作者:李盛安,慈濟大學醫學資訊學系副教授、英特爾軟體創新大使
在機器人技術的發展長河中,有些時刻象徵著技術能力的本質躍升:從2D視覺到深度學習、從手工特徵到端對端模型、從依賴雲端到邊緣運算。
而如今,我們正站在另一個重大轉折點的前端——3D 空間感知與即時推論的全面融合。
如果說深度學習讓機器能看懂「影像」(Image),那麼3D感知則讓機器能真正理解「空間」(Space)。而Intel OpenVINO Toolkit的角色,則是讓這種高維度的理解能力真正能夠在邊緣落地——不再依賴昂貴的伺服器或高功耗的獨立顯卡,而是在手掌大小的 NUC AI PC 上穩定運作。
本文將從感知的源頭談起,結合2025年最新的Ubuntu 24.04與 ROS 2 Jazzy 生態,帶領讀者理解:為什麼3D是機器人能力的關鍵突破?OpenVINO如何透過NPU與iGPU的異質運算推動這場革命?
從看見世界到理解世界:為什麼2D不夠用了?
過去十年,機器視覺高度仰賴2D影像進行辨識、分類與偵測。但2D視覺只能回答機器人一些有限的問題:「這是什麼?」(What)、「它在影像的哪個位置?」(Where)。
然而,要讓機器人安全且智慧地在真實世界中行動,我們更需要它回答:
- 「它離我多遠?」
- 「這個物體的體積為何?我能不能抓起它?」
- 「這條路徑的空間結構能不能走?會不會撞到懸空的障礙物?」
- 「這個人正在靠近還是離開?」
這些問題,本質上都是三維空間問題。
深度相機帶來的空間革命與資料海嘯
在目前的感測器光譜中,能提供真實3D感知的選項並不多。相比於昂貴的3D LiDAR或資訊量不足的2D LiDAR,而深度相機(Depth Camera,如 Intel RealSense 系列)能產生彩色影像與密集深度圖,成為了室內機器人的首選。
然而,深度感知帶來了巨大的資訊量衝擊:一幀640×480的深度影像可產生307,200個點雲點,若以每秒30幀計算,處理器每秒需運算高達900萬個空間點。
這就是瓶頸所在:3D感知並非不能做,而是「太重」。在SWaP(尺寸、重量、功耗)受限的邊緣設備上,沒有強大的推論和最佳化機制,很難實現真正的即時應用。
軟硬體的新基石:Ubuntu 24.04、ROS 2 Jazzy與NPU
為了解決算力瓶頸,2025年的機器人開發架構迎來了一次大換血。
過去,開發者常受限於舊版Linux Kernel無法驅動新硬體,但在Ubuntu 24.04 LTS與ROS 2 Jazzy Jalisco的組合下,我們終於能完整釋放新一代Intel Core Ultra (Meteor Lake/Lunar Lake)的潛能。
為什麼作業系統版本這麼重要?
新的Intel NPU(Meteor Lake / Lunar Lake)在Linux上的驅動,依賴較新的i915/xe GPU子系統與VPU模組,通常需要Linux Kernel 6.8或更高版本才能獲得完整而穩定的支援。Ubuntu 24.04 LTS原生採用Kernel 6.8,因此成為第一個能可靠啟用Intel NPU的主流Linux發行版。
這代表NPU推論不再主要依賴Windows的AI堆疊(如DirectML),Linux——尤其是採用ROS 2的機器人平台——現在也能利用 NPU 執行低功耗且持續運行的 AI 推論工作,如姿態偵測、關鍵字辨識與基本視覺模型推論。
ROS 2 生態系的成熟
ROS 2 Jazzy相較於前版(如 Humble、Iron),在 RMW(DDS 通訊層)上提供了更穩定的 QoS 行為與更佳的通訊效率,並正式支援Python 3.12,讓機器人在多感測器同步與資料密集型應用中能有更高效的表現。
在典型的 3D 機器人架構中:
- RealSense輸出RGB與深度影像,並可透過相機參數即時計算對應的點雲;
- rtabmap或ORB-SLAM3用於建圖與定位;
- Nav2負責全域與局部路徑規劃。
這些模組構成一套穩定的機器人骨架。然而,一旦加入AI模型(如物體偵測、語意分割或3D骨架追蹤),CPU 通常會迅速成為瓶頸,導致SLAM或 Nav2 的延遲飆高。因此在現代的邊緣平台上,AI推論通常會被卸載至NPU、GPU或OpenVINO的異質裝置,以維持整體系統的即時性。
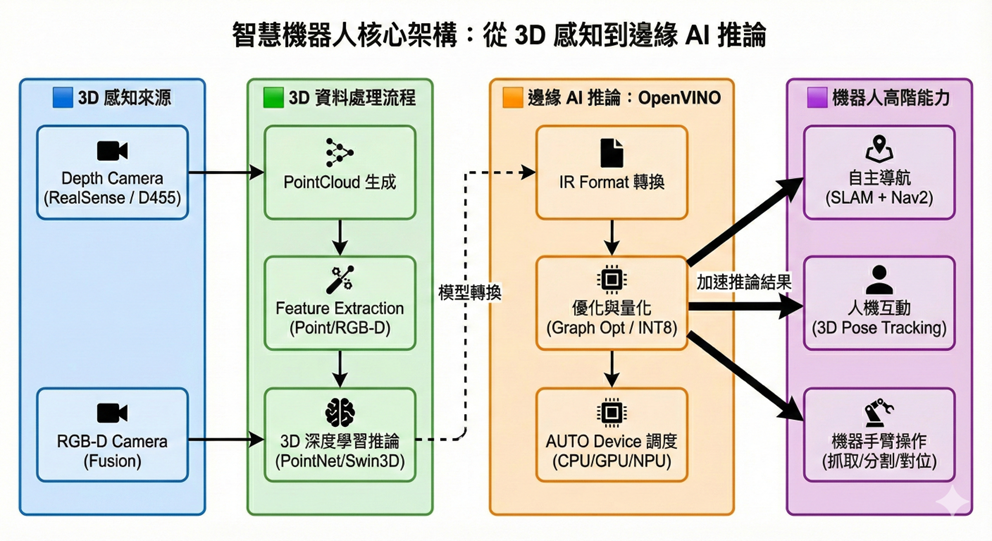
