作者:歐敏銓
隨著 2026 年全球機器人市場進入「具身智能」(Embodied AI)的爆發期,運算架構的競爭已從雲端數據中心轉向邊緣端。Intel 憑藉 Panther Lake(Core Ultra 系列 3)的 18A 製程與 NPU 5.0,配合 OpenVINO 2026.0 軟體棧與全新的 Robotics AI Suite,正試圖在 VLA 模型與實體 AI(Physical AI)領域,與 NVIDIA 的高算力霸權爭一片天。這不僅是算力的競爭,更是關於「能效比」與「即時控制」的落地革命。
事實上,就如同自動駕駛系統需要眾多的運算核心來處理多工的即時駕駛情境,實體AI所聚焦的「機器人」系統同樣也存在複雜、需協作的任務情境,不會是一、兩顆處理器就能全盤搞定的,本文且來探討Intel在機器人市場的可能佈局與契機。
邊緣AI的新異構運算體系:Panther Lake
在機器人技術的藍圖中,處理器始終面臨一個矛盾:要麼擁有強大的神經網路推理能力(如 GPU),要麼擁有精準的邏輯與即時控制能力(如 CPU)。Intel 於 2025 年底至 2026 年初全面推向市場的 Panther Lake ,有機會打破這一藩籬。
Panther Lake 採用了 Intel 最先進的 18A 製程,這不僅是物理尺寸的縮減,更是電晶體結構的革新。其核心在於「三位一體」的異構架構:Cougar Cove 效能核心 (P-core)、Skymont 效率核心 (E-core) 以及專為 AI 設計的 NPU 5.0。對於一個具身智能機器人而言,這代表著它不再需要外掛一張昂貴且耗電的獨立顯卡來處理視覺辨識。
180 TOPS 的「平台總算力」
技術上的落實體現在其平台總算力分配。Intel 在 2025 年 10 月的架構深度解析中明確指出,Panther Lake 平台透過整合 NPU 5.0(提供 50 TOPS)、Xe3 iGPU(提供高達 120 TOPS)以及 CPU(約 10 TOPS),達成總計 180 TOPS 的「平台總算力」。

