作者:武卓
人類透過視覺和語言感知世界。人工智慧(AI)的一個長期目標是構建智慧體,透過視覺和語言輸入來理解世界,並通過自然語言與人類交流。比如,在《如何以OpenVINO在Intel GPU上執行Stable Diffusion》中,我們介紹了利用OpenVINO執行Stable Diffusion模型,快速實現文生圖應用。讓人人可以成為繪畫大師,利用AI隨心作畫。
隨著電腦視覺和自然語言處理領域的快速發展,視覺與語言的融合越來越受到研究人員的重視。在這個背景下,BLIP (Bootstrapping Language-Image Pre-training)作為一種創新的預訓練模型,引起了廣泛關注。該模型在大規模的影像文字資料集上預訓練深度神經網路模型,以提高下游視覺語言任務的性能,如影像文字檢索、影像描述(Image Captioning)和視覺問答(visual question answering)。透過聯合訓練影像和文字資料,為視覺與語言的融合提供了強大的基礎。

圖1:BLIP推論結果範例。
BLIP 的預訓練過程涉及兩個關鍵元件:影像編碼器和文字編碼器。影像編碼器負責將輸入的影像轉換為低維向量表示,而文字編碼器則將輸入的文字轉換為另一個低維向量表示。為了實現統一的視覺-語言預訓練,BLIP 採用了一種跨模態約束策略,即在預訓練階段,影像編碼器和文字編碼器被設計成相互約束的。這樣的約束機制,強制模型學習將視覺資訊和語言資訊進行對齊,從而使得模型在後續任務中能夠更妥善地處理視覺與語言之間的聯合資訊。
除了視覺-語言理解任務,BLIP 還在視覺-語言生成任務中表現出色。在這個任務中,模型需要根據輸入的影像和文字生成相關的描述或回答問題。BLIP 透過聯合訓練和導入了影像-文字生成任務,使得模型具備了更強大的影像描述和問題回答能力。這使得 BLIP 在影像描述生成和視覺問答等任務上取得了優異的成績。
接下來,我們一起來看看如何在研揚科技(AAEON)的新產品UP Squared Pro 7000 Edg上,運作利用OpenVINO來最佳化BLIP的推論加速有哪些重點步驟吧!

作為研揚UP Squared Pro系列的第三代產品,Upsquared Pro 7000 系列 (up-shop.org) 透過高性能運算能力、升級的電路板設計和擴展的顯示介面,提供更大的開發潛力。作為該系列中首款採用Intel® Core™/Atom®/N系列處理器(原 Alder Lake-N)的產品,UP Squared Pro 7000是首款配備板載LPDDR5記憶體的產品,提高了I/O的執行速度。此外,UP Squared Pro 7000 在影像處理和顯示功能方面都有顯著提升,支援MIPI CSI攝影機,並搭配Intel UHD顯卡,可同時進行三台4K顯示器。
1.4倍以上CPU性能提升
UP Squared Pro 7000採用Intel Core/Atom/N-系列處理器,CPU性能是上一代的1.4倍。 UP Squared Pro 7000擁有多達8個Gracemont核心,支援OpenVINO Toolkit,以及第12代Intel處理器的UHD顯卡,擁有強大的運算能力、最佳化的推論引擎和影像處理功能,提供絕佳的智慧解決方案。
同步支援3台4K顯示器
UP Squared Pro 7000配備HDMI 2.0b、DP 1.2連接埠和透過USB Type-C的DP 1.4a,擁有出色的顯示介面。UP Squared Pro 7000整合了GPU和多重輸出,可以同步支援三個4K顯示器,非常適合用於數位看板等視覺導向型的相關應用。
雙倍的高速系統記憶體
作為UP Squared Pro系列中第一款配備板載LPDDR5系統記憶體的板卡,UP Squared Pro 7000搭載了16GB的系統記憶體,是上一代的兩倍。此外,快達4800MHz的記憶體速度讓使用者的頻寬和資料傳輸速度加倍,同時也更加省電。
全面的I/O升級
除了維持UP Squared Pro系列4″ x 4″的小巧外形之外,UP Squared Pro 7000 在電路板設計上更為精實。UP Squared Pro 7000配備了兩個2.5GbE、三個 USB 3.2和一個FPC埠,可外接更多像是MIPI CSI 攝影機的週邊設備。將這些特色與板載 LPDDR5 及性能強大的CPU相結合,非常適合用於智慧工廠機器人方面的視覺解決方案。
重點步驟
注意:以下步驟中的所有程式碼來自OpenVINO Notebooks開源倉庫中的233-blip-visual-language-processing notebook 程式碼範例,您可以點擊以下連結直達原始程式碼:https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/233-blip-visual-language-processing
第一步: 安裝相應工具套件、載入模型並轉換為OpenVINO IR格式
本次程式碼範例需要首先安裝BLIP相應工具套件。
然後下載及載入相應的PyTorch模型。在本範例中,您可以使用從Hugging Face下載的blip-vqa-base基本模型,同樣的操作也適用於BLIP系列中的其他模型。儘管該模型類別(model class)是為執行問答而設計的,但其元件也可以用於影像描述。要開始使用該模型,需要使用from_pretrained方法產生實體BlipForQuestionAnswering類別。BlipProcessor是一個助手類別(helper class),用於準備文字和視覺形態的輸入資料以及生成結果的後處理。
import time
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
sys.path.append("../utils")
from notebook_utils import download_file
# Get model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
接下來,我們看看如何將原始模型轉換為OpenVINO IR格式的模型,並利用OpenVINO進行相對應的最佳化以及部署推論加速。
第二步: 將模型轉換為OpenVINO IR格式