OpenVINO的技術核心:為3D推論補上最後一塊拼圖
業界常誤以為OpenVINO只是另一個「AI 加速框架」。更精準地說,它是一個部署框架(Deployment Framework),專注於推論階段的最佳效能、延遲穩定性與多硬體裝置調度。對3D機器人而言,OpenVINO的價值特別展現在「延遲抖動控制」與「異質運算能力」。
圖形最佳化(Graph Optimization):讓模型更適合邊緣硬體
在推論前,OpenVINO Runtime會重新整理模型計算圖:
- 算子融合(Operator Fusion):將Conv+BN+ReLU 合併成單一 運算核心(kernel)。
- 常數摺疊(Constant Folding):預先計算並移除不變張量。
- 記憶體布局最佳化(Layout Optimization):自動選擇CPU或GPU最佳tensor排列。
對3D模型特別有效,例如PointNet(大量MatMul)或3D segmentation模型(卷積堆疊)。這些最佳化能讓延遲分佈更穩定,減少實際系統常見的 jitter。
記憶體重用(Memory Reuse):降低jitter延遲抖動
3D模型推論會產生大量中間張量,如果沒有統一記憶體管理,每幀都會引發Allocate/Free,導致系統卡頓。OpenVINO的memory engine會快取並重用記憶體區塊,使SLAM、3D Pose Tracking等pipeline在邊緣設備中表現得更穩定。
異質運算(Heterogeneous Execution):CPU / GPU / NPU 的最佳分工
透過 ov::Core::compile_model(model, “AUTO”),OpenVINO Runtime會根據模型特性、功耗與延遲動態選擇最佳裝置(而非將模型拆分)。分工建議如下:
- NPU:低功耗、持續運作的任務(姿態偵測、跌倒偵測、語音喚醒)
- iGPU(Arc Graphics):高吞吐需求任務(3D segmentation、PointNet、SAM)
- CPU:掌控ROS 2感測器流水線、SLAM、地圖融合
這種異質分工讓3D感知與推論在邊緣平台真正落地。
實戰開發:拋棄舊套件,擁抱原生流水線
隨著3D感知工作流程越來越複雜,許多團隊開始從既有套件(如 ros2_openvino_toolkit)轉向自建推論節點(Custom Inference Node),以達到:
- 模型熱更新
- 多模型併行
- 更佳的資料同步
- 與Nav2/SLAM的深度整合
以下介紹ROS 2 pipeline:
Step 1:訂閱 RGB + Depth(對齊後)
以 RealSense 為例:
- /camera/color/image_raw
- /camera/aligned_depth_to_color/image_raw
深度資料與 RGB 完全對齊後,才能做 bounding box → depth query。
Step 2:OpenVINO 推論 YOLOv11 / SAM2 / PointNet
import openvino as ov
core = ov.Core()
model = core.read_model("yolov11.xml")
compiled = core.compile_model(model=model, device_name="NPU")
在 NPU 上跑偵測模型可以確保:
- 低功耗
- 穩定延遲
- SLAM 不被拖慢
Step 3:2D→3D 投影(以 YOLOv11 為例)
當 YOLOv11 完成推論後,每個偵測結果都會包含一個 2D 邊界框,例如 (x1,y1,x2,y2)。接著我們在對齊後的深度影像 /camera/aligned_depth_to_color/image_raw 中,擷取該框內的深度值,通常取中位數以降低雜訊。然後利用相機內參 (fx,fy,cx,cy)套用針孔相機模型,將像素座標與深度轉換為 3D 座標:
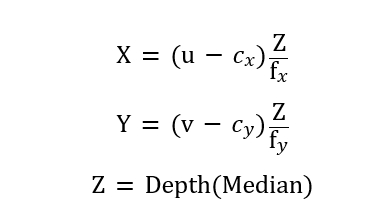
其中 (u,v)可以取邊界框中心或框內所有像素的平均位置。這樣一來,每一個 YOLOv11 的偵測結果就不再只是 2D bbox,而是帶有真實世界長度單位(公分或公尺)的三維座標 (X,Y,Z),可以直接提供給 Nav2 或 MoveIt 作為避障與抓取的依據。