研揚科技(AAEON)在 CES 2026 展出了採用Intel Robotics參考設計(上圖)的 CEXD-INTRBL 機器人開發系統中,具體描述了 Panther Lake 的分工:NPU 5.0 專門處理持續性的 AI 推理任務,如環境語義理解;Xe3 GPU 則負責高頻寬的 3D 空間感知與點雲處理;而 Cougar Cove 核心則確保了機器人作業系統(如 ROS 2)的即時響應。這種配置讓機器人從「思考」到「動作」的反應延遲縮短至毫秒級。
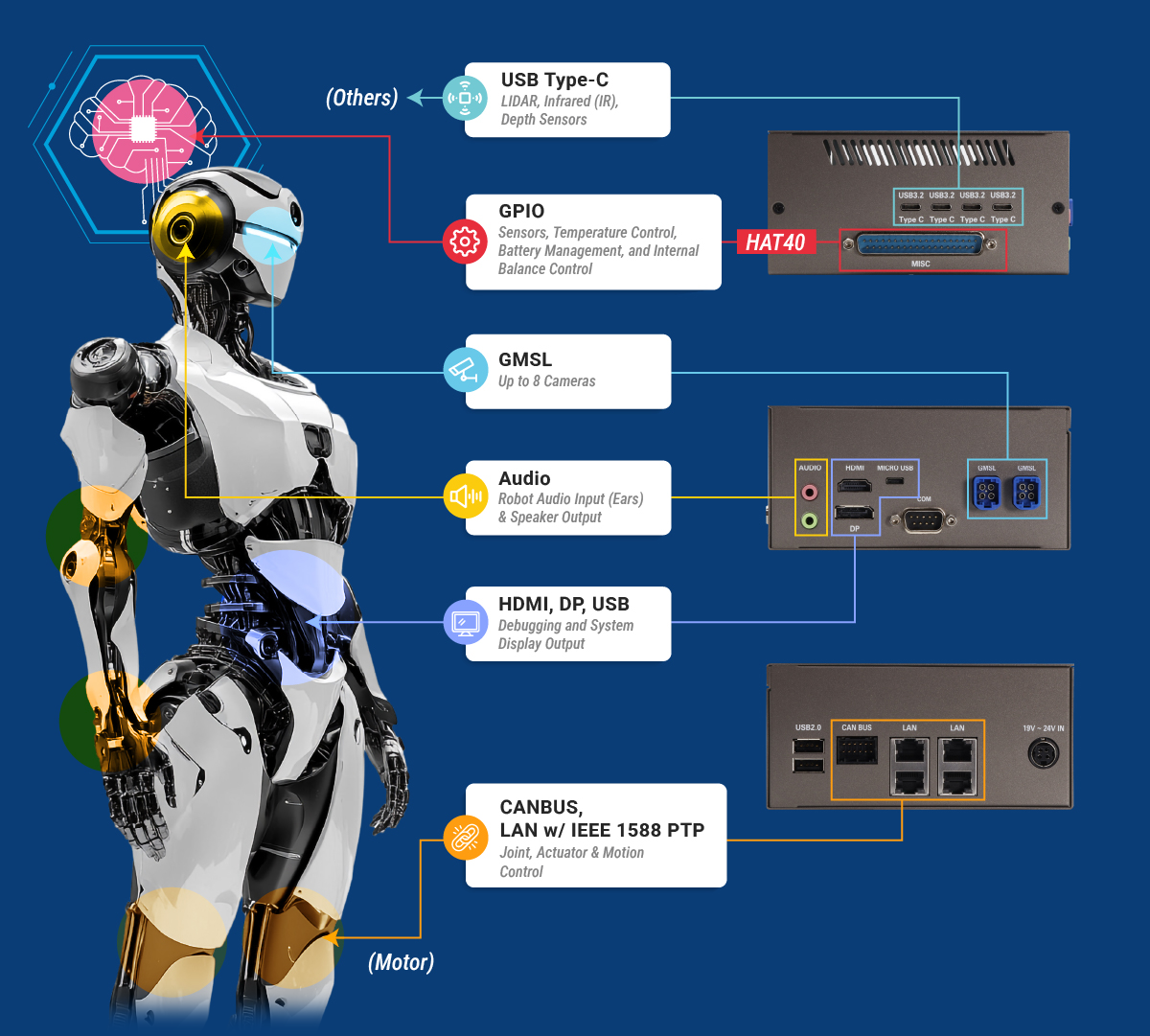
AAEON推出的CEXD-INTRBL專屬機器人開發系統(source)
30W 功率下的流暢運轉與能效比
事實上,NPU 與 CPU 的配合讓機器人在 30W 功耗下實現了更平滑的運動(Smoother motion)與更快的反應。
Intel 在 2026 年 CES 官方公告中提到,Core Ultra 系列 3(Panther Lake)在提供高達 180 TOPS 算力的同時,針對嵌入式與機器人場景優化了功耗。Panther Lake 的典型 TDP(熱設計功耗)範圍涵蓋 15W 至 45W,在機器人應用中,30W 是一個標準的穩定運行設定點。新聞稿中具體提到,這讓原本需要「多晶片 CPU+GPU(通常功耗破百瓦)」的複雜 VLA 任務,現在能由單一 SoC (System on Chip) 方案達成。
在人型機器人(Humanoids)應用中,Panther Lake 實現了比競爭對手(如 Jetson Orin)快 4.5 倍的 VLA 模型吞吐量(下圖),並將視覺推理到動作執行的「端到端延遲」大幅降低。這種配置解決了機器人在執行複雜 AI 任務時常見的「動作延遲」問題,讓機器人從「思考」到「出拳」的反應時間(Inference-to-Action Latency)縮短至毫秒級。

VLA 模型的落地:從「巨型雲端」到「輕量端側」