根據我們前面的介紹,BLIP模型包含視覺模型、文字編碼和文字解碼三個模型,因此我們需要分別將這三個模型轉換為OpenVINO IR格式。視覺模型的轉換操作比較常規,具體程式碼可以參考我們的notebook,這裡重點介紹一下文字編碼和文字解碼模型的轉換部分。
- 文字編碼器轉換:視覺問答任務使用文字編碼器來構建問題的嵌入表示。它採用經過分詞(tokenized)後的問題的input_ids,並輸出從視覺模型獲得的影像嵌入和它們的注意力遮罩(attention masks)。根據問題文字的不同,標記化輸入後的標記數量可能不同。因此,為使用標記的模型輸入保留動態形狀,dynamic_axes參數負責在onnx.export中保留輸入的動態特定維度。程式碼如下:
TEXT_ENCODER_ONNX = TEXT_ENCODER_OV.with_suffix(".onnx")
text_encoder = model.text_encoder
text_encoder.eval()
# if openvino model does not exist, convert it to onnx and then to IR
if not TEXT_ENCODER_OV.exists():
if not TEXT_ENCODER_ONNX.exists():
# prepare example inputs for ONNX export
image_embeds = vision_outputs[0]
image_attention_mask = torch.ones(image_embeds.size()[:-1], dtype=torch.long)
input_dict = {"input_ids": inputs["input_ids"], "attention_mask": inputs["attention_mask"], "encoder_hidden_states": image_embeds, "encoder_attention_mask": image_attention_mask}
# specify variable length axes
dynamic_axes = {"input_ids": {1: "seq_len"}, "attention_mask": {1: "seq_len"}}
# export PyTorch model to ONNX
with torch.no_grad():
torch.onnx.export(text_encoder, input_dict, TEXT_ENCODER_ONNX, input_names=list(input_dict), dynamic_axes=dynamic_axes)
# convert ONNX model to IR using model conversion Python API, use compress_to_fp16=True for compressing model weights to FP16 precision
ov_text_encoder = mo.convert_model(TEXT_ENCODER_ONNX, compress_to_fp16=True)
# save model on disk for next usages
serialize(ov_text_encoder, str(TEXT_ENCODER_OV))
print(f"Text encoder successfuly converted and saved to {TEXT_ENCODER_OV}")
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV}")
- 文字解碼器轉換:文字解碼器負責使用影像(以及問題,如果需要的話)的表示來生成模型輸出(問題的答案或描述)的分詞token序列。生成方法基於這樣的假設,即單詞序列的概率分佈可以分解為下一個單詞條件分佈的乘積。換言之,模型預測由先前生成的token引導迴圈生成下一個token,直到達到停止生成的條件(生成達到最大長度序列或獲得的字串結束的token)。在預測概率之上選擇下一個token的方式由所選擇的解碼方法來驅動。與文字編碼器類似,文字解碼器可以處理不同長度的輸入序列,並且需要保留動態輸入形狀。這部分特殊的處理可由如下程式碼完成:
text_decoder.eval()
TEXT_DECODER_OV = Path("blip_text_decoder.xml")
TEXT_DECODER_ONNX = TEXT_DECODER_OV.with_suffix(".onnx")
# prepare example inputs for ONNX export
input_ids = torch.tensor([[30522]]) # begin of sequence token id
attention_mask = torch.tensor([[1]]) # attention mask for input_ids
encoder_hidden_states = torch.rand((1, 10, 768)) # encoder last hidden state from text_encoder
encoder_attention_mask = torch.ones((1, 10), dtype=torch.long) # attention mask for encoder hidden states
input_dict = {"input_ids": input_ids, "attention_mask": attention_mask, "encoder_hidden_states": encoder_hidden_states, "encoder_attention_mask": encoder_attention_mask}
# specify variable length axes
dynamic_axes = {"input_ids": {1: "seq_len"}, "attention_mask": {1: "seq_len"}, "encoder_hidden_states": {1: "enc_seq_len"}, "encoder_attention_mask": {1: "enc_seq_len"}}
