳統的 Sim2Real 依賴人工編寫的模擬器(如 Mujoco, Isaac Gym)。而 World Model 則是從數據中「學習」出一個模擬器。
-
關聯: 如果 World Model 訓練得夠好,我們可以直接在 World Model 生成的「想像空間」中進行訓練,這大大降低了 Sim2Real 的難度,因為 World Model 比傳統模擬器更貼近真實數據分佈。
2.World Model 賦予 VLA 預測與規劃能力
目前的 VLA 很多是反應式的(Reactive),即看到什麼就做什麼。
-
關聯: 引入 World Model 後,VLA 在執行動作前,可以先透過 World Model 預測動作後的後果(例如:我推這個杯子會不會倒?)。這讓 VLA 從單純的「語意理解」進化到具備「物理直覺」。
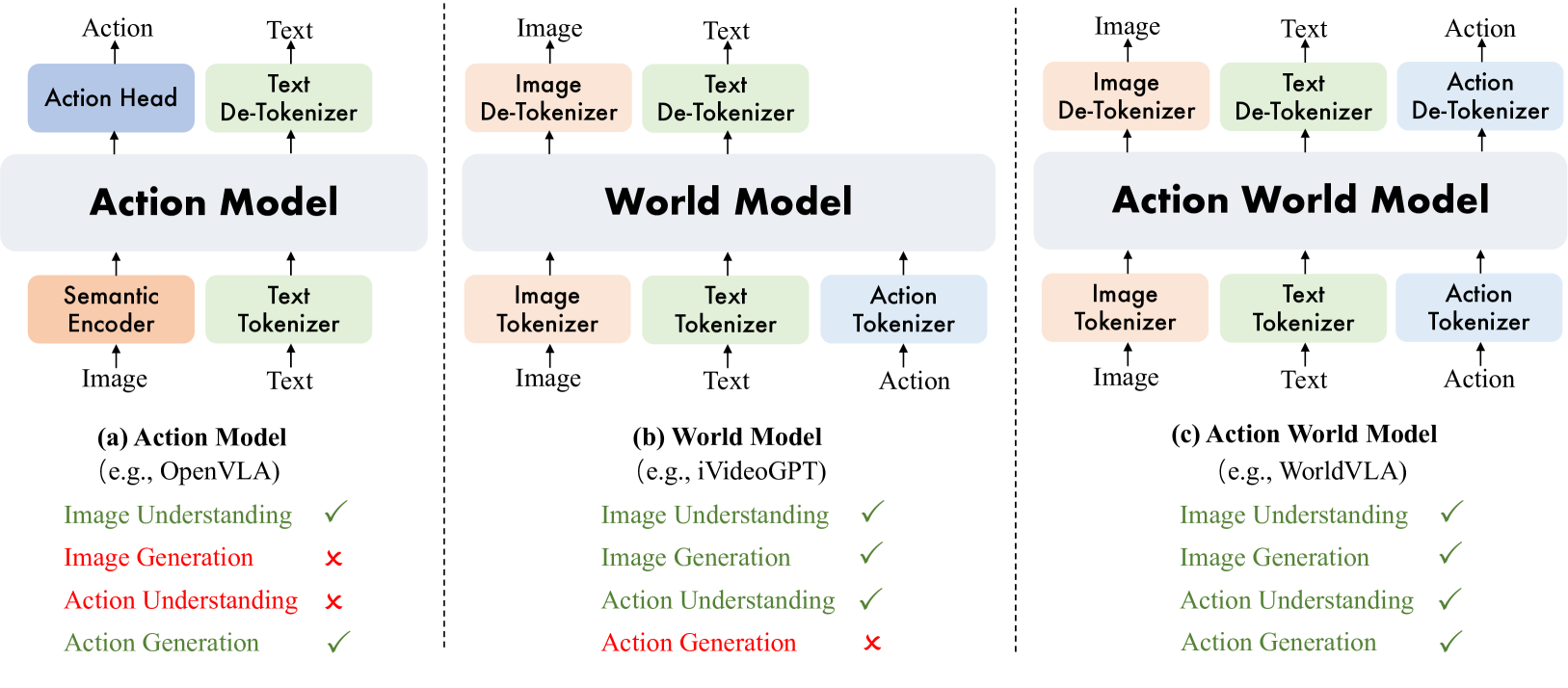
結合World Model和VLA的WorldVLA模型(source)
》延伸閱讀:WorldVLA:視覺、語言與動作的融合之路
3.Sim2Real 是驗證 VLA 與 World Model 的最終戰場
無論 VLA 多麼聰明,或者 World Model 想像得多準確,最終都必須通過 Sim2Real 的考驗。
-
關聯: 研究人員通常在數據量巨大的仿真環境中,利用 VLA 生成大量的操作數據,並透過 World Model 加速訓練,最後再透過 Sim2Real 技術將這套「大腦」部署到實體機器人上。
結語
曾幾何時,我們認為機器人會先取代藍領工作,後來發現 AI 先學會了畫畫與寫詩。如今,隨著 VLA、World Model 與 Sim2Real 的出現,AI 又重新聚焦到了物理世界。
或許不久後的某個清晨,你的機器人管家會一邊幫你準備早餐,一邊根據世界模型的預測提醒你:「今天濕度高,你上班路上的地面怕有點滑,穿這雙防滑鞋比較好。」那一天,我們與機器人的界線將變得很模糊了。
》延伸閱讀:

- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
- 【產業剖析】人形機器人火熱背後的現實難題 - 2026/06/15
- 【COMPUTEX 2026】以「具身智慧界Android」為定位的韓國Circulus - 2026/06/05
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


