作者:顏國進,英特爾創新大使
YOLOv9模型是YOLO系列即時目標檢測演算法中的最新版本,代表著該系列在準確性、速度和效率方面的又一次重大飛躍。它透過導入先進的深度學習技術和創新的架構設計,如通用ELAN (GELAN)和可程式化梯度資訊(PGI),顯著提升了物體檢測的性能。在本文中,我們將結合OpenVINO C# API使用最新發佈的OpenVINO 2024.0部署YOLOv9目標檢測和實例分割模型。
OpenVINO C# API
英特爾(Intel)發行版本OpenVINO工具套件基於oneAPI而開發,可以加快高性能電腦視覺和深度學習視覺應用開發速度工具套件,適用於從邊緣到雲端的各種英特爾平台上,幫助用戶更快地將更準確的真實世界結果部署到生產系統中。透過簡化的開發工作流程,OpenVINO可賦能開發者在現實世界中部署高性能應用程式和演算法。
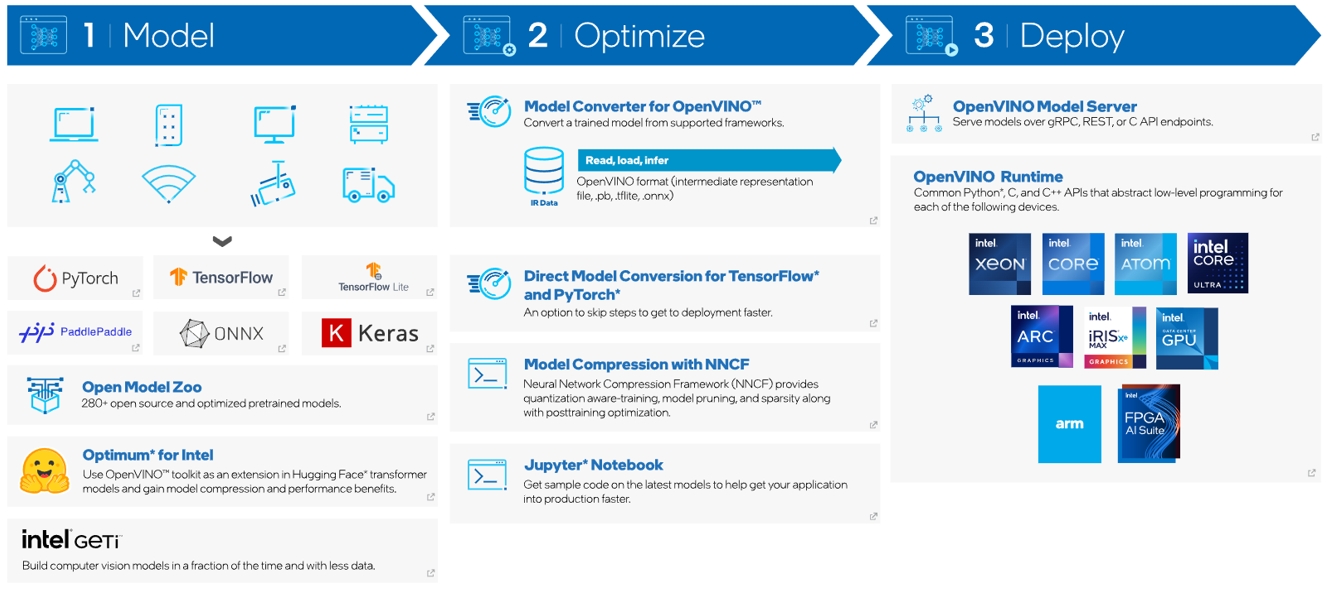
2024年3月7日,英特爾發佈了2024.0版的開源OpenVINO工具套件,用於在各種硬體上最佳化和部署人工智慧推論。OpenVINO是英特爾出色的開源AI工具套件,不僅可以在 x86_64 CPU上加速AI推論,還可以在Arm CPU和其他架構、英特爾整合式顯卡和獨立顯卡等硬體上加速AI推論,包括最近推出的NPU外掛程式,可用於利用新一代Core Ultra (代號Meteor Lake)系統晶片中的英特爾NPU。
OpenVINO 2024.0也更注重生成式AI (GenAI),能為TensorFlow句子編碼模型提供更好的開箱即用體驗,並支援混合專家架構(MoE)。同時還提高了LLM的INT4權重壓縮品質,增強了 LLM在英特爾CPU上的性能,簡化了Hugging Face模型的最佳化和轉換,並改善了其他 Hugging Face整合。
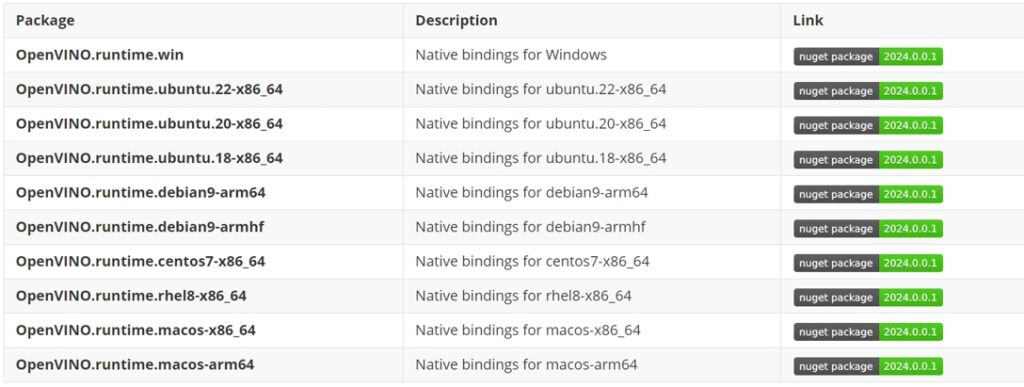
OpenVINO C# API是一個OpenVINO的.Net wrapper,應用最新的OpenVINO程式庫開發,透過OpenVINO C# API 實現.Net 對OpenVINO Runtime呼叫,使用習慣與OpenVINO C++ API 一致。因為OpenVINO C# API是以OpenVINO為基礎開發,所支援的平台與OpenVINO完全一致,具體資訊可以參考OpenVINO。透過使用OpenVINO C# API,可以在.NET、.NET Framework等框架下使用C#語言,實現深度學習模型在指定平台的推論加速。
下表為當前發佈的OpenVINO C# API NuGet Package,支援多個目標平台,可以透過NuGet一鍵安裝所有依賴。

Core Managed Libraries
Native Runtime Libraries
YOLOv9
具體來說,YOLOv9解決了深度神經網路中資訊丟失的問題,透過整合PGI和GELAN架構,不僅增強了模型的學習能力,還確保了在整個檢測過程中保留關鍵資訊。此外,它採用更深的網路結構以提取更豐富的特徵,同時導入殘差連接和跨層連接等機制以最佳化訓練過程。為了提高模型的泛化能力並降低過擬合風險,YOLOv9還使用了正則化技術,如權重衰減和Dropout。
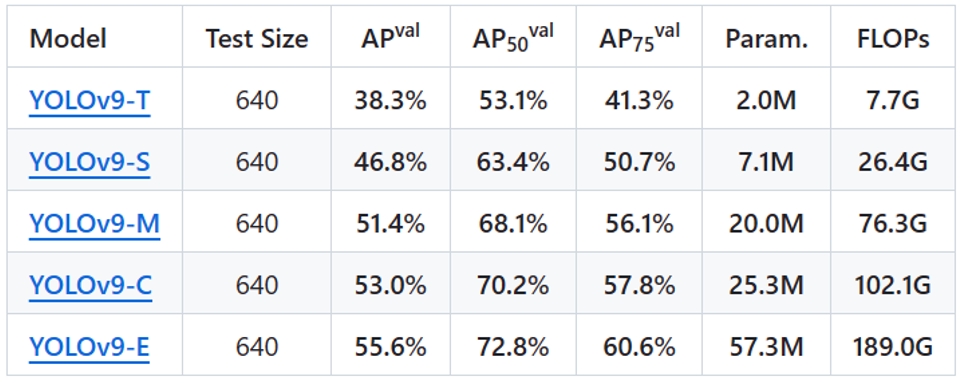
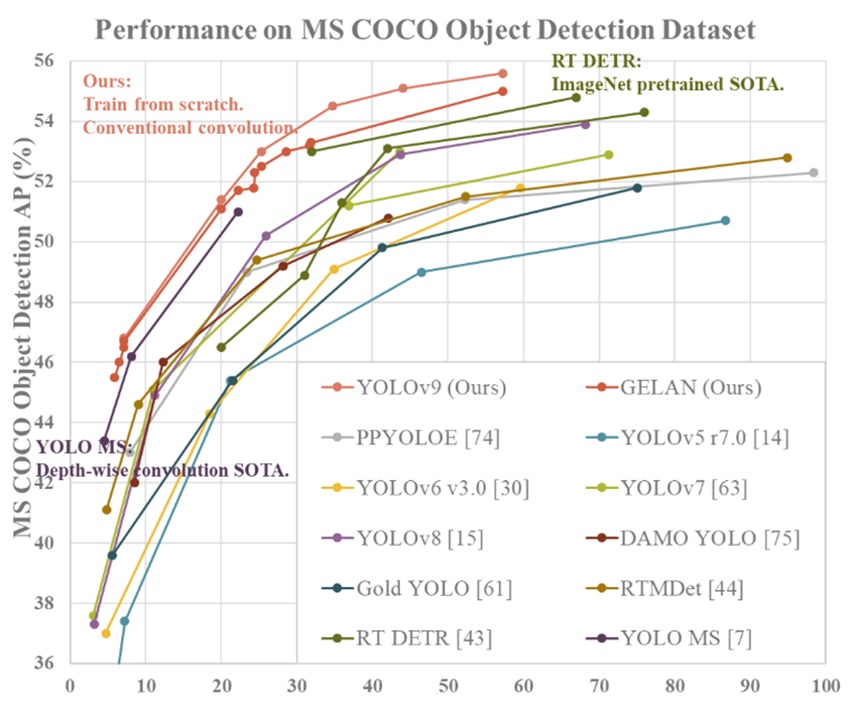
由於YOLOv9在模型架構、訓練策略以及資料處理等方面的改善,它在COCO資料集上能夠獲得更高的AP值,顯示出其在複雜和多樣化場景下的卓越性能。此外,YOLOv9還注重即時性能,透過最佳化網路結構和計算效率,實現了在保持高性能的同時減少計算量和提高處理速度。這使得YOLOv9在即時目標檢測任務中具有顯著優勢,能夠滿足各種應用場景的需求。
取得模型
源碼下載
YOLOv9 模型可以透過原始程式碼進行下載,首先複製GitHub上的原始程式碼,輸入以下指令:
git clone https://github.com/WongKinYiu/yolov9.git
cd yolov9
配置環境
接下來安裝模型下載以及轉換環境,此處使用Anaconda進行程式集管理,輸入以下指令創建一個yolov9環境:
conda create -n yolov9 python=3.10
conda activate yolov9
然後安裝yolov9模型下載以及轉換所必需的環境,輸入以下指令:
pip install -r requirements.txt
pip install openvino==2024.0.0
下載模型
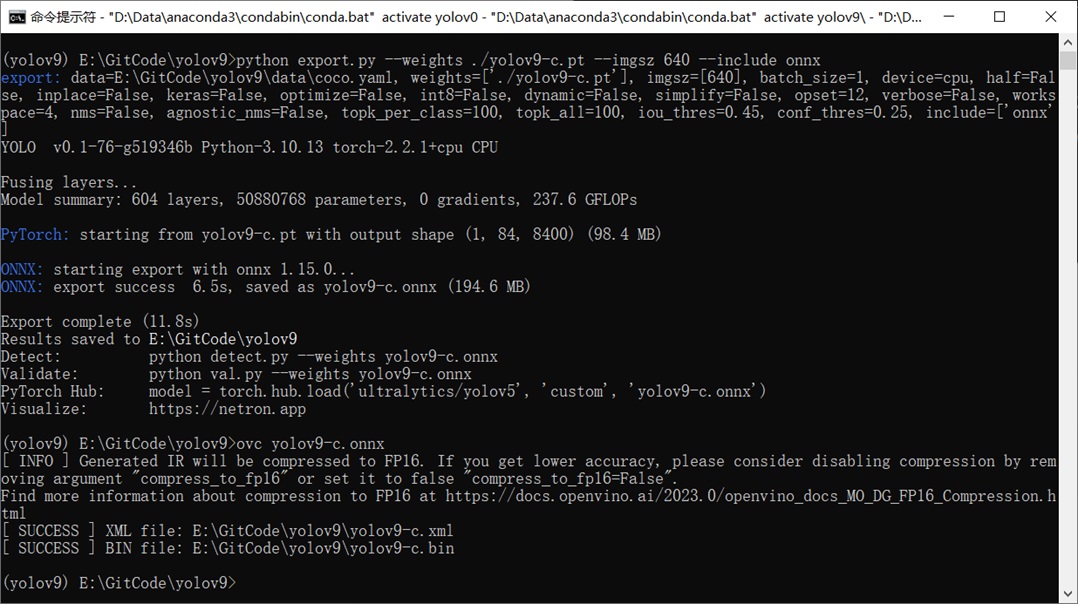
首先匯出目標識別模型,此處以官方預訓練模型為例,首先下載預訓練模型檔,然後呼叫export.py檔匯出ONNX格式的模型檔,最後使用OpenVINO的模型轉換命令將模型轉為IR格式,依次輸入以下指令即可:
wget https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.p
python export.py --weights ./yolov9-c.pt --imgsz 640 --include onnx