視覺-語言-動作模型(Vision-Language-Action, VLA)是 2026 年機器人的主流開發趨勢。它讓機器人能理解「幫我拿那杯冒煙的咖啡」這種模糊指令。然而,像 Google RT-2 或 Physical Intelligence 的 π0 這種模型,動輒擁有數十億甚至數百億參數。
Intel 的解決方案並非硬碰硬地追求單一晶片運算極限,而是透過 OpenVINO 2026.0 進行「外科手術式」的優化。OpenVINO 2026.0引進了 混合專家模型 (MoE,Mixture of Experts) 專用調度器。該版本引進了針對 Intel CPU 與 NPU 優化的「動態專家調度」功能,當 Panther Lake 執行 VLA 模型(如 Qwen3-30B-A3B)的推論時,系統不再激活所有參數,而是根據指令僅調用相關的權重。例如,當機器人只需要進行導航時,語言理解模組會進入低功耗狀態,僅由視覺與動作模組主導。
》延伸閱讀:Create LLM-powered Chatbot using OpenVINO
此外,Intel 推出的 Action Tokenization(動作標記化) 技術,成功將 VLA 輸出的抽象文字指令,直接在 OpenVINO 內層映射為機器人執行器的 PWM 信號。這省去了中間層的軟體轉換,大幅提升了 Physical AI 的執行效率,使得原本需要在伺服器運行的模型,現在能在功率不到 30W 的 Panther Lake 晶片上流暢運轉。
2026.0版本的 OpenVINO 還增加了針對 NPU 的 Speculative Decoding(猜測性解碼) 支援。這項技術專門用於加速 LLM/VLA 模型的 Token 生成速度。技術測試顯示,這種優化能顯著降低推理到動作生成的延遲,使機器人在處理閉環控制(Closed-loop control)時達到毫秒級的反應速度,這在物理 AI(Physical AI)的避障與抓取任務中至關重要。