# specify output names, logits is main output of model
output_names = ["logits"]
# past key values outputs are output for caching model hidden state
past_key_values_outs = []
text_decoder_outs = text_decoder(**input_dict)
for idx, _ in enumerate(text_decoder_outs["past_key_values"]):
past_key_values_outs.extend([f"out_past_key_value.{idx}.key", f"out_past_key_value.{idx}.value"])
接下來,對於文字解碼器的轉換,還有來自前一步驟的隱藏狀態的額外輸入。與輸出類似,在模型匯出為ONNX格式後,它們將被展平。需要使用新的輸入層更新dynamic_axies和input_names。因此,其後的轉換過程與前面的文字編碼器轉換過程類似,在本文中不再贅述。
第三步:執行OpenVINO 推論
如前所述,在這裡我們將主要展示BLIP進行視覺問答以及影像描述的流水線如何搭建、以及如何執行OpenVINO來進行推論的情況。
- 影像描述
視覺模型接受BlipProcessor預處理的影像作為輸入,並生成影像嵌入,這些影像嵌入直接傳遞給文字解碼器以生成描述標記。生成完成後,分詞tokenizer的輸出序列被提供給BlipProcessor,用於使用tokenizer解碼為文字。
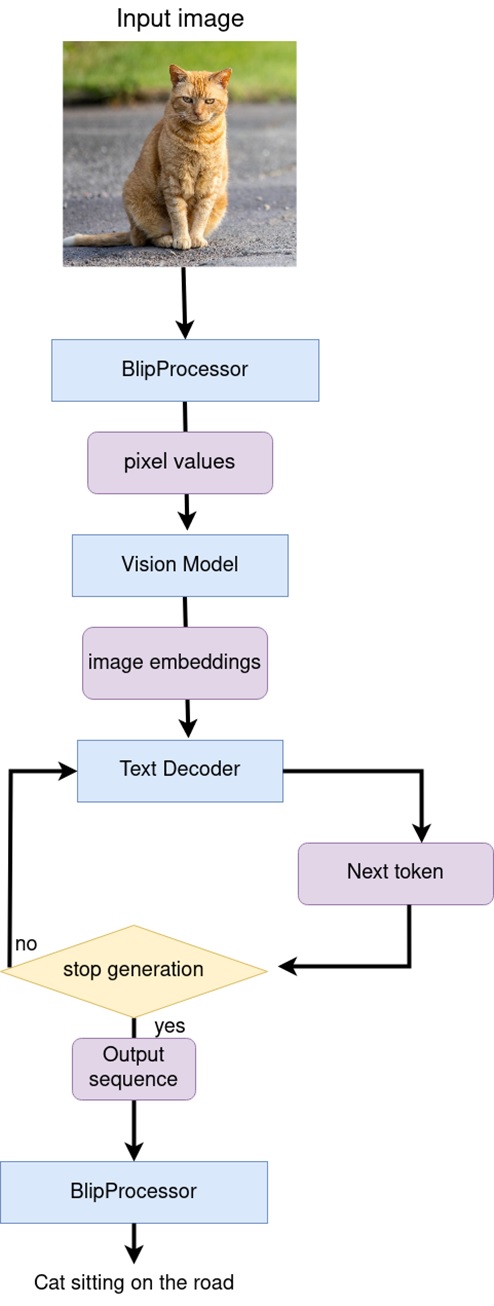
定義OVBLIPModel類別:
"""
Model class for inference BLIP model with OpenVINO
"""
def __init__(self, config, decoder_start_token_id:int, vision_model, text_encoder, text_decoder):
"""
Initialization class parameters
"""
self.vision_model = vision_model
self.vision_model_out = vision_model.output(0)
self.text_encoder = text_encoder
self.text_encoder_out = text_encoder.output(0)
self.text_decoder = text_decoder
self.config = config
self.decoder_start_token_id = decoder_start_token_id
self.decoder_input_ids = config.text_config.bos_token_id
定義影像字幕函數如下:
"""
Image Captioning prediction
Parameters:
pixel_values (torch.Tensor): preprocessed image pixel values
input_ids (torch.Tensor, *optional*, None): pregenerated caption token ids after tokenization, if provided caption generation continue provided text
attention_mask (torch.Tensor): attention mask for caption tokens, used only if input_ids provided
Retruns:
generation output (torch.Tensor): tensor which represents sequence of generated caption token ids
"""
batch_size = pixel_values.shape[0]
image_embeds = self.vision_model(pixel_values.detach().numpy())[self.vision_model_out]
image_attention_mask = torch.ones(image_embeds.shape[:-1], dtype=torch.long)
if isinstance(input_ids, list):
input_ids = torch.LongTensor(input_ids)
elif input_ids is None:
input_ids = (
torch.LongTensor([[self.config.text_config.bos_token_id, self.config.text_config.eos_token_id]])
.repeat(batch_size, 1)
)
input_ids[:, 0] = self.config.text_config.bos_token_id
attention_mask = attention_mask[:, :-1] if attention_mask is not None else None
outputs = self.text_decoder.generate(
input_ids=input_ids[:, :-1],
eos_token_id=self.config.text_config.sep_token_id,
pad_token_id=self.config.text_config.pad_token_id,
attention_mask=attention_mask,
encoder_hidden_states=torch.from_numpy(image_embeds),
encoder_attention_mask=image_attention_mask,
**generate_kwargs,
)
return outputs
- 視覺問答