ovc yolov9-c.onnx
同樣的方式可以匯出實例分割模型:
wget https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c-seg.ptt
python export.py --weights ./gelan-c-seg.pt --imgsz 640 --include onnx
ovc gelan-c-seg.onnx
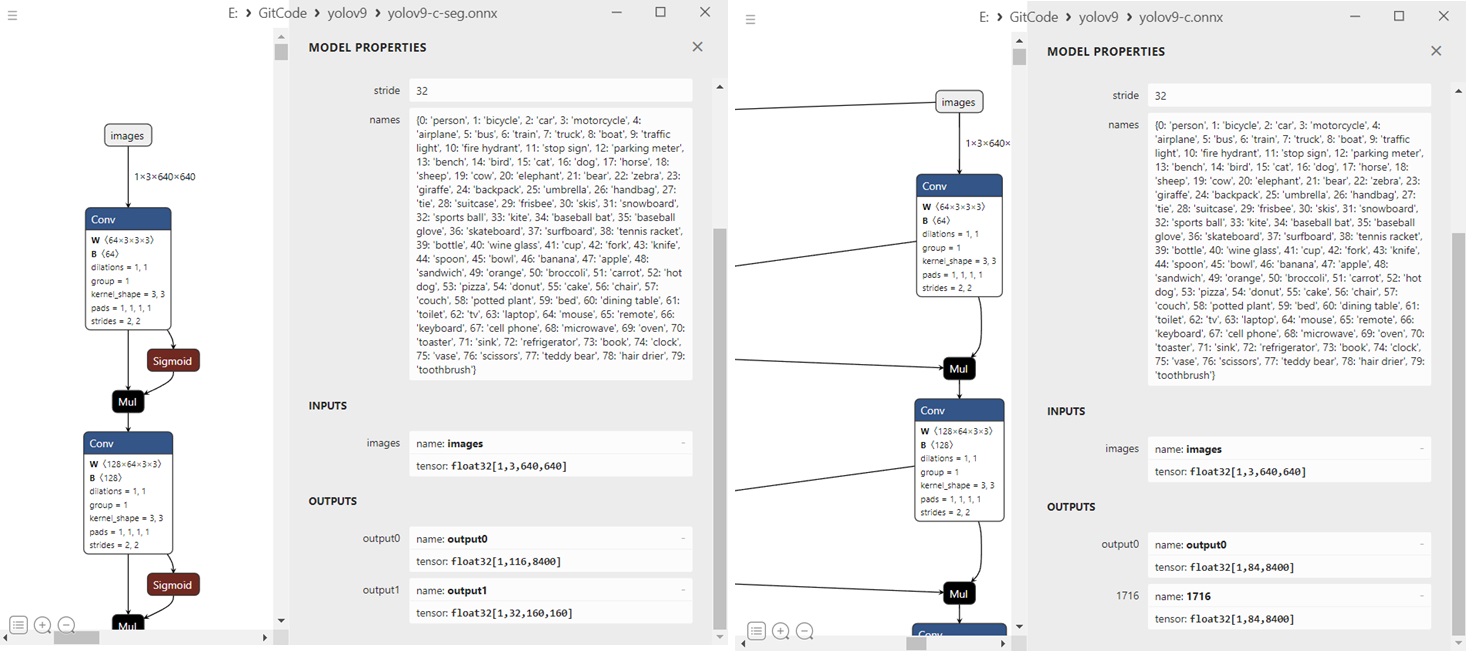
模型的結構如下圖所示:
Yolov9 專案配置
專案創建與環境配置
在Windows平台開發者可以使用Visual Studio平台開發程式,但無法跨平台實現,為了實現跨平台,此處採用dotnet指令進行專案的創建和配置。
首先使用dotnet創建一個測試專案,在終端中輸入以下指令:
dotnet new console --framework net6.0 --use-program-main -o yolov9
此處以Windows平台為例安裝專案依賴,首先是安裝OpenVINO C# API專案依賴,在命令列中輸入以下指令即可:
dotnet add package OpenVINO.CSharp.API
dotnet add package OpenVINO.runtime.win
dotnet add package OpenVINO.CSharp.API.Extensions
dotnet add package OpenVINO.CSharp.API.Extensions.OpenCvSharp
接下來安裝使用到的影像處理庫OpenCvSharp,在命令列中輸入以下指令即可:
dotnet add package OpenCvSharp4
dotnet add package OpenCvSharp4.Extensions
dotnet add package OpenCvSharp4.runtime.win
添加完成專案依賴後,專案的設定檔如下所示:
Exe
net6.0
enable
enable
定義模型預測方法
使用 OpenVINO C# API 部署模型主要包括以下幾個步驟:
- 初始化 OpenVINO Runtime Core
- 讀取本地模型(將圖片資料預處理方式編譯到模型)
- 將模型編譯到指定設備
- 創建推論通道
- 處理影像輸入資料
- 設置推論輸入資料
- 模型推論
- 取得推論結果
- 處理結果資料
定義目標檢測模型方法
按照 OpenVINO C# API部署深度學習模型的步驟,編寫YOLOv9模型部署流程,在之前的專案裡,我們已經部署了YOLOv5~8等一系列模型,其部署流程是基本一致的,YOLOv9模型部署程式碼如下所示:
static void yolov9_det(string model_path, string image_path, string device)
{
// -------- Step 1. Initialize OpenVINO Runtime Core --------
Core core = new Core();
// -------- Step 2. Read inference model --------
Model model = core.read_model(model_path);
// -------- Step 3. Loading a model to the device --------
CompiledModel compiled_model = core.compile_model(model, device);
// -------- Step 4. Create an infer request --------
InferRequest infer_request = compiled_model.create_infer_request();
// -------- Step 5. Process input images --------
Mat image = new Mat(image_path); // Read image by opencvsharp
int max_image_length = image.Cols > image.Rows ? image.Cols : image.Rows;
Mat max_image = Mat.Zeros(new OpenCvSharp.Size(max_image_length, max_image_length), MatType.CV_8UC3);
Rect roi = new Rect(0, 0, image.Cols, image.Rows);
image.CopyTo(new Mat(max_image, roi));
float factor = (float)(max_image_length / 640.0);
// -------- Step 6. Set up input data --------
Tensor input_tensor = infer_request.get_input_tensor();