》延伸閱讀:OpenVINO 2026.0: New Models, Enhanced GenAI, and Smarter Compression
關鍵催化劑:Intel Robotics AI Suite 的全棧整合
在機器人開發架構上,Panther Lake 是運算核心,OpenVINO 是軟體引擎,串起兩者的開發框架則是 Intel Robotics AI Suite。
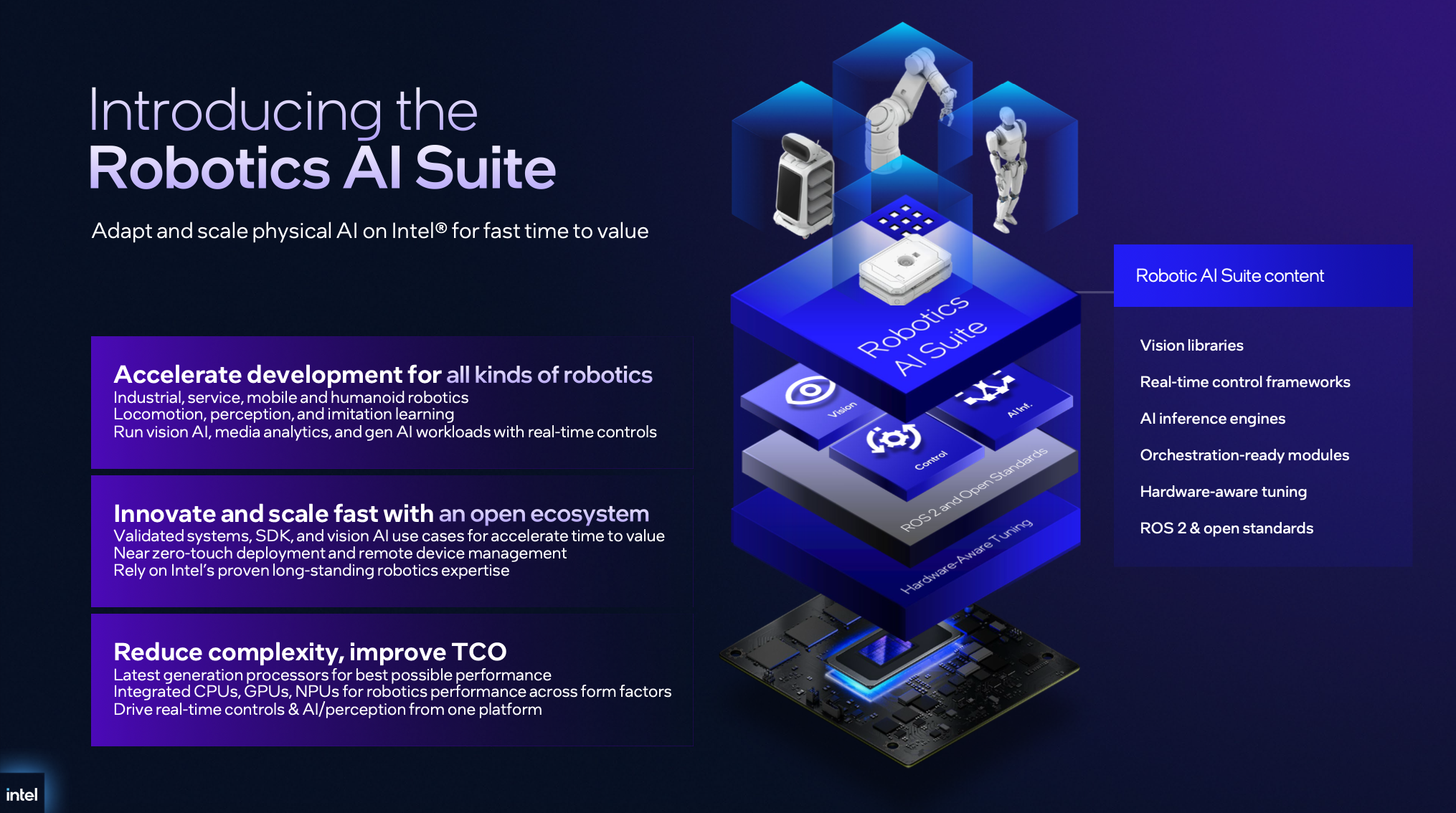
Intel Robotics AI Suite 是一個專為具身智能設計的軟體開發平台,它直接整合了 OpenVINO 2026.0 的推理能力。其核心價值在於提供「開箱即用」的 VLA 參考流水線 (Reference Pipelines)。開發者不再需要從零開始撰寫如何驅動 NPU 進行動作預測,這平台內建的 Action Tokenizer 會自動將 AI 模型生成的 Token 映射至機器人的馬達控制器。此外,它還支援 Collaborative SLAM 庫,讓多台搭載 Panther Lake 的機器人能在同一場域內共用地圖數據,這對於自動化倉儲與醫院物流至關重要。
透過這套平台,Intel 成功將 Panther Lake 的硬體特性發揮到極致。例如,它能自動偵測 NPU 的負載,並在需要高精細避障時,動態地將計算壓力分流至 Xe3 GPU 的 XMX 矩陣引擎,確保 Physical AI 的決策不會因為運算資源衝突而卡頓。
Physical AI 的具體實踐:從感測到即時回饋
在 Physical AI 領域,Intel 解決方案的另一個支柱是與 Intel TCC (Time-Coordinated Computing) 的深度整合。TCC是一項針對物聯網與工業自動化開發的技術,旨在降低處理器內的時延(Latency)並減少抖動(Jitter),提供確定性(Deterministic)的運算效能。
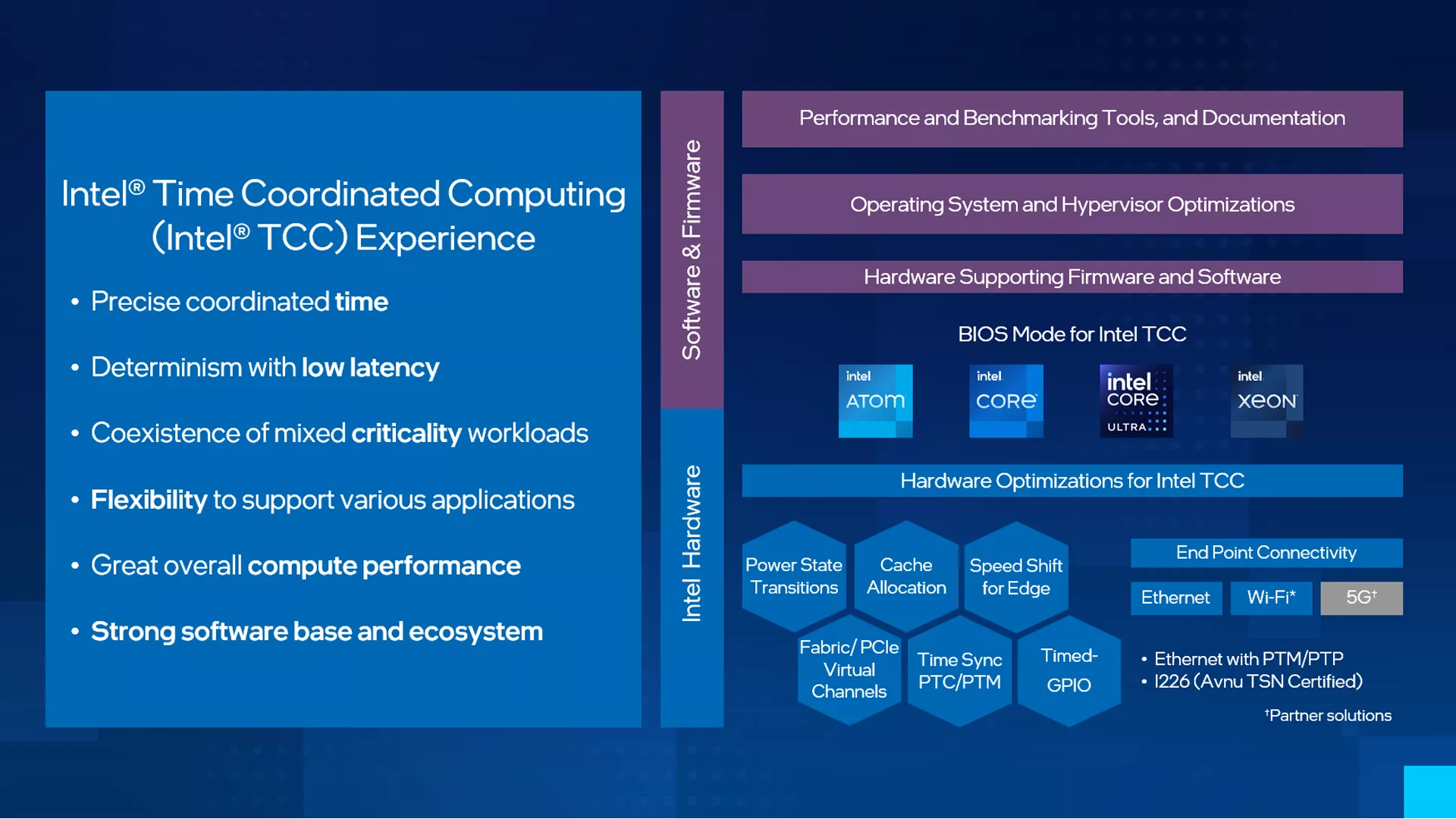
