作者:高煥堂
何為LoRA 模型?它是一種訓練好的模型,只要在Stable Diffusion上餵給它相關風格的圖,就可以產出類似風格的影像,而且速度較快、檔案較小,你可以在網路上找到有很多訓練好的分享模型檔。
我想創造自己獨有的約翰韋恩風格LoRA 模型。
依據採用的 diffusion 主模型所需,準備 14 張約翰韋恩照片,縮放、裁切為像素 512 x 512,存於筆電,用來生成約翰韋恩風的LoRA 模型。

約翰韋恩照片
備妥Google 雲端硬碟並安裝Colab操作環境。由於Colab是依附在 Chrome 的執行環境,因此瀏覽器需使用Crome。
在Colab訓練自己的LoRA
首先,進入https://github.com/camenduru/stable-diffusion-webui-colab 頁面,我們頁面中,可找到 simple LoRA Train (ipynb),直接開啟使用。

圖一
點擊 branches
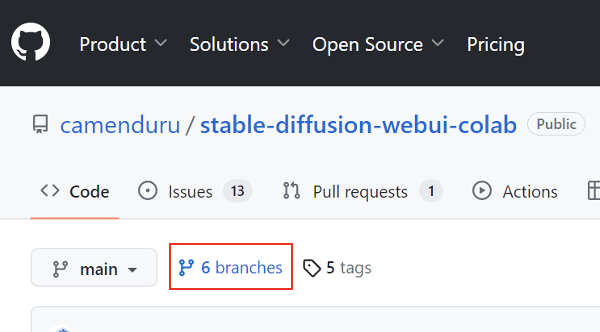
圖二
可以看見,原碼分支除了main外,有幾個不同分支。點擊 training 分支(它未必排在第一個)。
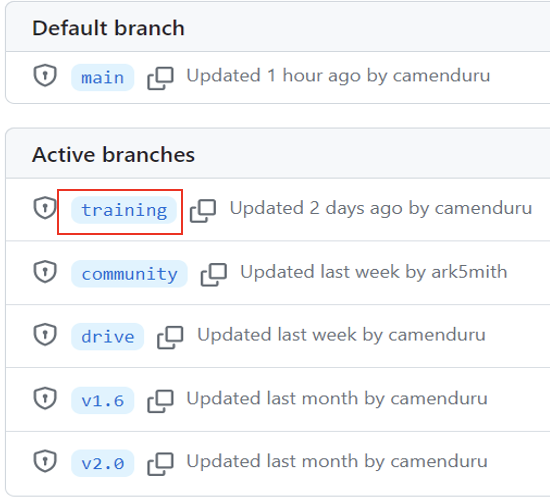
圖三
在三個colab 頁面中,請以Ctrl + 點擊 Simple LoRA Trainer 所在列的 open_in_colab 圖示,如圖四紅框處。
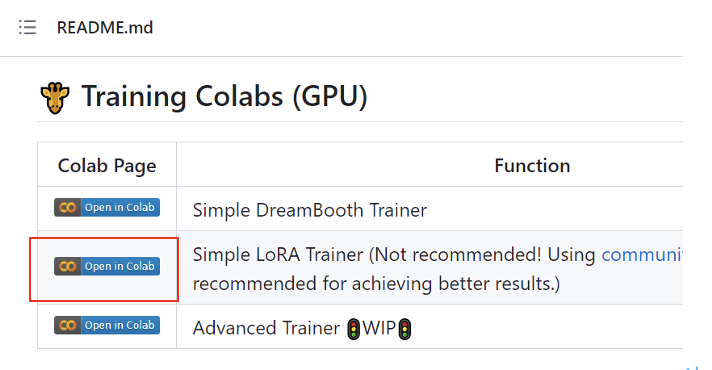
圖四
產生另一分頁 simple_lora_trainer.ipynb後,我們切換到 simple_lora_trainer.ipynb。

圖五
simple_lora_trainer.ipynb 是簡約版的 LoRA 模型訓練腳本。而撰寫此腳本的開發者,相當體貼的將在訓練過程中,需要我們填入的資訊單獨的拉至另外一個頁面。如下圖紅框處,一共有5個欄位,等待我們填入相關資訊。