Shape input_shape = input_tensor.get_shape();
Mat input_mat = CvDnn.BlobFromImage(max_image, 1.0 / 255.0, new OpenCvSharp.Size(input_shape[2], input_shape[3]), 0, true, false);
float[] input_data = new float[input_shape[1] * input_shape[2] * input_shape[3]];
Marshal.Copy(input_mat.Ptr(0), input_data, 0, input_data.Length);
input_tensor.set_data(input_data);
// -------- Step 7. Do inference synchronously --------
infer_request.infer();
// -------- Step 8. Get infer result data --------
start = DateTime.Now;
Tensor output_tensor = new Tensor();
if (model.get_outputs_size() > 1)
{
output_tensor = infer_request.get_output_tensor(1);
}
else
{
output_tensor = infer_request.get_output_tensor();
}
int output_length = (int)output_tensor.get_size();
float[] output_data = output_tensor.get_data(output_length);
// -------- Step 9. Process reault --------
Mat result_data = new Mat(84, 8400, MatType.CV_32F, output_data);
result_data = result_data.T();
// Storage results list
List position_boxes = new List();
List class_ids = new List();
List confidences = new List();
// Preprocessing output results
for (int i = 0; i < result_data.Rows; i++) { Mat classes_scores = new Mat(result_data, new Rect(4, i, 80, 1)); OpenCvSharp.Point max_classId_point, min_classId_point; double max_score, min_score; // Obtain the maximum value and its position in a set of data Cv2.MinMaxLoc(classes_scores, out min_score, out max_score, out min_classId_point, out max_classId_point); // Confidence level between 0 ~ 1 // Obtain identification box information if (max_score > 0.25)
{
float cx = result_data.At(i, 0);
float cy = result_data.At(i, 1);
float ow = result_data.At(i, 2);
float oh = result_data.At(i, 3);
int x = (int)((cx - 0.5 * ow) * factor);
int y = (int)((cy - 0.5 * oh) * factor);
int width = (int)(ow * factor);
int height = (int)(oh * factor);
Rect box = new Rect();
box.X = x;
box.Y = y;
box.Width = width;
box.Height = height;
position_boxes.Add(box);
class_ids.Add(max_classId_point.X);
confidences.Add((float)max_score);
}
}
// NMS non maximum suppression
int[] indexes = new int[position_boxes.Count];
CvDnn.NMSBoxes(position_boxes, confidences, 0.5f, 0.5f, out indexes);
for (int i = 0; i < indexes.Length; i++)
{
int index = indexes[i];