實體 AI 的挑戰在於機器人必須對物理世界的微小變化(如路面不平、物體滑落)做出即時補償。Intel Panther Lake 內建的 TCC 技術,能夠在硬體層級為機器人控制循環(Control Loop)保留專用的 CPU 週期。這意味著即便系統正在進行繁重的 VLA 語義計算,底層的平衡控制演算法也不會被中斷。
具體事實顯示,在 2026 年初的一項工廠自動化案例中,搭載 Panther Lake 的機器臂在執行「動態抓取」任務時,其延遲抖動(Jitter)控制在 10 微秒以內。配合 OpenVINO 對 3D 點雲數據的加速處理,機器人能精確識別透明物體或反光金屬,這在過往是純視覺方案的痛點。
此外,Panther Lake 的硬體隔離技術 (Intel TDX) 可確保機器人的 AI 模型不會被惡意竄改。在實體 AI 應用中,這保證了機器人的運動軌跡安全性(Safety Guardrails)是在硬體受信任層執行的,而非單純的軟體判定。
區隔與互補:雙強並立的機器人生態
很顯然地,Intel 無法在每個領域都與 NVIDIA正面對決。事實上,兩者在技術落實上呈現出互補態勢。NVIDIA 的 Isaac Sim 依然是開發者的首選「訓練場」,在虛擬環境中生成數百萬小時的訓練數據;而 Intel 則致力於成為這些數據轉化為產品後的「執行場」。
為了讓開發者能平順轉化模型,Intel提出跨架構模型轉移 (Cross-Architecture Portability)的功能:開發者在 NVIDIA DGX 伺服器上利用物理引擎訓練出的大型權重,可透過 OpenVINO 的 Model Optimizer 快速轉換為 OpenVINO IR 格式。這過程包括自動化的「權重剪枝」與「層融合」,讓原本需耗費 300W 功耗運行的模型,在 Panther Lake 上以 15W-28W 運作,且精度損耗控制在 1% 以內。
整體來說,Intel 更專注於「邊緣整合與能效」,而 NVIDIA 則持續引領「極致性能與訓練模擬」。為了更直觀地理解 Intel 如何與 NVIDIA 做出區隔,我們整理了下表。