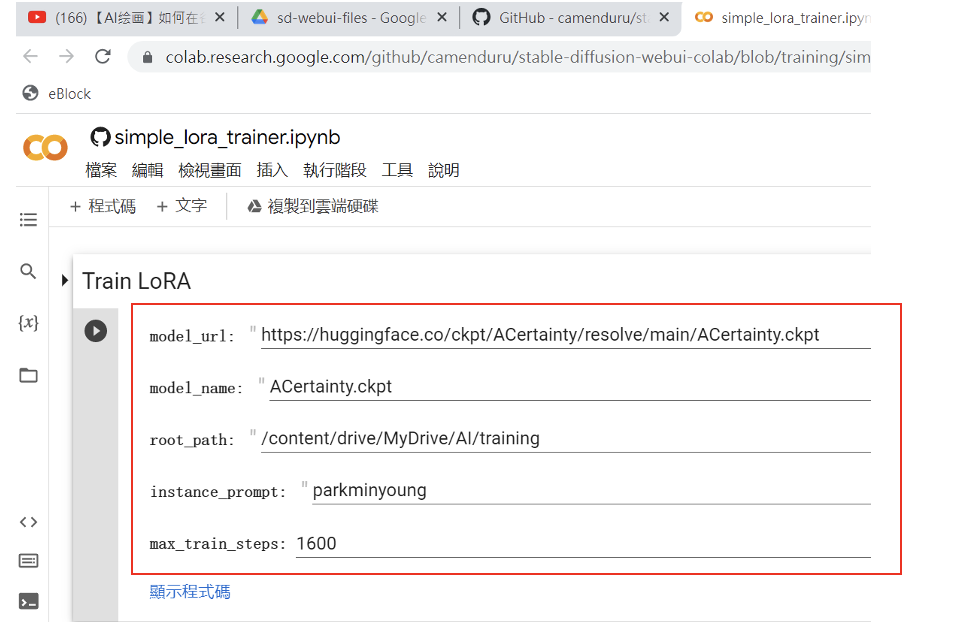
圖六
點擊「複製到雲端硬碟」,將simple_lora_trainer.ipynb複製到雲端硬碟。

圖七
接著,我們逐一填寫下列欄位:
1.Model_url,model_name :
訓練LoRA時,必須搭配適配的StableDiffusion 模型,可到 civitai或 Hugging Face 搜尋,這裡我是用AnyLoRA – Checkpoint,我們在瀏覽器Chrome 輸入https://civitai.com/models/23900/anylora
進入 AnyLoRA 下載網頁我們要下載 AnyLoRA-Checkpoint 作為我們的Stable Diffusion主模型,請以滑鼠右鍵點擊下圖紅框處。
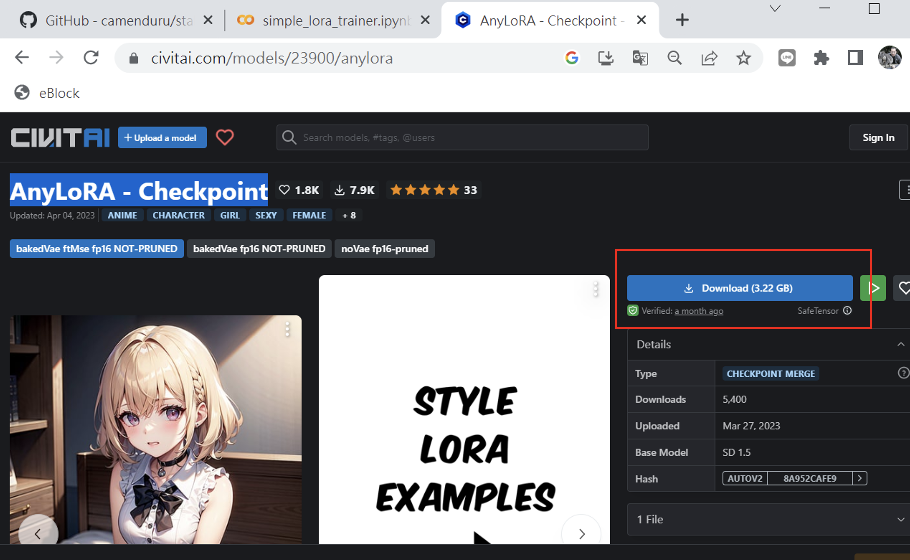
圖八
圖九
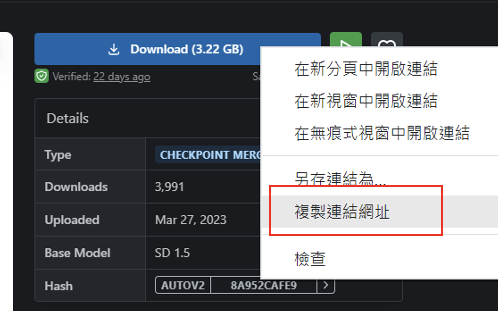
點擊 「複製連結網址」。