Cv2.Rectangle(image, position_boxes[index], new Scalar(0, 0, 255), 2, LineTypes.Link8);
Cv2.Rectangle(image, new OpenCvSharp.Point(position_boxes[index].TopLeft.X, position_boxes[index].TopLeft.Y + 30),
new OpenCvSharp.Point(position_boxes[index].BottomRight.X, position_boxes[index].TopLeft.Y), new Scalar(0, 255, 255), -1);
Cv2.PutText(image, class_ids[index] + "-" + confidences[index].ToString("0.00"),
new OpenCvSharp.Point(position_boxes[index].X, position_boxes[index].Y + 25),
HersheyFonts.HersheySimplex, 0.8, new Scalar(0, 0, 0), 2);
}
string output_path = Path.Combine(Path.GetDirectoryName(Path.GetFullPath(image_path)),
Path.GetFileNameWithoutExtension(image_path) + "_result.jpg");
Cv2.ImWrite(output_path, image);
Slog.INFO("The result save to " + output_path);
Cv2.ImShow("Result", image);
Cv2.WaitKey(0);
}
定義實例分割模型方法
實例分割模型部署流程與目標檢測基本一致,主要不同點是模型結果的後處理方式,此處只展示了模型結果後處理程式碼,其他程式碼與YOLOv9目標檢測程式碼一致,YOLOv9實例分割模型部署程式碼如下所示:
static void yolov9_seg(string model_path, string image_path, string device)
{
... ...(程式碼與上文一致)
// -------- Step 8. Get infer result data --------
Tensor output_tensor_0 = infer_request.get_output_tensor(0);
float[] result_detect = output_tensor_0.get_data((int)output_tensor_0.get_size());
Tensor output_tensor_1 = infer_request.get_output_tensor(1);
float[] result_proto = output_tensor_1.get_data((int)output_tensor_1.get_size());
Mat detect_data = new Mat(116, 8400, MatType.CV_32FC1, result_detect);
Mat proto_data = new Mat(32, 25600, MatType.CV_32F, result_proto);
detect_data = detect_data.T();
List position_boxes = new List();
List class_ids = new List();
List confidences = new List();
List masks = new List();
for (int i = 0; i < detect_data.Rows; i++) { Mat classes_scores = new Mat(detect_data, new Rect(4, i, 80, 1));//GetArray(i, 5, classes_scores); Point max_classId_point, min_classId_point; double max_score, min_score; Cv2.MinMaxLoc(classes_scores, out min_score, out max_score, out min_classId_point, out max_classId_point); if (max_score > 0.25)
{
Mat mask = new Mat(detect_data, new Rect(4 + 80, i, 32, 1));//detect_data.Row(i).ColRange(4 + categ_nums, categ_nums + 36);
float cx = detect_data.At(i, 0);
float cy = detect_data.At(i, 1);
float ow = detect_data.At(i, 2);
float oh = detect_data.At(i, 3);
int x = (int)((cx - 0.5 * ow) * factor);