| 技術維度 | Intel Panther Lake + OpenVINO | NVIDIA Jetson Thor + ISAAC |
| 核心算力源 | NPU 5.0 + Xe3 GPU (異構整合) | Blackwell GPU 架構 (強大並行運算) |
| 主要優勢 | 極高能效比、x86 生態系統、低總持有成本 | 頂級物理模擬、高維度 AI 訓練、領先的算力峰值 |
| 軟體工具重心 | 模型部署優化、輕量化量化 (INT8/FP8) | 數位孿生模擬 (Sim-to-Real)、強化學習 |
| 典型應用場景 | 商用配送、醫療照護、輕工業協作臂 | 通用型人型機器人、全自動化倉儲系統 |
下表則呈現了兩者在模型執行週期中的分工互補關係:
| 開發階段 | NVIDIA 的角色 (主導開發與訓練) | Intel 的角色 (主導落地與普及) |
| 訓練與模擬 | 提供超大規模 GPU 叢集與 Isaac Lab 物理環境。 | 利用 Gaudi 3 加速器提供具成本效益的微調環境。 |
| 模型優化 | TensorRT 優化,追求極限吞吐量。 | OpenVINO 優化,追求跨硬體相容性與低延遲。 |
| 邊緣部署 | Jetson Thor 針對高階人型機器人與重型 AMR。 | Panther Lake 針對主流商用、家用及嵌入式裝置。 |
結語
2026 年的機器人產業已不再盲目追求算力數值,而是回歸到「續航、安全、成本」這三大本質。Intel 通過 Panther Lake 與 OpenVINO 的組合,證明了不需要背負幾百瓦的功耗,也能實現 VLA 與實體 AI 應用。NVIDIA 建立了強大的虛擬世界模擬標準,而 Intel 則正在利用其深厚的邊緣運算能力,將這些虛擬的智慧實體,以更親民、更高效的方式帶入真實世界的工廠、醫院與家庭,值得期待。

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