import numpy as np
# 假設使用 Ultralytics YOLOv11
from ultralytics import YOLO
model = YOLO("yolov11n_openvino_model/") # OpenVINO 匯出的路徑
results = model(rgb_frame)[0] # 單張推論結果
boxes = results.boxes
# 相機內參
fx, fy = camera_info.fx, camera_info.fy
cx, cy = camera_info.cx, camera_info.cy
points_3d = []
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0].int().tolist()
# 在深度圖取出該框的區域
depth_roi = depth_frame[y1:y2, x1:x2]
# 去除 0 或無效深度後取中位數
valid = depth_roi[depth_roi > 0]
if valid.size == 0:
continue
Z = np.median(valid) * depth_scale # 轉成公尺(視你的 depth_scale 而定)
# 取邊界框中心點
u = int((x1 + x2) / 2)
v = int((y1 + y2) / 2)
X = (u - cx) * Z / fx
Y = (v - cy) * Z / fy
points_3d.append((X, Y, Z))
Step 4: 決策與導航
將 3D 座標發布給 Nav2 的 Costmap,實現動態避障。
模型案例:3D推論如何展現真正效果?
PointNet 3D 分割:從點雲到語意部件
在倉儲與物流場景中,機器手臂常需要辨識椅子等物件的椅背、椅腳、椅面等部件(例如 ShapeNetPart dataset)。PointNet 透過大量 MatMul 與 MaxPooling 建構全域特徵,經 OpenVINO 優化後,即使在無獨顯的 NUC 上也能維持高 FPS 運作,適合用於精準抓取與避障。
即時3D人體姿態估測(Live 3D Pose)
OpenVINO 的 3D Pose 模型
- human-pose-estimation-3d-0001(Intel Open Model Zoo)
- 支援 RGB → 2D keypoints
- 搭配深度(Z 值)即可重建 3D skeleton
用途包含健身教練、復健系統、長照跌倒偵測、工業人機協作安全模型等。可結合RGB與深度估計人體骨架在3D空間中的位置,用於復健、健身教練與長照照護。部署在NPU上能提供低功耗、長時間監控能力,同時避免佔用CPU造成SLAM與導航延遲。
強化視覺SLAM
在採用CNN 特徵(如SuperPoint)進行建圖與回環偵測的SLAM系統中,特徵提取網路可使用OpenVINO加速,使得回環更穩定、地圖品質更高,也提升機器人在複雜環境中的導航可靠度。
| 應用場景 | 使用模型 | OpenVINO 模型來源 | 適用設備 |
| 3D 分割 (椅背/椅腳等零件) |
PointNet / PointNet++ | ONNX → OpenVINO IR | NUC、Khadas Mind 2、Arc GPU |
| 3D 人體姿態 | human-pose-estimation-3d-0001 | Open Model Zoo | NPU、iGPU |
| 視覺 SLAM 特徵提取 | SuperPoint、SuperGlue | ONNX → OpenVINO IR | CPU / Arc GPU |
Edge AI設備的崛起:AI PC提供了最適合的落地環境
隨著3D感知與多模型推論成為智慧機器人的核心需求,邊緣運算設備的效能、功耗與記憶體頻寬比過去更加關鍵。以採用Intel Core Ultra(Lunar Lake)的最新一代AI PC為例,例如Khadas Mind 2或部分搭載Core Ultra處理器的ASUS NUC新款機種,這類設備通常整合了:
- Intel Arc GPU(具備高效的 AI 加速能力,官方估算最高可達約 64 TOPS)