int y = (int)((cy - 0.5 * oh) * factor);
int width = (int)(ow * factor);
int height = (int)(oh * factor);
Rect box = new Rect();
box.X = x;
box.Y = y;
box.Width = width;
box.Height = height;
position_boxes.Add(box);
class_ids.Add(max_classId_point.X);
confidences.Add((float)max_score);
masks.Add(mask);
}
}
int[] indexes = new int[position_boxes.Count];
CvDnn.NMSBoxes(position_boxes, confidences, 0.5f, 0.5f, out indexes);
SegResult result = new SegResult();
Mat rgb_mask = Mat.Zeros(new Size((int)image.Size().Width, (int)image.Size().Height), MatType.CV_8UC3);
Random rd = new Random(); // Generate Random Numbers
for (int i = 0; i < indexes.Length; i++)
{
int index = indexes[i];
// Division scope
Rect box = position_boxes[index];
int box_x1 = Math.Max(0, box.X);
int box_y1 = Math.Max(0, box.Y);
int box_x2 = Math.Max(0, box.BottomRight.X);
int box_y2 = Math.Max(0, box.BottomRight.Y);
// Segmentation results
Mat original_mask = masks[index] * proto_data;
for (int col = 0; col < original_mask.Cols; col++)
{
original_mask.Set(0, col, sigmoid(original_mask.At(0, col)));
}
// 1x25600 -> 160x160 Convert to original size
Mat reshape_mask = original_mask.Reshape(1, 160);
// Split size after scaling
int mx1 = Math.Max(0, (int)((box_x1 / factor) * 0.25));
int mx2 = Math.Min(160, (int)((box_x2 / factor) * 0.25));
int my1 = Math.Max(0, (int)((box_y1 / factor) * 0.25));
int my2 = Math.Min(160, (int)((box_y2 / factor) * 0.25));
// Crop Split Region
Mat mask_roi = new Mat(reshape_mask, new OpenCvSharp.Range(my1, my2), new OpenCvSharp.Range(mx1, mx2));
// Convert the segmented area to the actual size of the image
Mat actual_maskm = new Mat();
Cv2.Resize(mask_roi, actual_maskm, new Size(box_x2 - box_x1, box_y2 - box_y1));
// Binary segmentation region
for (int r = 0; r < actual_maskm.Rows; r++)
{
for (int c = 0; c < actual_maskm.Cols; c++)
{
float pv = actual_maskm.At(r, c);
if (pv > 0.5)
{
actual_maskm.Set(r, c, 1.0f);
}
else
{
actual_maskm.Set(r, c, 0.0f);
}
}
}
// 預測
Mat bin_mask = new Mat();
actual_maskm = actual_maskm * 200;
actual_maskm.ConvertTo(bin_mask, MatType.CV_8UC1);
if ((box_y1 + bin_mask.Rows) >= (int)image.Size().Height)
{
box_y2 = (int)image.Size().Height - 1;
}
if ((box_x1 + bin_mask.Cols) >= (int)image.Size().Width)