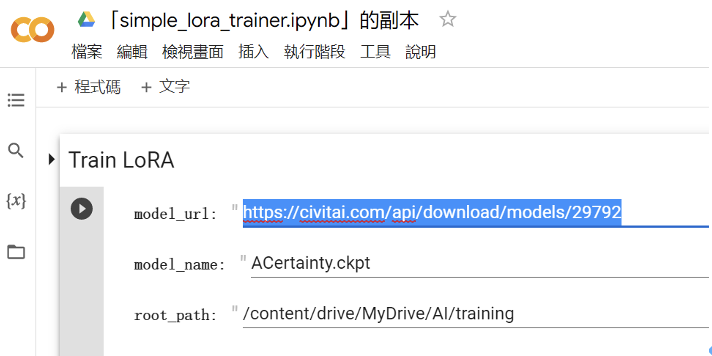
複製網址連結,貼到 model_url。
圖十
並將sd模型名稱,貼到model_name。
圖十一

圖十二
2.Root_path 是 訓練素材所在路徑,instance_prompt 為LoRA 模型名稱。
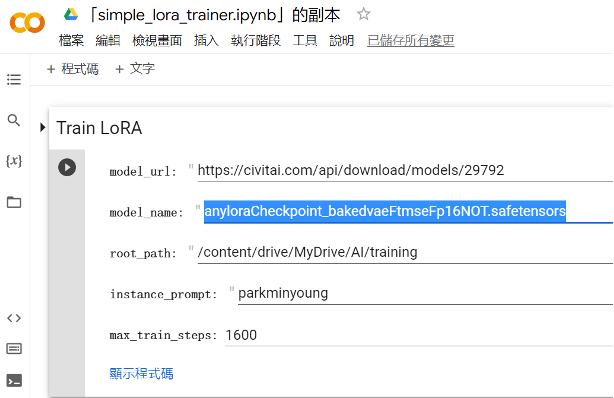
圖十三
在雲端硬碟建立一個和LoRA模型同名的資料夾後,將訓練素材複製到此路徑。
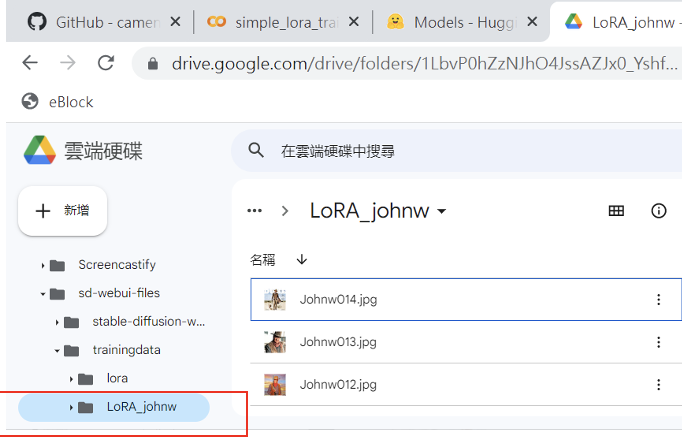
圖十四
填入訓練素材資料夾名稱到 instance_prompt欄,它的上層資料夾完整路徑填入 root_path後,點擊 「顯示程式碼」,開啟 LoRA訓練腳本。
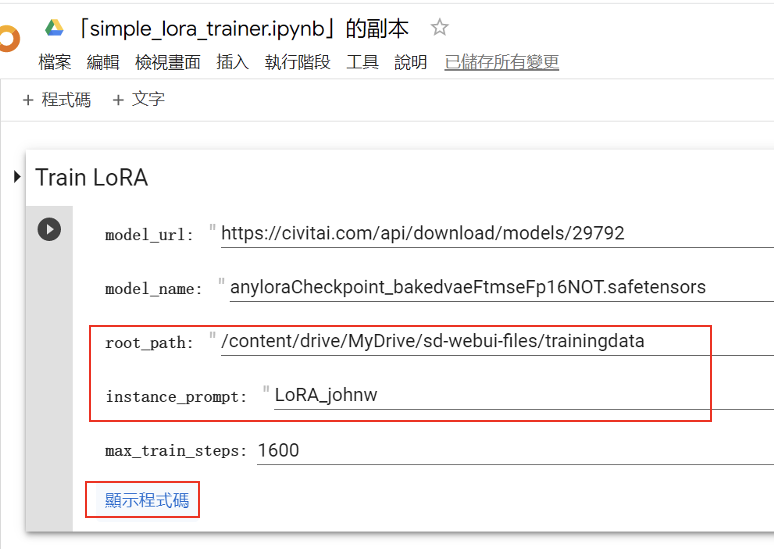
圖十五
由於我們已填入root_path, instance_prompt ,因此我們僅需略為調整腳本即可。首先將 {model_url} 使用 “”圍起,如圖十六:
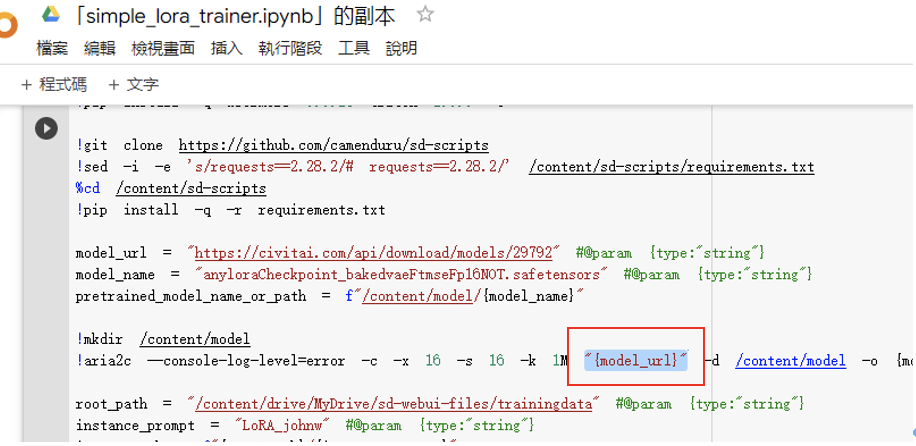
圖十六
接著複製root_path + “/lora/{instance_prompt}” 取代 output_dir。
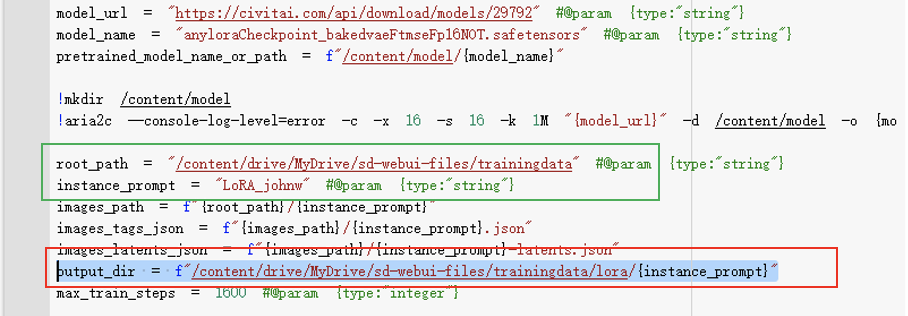
圖十七
開始運行LoRA訓練前,記得儲存我們的操作成果。
圖十八
接著,點擊「執行」 ,開始執行 LoRA 訓練腳本。
圖十九
訓練過程視情況需約 20 ~ 40分鐘。訓練完成時,將生成 LoRA檔 .safetensors,並且為每張訓練素材圖檔生成一個 prompt文字檔。
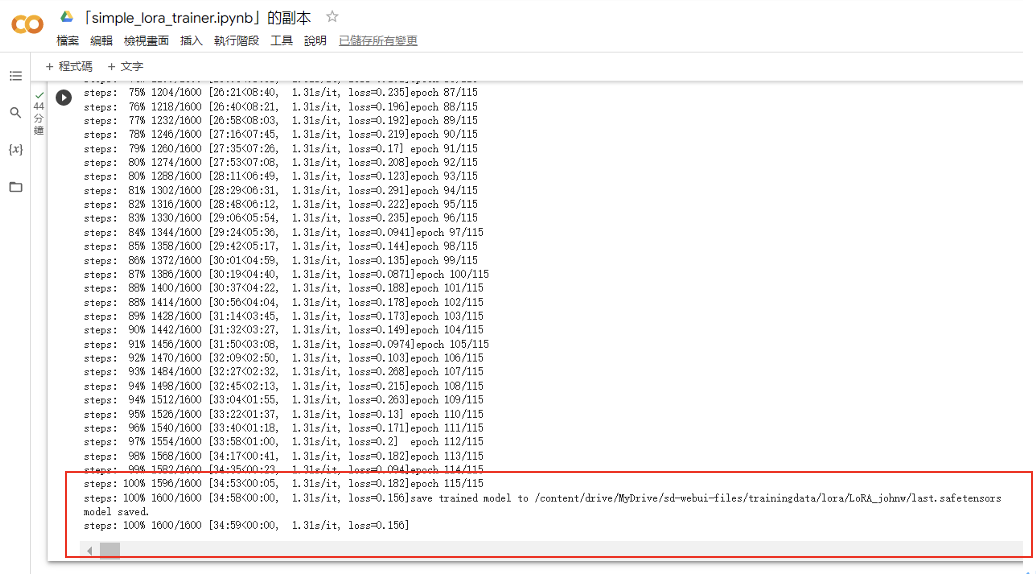
圖二十

圖二十一
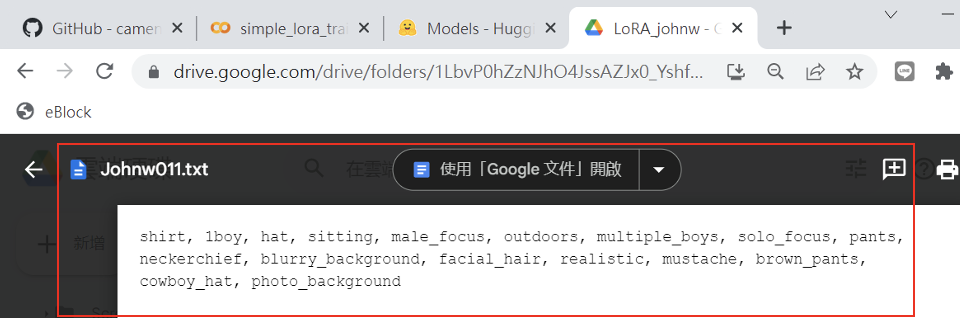
圖二十二
LoRA 模型 LoRA_johnw.safetensors生成:
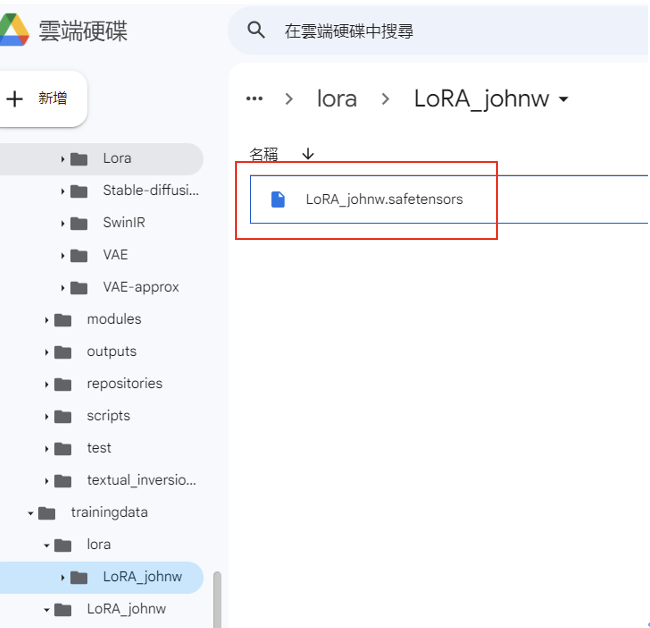
圖二十三
開啟 SD-webUI-demo.ipynb 網頁,測試剛訓練完成的 LoRA 模型。
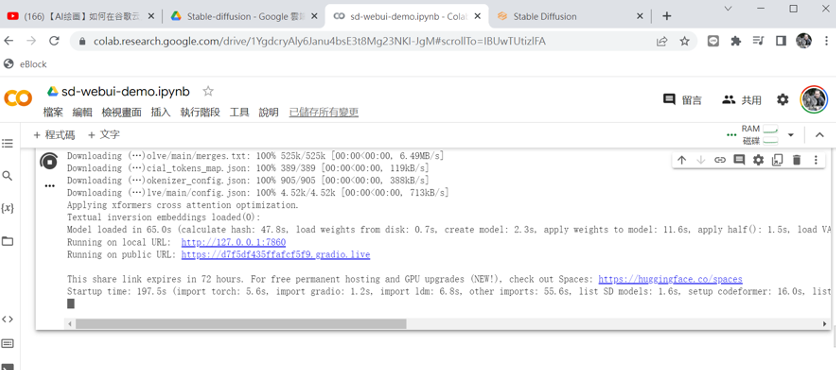
圖二十四
確認使用的SD主模型是否為AnyLoRA,並選擇我們自己訓練的LoRA模型。
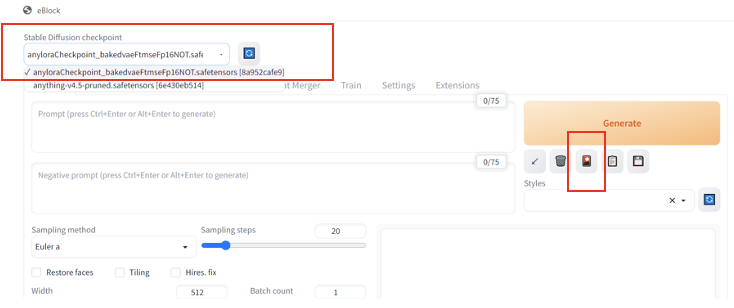
圖二十五
Txt2img 可輸入提示詞或複製訓練LoRA時生成的prompt提示詞後,點擊 Generate。
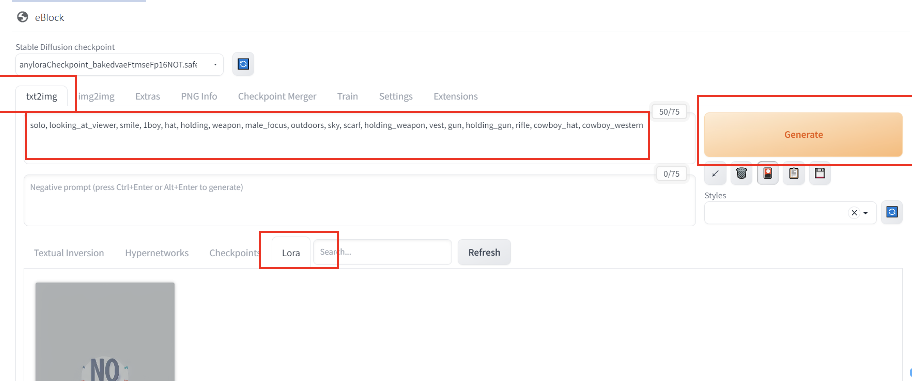
圖二十六
即可生成我們的目標:約翰韋恩風格的人物。
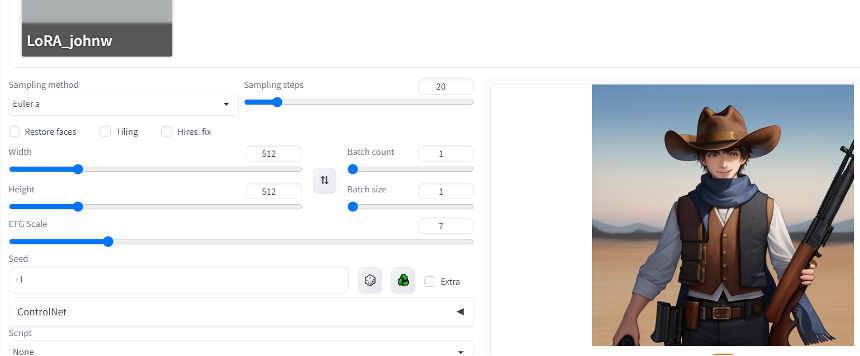
圖二十七

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