- Intel NPU(專為低功耗推論設計,AI 加速能力最高約 47 TOPS)
- LPDDR5X 高頻寬記憶體(有助於 3D 感知與多模型推論的資料吞吐)
| 項目 | 規格內容 | 說明(與 AI/機器人相關性) |
| 處理器(CPU) | Intel Core Ultra 7 / Ultra 5(Lunar Lake) | 新世代 Intel 低功耗架構,適合機器人本地推論與 ROS 2 工作負載 |
| GPU(Intel Arc Graphics) | AI 加速能力最高 64 TOPS(INT8 理論值) | 適合 YOLO segmentation、SAM2、PointNet、Swin3D 等高吞吐模型 |
| NPU(Intel AI Boost / VPU) | AI 加速能力最高 47 TOPS | 適合長時間運行的低功耗任務,如 3D Pose、關鍵字辨識 |
| 總 AI 加速能力 | 官方估算最高約 115 TOPS(CPU+GPU+NPU) | 作為整體 AI 能力上限的參考值(非所有工作負載可同時滿載) |
| 記憶體 | LPDDR5X(高頻寬) | 適合 3D 感知與影片 Transformer 中的大量資料搬移 |
| 儲存 | NVMe SSD(最高 PCIe Gen 4) | 適合模型載入、SLAM 地圖儲存與高速資料紀錄 |
| 連接介面 | USB4、USB-C、HDMI、Ethernet | 支援 RealSense、ZED、LiDAR 與 ROS 2 Gateway |
| 擴充能力 | Mind Link(可擴充外接 GPU / Dock / PCIe) | 保留加速卡、深度相機等擴充彈性 |
| 尺寸 | 147 × 101 × 20 mm | 可直接搭載在移動機器人底盤 |
| 功耗 | 約 15W–30W(依負載) | 適合長時間 3D 感知與 AI 推論 |
| 作業系統支援 | Ubuntu 24.04 / Windows 11 | Ubuntu 24.04(Kernel 6.8+)可啟用 NPU,適合 OpenVINO 部署 |
基於其CPU、GPU、NPU的異質架構與高頻寬記憶體,像Khadas Mind 2這類AI PC能有效地將不同工作負載分配至最適合的硬體單元,例如由GPU處理影像分割、由NPU執行低功耗推論、由CPU處理SLAM與ROS 2流水線。搭配OpenVINO的AUTO裝置調度與模型最佳化,這些AI PC已成為邊緣推論與3D感知最理想的部署平台之一。
結語:開啟智慧機器人的下一個十年
整合上述所有技術,你會發現一條非常清晰的新機器人計算架構:
3D感知(RealSense) → 邊緣推論(OpenVINO + NPU) → 空間決策(ROS 2 Nav2)
從前述的技術脈絡中,我們可以清晰看出未來智慧機器人的核心計算架構:
3D感知(Depth/RGB-D) → 邊緣推論(OpenVINO × NPU × GPU) → 空間理解與決策(SLAM + Nav2)
這代表著機器人已經正式從過去的「影像辨識導向」,跨越到真正的「空間理解導向」。
3D 機器人的瓶頸從來不是感測器的品質,也不是SLAM理論的成熟度,而是 AI 模型無法在邊緣設備上以穩定、快速、低功耗的方式執行。
如今,隨著Ubuntu 24.04完整支援Intel NPU、OpenVINO進化為異質推論框架,以及AI PC的普及,這個瓶頸正被徹底解除。接下來的十年,智慧機器人將不再依賴雲端,而是以本地推論的方式完成感知、理解與行動——真正具備三維認知能力、自主決策能力與長時間運行能力的機器人時代,已經正式開始。

專長:醫療資訊系統、生物資訊、雲端運算、大數據、人工智慧、分散式系統、行動裝置程式設計、軟體工程、行動資訊系統、數位圖像處理
- 以3D感知開啟智慧機器人新時代:從深度相機到OpenVINO的邊緣智慧革命 - 2025/12/12
- OpenVINO 2024.2姿態模型效能評估:以OpenPose、YOLOv8與3D-Pose為例 - 2024/08/05
- 優化OpenVINO模型效能:參數設定影響實測 - 2021/08/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