{
box_x2 = (int)image.Size().Width - 1;
}
// Obtain segmentation area
Mat mask = Mat.Zeros(new Size((int)image.Size().Width, (int)image.Size().Height), MatType.CV_8UC1);
bin_mask = new Mat(bin_mask, new OpenCvSharp.Range(0, box_y2 - box_y1), new OpenCvSharp.Range(0, box_x2 - box_x1));
Rect roi1 = new Rect(box_x1, box_y1, box_x2 - box_x1, box_y2 - box_y1);
bin_mask.CopyTo(new Mat(mask, roi1));
// Color segmentation area
Cv2.Add(rgb_mask, new Scalar(rd.Next(0, 255), rd.Next(0, 255), rd.Next(0, 255)), rgb_mask, mask);
result.add(class_ids[index], confidences[index], position_boxes[index], rgb_mask.Clone());
}
Mat masked_img = new Mat();
// Draw recognition results on the image
for (int i = 0; i < result.count; i++)
{
Cv2.Rectangle(image, result.datas[i].box, new Scalar(0, 0, 255), 2, LineTypes.Link8);
Cv2.Rectangle(image, new Point(result.datas[i].box.TopLeft.X, result.datas[i].box.TopLeft.Y + 30),
new Point(result.datas[i].box.BottomRight.X, result.datas[i].box.TopLeft.Y), new Scalar(0, 255, 255), -1);
Cv2.PutText(image, CocoOption.lables[result.datas[i].index] + "-" + result.datas[i].score.ToString("0.00"),
new Point(result.datas[i].box.X, result.datas[i].box.Y + 25),
HersheyFonts.HersheySimplex, 0.8, new Scalar(0, 0, 0), 2);
Cv2.AddWeighted(image, 0.5, result.datas[i].mask, 0.5, 0, masked_img);
}
string output_path = Path.Combine(Path.GetDirectoryName(Path.GetFullPath(image_path)),
Path.GetFileNameWithoutExtension(image_path) + "_result.jpg");
Cv2.ImWrite(output_path, masked_img);
Slog.INFO("The result save to " + output_path);
Cv2.ImShow("Result", masked_img);
Cv2.WaitKey(0);
}
使用OpenVINO預處理介面編譯模型
OpenVINO提供了推論資料預處理介面,使用者能以更具模型的輸入資料預處理方式進行設置。在讀取本地模型後,呼叫資料預處理介面,按照模型要求的資料預處理方式進行輸入配置,然後再將配置好的預處理介面與模型編譯到一起,這樣便實現了將模型預處理與模型結合在一起,實現OpenVINO對於處理過程的加速。主要程式碼如下所示:
static void yolov9_seg_with_process(string model_path, string image_path, string device)
{
// -------- Step 1. Initialize OpenVINO Runtime Core --------
Core core = new Core();
// -------- Step 2. Read inference model --------
Model model = core.read_model(model_path);
OvExtensions.printf_model_info(model);
PrePostProcessor processor = new PrePostProcessor(model);
Tensor input_tensor_pro = new Tensor(new OvType(ElementType.U8), new Shape(1, 640, 640, 3));