視覺回答的流水線看起來很相似,但有額外的問題處理。在這種情況下,由BlipProcessor標記的影像嵌入和問題被提供給文字編碼器,然後多形態問題嵌入被傳遞給文字解碼器以執行答案的生成。
在OVBLIPModel類別內部同理可定義視覺問答函數如下:
"""
Visual Question Answering prediction
Parameters:
pixel_values (torch.Tensor): preprocessed image pixel values
input_ids (torch.Tensor): question token ids after tokenization
attention_mask (torch.Tensor): attention mask for question tokens
Retruns:
generation output (torch.Tensor): tensor which represents sequence of generated answer token ids
"""
image_embed = self.vision_model(pixel_values.detach().numpy())[self.vision_model_out]
image_attention_mask = np.ones(image_embed.shape[:-1], dtype=int)
if isinstance(input_ids, list):
input_ids = torch.LongTensor(input_ids)
question_embeds = self.text_encoder([input_ids.detach().numpy(), attention_mask.detach().numpy(), image_embed, image_attention_mask])[self.text_encoder_out]
question_attention_mask = np.ones(question_embeds.shape[:-1], dtype=int)
bos_ids = np.full((question_embeds.shape[0], 1), fill_value=self.decoder_start_token_id)
outputs = self.text_decoder.generate(
input_ids=torch.from_numpy(bos_ids),
eos_token_id=self.config.text_config.sep_token_id,
pad_token_id=self.config.text_config.pad_token_id,
encoder_hidden_states=torch.from_numpy(question_embeds),
encoder_attention_mask=torch.from_numpy(question_attention_mask),
**generate_kwargs,
)
return outputs
- 初始化OpenVINO Runtime並執行推論
初始化OpenVINO Core物件,選擇推論設備,並載入、編譯模型:
core = Core()
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
# load models on device
ov_vision_model = core.compile_model(VISION_MODEL_OV, device.value)
ov_text_encoder = core.compile_model(TEXT_ENCODER_OV, device.value)
ov_text_decoder = core.compile_model(TEXT_DECODER_OV, device.value)
ov_text_decoder_with_past = core.compile_model(TEXT_DECODER_WITH_PAST_OV, device.value)
-
- 執行影像描述推論
caption = processor.decode(out[0], skip_special_tokens=True)
fig = visualize_results(raw_image, caption)
執行效果如下圖所示:

-
-
- 執行視覺問答推論
-
out = ov_model.generate_answer(**inputs, max_length=20)
end = time.perf_counter() - start
answer = processor.decode(out[0], skip_special_tokens=True)
fig = visualize_results(raw_image, answer, question)
執行效果如下圖所示:

小結
整個步驟就是這樣!現在就開始跟著我們提供的程式碼和步驟,動手試試用OpenVINO和BLIP吧。
關於英特爾OpenVINO開源工具套件的詳細資料,包括其中我們提供的三百多個經驗證並優化的預訓練模型的詳細資料,請點擊以下連結:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,為了方便大家瞭解並快速掌握OpenVINO的使用,我們還提供了一系列開源的Jupyter notebook demo。執行這些notebook,就能快速了解在不同場景下如何利用OpenVINO實現一系列包括電腦視覺、語音及自然語言處理任務。OpenVINO notebooks的資源可以在GitHub下載安裝:https://github.com/openvinotoolkit/openvino_notebooks 。

- OpenVINO 2025.3: 更多生成式AI,釋放無限可能 - 2025/09/26
- 用OpenVINO GenAI解鎖LoRA微調模型推論 - 2025/08/29
- 用OpenVINO GenAI解鎖LLM極速推論:推測式解碼讓AI爆發潛能 - 2025/04/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