InputInfo input_info = processor.input(0);
InputTensorInfo input_tensor_info = input_info.tensor();
input_tensor_info.set_from(input_tensor_pro).set_layout(new Layout("NHWC")).set_color_format(ColorFormat.BGR);
PreProcessSteps process_steps = input_info.preprocess();
process_steps.convert_color(ColorFormat.RGB).resize(ResizeAlgorithm.RESIZE_LINEAR)
.convert_element_type(new OvType(ElementType.F32)).scale(255.0f).convert_layout(new Layout("NCHW"));
Model new_model = processor.build();
// -------- Step 3. Loading a model to the device --------
CompiledModel compiled_model = core.compile_model(new_model, device);
// -------- Step 4. Create an infer request --------
InferRequest infer_request = compiled_model.create_infer_request();
// -------- Step 5. Process input images --------
Mat image = new Mat(image_path); // Read image by opencvsharp
int max_image_length = image.Cols > image.Rows ? image.Cols : image.Rows;
Mat max_image = Mat.Zeros(new OpenCvSharp.Size(max_image_length, max_image_length), MatType.CV_8UC3);
Rect roi = new Rect(0, 0, image.Cols, image.Rows);
image.CopyTo(new Mat(max_image, roi));
Cv2.Resize(max_image, max_image, new OpenCvSharp.Size(640, 640));
float factor = (float)(max_image_length / 640.0);
// -------- Step 6. Set up input data --------
start = DateTime.Now;
Tensor input_tensor = infer_request.get_input_tensor();
Shape input_shape = input_tensor.get_shape();
byte[] input_data = new byte[input_shape[1] * input_shape[2] * input_shape[3]];
//max_image.GetArray(out input_data);
Marshal.Copy(max_image.Ptr(0), input_data, 0, input_data.Length);
IntPtr destination = input_tensor.data();
Marshal.Copy(input_data, 0, destination, input_data.Length);
// -------- Step 7. Do inference synchronously --------
... ...(後續與上文程式碼一致)
}
模型預測方法呼叫
定義完模型推論介面後,便可以在主函數裡進行呼叫。此處為了讓大家更充分重現本文程式碼,提供了線上模型,使用者只需要執行以下程式碼,便可以直接下載轉換好的模型進行模型推論,無需再自行轉換,主函數程式碼如下所示:
static void Main(string[] args)
{
string model_path = "";
string image_path = "";
string device = "AUTO";
if (args.Length == 0)
{
if (!Directory.Exists("./model"))
{
Directory.CreateDirectory("./model");
}
if (!File.Exists("./model/yolov9-c-converted.xml") && !File.Exists("./model/yolov9-c-converted.bin"))
{
if (!File.Exists("./model/yolov9-c-converted.tar"))
{
_ = Download.download_file_async("https://github.com/guojin-yan/OpenVINO-CSharp-API-Samples/releases/download/Model/yolov9-c-converted.tar",
"./model/yolov9-c-converted.tar").Result;
}
Download.unzip("./model/yolov9-c-converted.tar", "./model/");
}
if (!File.Exists("./model/test_det_01.jpg"))
{
_ = Download.download_file_async("https://github.com/guojin-yan/OpenVINO-CSharp-API-Samples/releases/download/Image/test_det_01.jpg",
"./model/test_det_01.jpg").Result;
}
model_path = "./model/yolov9-c-converted.xml";
image_path = "./model/test_det_01.jpg";
}
else if (args.Length >= 2)
{
model_path = args[0];
image_path = args[1];
device = args[2];
}
else
{
Console.WriteLine("Please enter the correct command parameters, for example:");
Console.WriteLine("> 1. dotnet run");
Console.WriteLine("> 2. dotnet run ");
}
// -------- Get OpenVINO runtime version --------
OpenVinoSharp.Version version = Ov.get_openvino_version();
Slog.INFO("---- OpenVINO INFO----");
Slog.INFO("Description : " + version.description);
Slog.INFO("Build number: " + version.buildNumber);
Slog.INFO("Predict model files: " + model_path);
Slog.INFO("Predict image files: " + image_path);
Slog.INFO("Inference device: " + device);
Slog.INFO("Start yolov9 model inference.");
yolov9_det(model_path, image_path, device);
yolov9_det_with_process(model_path, image_path, device);
}
備註:
由於篇幅限制,上文中只展示了部分程式碼,想要獲取全部原始程式碼,請參考以下GitHub的專案連結自行下載:
此外為了滿足習慣使用EmguCV處理影像資料的開發者,此處我們也提供了EmguCV版本程式碼:
專案執作與展示
專案編譯和執行
接下來輸入專案編譯指令進行專案編譯,輸入以下指令即可:
dotnet build
接下來執行編譯後的程式檔,在CMD中輸入以下指令,執行編譯後的專案檔案:
dotnet run --no-build
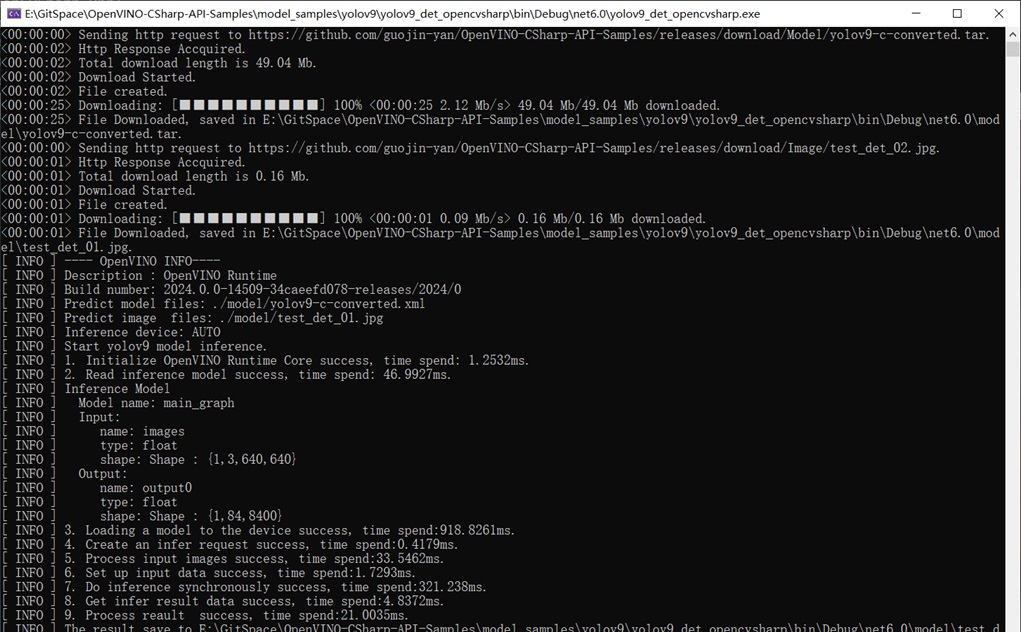
下圖為使用YOLOv9目標檢測模型推論結果:
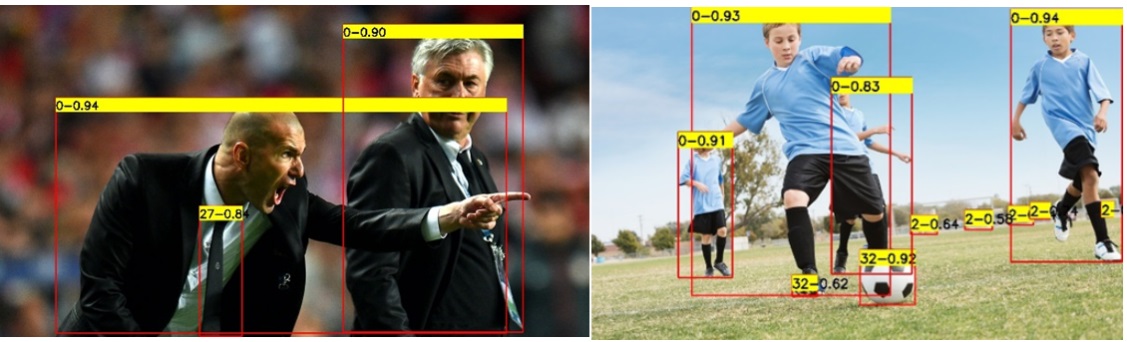
YOLOv9 實例分割模型運作結果
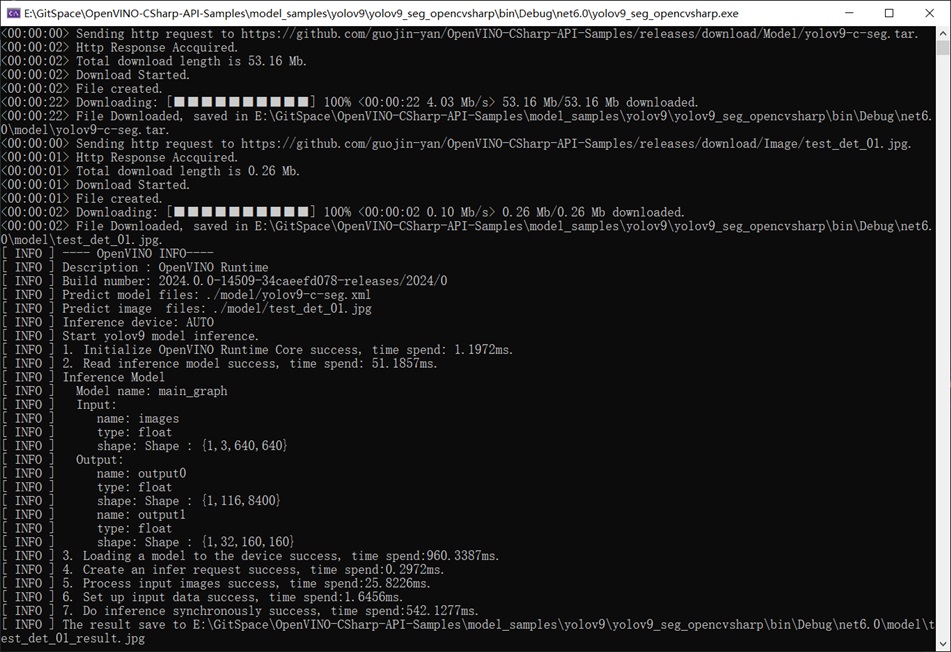
下圖為YOLOv9實例分割模型運作輸出資訊,此處我們使用線上轉換好的模型進行推論。首先會下載指定模型以及推論資料到本地,這樣避免了開發者再自己配置環境和下載模型;接下來是輸出列印OpenVINO版本資訊,此處我們使用NuGet安裝的依賴項,已經是OpenVINO 2024.0最新版本;接下來就是列印相關的模型資訊,並輸出每個過程所消耗時間。
下圖為使用YOLOv9實例分割模型推論結果:

總結
在這個專案中,我們結合之前開發的OpenVINO C# API專案部署YOLOv9模型,成功實現了物件目標檢測與實例分割,並且根據不同開發者的使用習慣,同時提供OpenCvSharp以及Emgu.CV兩種版本供各位開發者使用;如果各位開發者在使用中有任何問題,歡迎提出來一起討論!

- AI Agent時代來臨:看邊緣AI如何成為驅動智慧機器人的關鍵 - 2025/11/28
- OpenVINO×ExecuTorch:解鎖英特爾架構AI PC模型推論效能新境界 - 2025/11/21
- 讓生成式AI應用在Intel架構系統本地端高效率運作的訣竅 - 2025/10/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


